 夜雨聆风
夜雨聆风





OpenAI账单只告诉你烧了多少钱,却不告诉钱死在哪:一套3文件成本追踪仪表盘

很多团队接入 OpenAI API 后,第一反应都是盯总账单:今天花了多少、这个月烧了多少、哪天突然变贵。
但真正危险的地方不在这里。总账单只能告诉你“钱没了”,却很难回答更关键的问题:到底是哪一个租户、哪一个功能、哪一轮对话、哪一次失败调用,把预算悄悄吃掉了?
对单人实验项目来说,这可能只是一个管理不够精细的小问题。对多租户 SaaS、AI 客服、智能导购、内容生成平台来说,这就是生产事故的前奏。因为 AI 成本不是按功能模块线性增长,而是被上下文长度、模型选择、工具调用、重试逻辑、异常请求一起放大。
所以,AI 产品上线前最该补的一层基础设施,不是更复杂的 Prompt,而是一套能回答“钱死在哪”的成本追踪仪表盘。
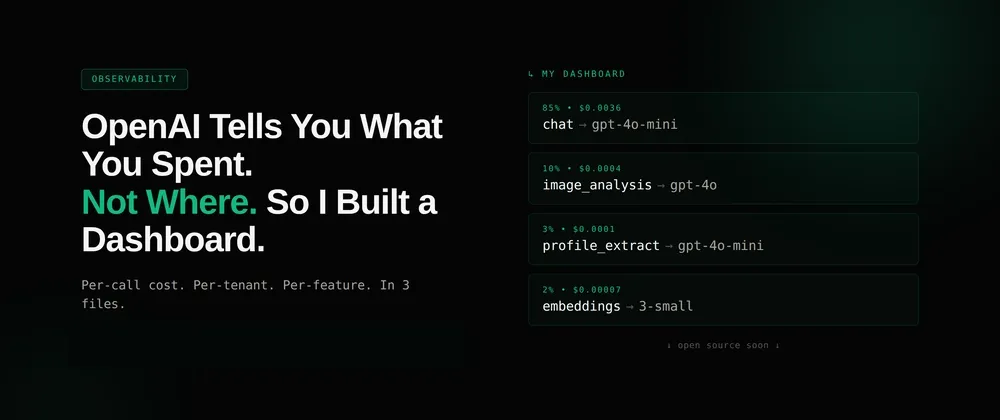
OpenAI 成本追踪仪表盘示意图
一、最炸裂的问题:总账单没变大之前,工程团队其实已经瞎了
OpenAI 官方控制台能看到总消耗、模型维度、Token 用量等基础信息。这些数据适合财务对账,却不等于工程可观测性。
真正上线后,团队需要的是下面这些问题的答案:
|
问题 |
如果没有应用侧日志,会发生什么 |
|---|---|
|
哪个租户最贵 |
只能看总费用,无法识别异常客户或高频使用场景 |
|
哪个功能最烧钱 |
聊天、图片分析、Embedding、摘要提取混在一起 |
|
哪次对话超预算 |
无法回放具体上下文,也无法解释单次成本异常 |
|
失败请求是否仍在计费 |
错误调用可能消耗输入 Token,却没有被业务日志捕获 |
|
延迟和成本是否相关 |
只能猜是模型慢、上下文长,还是工具链阻塞 |
这就是 AI 应用最容易被低估的成本盲区:账单是结果,日志才是因果链。
如果你只看总花费,就像只看数据库每月账单,却不记录慢查询、不记录接口、不记录租户。成本暴涨时,排查只能靠猜。
二、别再直接调 OpenAI:所有请求都必须先进一层成本 Wrapper
第一步不是做漂亮图表,而是立一条硬规则:业务代码不要直接调用 OpenAI SDK,而是统一走一个封装层。
这个 Wrapper 要做五件事:
|
记录项 |
作用 |
|---|---|
|
model |
知道本次调用用了哪个模型 |
|
prompt_tokens / completion_tokens |
计算输入和输出成本 |
|
endpoint |
区分聊天、图片分析、Embedding、资料提取等功能 |
|
tenant_id / conversation_id |
把费用归因到客户、门店、会话或用户 |
|
duration_ms / status / error |
同时记录延迟、成功失败和异常原因 |
一个最小实现可以长这样:
const PRICING = {"gpt-4o": { input: 2.5, output: 10.0 },"gpt-4o-mini": { input: 0.15, output: 0.6 },};export async functiontrackedCompletion(params, meta) {const startedAt = Date.now();const result = await openai.chat.completions.create(params);const durationMs = Date.now() - startedAt;const usage = result.usage;const price = PRICING[params.model] ?? PRICING["gpt-4o-mini"];const cost = usage? (usage.prompt_tokens * price.input +usage.completion_tokens * price.output) / 1_000_000: 0;logApiCallAsync({tenant_id: meta.tenantId,conversation_id: meta.conversationId,endpoint: meta.endpoint,model: params.model,prompt_tokens: usage?.prompt_tokens,completion_tokens: usage?.completion_tokens,total_tokens: usage?.total_tokens,duration_ms: durationMs,cost,status: "success",});return { result, cost, durationMs };}
这里的重点不是代码有多复杂,而是接口边界必须统一。只要还有业务模块绕过 Wrapper 直接调 SDK,仪表盘就会出现盲点。
三、真正值钱的不是“记录成本”,而是把成本切到业务维度
很多人会把成本监控做成一个总额曲线,这仍然不够。AI 成本优化真正需要的是“切片能力”。
建议至少设计这样一张日志表:
CREATE TABLE api_logs (id UUID DEFAULT gen_random_uuid() PRIMARY KEY,tenant_id UUID,conversation_id UUID,endpoint TEXT NOT NULL,model TEXT NOT NULL,prompt_tokens INT,completion_tokens INT,total_tokens INT,cost DECIMAL(10,8),duration_ms INT,status TEXT DEFAULT 'success',error TEXT,created_at TIMESTAMPTZ DEFAULT now());CREATE INDEX idx_api_logs_tenant ON api_logs(tenant_id);CREATE INDEX idx_api_logs_endpoint ON api_logs(endpoint);CREATE INDEX idx_api_logs_created ON api_logs(created_at);
注意这里的 cost DECIMAL(10,8)。AI 调用的单次成本通常是小数美分,如果只保留两位小数,绝大多数调用都会变成 0.00,最后统计完全失真。
这张表不是为了“存更多字段”,而是为了让你能回答下面这些运营级问题:
|
维度 |
能回答的问题 |
|---|---|
|
按租户 |
哪个客户消耗最高,是否需要限额或调价 |
|
按功能 |
哪个功能最烧钱,是否值得继续使用大模型 |
|
按会话 |
哪类对话触发了超长上下文或重复工具调用 |
|
按模型 |
模型迁移后成本是否真的下降 |
|
按错误 |
失败调用是否还在持续消耗 Token |
|
按延迟 |
高成本请求是否同时拖慢响应 |
总额只是数字。能切到业务维度,才是洞察。
四、最容易踩坑的一条:日志写入绝不能阻塞用户请求
成本日志很重要,但它不能比用户请求更重要。
如果每次调用 OpenAI 后都等待数据库日志写入成功,监控系统就会进入主链路。数据库抖动、网络波动、表结构变更,都可能把用户响应拖慢甚至拖挂。
更稳妥的做法是:日志异步写,失败静默降级,必要时再用队列补强。
|
写法 |
风险 |
|---|---|
|
请求链路同步等待日志入库 |
增加延迟,日志库故障会影响用户 |
|
fire-and-forget 异步写入 |
少量日志可能丢失,但主链路稳定 |
|
队列化写入 |
更可靠,但系统复杂度更高 |
早期产品可以先用 fire-and-forget。等到量级上来,再接入队列、重试、批量写入和死信表。不要一开始就把成本监控做成另一个故障源。
五、仪表盘不要炫技,只要能抓住 5 个异常信号
成本仪表盘不需要做成 BI 大屏。第一版只要能看清五类信号就够了:
|
模块 |
应该展示什么 |
触发的行动 |
|---|---|---|
|
总览卡片 |
请求数、Token 数、平均延迟、总成本 |
判断当天是否异常 |
|
功能拆分 |
各 endpoint 的调用量和成本占比 |
找出最烧钱功能 |
|
模型拆分 |
各模型费用、调用量、Token 分布 |
判断是否该降级模型 |
|
租户排行 |
每个客户的成本和请求数 |
做限额、预警和套餐设计 |
|
明细日志 |
单次调用的上下文、耗时、错误 |
定位具体事故 |
真正有用的仪表盘通常很朴素:上面几张统计卡,中间两三个趋势图,下面一张可筛选日志表。它的目标不是好看,而是让工程师在 30 秒内判断问题在哪里。
六、一个典型发现:1% 的图片调用,可能吃掉 10% 的预算
当成本被拆到功能维度后,很多团队会第一次看到一个残酷事实:调用次数最多的功能,不一定是最贵的;调用次数很少的能力,反而可能吃掉大量预算。
以常见 AI 导购场景为例:
|
功能 |
典型模型 |
调用频率 |
成本风险 |
|---|---|---|---|
|
日常聊天 |
小模型 |
很高 |
单次便宜,但上下文过长会累积 |
|
Embedding |
向量模型 |
很高 |
通常稳定,适合批量优化 |
|
用户画像提取 |
小模型 |
中等 |
可异步,可降频 |
|
图片分析 |
多模态大模型 |
很低 |
单次昂贵,最容易被低估 |
这就是为什么“按模型看成本”还不够。你必须同时知道它属于哪个功能,否则只会看到某个模型变贵,却不知道产品哪里在烧钱。
一旦发现图片分析、长上下文聊天、重复工具调用这类高成本点,就可以进一步做三件事:
-
对高成本功能加开关、限额和冷却时间。 -
把可延迟任务移到异步队列。 -
用更便宜模型先做预筛选,只有必要时才调用大模型。
七、上线前直接照抄这份 AI 成本追踪清单
如果你的产品已经接入大模型,建议按下面顺序补齐:
|
优先级 |
动作 |
验收标准 |
|---|---|---|
|
P0 |
所有模型调用统一走 Wrapper |
代码库里没有散落的直接 SDK 调用 |
|
P0 |
记录租户、功能、会话、模型、Token、成本、延迟 |
能定位单次调用费用 |
|
P0 |
成本字段保留 8 位小数 |
小额调用不会被四舍五入吞掉 |
|
P1 |
仪表盘支持日期、租户、功能、模型筛选 |
能快速切片排查 |
|
P1 |
失败调用单独统计 |
能识别无效消耗 |
|
P1 |
每租户每日预算预警 |
异常客户不会拖爆总账单 |
|
P2 |
接业务结果表 |
能算每次成交、注册、转化的 AI 成本 |
成本追踪不是等账单爆了再补的东西。它应该和登录、日志、错误监控一样,属于 AI 产品的上线基础设施。
八、总结:AI 成本失控,通常不是模型太贵,而是你没有归因
很多 AI 产品的成本问题,表面看是“模型价格高”,实际是工程归因缺失。
你不知道哪个租户贵,就无法定套餐。 你不知道哪个功能贵,就无法做模型分层。 你不知道哪轮对话贵,就无法优化上下文。 你不知道失败调用贵,就无法修复浪费。
所以,别再只盯 OpenAI 总账单。总账单是财务视角,成本归因才是工程视角。
真正该做的是给每一次模型调用打上业务坐标:谁发起、为了什么、用了哪个模型、消耗多少 Token、花了多少钱、耗时多久、是否成功。
当这些数据都进了自己的表,你才第一次拥有优化 AI 成本的主动权。
参考资料
-
OpenAI API Pricing: https://platform.openai.com/docs/pricing/ -
OpenAI GPT-4o Model 文档: https://developers.openai.com/api/docs/models/gpt-4o -
OpenAI GPT-4o mini Model 文档: https://developers.openai.com/api/docs/models/gpt-4o-mini