 夜雨聆风
夜雨聆风





Cognee:给 AI Agent 补记忆,这次终于不是再套一层 RAG 了
我刚点进 Cognee 仓库时,先停在那句“6 行代码做 AI memory”。
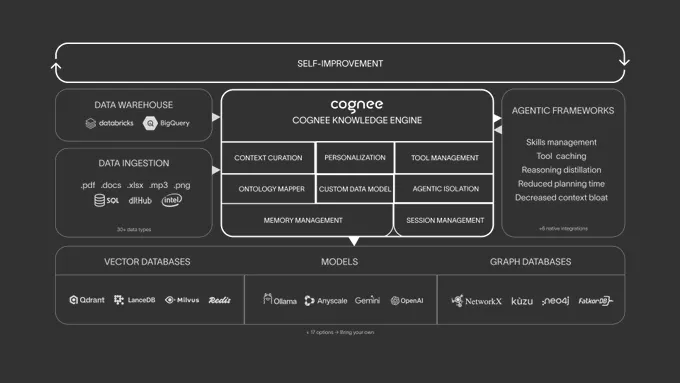
这种话平时看多了,第一反应 usually 都是:又来一个把 RAG 包装一下的项目。可往下翻两眼,味道不太一样。它没有把“记忆”继续当成一堆切碎的 chunk 去塞进上下文,而是把语义检索和关系连接放在一起做,底下同时接向量库和图存储。文档不只是能被搜到,还会和人、事件、主题重新挂上关系。
这类东西,Agent 一上手就能感觉出来差别。
传统 RAG 最烦的不是搜不到,而是搜出来的东西经常只对一半。你问的是“这个人之前答应过什么”,它给你抛回来几段相似文本;你再追问一次,上下文又断了。Cognee 想补的就是这块:把过往对话、文件、图片、音频转写之类的内容先吃进去,再在 Cognify 这一步里拆 chunk、做 embedding、抽实体、建边,最后变成一层可持续更新的记忆。
我更在意的是它把流程抽得很干净。
ECL,Extract、Cognify、Load。名字不复杂,但这套分法挺适合开发者下手:先接数据,再把原始内容整理成结构化知识,最后写进对应的存储后端。你可以把它当成 RAG 的替代品,也可以把它当成一层专门给 Agent 准备的 memory pipeline,后面自己改 chunker、ontology、search type 都还有空间。

还有个细节我看了下,Cognee 没把自己做成只能写 Python 代码的库。
它有 CLI,能直接 add、cognify、search,也能起本地 UI。想全本地跑也行,官方文档和博客都给了 Ollama 这条路。对很多正在折腾本地 Agent、知识库、私有数据接入的人来说,这比“模型多强”更实在。
现在再看 Cognee,会发现它火不是因为“AI memory”这几个字新。
而是很多人已经被上下文膨胀、检索失真、记忆不连续折腾过一轮了,开始接受一件事:给 Agent 补记忆,可能确实不该再只靠向量检索硬顶。Cognee 这套图加向量的做法,至少已经把这件事往能落地的方向推了一步。仓库目前在 GitHub 上已经有 15.9k+ Star。
GitHub地址:topoteretes/cognee