 夜雨聆风
夜雨聆风





Obsidian + AI 知识库是长出来的
DEEP NOTE
知识库是长出来的
——125 篇之后,我才明白知识库不是修出来的
黄晨征 | 全文约 1700 字
我的 Obsidian vault 现在 125 篇。一开始是文件夹丢着,后来加 frontmatter,加索引页,前几天又大改了一次结构。每一次升级都是被现状逼的,不是预先设计的。
手把手搭建自生长的Obsidian + AI 知识库,让每一笔知识都生产复利
这篇讲一件事:知识库不是修出来的,是长出来的。AI 让”长出来”成立——它把结构升级的成本打到接近。

● ● ●
01 — 大佬的方案只是底层逻辑
是方向,不是终极答案
Karpathy 的 LLM Wiki Gist、nashsu 的 llm_wiki、国内一堆 LLM Wiki 实践——是方向,不是终极答案。
我拿 Karpathy 那篇对照过自己搭的:raw + wiki + schema 三层、Ingest + Query + Lint 三操作、CLAUDE.md 当 schema——大方向一致。但他的细节我用不上,我自己的细节他没讲。
判断标准是这两条:
底层逻辑不变 — 本地 Markdown、wiki link 双链、AI 持续维护、规则文件做 schema
可变的 — 目录怎么切、字段叫什么、流程怎么跑、什么时候体检
调整方法是跟 AI 共同商量。不是问”该怎么搭”,是把现状和痛点抛给它,让它根据实际情况推一套。跑一阵,不顺再改。
● ● ●
02 — 关键前提
升级成本被 AI 打到接近零
前面所有判断,建立在一个前提上——结构改造的成本被 AI 打到接近零。
70+ 文件改一遍,10 分钟级。具体在做什么:
19 篇旧剪藏 — 一次性补 frontmatter + AI 摘要 + 双向关联,每篇平均 30-60 秒
6 个课程文件 — 回写新素材引用,本来是手动整理一晚上的活
体检报告 — 全 vault 跑一遍,断链 / 残留 / 孤儿 / 合规违规一次扫完
以前是月度甚至季度的工程,现在是一次对话。
老实说,前两年同样的工作量,我可能会推到下个月,推到下个季度,最后推没了。
这件事直接改写了知识库的搭建逻辑:
过去 — 因为升级费时,所以要预先设计完整结构,避免返工
现在 — 因为升级便宜,所以不预先设计,等内容长出来再调
“等到那时候再说”突然就成立了——”那时候做”和”现在做”,代价一样。
● ● ●
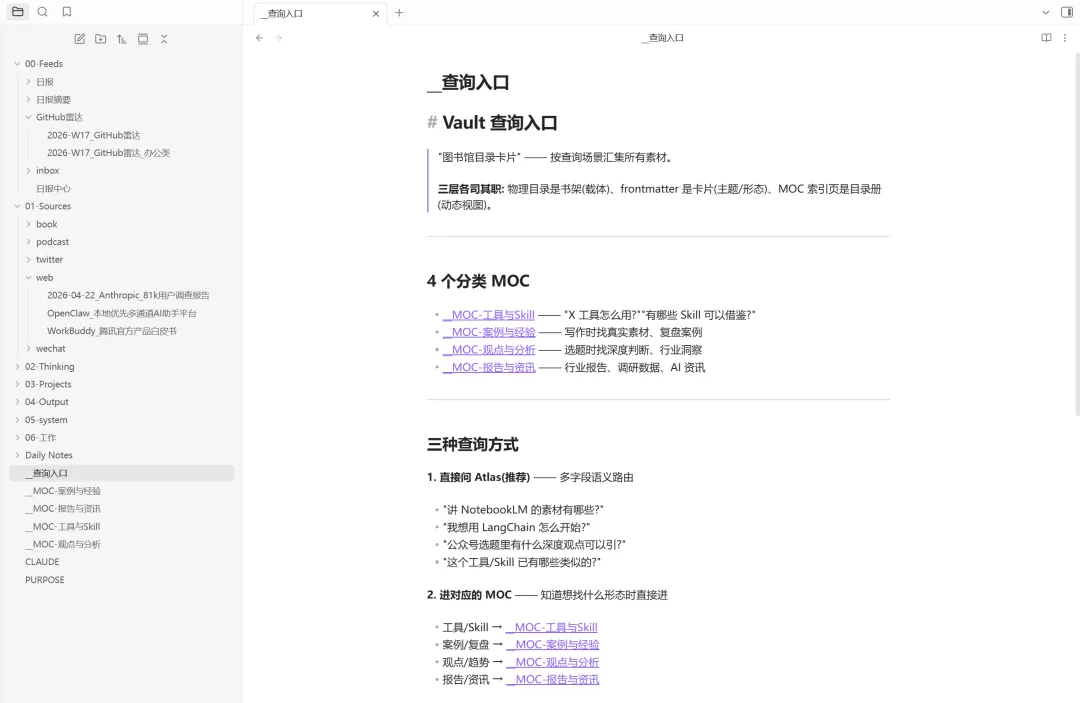
05 — vault 会自己生长
课程是主线,但 vault 会反过来推动课程
更值得记录的是另一件事:vault 在自己生长。
我一开始是围绕课程搭的——为”马桶上的 AI 课”收素材、做关联。但内容多了之后,里面冒出来一些没刻意做但已经长得很厚的方向:
AI 时代的 PPT 这一簇 — PPT skill 横评、HTML 是新的 PPT、PPT-Master 拆解——够独立成一个”AI 时代怎么做演示”专题
AI 组织协作这一簇 — 14 位 agent 实战者掏家底、CEO 是最先被替代的岗位、agent 也有办公室政治——够独立成一个研讨方向
这两个方向不是设计出来的,是被三件事显出来的:
① wiki link 双链 — 每次入库新素材,顺手在 related 里 link 旧笔记。link 攒多了,某一天打开 MOC 索引页,会发现某个分类下密度突然变高——那就是新主题在成形
② frontmatter keywords 重叠 — 同一组 keyword 反复出现,本身就是新主题在成形
③ 索引页归类时的违和感 — 某篇笔记往现有索引里塞,塞不进去——它不属于任何旧分类,它在长出新分类
机制就这三条。课程是主线,但 vault 会反过来推动课程演化。这是我没预料到的。
● ● ●
04 — 落地路径
如果重来一遍,该怎么走
5–10 篇 — 单文件夹丢着,看效果
30 篇 — 加 frontmatter,基本字段就够(source / tags / keywords / related)
100 篇 — 加索引页 + 体检规则
300 篇 — 一次大升级,让 AI 帮你重排
500+ — 再升级,那时候再说
每一步都是被现状逼出来的,不是预先设计的。
知识库不是修出来的,是长出来的。AI 让它”长得出来”。
● ● ●
下次有人问”知识库怎么搭”
别搭。
先丢着。
等它告诉你它需要什么。
黄晨征 | 2026.05.01 | 全文约 1400 字
部分内容由 Atlas AI助手辅助生成