 夜雨聆风
夜雨聆风





深度干货 | 为什么你的AI总在说废话?优化你的AI工具效率
深度干货 | 为什么你的AI总在说废话?优化你的AI工具效率
在这个“万物皆可AI”的时代,很多人都经历了这样的心态转变:从刚接触AI时的极度兴奋,到使用几次后因为AI“听不懂人话”、“满嘴废话”而感到深深的失落。
这其实是一个普遍的误区:我们错把大语言模型(LLM)当成了传统的搜索引擎。
你不需要用关键词去迎合它,你需要用工程师的思维去“配置”它。掌握提示词工程(Prompt Engineering),就等于掌握了使唤这些超级大脑的遥控器。
今天,我们将彻底抛弃那些表面花哨的技巧,直击底层逻辑。这篇文章包含大量硬核干货与高阶实操案例,建议先收藏,再配合键盘进行实操。

一、 重新认识提示词:大模型的“上下文控制术”
大模型的本质是“概率预测机”,它根据你给出的上文,预测最可能出现的下文。如果你的输入(Input)模糊不清,它的输出(Output)必然是平庸的套话。
核心思维转变:从“提问者”转变为“项目经理”。不要问AI“你能帮我做这个吗?”,而是直接下达指令:“你现在的角色是X,你需要利用Y背景信息,完成Z任务,并以W格式输出给我。”
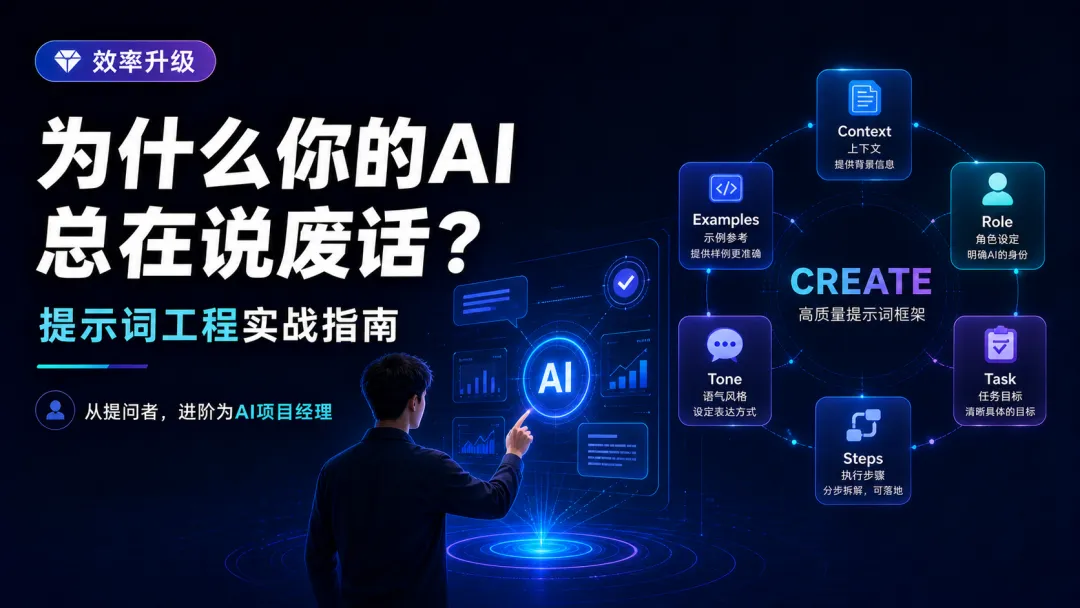
这里引出我们今天的高阶提示词框架:CREATE 模型。
-
• C (Context) 业务背景:事情的前因后果。 -
• R (Role) 专家角色:让AI带入特定视角的行业模型。 -
• E (Explicit Task) 明确任务:具体要解决的问题。 -
• A (Action Steps) 执行步骤:限制AI的发散,规定工作流。 -
• T (Tone & Format) 语气与格式:输出的排版、字数、语气。 -
• E (Examples) 样例参考:Few-shot(少样本)提示,直接给参考模板。 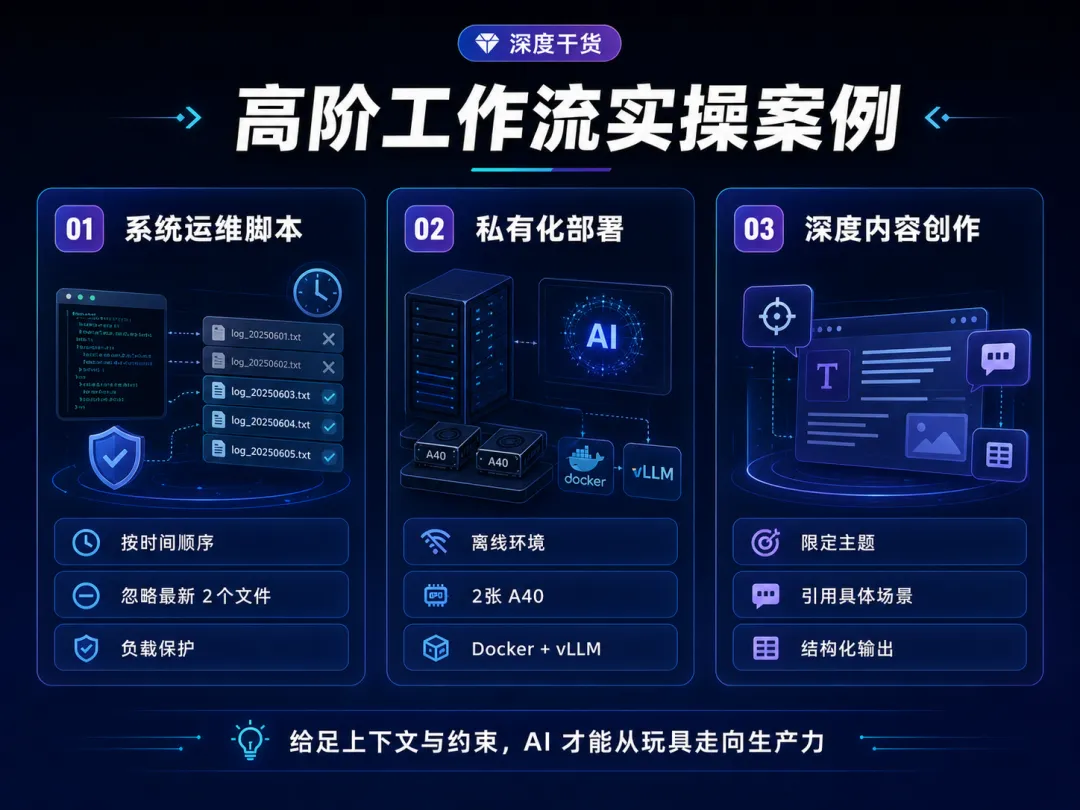
二、 告别玩具级应用:高阶工作流实操案例
理论必须落地。我们直接进入那些真正能大幅提升生产力的硬核场景。
场景 1:复杂系统运维与自动化脚本开发
许多开发者在使用AI写代码时,常常抱怨AI写的脚本有逻辑漏洞或者不符合实际环境。这往往是因为约束条件给得不够。
-
• ❌ 低效提示词: 帮我写个发文件的Shell脚本。
-
• ✅ 高效提示词(CREATE框架应用): 作为一名资深基础架构运维工程师(Role)。我目前需要处理服务器集群间的网络抓包文件同步。我们需要将本地不断生成的pcap抓包文件,通过socat工具分发到其他服务器(Context)。
请帮我编写一个Shell脚本(Task)。核心逻辑与约束条件如下(Action Steps):
请输出完整的Shell脚本,并在关键逻辑处加上中文注释,不要多余的废话(Format)。
-
1. 遍历目标目录,按文件创建的时间顺序,优先处理最老的pcap文件。 -
2. 关键机制:为了防止文件正在写入中导致传输损坏或冲突,必须在分发时严格忽略最新生成的2个文件。 -
3. 包含系统负载(Load Average)检测机制,当系统负载超过安全阈值时,脚本需自动暂停发送,等待负载下降。
💡 解析: 明确了使用 socat、强调了“忽略最新2个文件”的痛点逻辑、加入了负载保护。这样的提示词生成的代码,可以直接进入生产环境测试,而不是玩具代码。
场景 2:AI大模型私有化部署与架构设计
面对技术攻坚,AI不仅能写代码,还能做方案设计和排错。
-
• ❌ 低效提示词: 怎么离线安装Qwen大模型?
-
• ✅ 高效提示词: 你现在是一名AI基础设施架构师。我负责在完全隔离的内网(air-gapped)环境中部署大语言模型服务。
硬件与环境背景:我们拥有2张 NVIDIA A40 显卡(请注意,是A40,不是A10),操作系统为 CentOS,使用 Docker 进行容器化管理。任务要求:请为我提供一份部署 Qwen 或 DeepSeek 模型的详细方案。
重点解答以下问题:
请以结构化的技术文档格式输出,包含必要的终端命令。
-
1. 如何基于 vLLM 框架在这两张A40显卡上实现最高效的分布式推理配置? -
2. 在纯离线环境下,模型权重文件和 Docker 镜像的打包、导入标准流程是什么?
💡 解析: 纠正了常见的硬件误区(明确A40而非A10),指定了技术栈(Docker, vLLM),并限定了“内网离线”这个苛刻的上下文。AI会立刻收敛其发散性,提供精准的工程实施步骤。
场景 3:高质量深度内容的结构化产出
无论是公众号推文、行业分析还是读书笔记,只要掌握方法,AI都能提供极具深度的见解。
-
• ❌ 低效提示词: 写一篇1984的读后感。
-
• ✅ 高效提示词: 作为一名严肃文学评论家和资深媒体人。请撰写一篇关于乔治·奥威尔《1984》的深度文学分析长文。
文章受众:关注人文社科与思想深度的微信公众号读者。核心探讨主题:不限于表层的监控,请深挖‘语言控制(新话)如何重塑人类认知边界’以及‘现代社会中的隐性异化’。排版要求:
-
1. 采用引人入胜的开篇。 -
2. 正文分为3-4个小标题,逻辑层层递进。 -
3. 必须引用书中的具体设定或经典场景进行佐证,避免空洞说教。 -
4. 语言风格需兼具学术的严谨性与新媒体的易读性,富有批判性思考。
💡 解析: 通过限定核心探讨主题和排版要求,避免了AI生成中小学生式的“读后感”,直接拉升了内容的思想维度和专业感。
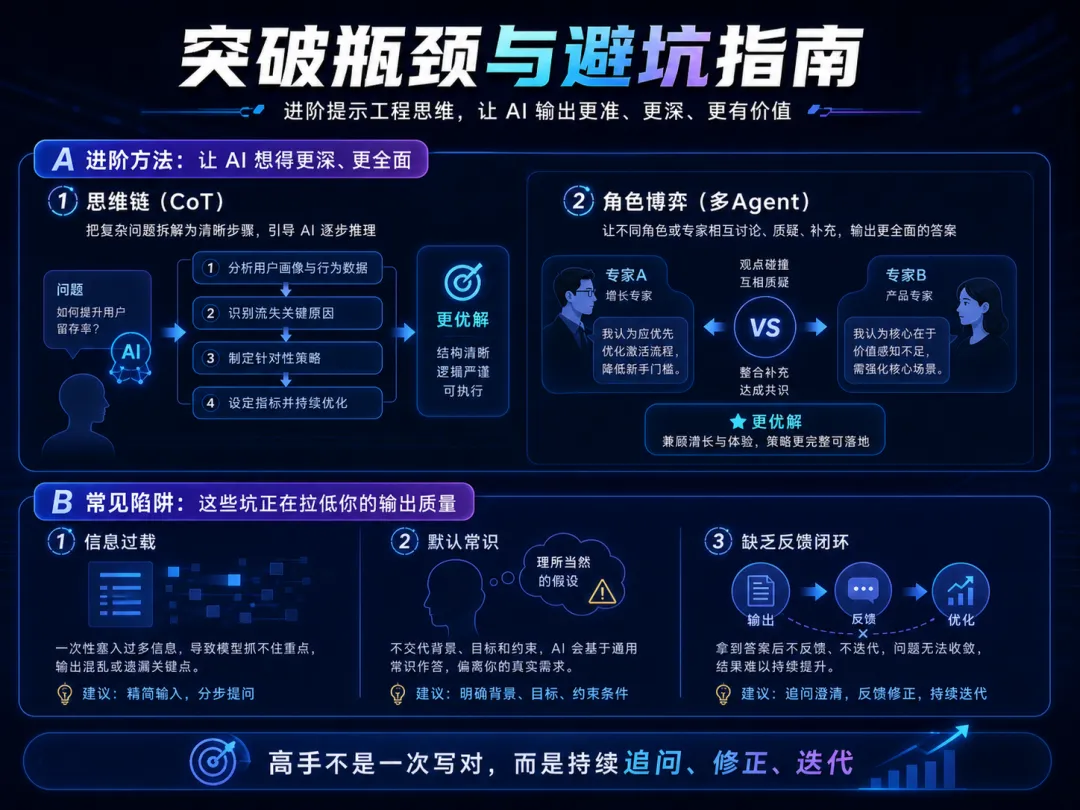
三、 突破瓶颈:Prompt Engineering 高阶思维
当你的应用进入深水区,普通的指令可能不够用了,你需要掌握以下两个学术界公认的有效技巧:
1. 思维链(Chain of Thought, CoT)——“请一步步思考”
面对复杂的逻辑推理、架构设计或数据统计时,直接要结果往往会出错。在指令末尾加上一句 “请一步步进行推理(Let’s think step by step)”。
这会强制AI把计算和推理过程外显出来,极大降低“幻觉”和错误率。例如在设计复杂的“基于权重的API轮询策略”时,先让AI写出权重计算公式,再让它输出架构图或代码。
2. 角色博弈(多Agent对话模拟)
遇到棘手难题,可以让AI分饰两角。
请你模拟一场系统设计评审会。角色A是激进的后端开发,主张使用最新的中间件;角色B是保守的运维总监,强调稳定性和容灾。请针对‘引入高可用缓存方案’进行多轮辩论,最后总结出一个折中的最优解。
四、 避坑指南:为什么你的AI会翻车?
-
1. 信息过载与上下文遗忘大模型的记忆(Token)是有限的。在一个对话框里聊得太久,它会忘记最初的设定。建议: 一个对话框只处理一个具体的项目。开启新任务时,果断新建对话(New Chat)。 -
2. 默认了“常识”你所在行业的黑话和常识,AI不一定知道。不要吝啬给背景信息。 -
3. 缺乏反馈闭环第一次输出不完美是常态。高阶玩家会花80%的时间去“追问”和“修正”。例如指出:“你刚才给出的正则匹配规则忽略了空字符的情况,请修正这段代码。”
五、 结语:人机协作的新范式
熟练掌握提示词,并不是为了向机器妥协,而是为了更好地将我们大脑中模糊的、非结构化的创意,转化为机器可以高效执行的结构化工程。
工具的上限,往往取决于使用者的认知边界。当你学会了如何精确地定义问题,你就已经解决了问题的一大半。
希望这篇长文能成为你提升AI生产力的案头手册。开始行动吧,去构建属于你的高效工作流。