 夜雨聆风
夜雨聆风





为什么说现在的 AI 哪怕再聪明一万倍,也通不过“爱因斯坦测试”?
如果你这两年一直在搭 agent,会很容易被一种表面进步带着走:模型会调工具了,context 变长了,workflow 能串十几步了,推理链写得像模像样了,于是大家下意识觉得,剩下的不过是把 token、工具和 orchestration 再堆厚一点。
Demis Hassabis 这场访谈最值得重视的地方,恰恰是他把这层幻觉拆掉了。他不是在否认现在这条路,而是在提醒:今天最缺的不是更花哨的编排,也不是再多几层 prompt 包装,而是让系统真正具备可持续工作的内部结构。换句话说,问题不在 demo 能不能跑通,而在系统能不能在长时间、真实环境、连续任务中稳定工作。
这也是为什么,这场对谈对任何正在做 agent、copilot、工作流自动化、AI infra、AI for Science 的团队都很重要。因为 Hassabis 给出的不是一张更激进的能力曲线,而是一张更接近工程现实的缺口清单:持续学习、真正可用的记忆、长程推理与自省。你会发现,今天大多数系统的 bug,几乎都能落回这三件事上。
一、真正卡住 agent 的,不是“不会调用工具”,而是不会积累状态
Hassabis 对当前范式的判断其实并不悲观。预训练、RLHF、思维链,这些都不是伪命题,反而几乎肯定会进入未来 AGI 架构。问题在于,它们更像基础件,不是整机。现有路线也许能通过渐进创新补齐缺口,也许还要再来一两个真正的大想法,他给出的概率判断是 50/50。
这个表态的含义非常大。因为它把“现在这条路有效”和“现在这条路已经足够”分开了。对做系统的人来说,这相当于在说:你今天看到的高能力输出,并不自动意味着你已经拿到了可交付的稳定系统。
第一个硬缺口就是持续学习。今天大模型上线后的状态,仍然更像一个被冻结的能力快照。你可以在外面给它挂 memory、挂 retrieval、挂 profile、挂 tool trace,甚至挂人工反馈闭环,但这些大多是外插结构,不是系统自己真正吸收、整合、再迁移的能力。你今天教会它一个偏好,明天它不一定真的记住;你今天修复一个错误,下一次它不一定自动避开同一个坑。
这对 agent 开发是一个致命问题。因为长期任务的价值,从来不在于第一次调用能不能成功,而在于第二十次、第二百次交互之后,系统有没有比第一次更懂环境、更懂用户、更懂约束。一个不会持续学习的 agent,本质上始终在重复 cold start。表面看它会规划、会执行、会用工具,实际上每轮都像重新拼一遍临时 scaffold。
第二个硬缺口是记忆。Hassabis 几乎是直接戳破了行业里最常见的一个错觉:长上下文不等于记忆。把更多历史塞进 context,本质上是把选择问题延后,不是把选择问题解决。真正的记忆不是仓库存储,而是压缩、筛选、抽象、遗忘和精确取回。系统要知道什么是一次性的噪声,什么是长期偏好,什么应该沉淀为策略,什么应该在关键决策点被重新激活。
他说得很具体。百万 token 听起来很大,但如果处理实时视频流,可能只够二十分钟;如果要理解一个人几周甚至几个月的行为轨迹,就远远不够。这个例子对 agent infra 很有杀伤力,因为它说明“把一切都塞进窗口里”只是 duct tape,是临时补丁,不是架构答案。
第三个硬缺口是长程推理。不是生成一段很长的 reasoning text,而是在复杂目标下持续保持约束,不在中途反复回到错路,不因为局部搜索失败就重蹈覆辙。今天很多系统看起来会思考,实际上只是把搜索过程展开成自然语言,并没有形成真正的错误标记、路径剪枝和策略修正。
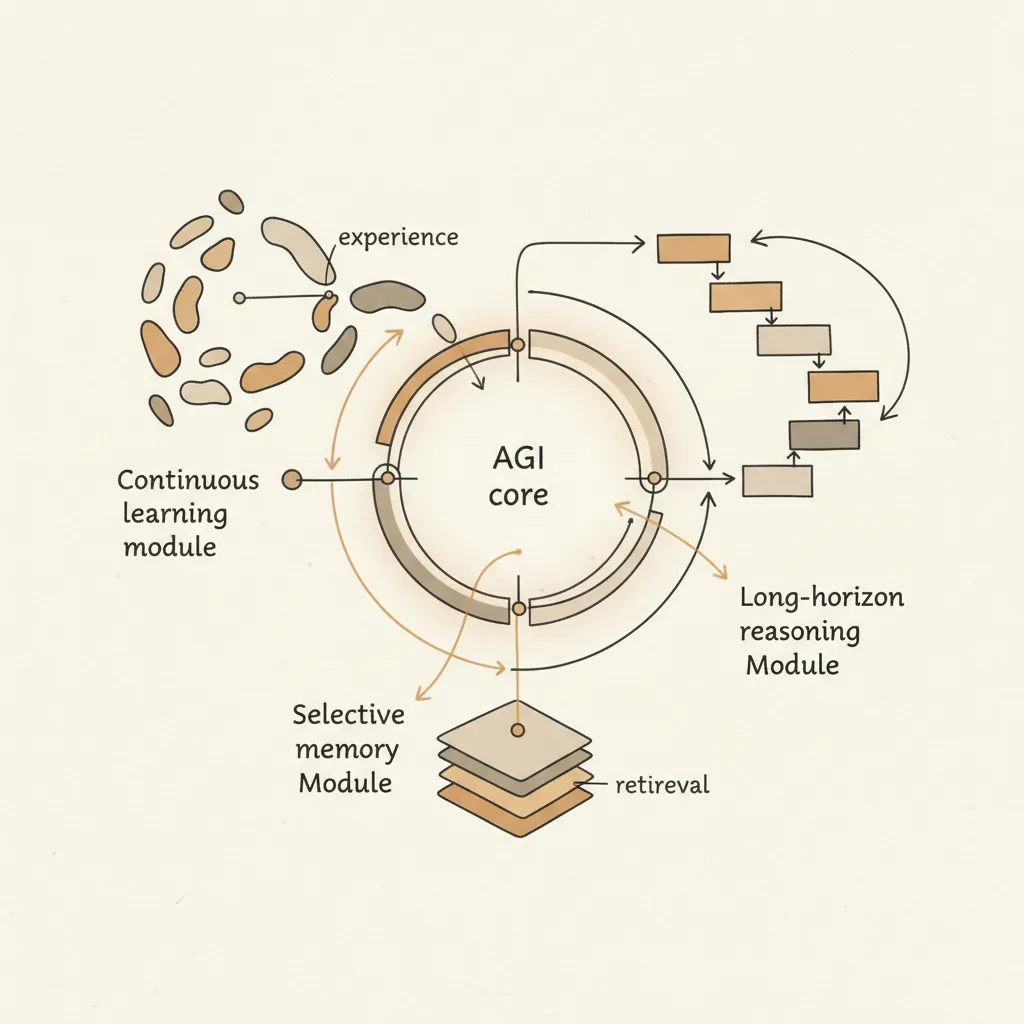
二、为什么大量 agent 还停留在“能演示”,没有进入“能托管”
Hassabis 对智能体的判断,可能是这场访谈里最值得工程团队抄下来的部分。他没有否定 agent,反而明确说,要走向 AGI,必须有主动解决问题的系统,智能体就是路径的一部分。但他同时指出,今天的智能体仍然处在实验阶段,核心原因是它们还不能在具体环境里持续学习和适应,所以还谈不上真正的“fire and forget”。
这句判断其实已经够重了。因为它直接把今天大量 agent 产品从“智能主体”拉回“高维护自动化脚本”的现实位置。很多团队展示的是长流程、多工具、多轮执行、几十小时连续运行,看上去像自主系统;但 Hassabis 追问的不是它跑了多久,而是投入产出比是不是成立。
他说自己看到很多人放出几十个智能体跑四十个小时,但还没有看到足够多的输出能证明这种投入值得。这句话很像在给整个 agent 赛道做 ROI 审计。真正稀缺的从来不是把并行任务数堆上去,而是能不能在成本、延迟、失败率、人工兜底、结果质量之间形成正回报。
这背后的结构性原因,还是持续学习和记忆缺失。一个不能从环境中吸收经验的 agent,本质上更像“每次被重新实例化的高性能实习生”。它可以完成局部任务,但很难随着项目推进逐步形成工作上下文、偏好模型和错误历史。于是你必须反复补 prompt、补 guardrail、补 evaluator、补人工审批。表面是 agent 在工作,实际是人类在给一套脆弱系统不断铺轨。
所以今天很多架构的真实瓶颈,并不是 tool calling 本身,而是缺乏跨 session 的工作记忆、缺乏能沉淀经验的状态层、缺乏把错误转成后续策略修正的反馈回路。只要这几层不成立,agent 再会调用工具,也只是把“会行动”伪装成“能交付”。
三、上下文窗口、思维链、蒸馏和多模态,都在说明什么
Hassabis 在访谈里给了几个很值得放到系统设计文档里的观察。
先说记忆。他把“把所有东西都塞进上下文窗口”形容成“用胶带糊住的临时方案”。这几乎可以视为对当下主流 memory hack 的一针见血评价。上下文窗口当然重要,但它更像高速缓存,不是长期记忆本身。只要系统还不会做压缩、分层、检索和遗忘,context 再大也只是把成本往后推。
再说推理。他提到自己会用 Gemini 下棋,发现模型能意识到某一步是错棋,兜一圈找不到更好方案,最后又回去走那步错棋。这不是一个孤立笑话,而是今天很多 reasoning system 的典型病灶:它能展开过程,但不会对错误路径形成硬约束,也缺乏真正的自省层。Hassabis 把这称作“锯齿状智能”,也就是某些高难任务能惊艳,换个问法却在基础问题上突然掉线。
这也是为什么他强调,自省不是哲学问题,而是工程问题。系统能不能监控自己的思维链进展,能不能在中途介入修正,能不能终止错误循环,能不能把失败变成下一次可迁移的经验。这些能力如果缺失,再长的推理链也可能只是更昂贵的绕远路。
访谈里另一条重要线索,是 AlphaGo 和 AlphaZero 时代的方法正在回归。Hassabis 明确提到,Google DeepMind 正在重新审视蒙特卡洛树搜索等旧想法,并尝试在当代基础模型规模上重新应用。这非常值得注意,因为它意味着未来几年真正有效的突破,未必来自继续把生成做得更像人,而可能来自把搜索、规划、强化学习、经验回放、结构化推理重新嵌回基础模型栈。
同样值得保留的是他对小模型的判断。蒸馏让小模型越来越接近前沿模型,Flash 类模型可以逼近前沿能力,成本却低得多。Google DeepMind 的判断是,前沿模型发布半年到一年后,同等能力就会出现在边缘级小模型上。背后的商业逻辑也很清楚:Google 有十几个十亿用户级产品,搜索里的 AI Overviews 和 AI Mode、Gemini 应用、YouTube、Maps,都要求高效率、低延迟、低成本服务,这种规模压力反过来推动了小模型工程。
他还给出了一种非常现实的系统形态:未来可能是本地小模型处理日常任务,比如音频和视频流,只在必要时调用云端前沿模型。这种“本地 + 云端”的分层架构,对隐私和安全尤其重要,家用机器人等场景会很依赖它。
多模态也是类似逻辑。Hassabis 认为 Gemini 从一开始按多模态方式训练,这种早期更难、长期更值的选择,正在显现优势。Gemini 在语音直连模型和工具调用方面被认为是当前最深的系统之一;世界模型生成器 Genie 建立在这种多模态能力之上,对机器人方向很关键;Waymo 也已经在使用 Gemini 相关技术。换句话说,这不是单点 feature,而是为了让通用模型真正理解物理世界而做的长期下注。
四、真正高价值的突破,为什么会出现在科学和专用系统协同层
如果说前半场访谈在讲 agent 和 AGI 的系统缺口,那么后半场其实在给“什么样的系统更可能留下长期价值”一个更具体的答案。
Hassabis 谈创造力时给了两个尺度。第一个尺度很接地气:他现在半小时就能做出 Theme Park 的原型,而 17 岁时要花六个月。这说明工具层生产力已经发生了巨大跃迁。但他马上追问:如果工具已经这么强了,为什么还没有一个靠 vibe coding 做出来的爆款作品卖出一千万份?他的判断是,缺的可能是 craft 和 soul,也就是品味、执着和更高阶的结构创造力。
第二个尺度更狠。他说 Move 37 级别的创造力还不够,关键不是能不能下出一步妙手,而是能不能发明围棋本身。顺着这个标准,他提出了著名的“爱因斯坦测试”:用 1901 年的物理学知识训练系统,看它能不能走到 1905 年的狭义相对论。这测试的不是高分解题,而是真正产生新结构、新解释和新问题的能力。
他坦白说,自己还没看到任何真正重大的 AI 科学发现。Google DeepMind 有 Co-Scientist 这样的通用科学推理系统,也有在基础 Gemini 之上增加能力的 AlphaEvolve,但真正的根节点突破仍然罕见。不过他也给了非常清晰的工作框架:像 AlphaFold 那样的突破,通常出现在三个条件同时满足的地方,第一是巨大的组合搜索空间,第二是清晰的目标函数,第三是足够的数据或模拟器。
这也是 AlphaFold 至今仍然重要的原因。它不只是一次模型胜利,而是一个“通用模型 + 专用系统”架构的标志性样板。Hassabis 甚至直接把未来形态说透了:不会是一个超级大模型吞掉一切,更可能是 Gemini 这样的通用模型负责理解、编排和调用,AlphaFold 这样的专用系统在某个高难度垂直领域提供深能力。如果把蛋白质折叠知识直接塞进 Gemini,反而会伤到它的语言能力。
沿着这条线,他还提到 Isomorphic Labs 正在把 AlphaFold 之外的相邻生物化学和化学能力做起来,设计具有正确性质的化合物,而且“很快会有重大公告”。对于虚拟细胞,他给出的时间表大约是 10 年,当前瓶颈不在想象力,而在数据,尤其是无法在不杀死细胞的情况下对活细胞进行纳米级无损成像。静态分辨率已经很高,但动态信息仍然缺失。
五、这场访谈给系统团队最实际的提醒,是重写路线图
Hassabis 最后的创业建议,表面上是在讲深科技,实际上也适用于今天所有在搭 AI 系统的人:如果你的 AGI 时间线是 2030 年,而很多项目周期本身就接近十年,那么 AGI 会在你的旅程中途出现。你不能把这件事当背景噪音,而要从现在就写进技术路线和商业计划里。
这句话翻译成系统语言就是:你今天做的东西,到那时是被更强的通用模型抹平,还是会成为通用模型必须调用的专用层?你是在造一个薄薄的包装壳,还是在造一个与真实环境、专业工作流、垂直数据、物理约束深度绑定的能力节点?
这也解释了为什么他一方面继续押注 Gemini 这样的前沿模型,另一方面又把大量精力放在 AlphaFold、Isomorphic Labs、Gemma、多模态、机器人、Waymo 这些不同层级的系统上。Gemma 的开源也不是随手为之。Hassabis 明说过,开源世界里需要 Western stacks,而中国模型目前在开源上非常强;同时,Google 需要在 Android、眼镜、机器人等设备上运行模型,既然部署到设备端后权重本来就会暴露,不如直接在 Nano 级别采用开源策略。
把这些线索放在一起看,这场访谈真正想说的,也许不是“AGI 何时到来”,而是“别把表层能力误当成系统成熟度”。上下文窗口变长,不代表记忆成立;workflow 能跑,不代表 agent 可托管;思维链更长,不代表推理更稳;模型能在单点任务上惊艳,不代表它已经能提出新的科学问题。
对今天的系统团队来说,真正该重算的不是 benchmark 上多了几分,而是路线图的优先级:有没有持续学习层,有没有真正的记忆组织,有没有自省与纠错回路,有没有能沉淀经验的状态架构,有没有把通用模型和专用系统分层协同,而不是粗暴堆成一个更长的调用链。
如果这些问题不解决,行业会继续生产越来越能看的 demo;如果这些问题开始被认真解决,agent 才有机会从“会演示的生成机器”真正跨进“可交付的工作系统”。这大概就是 Hassabis 这场访谈最重要的价值:它没有给出一个更热闹的未来,而是给出了一份更诚实的系统缺口清单。
🎁后台回复「Chat」,可领取特供Plus优惠券或者kicode中转额度,先到(优惠额度越高)先得。
ChatGPT Plus订阅优惠使用方法,参考: 2026年5月保姆级教程:国内如何注册并升级 ChatGPT Plus(全流程图解)
Cladue/Codex 最性价比使用方式,参考:2026 保姆级教程:国内如何配置并使用codex(全流程图解)
对文章中提到的操作/信息等感兴趣,可加:
