夜雨聆风
夜雨聆风





从“散点工具”到“科研驾驶舱”:AI如何驱动临床研究全流程自动化?
在过去十年的数字化浪潮中,临床医生的桌面变得越来越挤:
数据采集用一套系统,病历结构化找一个插件,统计分析靠几个学生手动导表,论文润色再求助于各类翻译网站。这种“拼多多式”的科研路径,本质上是“散点式工具”的低效堆叠。每一个工具之间都隔着一道厚厚的“数据墙”,医生不得不充当那个搬运数据的“人体搬运工”。
那么,在 2026 年,当我们谈论“科研自动化”时,我们谈论的究竟是什么?是更快的算法吗?不,是像“特斯拉驾驶舱”一样的全流程逻辑集成。

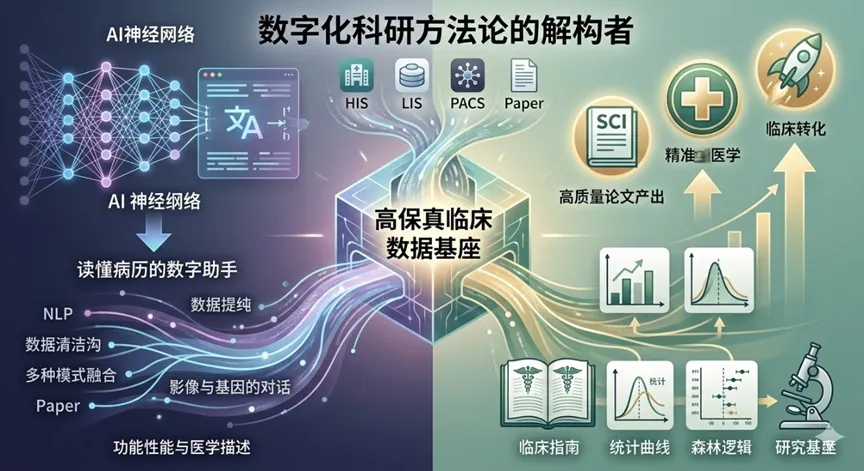
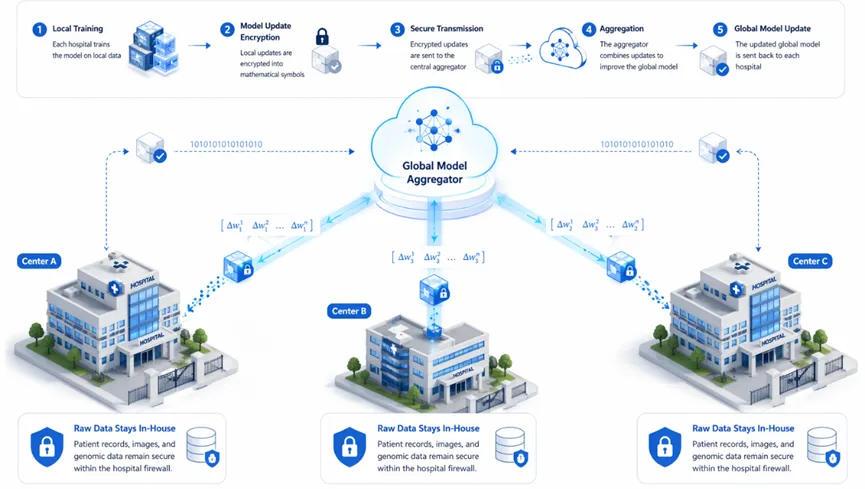
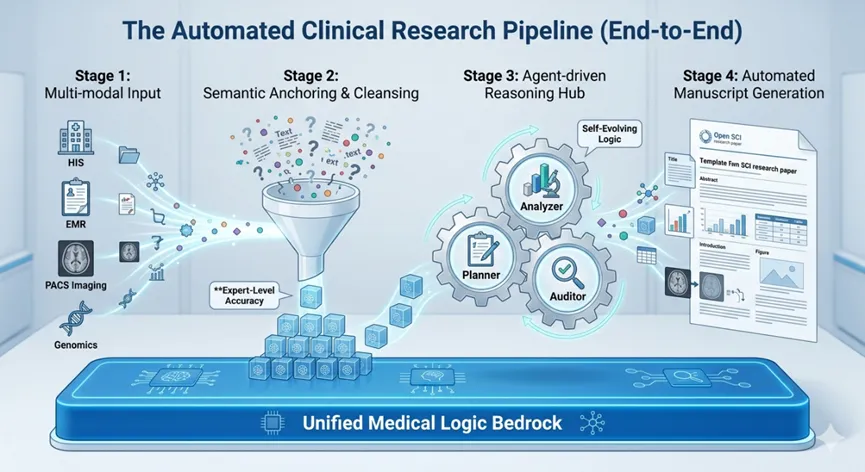
驱动全流程自动化的“三层架构”
要实现从“数据输入”到“论文产出”的自动驾驶,靠的不是单一功能的增强,而是底层医学语义的彻底贯通。其核心技术逻辑由以下三个维度支撑:
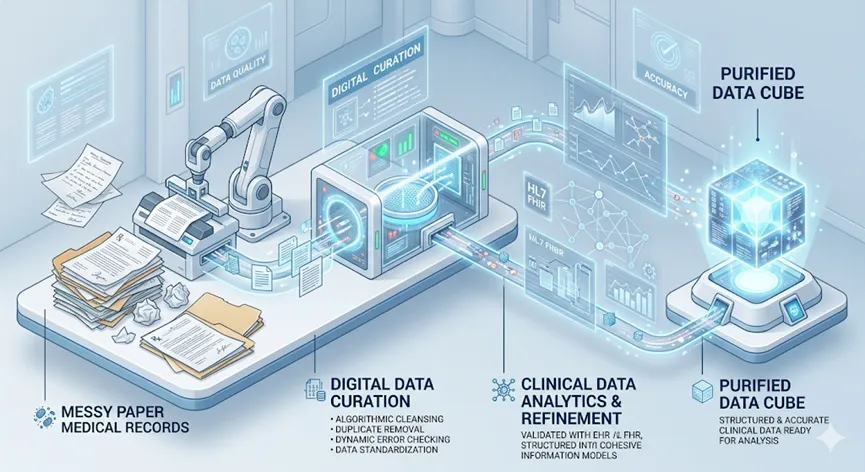
第一层:语义级别的“全模态对齐”(Semantic Alignment) 自动化起步于对“混乱”的终结。通过我们在第三、四期提到的语义定锚技术,系统不再是机械地抓取关键词,而是实现了从 HIS、EMR、PACS 到基因组数据的全模态语义识别。这意味着,当科研需求提出时,AI 能在毫秒内自动检索并对齐所有相关变量,无需人工干预数据清洗过程。这是自动化的“传感器层”。
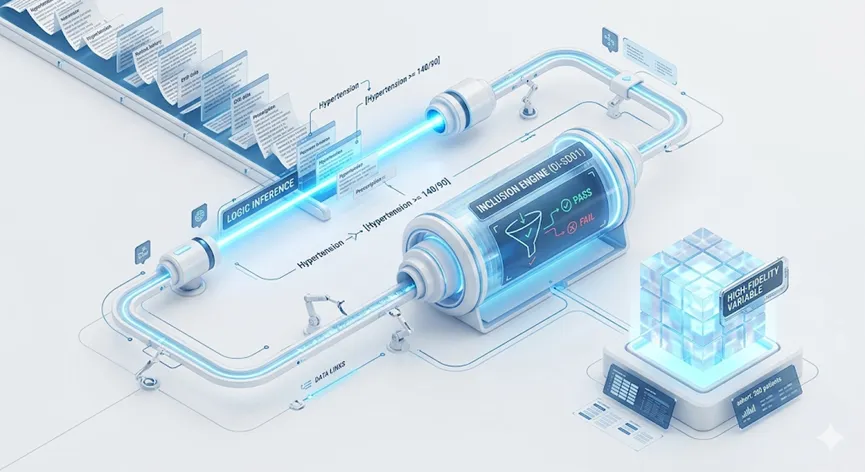
第二层:多智能体驱动的“逻辑推演引擎”(Agentic Reasoning) 这是“驾驶舱”的大脑。我们引入了基于 Multi-agent(多智能体) 协作的分析范式(如前文提到的 BioMedAgent)。在这个架构中,一个智能体负责锁定临床金标准,一个负责执行统计学建模,一个负责质量审计。它们之间不再需要医生手动调参数,而是通过内部的**“自进化逻辑循环”**,自主完成从变量筛选到多因素回归的复杂分析。
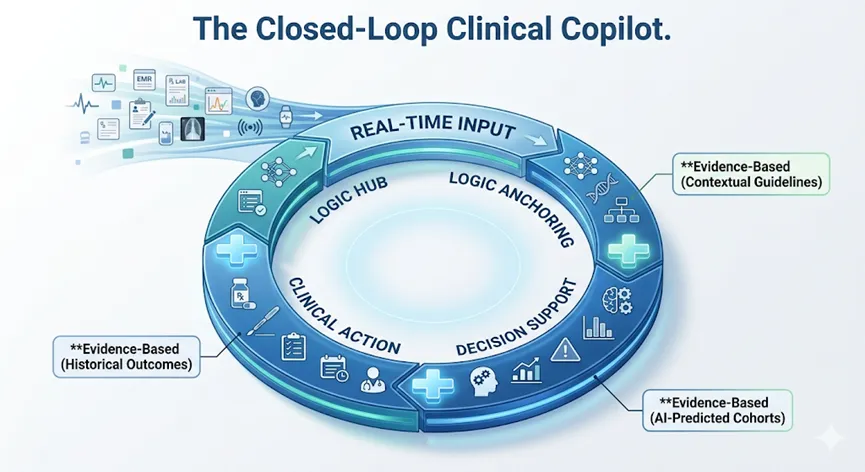
第三层:从证据到稿件的“实时映射”(Evidence-to-Manuscript Mapping) 这是自动化的最后一百米。传统的科研产出是断裂的,而“科研驾驶舱”实现了结果的可视化与叙事化同步。AI 在产出统计图表的同时,会自动溯源至原始病历证据链,并将其翻译为符合顶级期刊逻辑的学术表达。这种映射确保了每一个数据点都具备可解释性,实现了从“数据堆砌”到“科学结论”的端到端自动化。
让灵感,不再止步于琐事
为什么我们如此执着于“全流程自动化”?
因为我们见过太多极具天赋的临床主任,由于被困在琐碎的漏诊检查、逻辑校验和格式调整中,最终磨灭了最初那个惊艳的科学猜想。
AI 的使命,从来不是为了取代人类的思考,而是为了替人类承担那些“确定性”的枯燥,从而腾出空间去承载那些“不确定性”的灵感。
当科研从一门“苦力活”变成一种“驾驶感”,医生的手术刀与思想将不再被繁琐的数据所羁绊。我们所构建的“科研驾驶舱”,就是为了让每一位医护人员在决策的瞬间,都能拥有博览万卷的底气,在科研的航道上,只负责定义终点,而让 AI 处理风浪。
愿未来的临床研究,不再有“跨行如隔山”的无奈,只有“洞察即所得”的快感。

随着本期的收官,我们 3-4 月关于“医疗 AI 祛魅与重构”的系列科普也正式告一段落。文末为您整理了本系列的往期回顾,邀您共同复盘这场从底层数据基座到全流程自动化的技术进化之旅。
感谢观看
JWZY 京卫智云|微信号:lhz_wf5566


长按,识别二维码,了解产品详情