 夜雨聆风
夜雨聆风





AI 科技前沿 | 2026-05-03
0503:瘫痪患者用意念玩魔兽,这不再是科幻
用意念控制机械臂、甚至操控无人机,这事儿离我们还有多远?
看完今天的新闻,你可能会觉得科幻电影的编剧其实挺”保守”的。
Neuralink新突破:瘫痪患者用意念玩魔兽世界

Neuralink这次动真格了。
不是猴子打游戏,而是两位瘫痪患者真正用意念控制了机械臂和无人机。
其中一位甚至还在《魔兽世界》里实现了”无手操作”。
这事儿为什么重要?
它证明了脑机接口不再只是”动动鼠标”那么简单,而是能处理复杂的多维控制任务。
想象一下:一个全身瘫痪的人,通过植入大脑的芯片,不仅能控制机械臂拿水杯,还能在游戏里指挥角色战斗。
这不仅是恢复生活自理,更是在拓展人类能力的边界。
据推文介绍,患者Alex Conley成功用意念控制机械臂并驾驶无人机,另一位患者Jon L. Noble则通过脑信号玩《魔兽世界》。
两年前,这些还只存在于科幻小说里。
说实话,这比任何大模型的参数升级都更让我感到震撼。
参考:https://x.com/XFreeze/status/2050482135874637861#m
Grok 4.3发布:更聪明,还便宜了40%
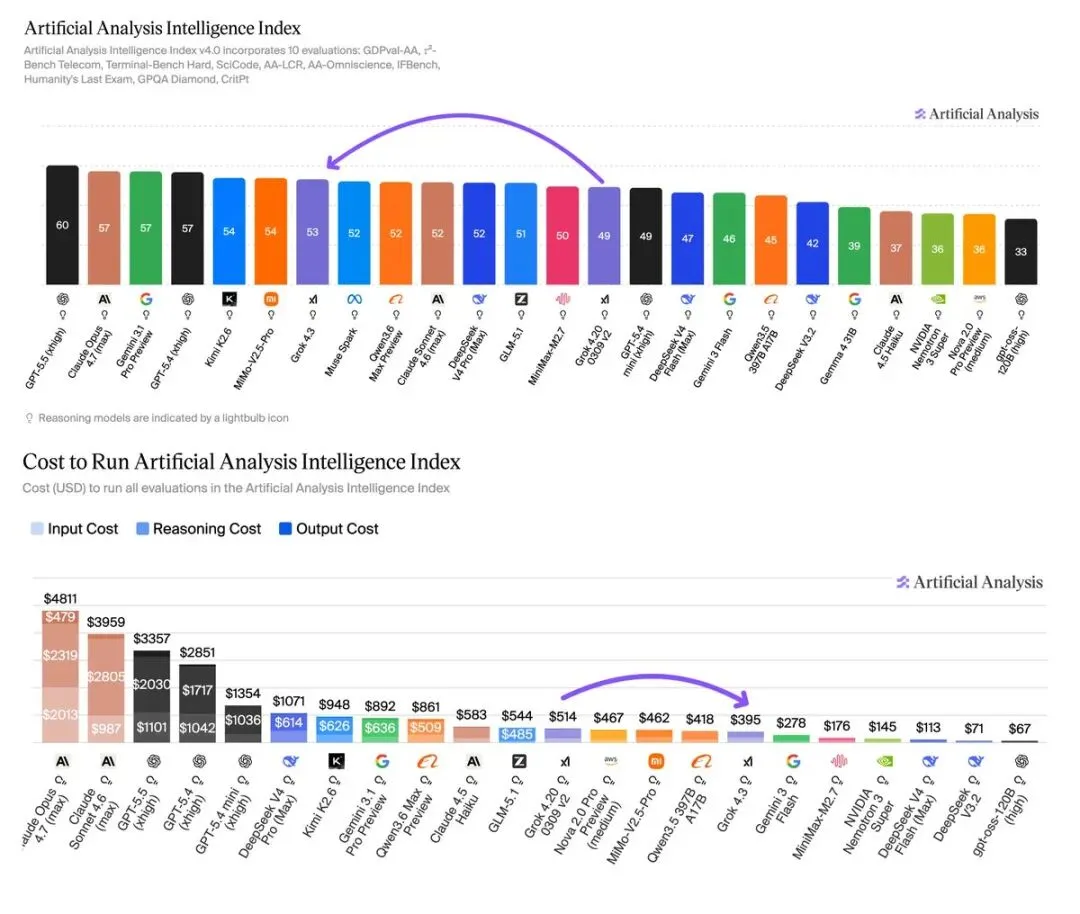
xAI悄悄上线了Grok 4.3。
根据Artificial Analysis的测评,新版本智能指数拿到53分,比上一代Grok 4.20高了4分,刚好压过Claude Sonnet 4.6。
但更有意思的是价格。
输入成本降了约40%,输出成本降了约60%。
这意味着什么?
如果你是重度用户,同样的预算现在能跑接近两倍的量。
大模型的价格战,看来还没打完。
Elon Musk转发评价称其”单位成本智能表现优秀”。
虽然Musk的话要打折听,但这个降价幅度确实有点狠。
参考:https://x.com/ArtificialAnlys/status/2049987001655714250#m
一张3090显卡,跑出95.7%的搜索准确率
本地部署大模型的朋友,这个消息会让你省下一笔钱。
有人在Reddit分享了一个测试结果:
用一张二手市场常见的RTX 3090显卡,配合Qwen3.6-27B模型和开源的LDR搜索框架,在SimpleQA基准测试中达到了95.7%的准确率。
这个成绩是什么概念?
你不需要每月付几百块订阅云端API,在家用消费级显卡就能跑出一个相当聪明的”搜索助手”。
项目作者透露,整个测试在单张3090(24GB显存)上完成,平均每道题耗时约1分54秒。
对于个人开发者和小团队来说,这个性价比相当能打。
参考:https://www.reddit.com/r/LocalLLaMA/comments/1t1n6o8/we_are_finally_there_qwen3627b_agentic_search_957/
Replit十周年:Agent免费玩一天
Replit庆祝成立十周年,搞了个挺大方的活动:
5月2日当天,所有用户可以免费使用Replit Agent。
这个Agent能干嘛?
根据官方介绍,你可以用它零成本搭建网站、做研究、构建内部系统。
平时这可是付费功能。
虽然只有一天,但对于想体验AI编程助手、或者手头有个小项目想快速落地的朋友来说,这波羊毛值得薅。
参考:https://x.com/Replit/status/2050561228171264507#m
OpenAI搞了个”电子宠物”活动

OpenAI在开发者社区发起了一个挺有意思的活动:
用 `/hatch` 命令生成你的专属”Codex宠物”,然后晒出来。
官方会选出10个最喜欢的作品,送出30天的ChatGPT Pro会员。
这事儿本身不大,但能看出OpenAI在努力让Codex这个编程模型变得更”亲民”。
毕竟,谁不喜欢养个独一无二的电子宠物呢?
参考:https://x.com/OpenAIDevs/status/2050275779452588309#m
开源工具Caliber:帮你管理AI助手的”人设”
如果你同时用Cursor、Claude Code、GitHub Copilot这些AI编程助手,可能会遇到一个头疼的问题:
每个工具都要单独配置规则文件,散落在各个项目文件夹里,乱得很。
一位开发者做了个开源工具Caliber,专门解决这个问题。
它能统一管理这些配置文件,支持版本控制和团队共享。
目前项目在GitHub上已经获得888颗星。
对于团队协作来说,这相当于给每个AI助手发了一本统一的”员工手册”。
参考:https://github.com/caliber-ai/caliber
有人用C++从零手搓了一个Transformer
在大家都用PyTorch的时代,有位开发者反其道而行——
用纯C++17从零手写了一个完整的GPT模型。
没有PyTorch,没有BLAS库,没有任何自动微分工具。
张量运算、前向传播、反向传播的梯度推导,全部手写。
最终模型参数量约83万,在CPU上训练76分钟达到验证损失1.64。
这就像在快餐时代,有人坚持自己种麦子、磨面粉、手擀面条。
虽然不一定比餐厅好吃,但这份对原理的执着,值得respect。
参考:https://github.com/Eamon2009/Quadtrix.cpp
LeCun的新动向:离开Meta,自己创业了

图灵奖得主、Meta首席AI科学家Yann LeCun,在2025年底离开了Meta,在巴黎创办了AMI Labs。
据传这家公司在产品还没发布时,估值已达35亿美元。
LeCun的方向很明确:世界模型,而非LLM。
他一直公开批评大语言模型路线,认为LLM无法真正理解物理世界。
现在,他要用实际行动证明自己的判断。
从1987年坚持”已死”的神经网络研究,到今天再次站在主流对立面,这位”AI教父”的剧本,确实够传奇。
参考:https://x.com/CaptainInsightX/status/2050494474212815128#m
Flare-TTS:28M参数的轻量语音模型

一位开发者在Reddit发布了自研的文字转语音模型Flare-TTS 28M。
整个模型在单张A6000显卡上训练24小时完成,参数量仅28M,使用LJSpeech数据集。
作者坦言效果”还是有点机器人味”,但作为个人项目,这个完成度已经很不错了。
对于想在本地部署TTS、又不想跑几个G大模型的朋友,这个28M的小家伙值得关注。
参考:https://huggingface.co/LH-Tech-AI/Flare-TTS-28M
当瘫痪患者能用意念玩游戏、大模型越来越便宜、开源社区越来越强的时候,你最期待AI改变生活的哪个部分?