AI 智能体是怎么记忆的?深度拆解 Hermes Agent 四层记忆架构
我一直有个好奇:AI 智能体(AI Agent)究竟是怎么「记事」的?
带着这个问题,我花了整整一周时间,深入拆解了一个完全开源的智能体项目——Hermes Agent。不同于大多数闭源 AI,Hermes 的代码库、文档、底层逻辑全部公开,可以一层层地剥开来看。
拆解完之后,我最大的感受是:Hermes 根本没有单一的记忆系统。它构建的是一套分层、分工明确的四层记忆架构,这也是它在众多智能体中能脱颖而出的核心原因。
更让我意外的是,这套架构背后的设计哲学,和我们做个人 IP、做一人公司的逻辑高度契合:
今天这篇文章,我打算从底层到应用,用最通俗的语言,把 Hermes 的记忆架构完整拆给你看——不只是技术层面,也聊聊这套逻辑能给我们做事方式带来什么启发。
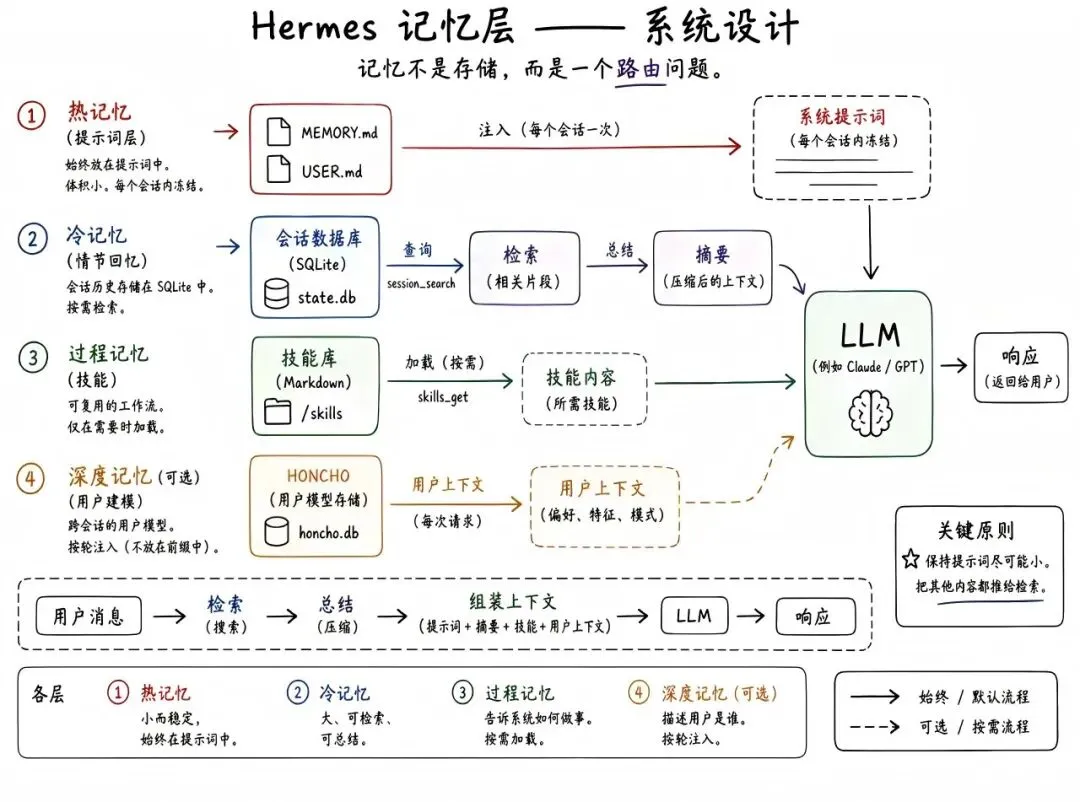
四层记忆架构总览
第一层 固化提示词记忆 MEMORY.md + USER.md,~1300 Token,随身携带的核心笔记
第二层 session_search 会话检索 历史全量存入 SQLite,按需检索压缩,低频回溯不占核心空间
第三层 技能(Skills) Markdown 存储复杂流程与方法论,仅索引入提示词,按需加载
第四层 Honcho 深度建模 可选增强,跨会话建立用户深度画像,从记住对话升级为理解用户
0 理解记忆之前,先搞懂 Hermes 给大模型发了什么
聊记忆系统之前,有一个前置概念必须先讲清楚:系统提示词(System Prompt)。
对大模型来说,系统提示词就是每次对话前发给它的「底层指令集」——告诉它自己是谁、能做什么、要注意什么。Hermes 所有的记忆设计,都围绕着一个核心目标展开:如何把系统提示词组装得又稳、又高效。
Hermes 的系统提示词不是随意堆砌的,而是严格按顺序固定组装,每一个位置都有精确的用意:
⑤ MEMORY.md 快照 智能体核心记忆,常驻,轻易不改动
⑧ 上下文规则文件 AGENTS.md、SOUL.md 等,补充基础行为逻辑
⑨ 日期 / 时间 + 平台信息 适配当下场景,不脱节
这个顺序背后藏着 Hermes 最核心的工程优化目标:针对大模型的「提示词缓存(Prompt Caching)」机制做极致优化。
大模型的提示词缓存,简单说就是:如果系统提示词的前缀部分保持不变,模型可以直接复用上次的计算结果,不需要重新处理,响应更快、成本更低。Hermes 的全部记忆设计,都是在服务这一个目标。
这一个设计决策,直接决定了整个四层记忆架构的形态。理解了这一点,后面的所有设计就都顺理成章了。
1 第一层:固化提示词记忆
Hermes 的第一层记忆,是体积极小、极度精简的常驻核心记忆。所有持久化的核心记忆,都存储在 ~/.hermes/memories/ 目录下的两个纯文本文件里:
存储内容是智能体的「行为准则」:环境配置、工具使用习惯、过往教训、边界限制。可以理解为,这是 Hermes 写给自己的「做事规范」,记下来的都是最关键的经验和底线。字符限制:2200 字符。
存储内容是「用户的核心信息」:偏好、沟通风格、身份背景、高频需求。做过私域运营的人对这个逻辑一定不陌生——记住核心用户是谁,才能精准匹配,不做无用功。字符限制:1375 字符。
两个文件加起来,仅约 1300 个 Token,容量小得惊人。但这正是 Hermes 的刻意为之。
不用追求「什么都懂」,聚焦核心优势,把一件事做到极致——这个逻辑适用于 AI 智能体,也适用于我们做一人公司。
让记忆逻辑与具体模型完全解耦。无需调用模型计算 Token,直接判断字符数是否超限,兼容性极强。这就像我们做目标设定,「每天写 3000 字」比「每天多写一点」更清晰、更易执行。
用 § 符号分隔每条记忆,没有复杂的向量数据库,没有自定义二进制格式,结构简单、易维护、可追溯。越简单的底层,越不容易出错,也越容易长期维护。
不堆砌所有历史信息,只保留最有价值、最高频的事实,把提示词的「黄金位置」留给真正重要的内容。和我们做内容一样:不贪多求全,把最核心的东西放在最前面。
Hermes 明确区分了哪些信息值得保留:
✅ 保留:用户偏好、环境事实、高频错误修正、稳定行为规范
❌ 不保留:任务进度、会话结果、临时待办事项
这是 Hermes 与其他智能体最大的区别之一。复盘不是记录「今天做了什么」的流水账,而是提炼出值得沉淀的经验和需要避免的错误——这个道理,对人对 AI 都成立。
2 第二层:session_search 会话检索
如果说 MEMORY.md 是 Hermes 随身携带的核心笔记,那 session_search 就是它的「历史档案室」——不用时刻翻阅,但需要的时候,能精准定位到想要的内容。
这一层解决的是一个实际问题:历史对话越来越长,全部塞进提示词会拖慢响应速度、推高成本。怎么在不牺牲质量的前提下,按需调取过往记忆?
Hermes 的解法是:所有历史会话完整存储在 SQLite 数据库(state.db)中,支持全文检索。当模型需要回溯过往内容时,走一套五步检索流程:
第三步 加载匹配度最高的会话内容——聚焦最有用的信息
第四步 调用低成本辅助模型对长会话做摘要精炼——去冗余,提核心
这套流程不强迫主模型处理冗长原文,而是用小模型先做一遍信息蒸馏,主模型只接收精炼后的关键内容。成本低,速度快,质量不打折。
同时,当会话过长、提示词空间不足时,Hermes 会触发对话压缩,但压缩前会先执行一步「记忆冲刷(Memory Flush)」。
流程是这样的:先给模型发送一条专项指令——「会话即将压缩,请优先保存用户偏好、修正建议、重复模式,而非具体任务细节」;然后单独调用一次模型,仅开启 memory 工具;模型把关键信息写入 MEMORY.md 后,再压缩对话。
这个设计的精妙之处在于:先固化「值得沉淀的经验」,再清空「不需要保留的过程」。核心不丢,负担卸掉,轻装进入下一段会话。
3 第三层:技能(Skills)
大多数 AI 记忆系统只关注「语义记忆」——记住事实、偏好、人物、背景。但 Hermes 多做了一层:过程记忆(Procedural Memory)。
换句话说,前两层解决的是「知道什么」,第三层解决的是「会做什么」。
技能文件存储在 ~/.hermes/skills/ 目录下,以 Markdown 格式保存,记录的是复杂流程、问题修复方案、优化后的工作方法、可复用的操作逻辑——相当于 Hermes 自己总结出来的「工作手册」,遇到同类问题时直接套用,不需要重新摸索。
关键在于调用逻辑:Hermes 绝不把全量技能塞进提示词。提示词里只放一个「技能索引」,需要执行时再按需加载具体的技能内容。
明确知道自己会什么,需要的时候再调用对应的技能——不贪多,不内耗。这和我们做一人公司的逻辑完全一致:你不需要时刻背着所有技能前行,需要时精准调取就够了。
这一层是 Hermes 能实现「自动化执行、自主迭代优化」的核心。它不只是一个会聊天的 AI,而是一个有自己方法论、能不断积累和改进的工作系统。
4 第四层:Honcho 深度建模
前三层都是 Hermes 的本地能力。第四层是它的「云端扩展」——Honcho,一个跨设备、跨平台的用户深度建模系统。
如果把前三层比作一个人的本地笔记本,Honcho 就是跨设备同步的长期用户档案:不只记住用户说过什么,而是真正理解这个用户是谁、在乎什么、如何思考问题。
它的集成方式非常精妙,完全不破坏之前建立的缓存稳定性:
会话第一轮 把 Honcho 的核心上下文织入系统提示词,建立初始用户画像
后续对话 不修改系统提示词(保持缓存稳定),而是把 Honcho 的回溯内容附加在用户当前提问之后
这样一来,既保证了缓存的有效性(快速响应、降低成本),又让 AI 能持续获取最新的用户深度信息。鱼与熊掌,都要。
5 Hermes vs OpenClaw:两种记忆哲学
拆完四层架构,我们来做一个横向比较。OpenClaw 是另一个主流智能体框架,两者的记忆设计代表了截然不同的两种哲学:
以 Markdown 文件为核心存储,日志和长时文件是记忆主体,偏向「流水账式」全量记录。理念上是「记得越多越好」,边界模糊,核心和冗余混在一起。
严格限制提示词记忆容量,历史全量存入 SQLite,仅按需检索;一切设计优先服务于「提示词缓存效率」。理念上是「只在正确的层级,用正确的成本,记正确的事」。
Hermes 的底层认知极其清醒:不是所有信息,都配占据「系统提示词」这个黄金位置。就像我们做一人公司,不是所有事情都值得用核心精力去做,只有真正创造价值的事,才值得全力以赴。
6 三条原则
拆解完 Hermes,我提炼出三条最核心的底层原则。这三条原则不只适用于 AI 工程,同样适用于做个人 IP、做一人公司、做自我管理:
小规模的「热记忆」负责常驻核心信息,大容量的「冷存储」负责低频回溯信息。两套系统各司其职,不互相干扰。
对应到我们做事:核心工作全力以赴,辅助工作交给工具或外包。不要让低频的杂事占用你的核心精力。
频繁改动提示词,会直接导致缓存失效,响应延迟增加,调用成本上升。Hermes 的解法是让提示词前缀尽可能稳定。
对应到我们做事:不要频繁变换方向,不要轻易改动自己验证过的核心框架。稳定输出,才能积累复利。频繁折腾,只会耗尽精力,sx一事无成。
用户画像、情景回溯、操作技能、深度建模——不同类型的记忆,天然需要不同的存储和调用方式,强行混在一起只会互相拖累。
对应到我们做事:清晰区分自己的核心能力、过往经验、做事方法论,每类信息用对应的方式去管理和运用,不盲目跟风,不混淆主次。
最后,我想用 Hermes 的设计哲学作为这篇文章的收尾:
这句话,同样适用于我们每个人。真正的成长、真正的成功,从来不是「做更多事」,而是在正确的方向上,用正确的方法,持续做正确的事。
Hermes 最让我折服的,不是它有多少功能,而是它清楚地知道什么不该做、什么不该记。这种克制,才是最难的事。
更多深度内容,请加入Nelson · AI·OPC共助社区 · 《AI一人公司搞钱模型库》
 夜雨聆风
夜雨聆风