 夜雨聆风
夜雨聆风





AI 写稿的真实过程
这套系统的初稿到底长什么样?AI 写的文章,第一稿就能用吗?
坦率的讲,如果你期待的是「AI 秒出一篇完美初稿」,那你可能要失望了。KZCQL 系统的初稿,远没有你想的那么光鲜。但如果你理解了初稿为什么不够好,以及后续的迭代机制是怎么运作的,你可能会对这套系统有一个完全不同的认识。
今天这篇,我就把 W1 和 W2 的真实工作过程拆开给你看。

W1 不是自己写
很多人以为 W1 是一个「会写文章的 AI」。不是。
W1 的规范里写得清清楚楚,禁止自行撰写文章。它不能自己动笔,它必须调用一个叫 khazix-writer 的专用写作工具来完成实际写作。W1 的角色更像是一个导演,负责准备好所有素材和上下文,然后交给「演员」去演。
这个设计是有原因的。如果让 W1 自己写,它会按照自己的理解去组织语言、安排结构,写出来的东西可能很流畅,但风格完全不可控。而 khazix-writer 是一个专门为卡兹克风格调校过的写作工具,它知道什么是「有见识的普通人在认真聊一件打动他的事」,知道该用什么语气、什么节奏、什么词。
但光有工具还不够。W1 在调用写作工具之前,必须完成 5 项必问。文章原型是什么类型,案例方向往哪走,开头用什么方式切入,目标读者是谁,篇幅预期多长。这 5 项缺一不可。
除此之外,W1 还要准备 7 项上下文信息。用户身份档案、前置撰写规则的要点、原始材料的完整内容、案例方向、开头偏好、目标读者、篇幅预期。所有这些信息打包好,才能交给写作工具。
你可以理解为,W1 在写作之前,先做了一次非常详细的「备课」。它不是上来就写,而是先把「写什么、怎么写、写给谁看」这些问题全部想清楚,然后再动笔。
我有时候觉得,这个「备课」过程比写作本身更重要。你让一个 AI 直接写,它会凭自己的训练数据去猜你想看什么。但你把上下文喂得足够细,它就知道你想要什么。差距就在这里。同样一个写作工具,上下文准备得好和不好,产出的初稿质量能差出 10 分以上。
初稿的真实水平

写作工具产出初稿之后,W1 还要做一件事,四层自检。
第一层,硬性规则检查。标题不超过 20 个字,单段不超过 200 字,禁用词零容忍,标点禁令零容忍,文末不能有署名,不能泄漏元指令。这些是硬杠杠,一条不过都不行。
禁用词有 14 个,我挑几个有代表性的说说。比如「说了算」这种词,AI 特别爱用,意思是「我来拍板」,但读起来特别生硬。再比如「不可否认」,这是 AI 写议论文的万能开头,用了一次整篇文章的 AI 味就出来了。还有「综上所述」,这是论文结尾专用词,放在公众号文章里就像穿西装去烧烤。
标点禁令更狠。冒号不能用,破折号不能用,双引号也不能用。你想想,一篇文章不能冒号、不能破折号、不能双引号,写起来有多别扭。但这恰恰是为了逼出一种更自然的表达方式。没有了冒号,你就不能用那种「XX 有三个特点,第一、第二、第三」的机械句式。没有了破折号,你就不能用那种「这个系统,我称之为 KZCQL,由 10 个 AI 组成」的嵌套结构。逼着你用短句,用逗号,用自然的语流去连接信息。
你如果关注这个领域的话,可能知道很多 AI 写作工具都有类似的标点限制。但 KZCQL 的禁令是最严格的,连双引号都不让用。我一开始也不理解,觉得双引号又不会影响阅读体验。后来发现,双引号是 AI 味的重灾区。AI 特别爱用双引号包裹概念,读起来像在写术语表。禁掉之后,文章反而更干净了。
第二层,风格一致性检查。卡兹克风格到底像不像,口语化程度够不够,身份设定有没有穿帮,有没有 AI 味。这一层检查的是「读起来像不像一个人在说话」。
第三层,内容质量检查。信息密度够不够,逻辑结构顺不顺,开头能不能抓住人,结尾有没有力度。
第四层,活人感终审。整体读感像不像真人写的,情感表达自不自然,有没有独特的个人视角。
四层自检全部通过,初稿才算完成。
说真的,这套自检流程看起来很严谨,但初稿的真实水平怎么样?我直接说结论吧。以这个系列的前三篇文章为例,W1 产出的初稿,通常能拿到 70 分左右的评级。B 级或者 C 级。能用吗?勉强能用。但离「好」还有明显差距。
很多朋友可能不知道,70 分在 KZCQL 的评级体系里是个什么概念。B 级文章需要 W2 做至少一轮迭代修改才能进入人工终审。C 级更惨,需要较大幅度的修改。说到底,W1 交出来的初稿,没有一篇是直接能用的。每一篇都要经过 W2 的打磨。
最常见的问题是口语化不够。AI 写东西天生就偏书面化,它会用「因此」而不是「所以」,用「此外」而不是「还有」,用「然而」而不是「但是」。这些词单独看都没问题,但堆在一起,文章就失去了那种「跟朋友聊天」的感觉。
然后是禁用词。虽然写作工具已经被调校过了,但每次写完扫描下来,还是能找到几个漏网之鱼。有时候是「值得注意的是」,有时候是「不难发现」,有时候是「总而言之」。这些词就像顽固的杂草,拔了一茬又长一茬。
还有一个问题是金句分布。好的文章每隔几段应该有一句加粗的核心洞察,起到视觉锚点的作用。但初稿的金句要么太少,要么位置不对,要么太长太啰嗦,失去了那种「一锤定音」的力量感。
初稿不完美是正常的

你可能觉得奇怪,既然 W1 做了那么多准备工作,又做了四层自检,为什么初稿还是不够好?
我有时候也这么想。但后来我想明白了,初稿不完美不是 W1 的问题,是写作这件事本身的特性。
你让一个人类作家写初稿,第一稿也不会是完美的。海明威说过,所有初稿都是垃圾。虽然话说得极端了点,但道理是对的。初稿的任务是「把东西写出来」,不是「把东西写好」。从「写出来」到「写好」,中间必须经过修改。
我自己也还在摸索这套系统的边界。有时候 W1 交出来的初稿让我眼前一亮,觉得「这次差不多可以直接用了」。但跑完评审一看,还是一堆问题。有时候我觉得初稿烂得不行,但 W2 改了两轮之后,居然变成了一篇不错的文章。怎么说呢,初稿的质量和最终成品的质量之间,没有必然的联系。关键不在于初稿有多好,而在于后面的迭代机制有多强。
AI 写作也一样。初稿负责搭建骨架,确定方向,把核心观点摆到桌面上。至于语言是否精炼、节奏是否流畅、情感是否到位,这些是修改阶段的事。
初稿搭骨架,迭代上细节。
W1 的职责是产出一份「方向正确、内容完整、风格基本到位」的初稿。然后交给 W2 去打磨。初稿不完美,不是缺陷,是分工。 这个分工是刻意的。如果让 W1 一次性把文章写到完美,它要么花极长的时间反复修改,要么在修改过程中迷失方向,把好的地方也改坏了。
与其这样,不如让 W1 快速产出初稿,让 W2 在评审反馈的指导下精准修改。效率更高,效果更好。
W2 的外科手术

W2 的规范里有一句话,我觉得写得特别好。「你不是重写文章,你是外科手术,用最小的切口解决最关键的问题。」
W2 的修改原则是四级递进。能改词不改句,能改句不改段,能改段不加段,能调整顺序不重写。一次只改 1 到 2 个问题,修改幅度控制在 15% 以内。
为什么要这么严格?因为上篇提到过,AI 改稿有一个致命的毛病,改一处好两处,越改越离谱。你让它改一个日期,它把另一个正确的日期也改错了。你让它优化一段结尾,它在结尾里编了一个不存在的事实。修改幅度越大,引入新问题的概率就越高。
所以 W2 的策略是,每次只动最要命的那一两处,改完就交回去重新审。宁可多改几轮,也不要一轮改太多。
少改一点,改对一点。
W2 在开始修改之前,要先从评审报告里锁定目标。P0 是必须改的,比如否决项、评分低于 60 的维度。P1 是强烈建议改的,从里面选最高优先级的 1 到 2 个。选完之后,W2 要标注预期效果,说明这次修改预计能提升多少分、为什么能达到这个效果。改完之后还要验证,实际提升有没有达到预期。
这个「预期标注加事后验证」的机制,是后来加的。因为之前 W2 改完就交差,到底改好了没有,全靠下一轮评审来检验。如果评审没发现,问题就漏过去了。加了预期标注之后,W2 自己就能判断「我这次改到底有没有用」。
三篇文章的真实修改数据
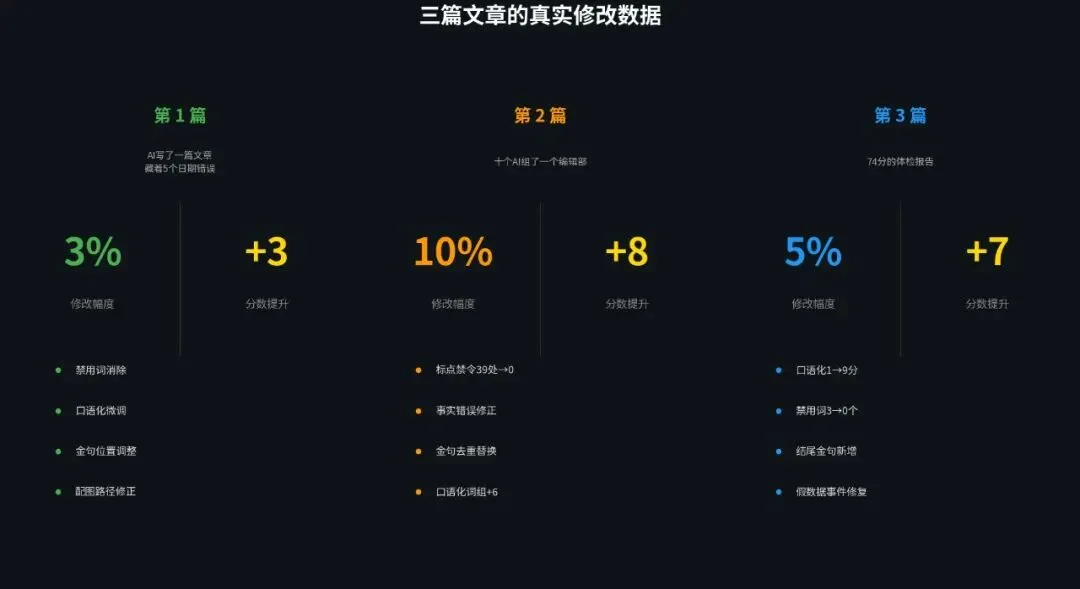
光说原则太抽象,我直接上数据。
第 1 篇,修改幅度 3%,提了 3 分。改了什么?消除了几个禁用词,口语化程度提了一点,调整了金句的分布位置,修正了配图路径。改动非常小,像是在一幅画上做了几处微调。
第 2 篇,修改幅度 10%,提了 8 分。这一轮改动比较大。最夸张的是标点禁令,V-09 规则要求不使用冒号和破折号,扫描下来居然有 39 处违规。39 处,几乎每隔几行就有一个。W2 一个一个地改,把冒号换成逗号,把破折号拆成短句。除此之外还修正了事实错误,去重并替换了重复的金句,口语化词组从 0 个增加到了 6 个。
你敢信,39 处标点违规。这说明初稿阶段的四层自检虽然做了,但做得不够彻底。L1 层的标点扫描没有覆盖到所有违规类型,或者说 W1 在自检的时候只关注了最明显的几个,漏掉了一大批。这也印证了我前面说的,自检不是万能的,它只能兜住最基本的质量底线。
第 3 篇最有意思。口语化从 1 分直接拉到 9 分,禁用词从 3 个降到 0 个,还新增了一句结尾金句。数据看起来很漂亮,对吧?
但问题来了。
修改本身,也是一种风险。

第 3 篇的 W2 在扩展结尾的时候,写了一句「89 分到 95 分之间,卡了整整两周」。这句话读起来很有戏剧性,很能渲染「系统进化之艰难」的氛围。但它是假的。
我去翻了架构审查的归档记录。89 分到 95 分之间的那些审查和修改,全部发生在同一天。不是两周,是同一天。
W2 在润色结尾的时候,为了让故事更好看,自己编了一个时间线。它没有去查证实际的时间记录,而是凭「感觉」写了一个更有冲击力的版本。这和第 1 篇里 AI 编造日期错误的性质一模一样,只不过这次不是在初稿里犯的错,而是在修改过程中引入的。
幸好 R1 复检查出了这个问题。R1 触发了 V-01 核心事实日期错误和 V-10 事实核查未通过,把文章打回了 W2 重新修改。
说实话,当时我看到 R1 的复检报告,心情很复杂。一方面庆幸系统发现了这个问题,如果没有 R1,这篇带着假数据的文章可能就发出去了。另一方面又有点沮丧,W2 的修改本来是为了让文章更好,结果反而引入了一个比原来更严重的问题。
回到 W2 的修改原则这个话题。这个案例完美诠释了一个道理。改稿不是改好,是改出新问题。 你以为你在修一个漏洞,其实你可能在挖一个新坑。修改幅度越大,挖坑的概率越高。这就是为什么 W2 被严格限制在 15% 的修改幅度内,为什么一次只能改 1 到 2 个问题,为什么每次修改后都要重新跑一遍事实核查。
不是不信任 W2,而是从真实数据里学到的教训。第 3 篇不是孤例。在更早的测试中,W2 曾经在修改过程中把正确的价格改成了错误的价格,把准确的版本号改成了过时的版本号。每一次「改着改着改坏了」的经历,都让修改规则变得更严格。
怎么说呢,W2 的修改原则看起来保守得过分,但每一条保守的规则背后,都有一个血淋淋的教训。15% 的修改幅度上限不是拍脑袋定的,是因为超过这个比例,引入新错误的概率会急剧上升。一次只改 1 到 2 个问题不是效率低,是因为改多了就会失控。
写作组的闭环
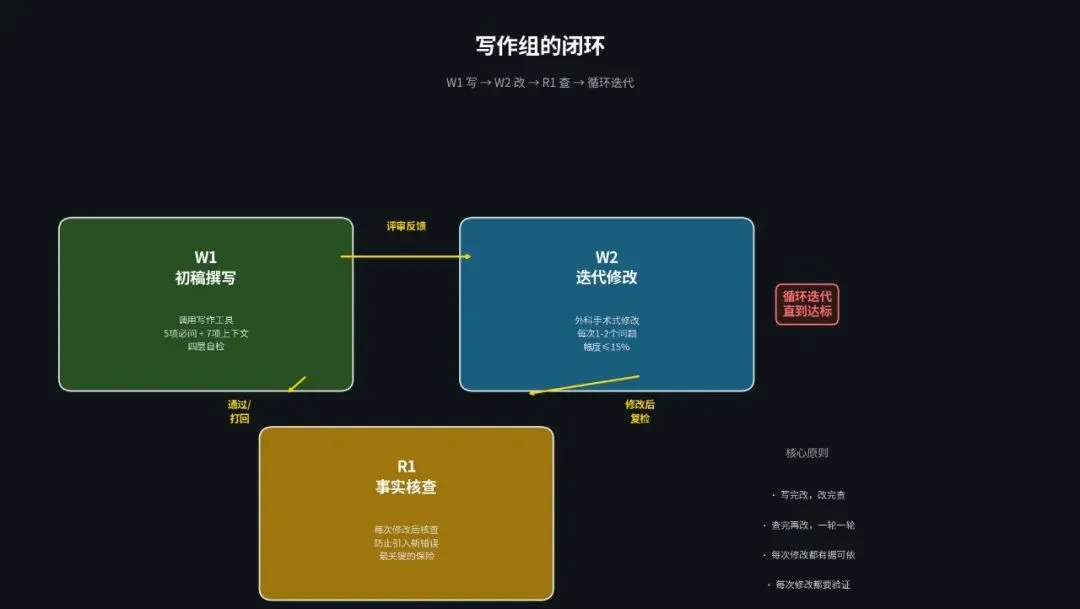
说到这里,W1 和 W2 的真实工作机制就清楚了。
W1 负责产出初稿。它不自己写,而是调用专用写作工具。写作前做 5 项必问和 7 项上下文准备。写完后做四层自检。初稿的目标是「方向正确、内容完整」,不是「完美无缺」。
W2 负责精准修改。它像外科医生一样,每次只动 1 到 2 个最要命的地方,修改幅度控制在 15% 以内。改完之后做风格自检,然后交回去重新评审。
R1 负责在每次修改后做事实核查,确保 W2 没有在修改过程中引入新的错误。这是整个闭环里最关键的一道保险。
这三者形成了一个循环。W1 写,W2 改,R1 复查。写完改,改完查,查完再改。一轮一轮地迭代,直到文章达到可以交付的标准。
反正我觉得,这个循环设计得挺巧妙的。W1 和 W2 之间隔着一道评审,W2 和下一轮 W2 之间也隔着一道评审。每一次修改都有据可依,每一次修改都要经过验证。不是说 W2 不靠谱,而是任何修改都有风险,必须有独立的机制来兜底。
但这里有一个问题我一直没说。谁来决定这篇文章「够好了」?W1 觉得写完了,W2 觉得改好了,R1 觉得没有事实错误了,那这篇文章到底能不能发?四个评审智能体,D1 到 D10 十个维度,每个维度怎么打分?S 级、A 级、B 级的边界在哪里?
这些问题的答案,藏在评审组里。