 夜雨聆风
夜雨聆风





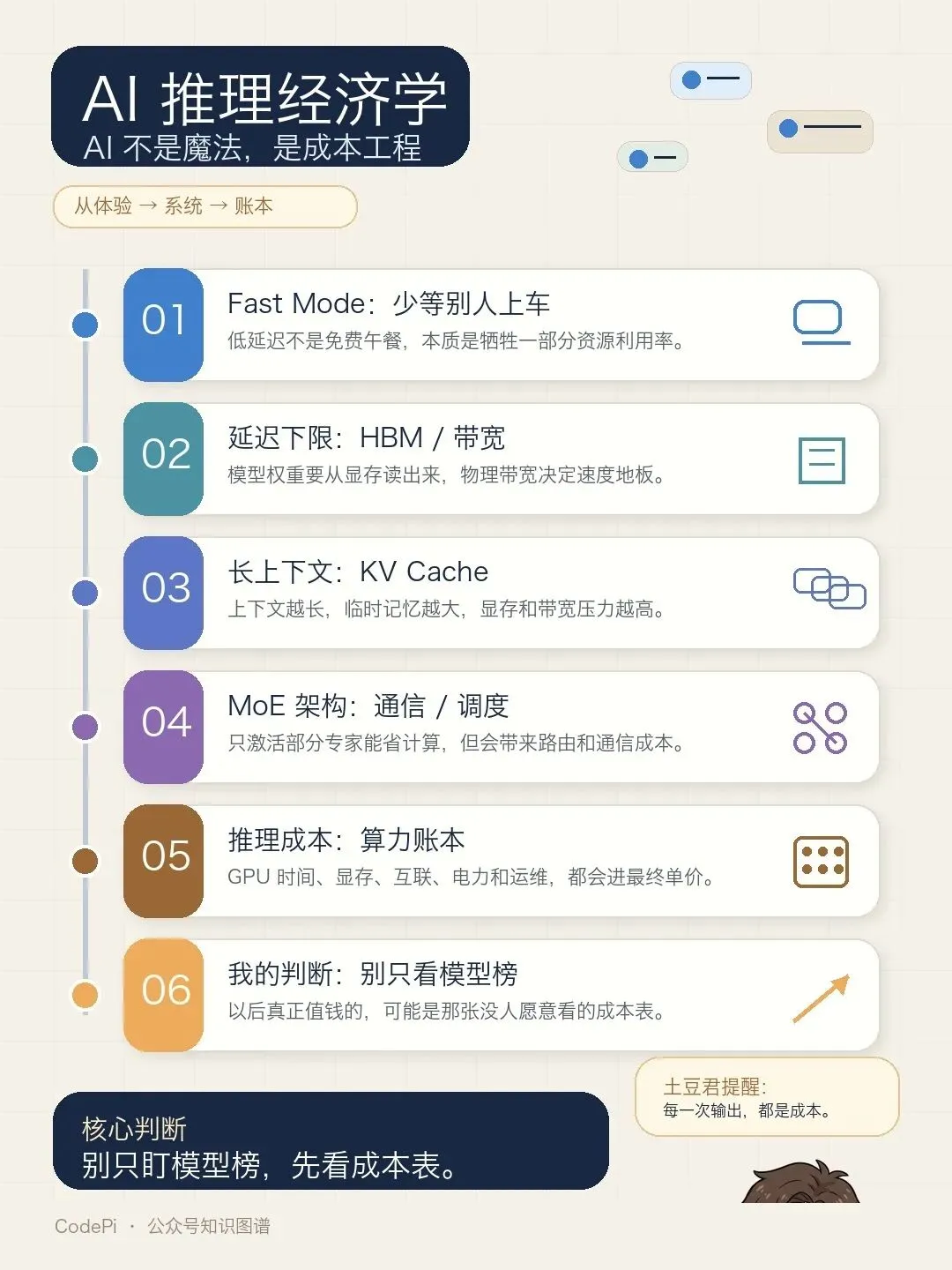
我越来越觉得:AI 拼到最后是算账
昨天看到 Saito 转的一篇长文,讲 Reiner Pope 那期播客。
我第一反应是:这东西一般人可能看不下去。
第二反应是:但如果你真的在做 AI 产品,或者准备把 AI 用进业务里,这期内容反而很值钱。
因为它讲的不是“模型又变强了”。
它讲的是另一件更扎心的事:AI 不是魔法,AI 是成本工程。
这两年大家聊大模型,特别容易被能力吸引。谁上下文更长,谁推理更快,谁写代码更像人,谁多模态更强。听起来都对,但我现在越来越觉得,光看这些东西,很容易误判。
真正决定一个 AI 产品能不能跑起来的,往往不是 demo 里的那一下惊艳。
是账本。
显存怎么算,带宽怎么算,batch 怎么排,KV Cache 怎么吃资源,Fast Mode 为什么贵,长上下文为什么贵,输出 token 为什么比输入 token 贵。
这些东西听起来很底层。
但说白了,它们决定了你最后能不能把一个聪明模型,变成一个可持续的生意。
1. Fast Mode 贵,不是因为厂商心黑
先说一个最接地气的问题。
为什么很多 AI 产品的 Fast Mode,贵很多,但没快很多?
比如你多付几倍的钱,结果速度只快两三倍。你可能会觉得:这是不是定价有点离谱?
我以前也这么想。
但从推理系统的角度看,这事没那么简单。
大模型服务用户,不是一个人来一个请求,就单独给你跑一次。真实情况更像班车:系统会把很多人的请求攒成一个 batch,一批一起送进 GPU。
车坐得越满,越划算。
因为模型权重读一次,可以服务更多人。成本被摊薄了。
但问题也来了。你要等。
Fast Mode 本质上就是让你少等。更小的 batch,更专属的资源,更低的延迟。
代价是什么?
资源利用率下降。
所以它一定更贵,而且不可能价格翻六倍,速度就线性翻六倍。你买的不是“六倍算力”,你买的是“少等别人上车”。
这就是很多 AI 产品定价里最容易被忽略的一点:快,不是免费的。低延迟本身就是一种奢侈品。
以前很多产品便宜,是因为有人在补贴。现在大家开始认真算账了,价格自然会变得不好看。

2. 延迟这件事,有地板
你可能会继续问:那我愿意多花钱,能不能把速度继续往下压?
可以压。
但压不到无限低。
原因很朴素:模型权重总得从 HBM 里读出来。这个读取时间绕不过去。
你可以优化调度,可以优化 batch,可以优化网络通信,但模型那么大,权重在那里,显存带宽在那里。它不是玄学,是物理。
这也是我觉得很多 AI 讨论很飘的地方。
大家总喜欢说“模型能力”“智能涌现”“范式变化”。当然,这些词都没错。
但真正跑服务的人,天天面对的是另一套东西:机架、电缆、显存、带宽、温度、功耗、排队、缓存。
听起来一点都不性感。
但它们决定了你的用户是秒回,还是转圈。
也决定了你的毛利是正的,还是越用越亏。
这就是 AI 产品跟普通软件最大的差别之一。普通 SaaS 多一个用户,边际成本可能很低。AI 不一样。每一次输出,背后都在烧真实的算力和带宽。
你以为你在卖智能,其实你也在卖 GPU 时间。
3. 长上下文为什么贵?答案在 KV Cache
长上下文现在很火。
几十万 token、上百万 token,听起来很爽。你把一堆资料塞进去,模型还能接着聊,好像世界突然变简单了。
但问题是:上下文不会凭空消失。
模型生成每一个新 token 时,都要带着前面的历史信息继续算。这里面有个关键东西,叫 KV Cache。
你可以把它理解成模型的“临时记忆”。
上下文越长,这个临时记忆越大。用户越多,这个临时记忆越多。它占显存,也占带宽。
所以长上下文贵,不是厂商随便找理由加钱。
它是真的贵。
输出 token 通常比输入 token 贵,也能从这里解释。输入可以一次性处理,输出要一个 token 一个 token 往外吐。每吐一个,都要带着 KV Cache 继续往前走。
这就是为什么很多 API 定价看起来很怪:输入一个价,输出一个价,缓存命中一个价,长上下文又是另一个价。
表面上看是商业定价。
底层看,是资源占用。
谁占了最稀缺的资源,谁就要付钱。
很现实。

4. MoE 不是架构审美,是硬件逼出来的选择
再说 MoE。
现在很多前沿模型都在用 MoE,也就是专家混合模型。简单说,一个模型里有很多专家,但每次只激活其中一小部分。
这听起来像一个很聪明的算法设计。
确实聪明。
但我更愿意把它看成一种工程妥协。
如果每次都激活全部参数,计算成本扛不住。那怎么办?只激活一部分。这样总参数可以做大,但每次推理的计算量不会同比例爆炸。
听起来完美?
没那么美。
MoE 会带来新的问题:专家分布在不同 GPU 上,推理时要通信。同一个机架里还好,跨机架就麻烦。网络一慢,延迟就上去。
所以模型最后长什么样,不完全是研究员拍脑袋决定的。
是硬件在参与设计。
机架有多大,带宽有多少,互联有多快,显存够不够,这些东西会反过来塑造模型结构。
这也是为什么我说 AI 不是纯算法竞赛。
它越来越像一门大型工业工程。模型、芯片、网络、调度、定价,绑在一起算。
谁只看其中一层,谁就容易看错。
5. 为什么模型会被“过度训练”
这里还有一个很有意思的点:为什么今天的模型会被训练得越来越狠?
以前我们会觉得,训练很贵,差不多就行了。
但如果推理阶段会产生海量 token,账就变了。
预训练花一次钱,推理是天天花钱。一个前沿模型如果每天服务大量用户,推理成本很快就会变成长期大头。
那怎么办?
你可以在训练阶段多花一点,让模型更熟练一点,从而让后面每一次推理更高效。
这有点像开工厂。
你可以少培训工人,让他每次现场慢慢摸索。也可以前期多培训,把动作练熟,后面每一件产品都更稳定、更便宜。
所以所谓“过度训练”,不一定是浪费。
它可能是推理经济学逼出来的选择。
这件事对很多创业公司也有启发。你不能只看模型调用价格今天是多少。你要想的是:当你的用户量上来、上下文变长、输出变多之后,这个账还能不能成立。
很多 AI 应用不是死在没人用。
是死在有人用之后,账算不过来。
6. 跟普通开发者有什么关系?
你可能会说,这些都是模型公司、云厂商、芯片公司的事,跟我有什么关系?
关系很大。
如果你是开发者,你要知道一个 AI 产品快不快、稳不稳、便不便宜,不只是模型名字决定的。背后推理栈、调度策略、缓存策略、硬件利用率,全都会反映到你的体验里。
同样一个模型,不同服务商跑出来,体验可能完全不一样。
如果你在做 AI 应用,更要小心。
不要把底层能力当成无限免费的水电煤。长上下文、低延迟、高并发、稳定输出,每一个听起来像产品卖点的东西,背后都有成本。
你今天为了体验把上下文拉满,明天账单可能会提醒你:别装。
说实话,这也是我现在看 AI 创业项目时很在意的一点。
我不只看它 demo 多惊艳。
我会看它有没有成本结构,有没有缓存策略,有没有降级方案,有没有想清楚哪些请求必须快,哪些请求可以慢,哪些地方可以复用,哪些地方不能硬省。
这听起来不像融资故事。
但这是活下来的故事。

我的判断
我现在越来越确定,AI 下一阶段的竞争,不只是模型能力竞争。
更是成本工程竞争。
模型会继续变强,这没悬念。但真正难的是,把强模型变成稳定、便宜、可规模化的服务。
谁能把 batch 排好,把 KV Cache 管好,把延迟和成本的账算清楚,谁才有机会把 AI 从 demo 做成生意。
别只盯着模型榜。
以后真正值钱的,可能是那张没人愿意看的成本表。