 夜雨聆风
夜雨聆风





AI 不只会聊天:拆解 Claude Code 如何通过 MCP 调用外部世界
导读
当 Claude Code 需要查数据库、调接口、读内部系统时,背后靠的不是魔法,而是一套 MCP 客户端机制。这篇从配置、授权、工具发现拆到异常兜底。
当你让 Claude Code 查数据库、读内部 API、控制浏览器、操作 Figma 时,它不是突然“变聪明”了。
真正让它走出聊天窗口的,是 MCP。
前六篇拆的都是 Claude Code 自己的“内政”:工具怎么跑、权限怎么判、上下文怎么记。这一篇翻到外面,看它怎么认识外部服务、请求授权、维持连接,并把远程能力变成 AI 可以调用的工具。
MCP(Model Context Protocol),是 Anthropic 在 2024 年底公开的一套协议。简单说,它是 AI 应用和外部工具/数据源之间的标准接口。任何程序只要实现了 MCP server,就能被 Claude Code 接入,变成 AI 能调用的能力。
听起来像 HTTP 对浏览器、LSP 对 IDE。大方向可以这么理解。
在我分析的这个版本里,Claude Code 的 MCP 相关实现已经是万行级规模,分散在多个模块里。这篇先讲你能动手配置、能直接感知的部分,再往下拆它背后的工程兜底逻辑。
PART 01
先看入口:从 .mcp.json 加一个 MCP server
最常见的入口是 .mcp.json。项目根目录放一个,格式长这样:
{ "mcpServers": { "postgres": { "command": "npx", "args": ["-y", "@modelcontextprotocol/server-postgres", "postgresql://localhost/mydb"] }, "figma": { "type": "http", "url": "https://mcp.figma.com/mcp" } } }提交到 git,团队里所有人 checkout 下来都能用同一套 MCP server。这就是“项目作用域”。
除了项目作用域,Claude Code 还会从其他地方收集 MCP 配置。先不用急着记优先级,记住一件事就够了:它最后会把这些来源合并成一张服务器表。
-
用户全局(~/.claude.json 里的 mcpServers 字段)。你个人的工具,跟项目无关。 -
本地私有(当前项目的 .claude/settings.local.json)。不提交 git,只你自己用。 -
企业托管(管理员下发的 managed-mcp.json)。公司 IT 统一配置,普通人改不动。 -
claude.ai 同步(登录 claude.ai 账号后拉取的服务器列表)。 -
插件带来的(plugin 安装时自带的 MCP server)。
这对团队协作很关键。个人工具、项目工具、企业托管工具可以共存,但真正生效的是合并后的结果,后面讲配置合并时会再展开。
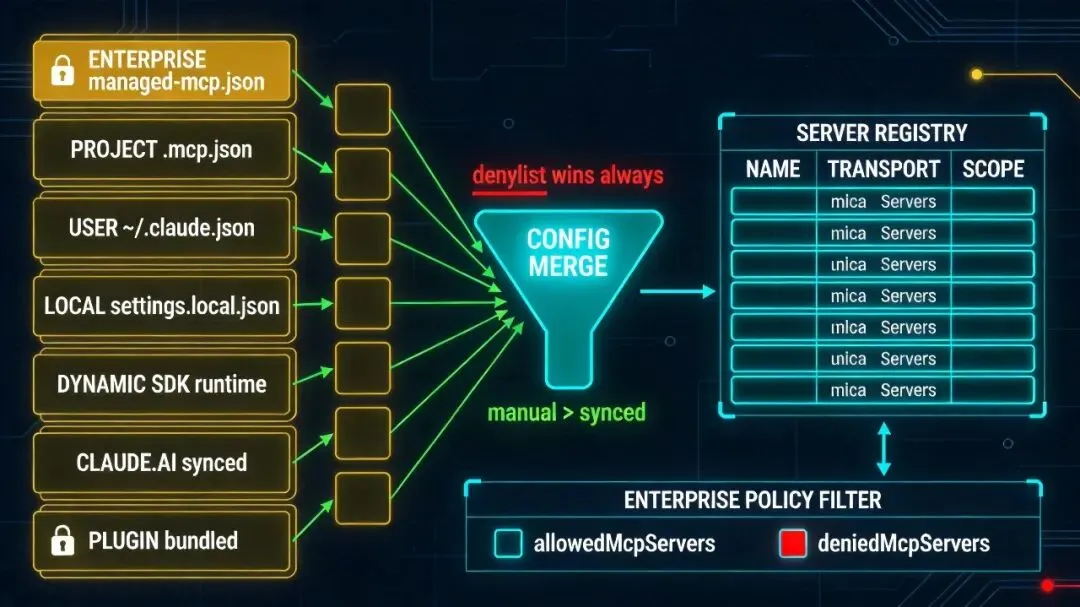
图:MCP 配置来源与合并管线
PART 02
再看连接:本地工具和远程服务不是一种接法
配置文件里的 type 字段,决定 Claude Code 怎么连这个服务器。Claude Code 会面对几类不同的连接形态。
stdio。最常见。Claude Code fork 一个子进程,通过标准输入输出跟它通信。适合本地工具,比如操作文件系统、访问本地数据库、调用本地 CLI。上面那个 postgres 例子就是 stdio,没写 type 是因为 stdio 是默认值。
优点是没有网络、启动快、权限跟当前用户一致。缺点是必须跟 Claude Code 跑在同一台机器上。
http。走标准 HTTP,支持 Streamable HTTP 规范。适合远程服务,比如云端 API、SaaS 产品的官方 MCP endpoint。上面 Figma 那个就是。
sse(Server-Sent Events)。早期 MCP 远程传输的主力方案,现在慢慢在被 http 替代。但存量配置里还很多,所以 Claude Code 还得支持。
ws(WebSocket)。双向长连接,适合需要服务器主动推消息的场景。用得相对少。
还有两个内部专用类型:sse-ide(JetBrains/VSCode 扩展用的)、sdk(SDK 内嵌的 MCP server,不需要真的起进程)。普通用户一般不会直接配置。
选择逻辑很朴素:本地工具优先 stdio,远程服务优先 http。其他情况通常不用纠结,服务方给什么接法,你就按它的文档来。
PART 03
OAuth:你可能会看到的登录弹窗
用远程 MCP server 的时候,经常会撞上一件事:第一次调用,Claude Code 弹出一个浏览器窗口让你登录授权。
这就是 OAuth 流程。MCP 协议里有一套标准的鉴权机制,远程服务器用它来确认调用方是谁。
你看到的流程大致是:
-
浏览器打开,跳到服务商的登录页。 -
你登录,点“允许 Claude Code 访问”。 -
浏览器跳回本地的某个端口,Claude Code 临时起的回调服务器会接住这次跳转。 -
终端里提示“已连接”,后续调用就带着 token 跑了。
Token 会缓存在本地 Claude Code 目录下,下次不用重新登录。过期了自动刷新,刷不动了才会再弹一次登录。
这里有个细节值得一提。在我分析的版本里,如果某次调用返回 401,Claude Code 会把这个服务器标记成 “needs-auth” 状态,并短时间缓存这个状态。这样你重启终端也不会反复触发登录,避免“每开一次终端都弹一次浏览器”的尴尬。
这个设计说明:授权状态不是简单的有或没有,还要考虑用户会不会被重复打扰。
企业场景里还有一套更复杂的东西叫 XAA(Cross-App Access,对应 MCP 的 SEP-990 扩展),你可以理解为“企业版的一次登录处处通”。简单说就是:公司 SSO 已经认证过你了,别再让我登一次。Claude Code 可以用企业 IdP 颁发的 token 去换 MCP server 的 access token,用户体感上少一步。
这不是个人用户日常会频繁碰到的东西,但它解释了为什么 MCP 不只是给个人 CLI 用的。
PART 04
连上之后:MCP server 能给 Claude Code 什么
连上只是第一步。真正有用的是,Claude Code 要知道这个 server 能提供什么。
按 MCP 的说法,常见的是三类 primitives:Tools、Resources、Prompts。换成更直白的话:Tools 是可执行动作,Resources 是可读上下文,Prompts 是可复用任务模板。
Tools。最常见。server 声明它提供哪些方法,每个方法有名字、描述、参数 schema。这些方法被 Claude Code 包装成内部工具,AI 就能调用了。
工具名有个固定格式:mcp__<服务器名>__<方法名>。比如 postgres server 里的 query 方法,最终在 Claude Code 里叫 mcp__postgres__query。前缀是为了避免不同 server 的同名方法冲突。
Resources。文件、文档、数据库记录,或者任何能用 URI 寻址的东西。AI 不会自动读,但你可以通过 MCP 资源相关工具把它们调出来。
Prompts。这个比较有意思。MCP server 可以定义“预设提示词”,进到 Claude Code 之后会变成 slash command。
你在终端里打 /mcp__github__create_issue,其实是在调 github server 的 create_issue prompt。prompt 可以带参数,触发时会被展开成一段完整的指令发给 AI。相当于“外部服务给你的快捷方式”。
所以 /mcp 命令列出来的,不只是连了几个服务器,还包括每个服务器带来的工具、资源、slash 命令分别多少个。到这一步,外部服务才真正开始进入 Claude Code 的工作流。
PART 05
Elicitation:MCP server 向你要信息
MCP 里还有一个容易被忽略的机制:elicitation。
场景:你让 AI 帮你在 GitHub 上建个 issue,AI 开始调用 github server 的 create_issue 工具。但这个工具需要知道 issue 的 priority 字段,参数里没有。这时候 server 可以反向请求 Claude Code:“请向用户要一下这些字段”。
Claude Code 会在终端里弹出一个交互式表单,你填完,结果送回给 server,工具继续执行。整个过程 AI 只是个传话人。
Elicitation 常见有两种模式:
-
form 模式:就是上面说的表单。字段结构由 server 定义。 -
url 模式:server 给一个 URL,让你在浏览器里完成一些操作,比如二次确认、付费、签名,完成后再通知 server。
这让 MCP 不只能单向调用工具,还能插入“用户交互”这个环节。对复杂工作流很有用,比如要人工审批的自动化流程。
如果你只关心怎么用,看到这里已经够了:配置 server、完成授权、确认它提供哪些工具/资源/Prompts,再按权限提示去调用。
但 Claude Code 真正有意思的地方在后面。因为把一个外部服务接进来,不难;难的是它断线、过期、返回脏数据、权限冲突的时候,客户端怎么兜住。
下面翻到底层。
PART 06
底层第一层:连接状态不是“成功/失败”这么简单
Claude Code 内部把每个 MCP server 的连接封装成一个状态机。以我分析的版本为准,一个连接可以处于以下五种状态之一:
- connected
:正常连接中,能调工具、拿资源。 - pending
:正在连接中,通常是因为 OAuth 流程没走完。 - needs-auth
:需要认证但当前没有有效 token。调用会立即返回错误提示用户登录。 - failed
:连接失败,通常是网络问题或者 server 崩了。会被定期重试。 - disabled
:被用户或者企业策略禁用。
每次状态变化都会触发事件通知 UI 更新。前端再把这些状态展示成用户能看懂的连接状态、登录提示或失败原因。
值得注意的是,连接状态本身通常不是长期记忆。每次 Claude Code 启动都会重新建立连接、重新走状态机。被缓存的是 token、短期认证状态这类对用户体验有影响的东西。
PART 07
底层第二层:从 MCP schema 到可调用工具
连上一个 server 之后,Claude Code 会干这么几件事,把 server 的工具变成 AI 能看到、能调的工具。
第一步,拉工具列表。发 tools/list 请求,拿回 server 声明的所有工具名、描述、参数 schema。
第二步,Unicode 清洗。server 返回的每个字段都会过一遍清洗逻辑。原因是 MCP server 可以是任何人写的、任何语言写的,返回内容里可能混入零宽字符、双向控制符、其他不可见 Unicode。这些字符进到系统提示词里会造成各种怪问题,必须先洗掉。
第三步,描述截断。每个工具的 description 都有长度限制。防止某个 server 写了几万字的描述,把上下文窗口吃掉。
第四步,名字规范化并加前缀。工具名被改成 mcp__<server>__<tool>,服务器名里的非法字符会被替换。这个最终名字会出现在系统提示词里、权限规则里、审计日志里,是 Claude Code 识别这个工具的唯一标识。
第五步,注册到主工具表。到这里 MCP 工具就跟 Read、Edit 这些内置工具平起平坐了。权限系统不区分来源,无论是内置工具还是 MCP 工具,都要走同一套权限判断。
有一个小陷阱。在我看的实现里,IDE 的 MCP server(sse-ide 类型)有白名单,只有少数诊断和执行类工具会被暴露出来,其他会被屏蔽。这是为了限制 IDE 扩展能让 AI 做的事。
换句话说,MCP 带来扩展性,但 Claude Code 不会因此放弃边界控制。
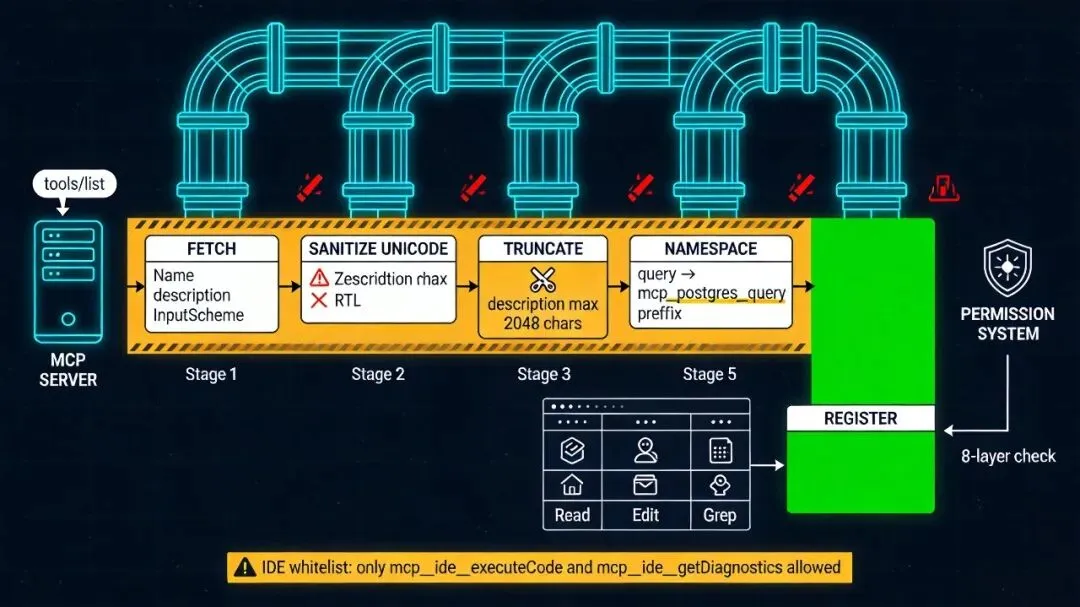
图:工具发现管线
PART 08
底层第三层:stdio 的“杀进程三连”
不同传输方式的实现细节各有讲究。说一个我觉得特别有意思的:stdio transport 怎么关闭子进程。
你可能会想,kill 一下不就完了?没这么简单。很多 MCP server 是 Docker 容器里跑着的 Node 进程,或者是自己带清理逻辑的守护进程。直接 SIGKILL 会留下孤儿进程、未释放的资源、写了一半的文件。
Claude Code 的做法是三级升级:
-
先发 SIGINT,相当于 Ctrl+C。绝大多数程序会捕获这个信号,优雅退出。 -
等一小段时间,看进程还在不在。还在?换一个更正式的终止信号 SIGTERM。很多守护进程只监听 SIGTERM,不监听 SIGINT。 -
再等一小段时间。还在?发 SIGKILL,内核级别的强杀。没得商量。
具体等待时间是实现细节,版本可能会变。但这个顺序本身很克制:先给体面退出的机会,不行再强杀。它说明本地 MCP 集成不是“调一下命令”那么简单,进程生命周期也会影响产品体验。
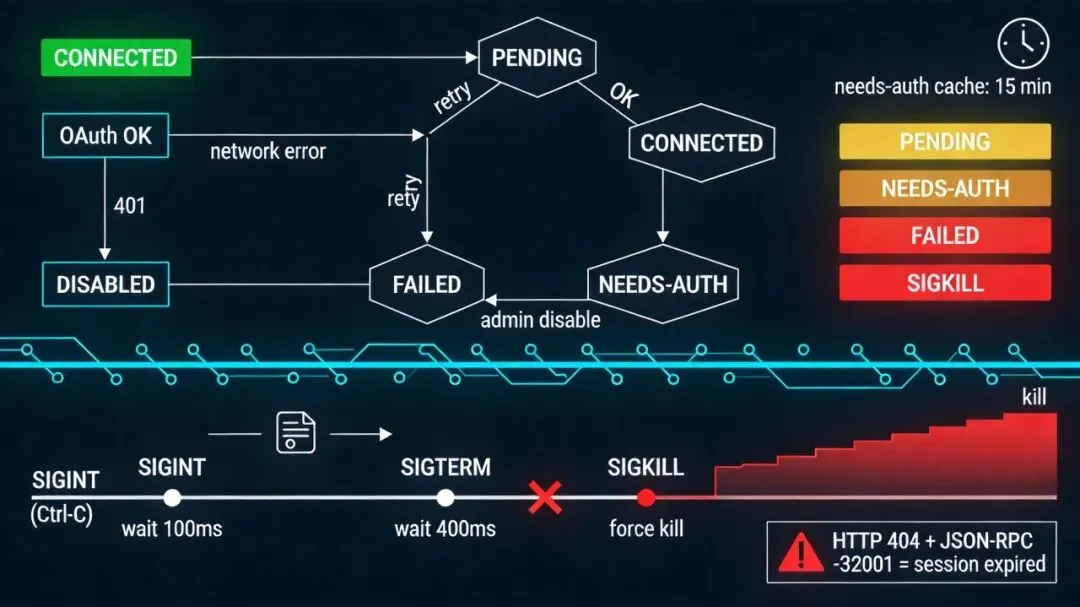
图:连接状态机与进程三级升级
SSE 和 HTTP transport 处理的是另一类问题:网络异常恢复、流中断检测、chunk 粘包拆包。思路都是一句话:尽可能优雅失败,失败了快速重连。
PART 09
底层第四层:会话过期不能只看 404
HTTP transport 里有一个容易踩坑的地方:远程 MCP server 会给每个连接分配一个 session ID,一段时间不用就过期。过期后你发请求过去会拿到 HTTP 404。
但 404 也可能意味着别的东西:你配置的 URL 写错了、server 下线了、路径变了。Claude Code 怎么区分这两种 404?
答案是检查双信号。在 Claude Code 当前实现里,HTTP 状态码是 404,同时响应体里包含 JSON-RPC 错误 code -32001(Session not found)。两个都满足,才判定为会话过期,才触发自动重连。
只匹配 404 不行,会把“URL 写错了”也当成会话过期,陷入无限重连。只匹配 -32001 也不行,因为现实里的 server 错误响应未必都规范。双信号是为了在“宁可错过也不误判”和“尽量自动恢复”之间找平衡。
这种细节在 MCP 客户端实现里到处都是。比如有的 OAuth 服务会在 HTTP 200 里返回错误对象,而不是按常规给 4xx。客户端只能单独兼容。
协议可以写得很干净,但真实世界接进来以后,代码一定会变脏。
PART 10
底层第五层:配置合并的优先级战争
配置合并干的事情概括起来就一句话:把多个来源的 MCP server 配置合并成一张表。以我分析的版本为例,来源大致包括这些:
-
enterprise(企业管理员下发的 managed-mcp.json) -
project(项目根目录的 .mcp.json) -
user(~/.claude.json 里的 mcpServers) -
local(项目的 .claude/settings.local.json) -
dynamic(运行时 SDK 动态加的) -
claudeai(登录 claude.ai 同步下来的) -
插件自带的
合并不是简单覆盖。规则大致是:
-
如果企业策略里有 allowedMcpServers / deniedMcpServers,所有来源都要先过一遍这个白黑名单。企业管得最严。 -
如果 enterprise 模式下开了 allowManagedMcpServersOnly,通常只有企业 MCP 配置会生效,其他来源会被排除。 -
手动配置(project/user/local)通常优先于自动同步(claudeai)。用户写进文件的东西,比远程拉下来的配置更明确。 -
同名 server 后加载的覆盖先加载的,但 denylist 是安全底线。
这里最值得注意的不是“谁覆盖谁”,而是企业策略和用户拒绝之间的关系。
扩展能力可以被集中下发,但拒绝和限制也必须有明确位置。否则 MCP server 越多,权限边界越容易变成一团浆糊。
PART 11
底层第六层:Elicitation handler 怎么把人插回流程
Elicitation handler 的代码量不算大,但逻辑很密。
它注册了一个处理器,监听 server 发过来的 elicitation 请求。收到之后:
-
先跑一次 elicitation hooks。用户可以配置钩子脚本,在 UI 弹出之前直接返回响应。比如你可以写一个 hook:所有 github server 的 priority 字段默认填 medium。 -
Hook 没拦下来,才把请求塞进一个队列,等 UI 消费。 -
UI 显示表单、用户填完,结果回来,再跑一遍 elicitation result hooks。这个阶段可以对用户填的内容做后处理,比如脱敏、校验、审计。 -
最后把结果通过 JSON-RPC 返回给 MCP server。
这就是 form 模式。url 模式也走同一套队列,只是 UI 变成打开 URL,然后 server 通过另一条消息通知 Claude Code “好了”。
它解决的是一个很现实的问题:AI 执行到一半,发现需要人确认、补字段、过审批,流程不能直接断掉。
PART 12
回头看
MCP 这套东西拆到这里,可以说它给 Claude Code 带来的不只是“多几个工具”。它带来的是扩展性,也带来了平台化的入口。
Claude Code 团队不需要内置所有集成。Figma、Notion、GitHub、Slack、Postgres、Kubernetes——任何一个想跟 AI 合作的服务,只要实现 MCP server 规范,就能进来。Claude Code 负责连接、鉴权、数据清洗、权限判断,剩下的交给生态。
这比“每个集成各自写一个插件”的模式轻得多。插件需要信任插件作者的代码能跑在你机器上;MCP server 是隔离的进程,能力通过标准协议声明,边界更清楚。
代价是代码复杂度。在我拆的这个版本里,MCP 相关实现已经到万行级。里面处理的大半不是 happy path,而是 OAuth 的各种非标实现、会话过期的各种信号、远程服务的各种不守规矩、企业策略的各种覆盖关系。
真实世界就是这么乱。协议设计者可以说“按规范来”,但客户端必须把现实情况兜住。Claude Code 的关键变化也在这里:它不只是多了几个命令,而是把 IDE/终端里的 AI 变成了可接外部系统的客户端。
我自己用下来的感受是,MCP 的价值要等你接的服务够多才能真正体会。接一个的时候你觉得麻烦;接五个的时候你会发现,所有集成都在用同一套机制:鉴权、工具发现、权限审批、交互弹窗。
这种一致性,是编程接口从“零散脚本”变成“平台能力”的分水岭。
如果你正在做 Agent、IDE 插件或内部工具平台,可以收藏这一篇,把它当作理解 MCP 接入层的路线图。判断一个 Agent 是否真正具备平台潜力,不只看模型能力,还要看它如何接入工具、管理权限、处理会话和发现能力。
MCP 的价值就在这里:它把“外部世界”变成了 AI 可以稳定理解和调用的接口层。
下一篇拆 System Prompt 拼装。Claude Code 的系统提示词不是一坨写死的字符串,而是每次启动从十几个源动态拼起来的。那套拼装逻辑怎么工作,模型为什么能“知道”当前仓库长什么样?下次聊。