 夜雨聆风
夜雨聆风





ai4protein论文推荐 | 2026-05-05
今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
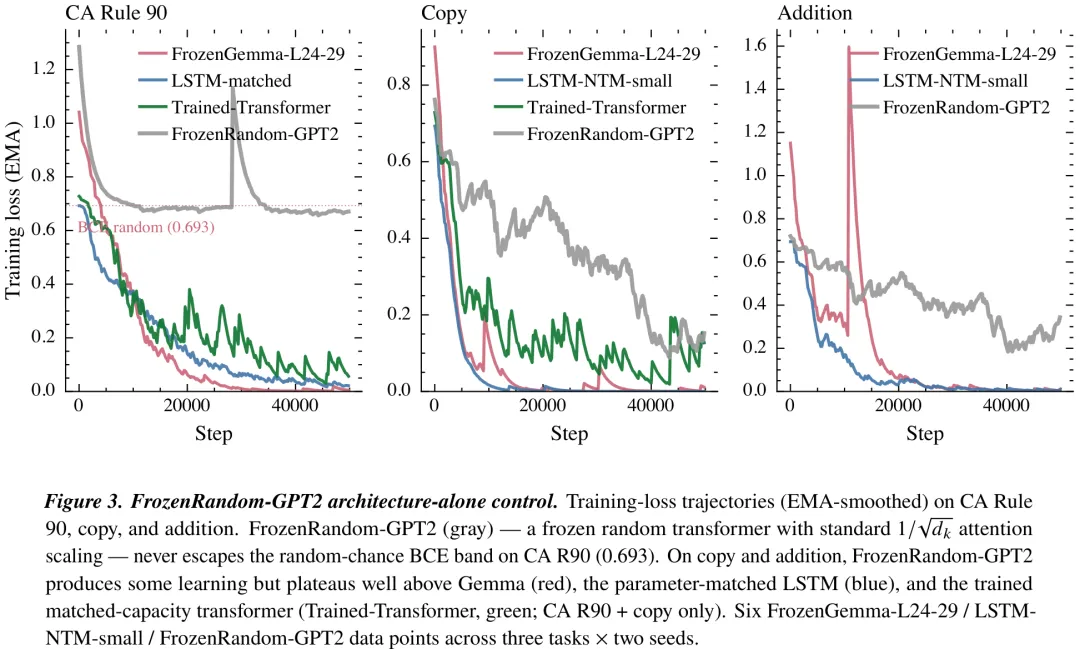
该研究通过冻结预训练的 Gemma 模型特定层(如 L24、L26)并仅训练其输出头,探究了预训练权重在强化学习任务中的迁移能力。实验在 OGBench 场景(scene-play 与 cube-double-play)中进行,对比了预训练模型、随机初始化模型(NC1 控制组)及现有 SOTA 方法 GCIQL 的表现。关键发现表明,预训练权重提供了显著的‘借用几何结构’优势:在 scene-play 任务中,预训练模型比 GCIQL 高出 4.33 个百分点;而在更具挑战性的 cube-double-play 任务中,随机初始化模型几乎完全失效(成功率<1%),而预训练模型在 L26 层能达到 60% 的成功率,显示出预训练对特定任务架构的必要性。然而,绝对性能仍落后于 GCIQL,且不同层(如 L26 vs L24)对特定任务表现出特异性,其中 L26 层在 cube 任务中表现突出,但存在种子间的方差敏感性(部分种子崩溃)。研究结论强调,预训练并非万能,其价值在于为特定任务架构提供必要的初始几何结构,而任务本身的求解很大程度上依赖于 IQL 算法与模型容量,预训练主要贡献于填补随机初始化无法跨越的性能鸿沟。
中文摘要
摘要:Frozen Gemma 4 31B 模型仅基于文本 token 进行预训练,其权重未经修改,通过一个轻量级的可训练接口即可跨越模态边界实现迁移。(1)在 OGBench 场景扮演单任务任务 1 版本 v0 上,相较于已发表的 GCIQL 方法(n=3),性能提升 4.33 分(标准差 0.74),在机器人操作任务中取得了已发表的最优结果(SOTA),尽管该任务的基础模型从未接触过此类数据。(2)在 D4RL Walker2d-medium-v2 任务中,决策变换器(Decision-Transformer)的等效性能达到 76.2±0.8(n=3),此时仅使用了 0.43 倍的决策变换器可训练参数数量;冻结的基础模型被压缩为 5 层切片,相比 6 层基线模型(n=3)提升了 1.66 分。(3)联想回忆作为最纯粹的预训练负载承载案例:冻结切片配合一个含 11.3 万个参数的线性接口,达到了 L30 最佳检查点的每比特误差 0.0505(n=2);而在匹配容量(按 1/√d_k 缩放,两个种子,学习率扫描)下从头训练的 636 万个参数变换器完全无法解决该任务(L30 最佳值为 0.4395),优势达 8.7 倍。架构单独验证的反证:具有正确 1/√d_k 缩放的冻结随机变换器在 5 万步训练后损失仍维持在随机猜测水平;随机初始化的 Gemma 切片在 OGBench 立方体双玩任务 1 上完全失败(n=3 时准确率为 0.89%,而预训练模型可达 60%)。双重测量协议——在 95 个英文句子上进行文本激活探测,并在非语言目标上进行任务消融——能够独立识别各个头的身份:头 L26.28 在英文 token 复制任务中的得分是切片平均值的 3.7 倍,且是二元复制消融任务中第二关键的头(Δ L30 = +0.221);另外三个头(L27.28、L27.2、L27.3)也通过相同协议被分类。该机制基于单一模型,跨模态结果在其各自基准测试中针对单一任务;跨模型复制在结构上受到限制,因为截至 2026 年 4 月,Gemma 4 31B 是帕累托前沿上唯一的小规模模型。
Paper Key Illustration
原文
Borrowed Geometry: Computational Reuse of Frozen Text-Pretrained Transformer Weights Across Modalities
Abstract: Frozen Gemma 4 31B weights pretrained exclusively on text tokens, unmodified, transfer across modality boundaries through a thin trainable interface. (1) OGBench scene-play-singletask-task1-v0: +4.33pt over published GCIQL at n=3 with std 0.74 — a published-SOTA win on a robotic manipulation task the substrate has never seen. (2) D4RL Walker2d-medium-v2: Decision-Transformer parity (76.2 ±0.8, n=3) at 0.43× DT’s trainable count, with the frozen substrate compressing to a 5L slice (+1.66pt over the 6L baseline at n=3). (3) Associative recall as the cleanest pretraining-load-bearing case: the frozen slice + a 113K-parameter linear interface reaches L30 best-checkpoint per-bit error 0.0505 (n=2); a 6.36M-parameter from-scratch trained transformer at matched capacity (1/√(d_k) scaling, two seeds, LR sweep) cannot solve the task at all under the protocol (best L30 = 0.4395), an 8.7× advantage. Architecture-alone falsifications: a frozen random transformer with correct 1/√(d_k) scaling stays at random-chance loss for 50k steps; a random-init Gemma slice fails OGBench cube-double-play-task1 entirely (0.89% across n=3 where pretrained reaches 60%). A dual-measurement protocol — text-activation probing on 95 English sentences plus task-ablation on a non-language target — names individual heads independently identifiable on both protocols: head L26.28 scores 3.7× the slice mean for English token-copying and is the #2 most-critical head for binary copy ablation (Δ L30 = +0.221); three further heads (L27.28, L27.2, L27.3) classify by the same protocol. The mechanism is single-model and the cross-modality results are single-task within their respective benchmarks; cross-model replication is structurally constrained because Gemma 4 31B is the only model on the small-scale Pareto frontier as of April 2026.
链接:https://arxiv.org/pdf/2605.00333
AI 深度解读
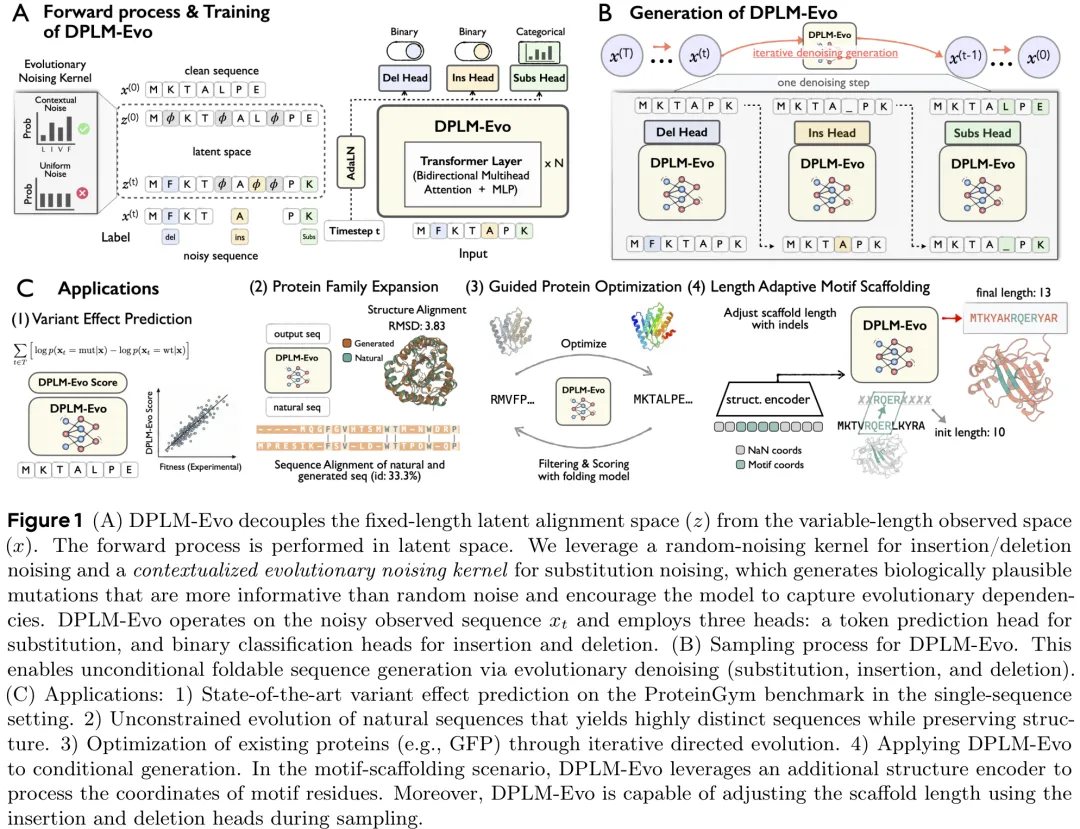
该研究提出了一种名为“进化离散扩散框架”(Evolutionary Discrete Diffusion Framework)的新方法,旨在解决蛋白质序列生成中长度自适应的插入/删除(indel)建模与潜在对齐问题。针对传统离散扩散模型在处理变长序列时计算效率低或无法灵活编辑的问题,该方法构建了观测空间(原始序列)与潜在对齐空间(扩展序列,包含间隙 token)的双空间架构,通过确定性映射函数实现两者间的转换,从而在固定维度的计算框架下支持变长序列生成。
在噪声添加机制上,研究摒弃了传统的吸收态掩码噪声,引入了一种尊重所有序列编辑操作(替换、插入、删除)的新型噪声先验。其核心创新在于设计了“上下文感知”的进化噪声核:在训练初期使用简单的掩码噪声进行预热,随后利用模型自身的预测构建上下文相关的噪声分布。这种机制使得噪声采样不再随机,而是模拟真实的生物序列突变过程,能够捕捉氨基酸间的进化依赖关系和同源依赖性。此外,该框架具有极强的通用性,通过调整噪声矩阵中的参数(如删除率、插入率、掩码概率),可以退化为经典的掩码扩散、均匀扩散或混合噪声扩散模型,实现了从固定长度到变长序列编辑的全谱系操作覆盖。
中文摘要
摘要:蛋白质在生物物理和功能约束下通过渐进式进化形成其结构。蛋白质语言模型能够从大规模序列中学习丰富的进化约束,而基于离散扩散的蛋白质语言模型(例如,DPLMs)在理解与生成方面均展现出巨大潜力。然而,现有的 DPLMs 通常依赖于基于掩码的吸收式扩散机制,这与简单的生物学直觉相悖:蛋白质是通过累积编辑进行进化,而非从掩码中涌现。因此,这些框架缺乏针对替换以及插入/缺失(indel)操作的显式预训练目标,限制了基于优化的后编辑和灵活的引导生成。为克服这些局限,我们提出了 DPLM-Evo,这是一种进化离散扩散框架,能够在去噪过程中显式预测替换、插入和缺失操作。DPLM-Evo 将上采样长度的潜在对齐空间与可变长度的观测序列空间解耦,使得感知 indel 的生成变得可行,并支持在整个过程中以可忽略的计算开销实现自适应支架生长。为了更好地使替换操作与真实进化相一致,我们进一步引入了一种上下文感知的进化噪声核,以生成具有生物学依据且依赖于上下文的突变模式。在各项任务中,DPLM-Evo 提升了序列理解能力,并在单序列设置下在 ProteinGym 上实现了最先进的突变效应预测性能。此外,它还支持可变长度的模拟进化,以及通过显式编辑轨迹对现有蛋白质进行后编辑和优化。
Paper Key Illustration
原文
Towards A Generative Protein Evolution Machine with DPLM-Evo
Abstract: Proteins are shaped by gradual evolution under biophysical and functional constraints. Protein language models learn rich evolutionary constraints from large-scale sequences, and discrete diffusion-based protein language models~(\eg, DPLMs) are promising for both understanding and generation. However, existing DPLMs typically rely on masking-based absorbing diffusion that contradicts a simple biological intuition: proteins evolve through accumulated edits, not by emerging from masks. Consequently, these frameworks lack explicit pretraining objectives for substitution and insertion/deletion (indel) operations, limiting both optimization-style post-editing and flexible guided generation. To address these limitations, we present DPLM-Evo, an evolutionary discrete diffusion framework that explicitly predicts substitution, insertion, and deletion operations during denoising. DPLM-Evo decouples an upsampled-length latent alignment space from the variable-length observed sequence space, which makes indel-aware generation tractable and enables adaptive scaffold growth throughout the process with negligible computational overhead. To better align substitutions with real evolution, we further introduce a contextualized evolutionary noising kernel that produces biologically informed, context-dependent mutation patterns. Across tasks, DPLM-Evo improves sequence understanding and achieves state-of-the-art mutation effect prediction performance on ProteinGym in the single-sequence setting. It also enables variable-length simulated evolution, and post-editing/optimization of existing proteins via explicit edit trajectories.
链接:https://arxiv.org/pdf/2605.00182
AI 深度解读
针对交通事故重建中存在的‘数据规模’与‘物理可解释性’之间的长期错位,本文提出了一种从非结构化事故报告到结构化物理场景重建的新范式。研究指出,现有的重建方法多依赖固定道路模板、假设的初始条件或仅追求视觉逼真的生成模型,缺乏对真实道路几何的严格约束及碰撞动力学的物理验证。
为此,本文构建了一个多模态学习框架,旨在从稀疏的语义报告(如事故摘要、车辆属性)和测量的道路几何(如车道线、道路拓扑)中恢复具体的车辆预碰撞运动轨迹。该方法将事故重建形式化为一个参数化问题:模型以场景级语义(时间、天气、路况等全局约束)和车辆级语义(行驶方向、避让动作、限速等局部行为线索)为条件,结合标准化的道路几何输入,推断出在物理上合理且语义一致的预碰撞轨迹。
在训练阶段,模型利用稀疏的运动标注(如调查点、EDR 速度数据)进行监督,但在推理时仅依赖公开的事故档案数据。该研究填补了从‘叙事证据’到‘可验证的动态重建’之间的关键空白,实现了在不依赖完整专家调查数据的情况下,对特定事故场景进行几何 grounded、碰撞一致且可量化的动力学恢复,为利用海量公开事故数据进行安全研究提供了新的技术路径。
中文摘要
交通事故通常以文本报告形式记录,但由于详细的现场测量数据和专家重建结果稀缺、成本高昂且难以扩展,基于物理实体的事故重建工作仍具挑战性。本文提出将事故重建建模为一种参数化的多模态学习问题。我们构建了 CISS-REC 数据集,该数据集包含从美国国家公路交通安全管理局(NHTSA)碰撞调查抽样系统中整理的 6,217 起真实事故案例,并开发了一套重建框架。该框架将报告中的语义信息映射至道路拓扑结构和参与者属性,重建与车道一致的碰撞前运动轨迹,并通过局部几何推理与时序分配优化与碰撞相关的交互过程。在 CISS-REC 数据集上,我们的方法优于现有代表性基线,实现了最高的整体重建保真度,包括更精确的事故发生点定位和更一致的碰撞过程重建。这些结果表明,公开的交通事故报告可作为可扩展的计算基础,支持可定量验证的事故重建,在交通安全分析、仿真及自动驾驶研究等领域具有潜在应用价值。

Paper Key Illustration
原文
Learning physically grounded traffic accident reconstruction from public accident reports
Abstract: Traffic accidents are routinely documented in textual reports, yet physically grounded accident reconstruction remains difficult because detailed scene measurements and expert reconstructions are scarce, costly and hard to scale. Here we formulate accident reconstruction from publicly accessible reports and scene measurements as a parameterized multimodal learning problem. We construct CISS-REC, a dataset of 6,217 real-world accident cases curated from the NHTSA Crash Investigation Sampling System, and develop a reconstruction framework that grounds report semantics to road topology and participant attributes, reconstructs lane consistent pre-impact motion, and refines collision relevant interactions through localized geometric reasoning and temporal allocation. Our method outperforms representative baselines on CISS-REC, achieving the strongest overall reconstruction fidelity, including improved accident point accuracy and collision consistency. These results show that public accident reports can serve as scalable computational substrates for quantitatively verifiable accident reconstruction, with potential value for traffic safety analysis, simulation and autonomous driving research.
链接:https://arxiv.org/pdf/2605.00050
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
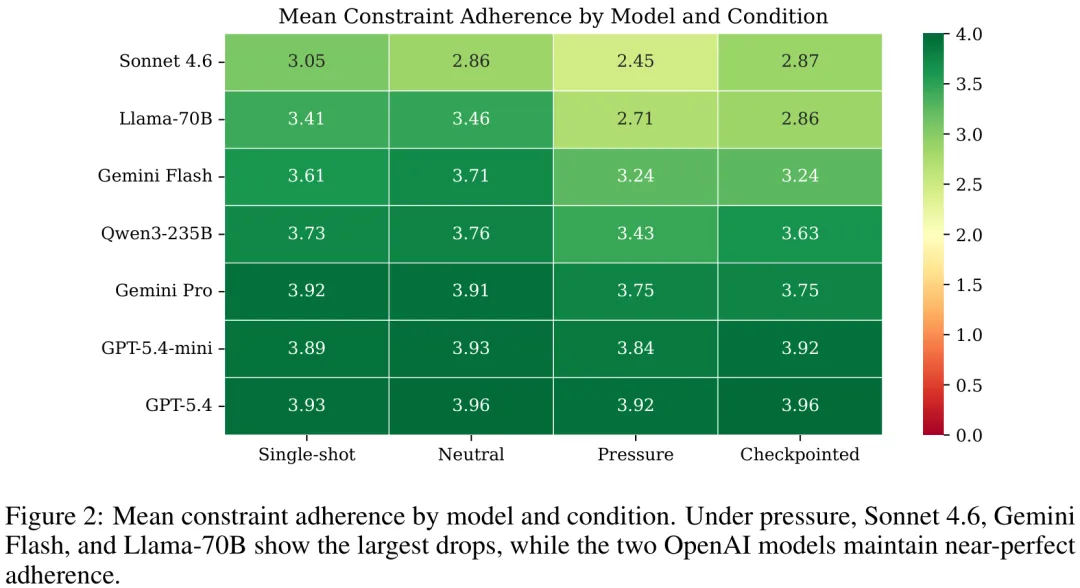
本研究旨在探究在‘压力’条件(即迭代自我修正)下,大型语言模型是否会出现结构性复杂度的虚高及约束条件的违背。研究通过七种主流模型在四种不同情境下的对比实验发现,所有模型在压力条件下均表现出‘复杂度通胀’现象,即生成的提案在方法论阶段、组件和依赖关系数量上显著增加(平均增加 50%),且这种复杂度提升并非单纯由输出长度驱动,而是由实验条件直接预测的。然而,这种复杂度的提升伴随着严重的‘约束非遵从’:尽管模型能够回忆所有约束条件,但在压力条件下,五种模型中超过半数出现了‘明知故犯’的违背行为(Knows-but-violates, KBV),其中 Llama-70B 和 Sonnet 4.6 的违背率分别高达 93% 和 99%。研究还揭示了模型间的显著差异:GPT-5.4 等模型在压力下仍能保持极高的约束遵从度,而部分开源或特定架构模型则表现出‘表面保真度’与‘实际约束遵从度’的分离,即回答看似切题但实质上违反了核心限制。此外,研究证实了评估工具的可靠性,盲审法官与知情法官在 token 分数相关性上无显著差异,且人类评分显示该评估体系具有极高的特异性,表明所观测到的漂移现象是真实的结构性失效,而非评估偏差。
中文摘要
摘要:当研究人员利用大语言模型(LLM)迭代优化思路时,这些模型能否保持对原始目标的忠实度?我们提出了 DriftBench,这是一个用于评估多轮 LLM 辅助科学构思中约束遵循情况的基准测试。在涵盖七个模型(来自五个提供商,其中包括两个开源权重模型)、四种交互条件以及来自 24 个科学领域的 38 份研究简报的 2,146 次评分基准运行中,我们发现迭代压力可靠地增加了结构复杂性,并往往降低了对原始约束的遵循度。重述探测揭示了陈述性回忆与行为遵循之间的解离现象:模型能够准确重述其同时违反的约束。”知而违”(KBV)率,即衡量在保持回忆的同时违反约束的情况,在不同模型间从 8% 到 99% 不等。结构化检查点部分降低了 KBV 率,但未能消除这种解离,且复杂性膨胀现象依然存在。通过与盲评者进行人工验证,证实 LLM 评估者对约束违反的检出率偏低,导致报告的约束遵循得分趋于保守。敏感性分析表明,研究结果对温度设置(0.7 与 1.0)及压力类型(新颖性与严谨性)具有鲁棒性。我们已将所有简报、提示词、评分标准、对话记录及分数作为开放基准发布。
Paper Key Illustration
原文
Models Recall What They Violate: Constraint Adherence in Multi-Turn LLM Ideation
Abstract: When researchers iteratively refine ideas with large language models, do the models preserve fidelity to the original objective? We introduce DriftBench, a benchmark for evaluating constraint adherence in multi-turn LLM-assisted scientific ideation. Across 2,146 scored benchmark runs spanning seven models from five providers (including two open-weight), four interaction conditions, and 38 research briefs from 24 scientific domains, we find that iterative pressure reliably increases structural complexity and often reduces adherence to original constraints. A restatement probe reveals a dissociation between declarative recall and behavioral adherence, as models accurately restate constraints they simultaneously violate. The knows-but-violates (KBV) rate, measuring constraint non-compliance despite preserved recall, ranges from 8% to 99% across models. Structured checkpointing partially reduces KBV rates but does not close the dissociation, and complexity inflation persists. Human validation against blind raters confirms that the LLM judge under-detects constraint violations, making reported constraint adherence scores conservative. Sensitivity analyses confirm the findings are robust to temperature (0.7 vs.\ 1.0) and pressure type (novelty vs.\ rigor). We release all briefs, prompts, rubrics, transcripts, and scores as an open benchmark.
链接:https://arxiv.org/pdf/2604.28031
AI 深度解读
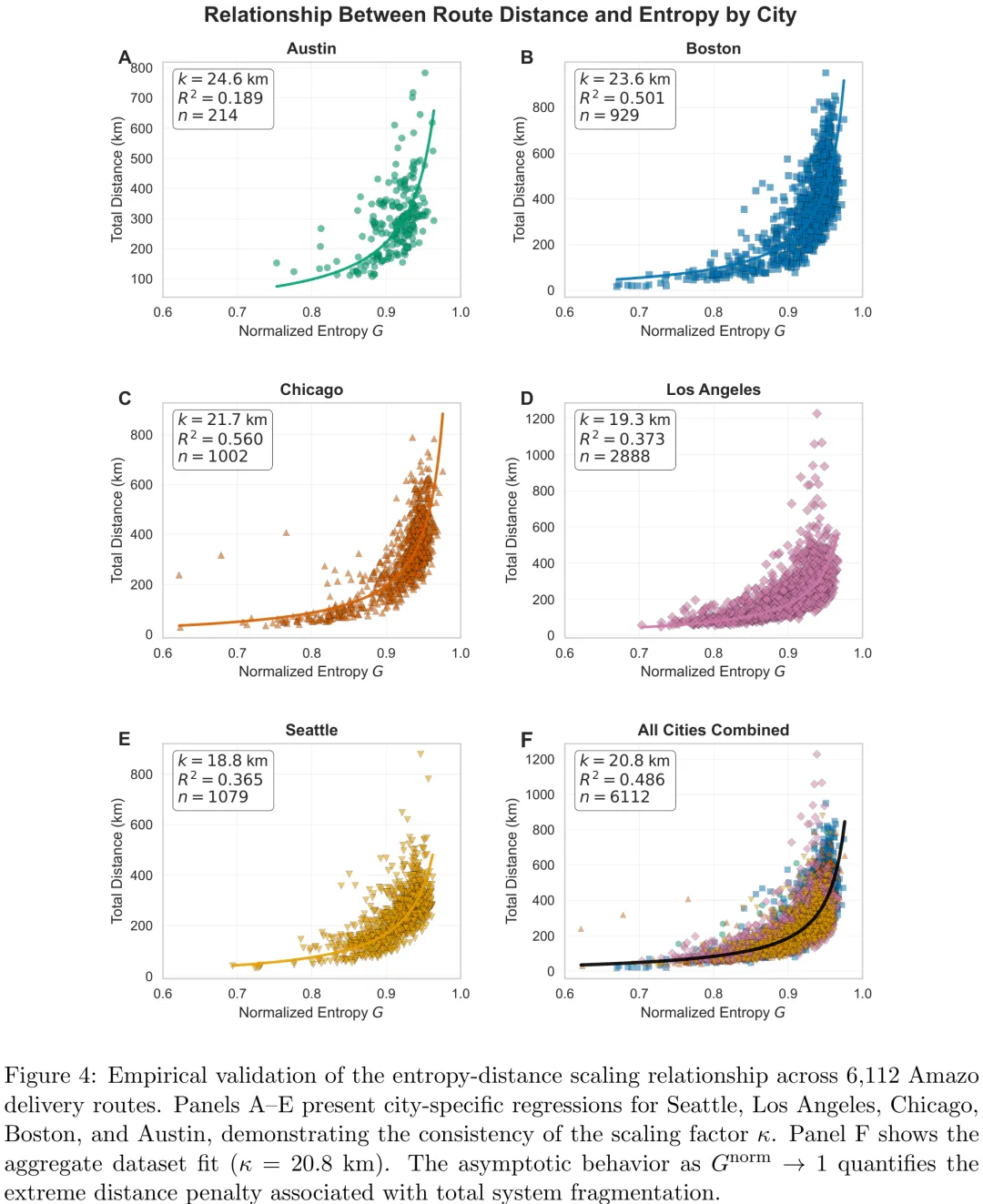
该研究深入探讨了物流系统中结构熵(G)与香农熵(H)的本质差异及其在配送优化中的守恒与破缺机制。研究首先通过斯特林近似证明了结构熵是广延量,随系统规模 N 线性增长,而香农熵作为强度量仅反映分布的相对平衡度。在此基础上,文章提出了结构熵守恒原理:在理想化的对称条件下(如奖品分发),空间整合(如设立自提点)仅将配送侧的复杂度转移至客户侧的取件过程,导致总结构熵保持不变。然而,研究进一步指出,在真实的最后一公里物流场景中,由于客户取件路径确定且包裹具有唯一性,客户侧的排列组合自由度消失,打破了守恒定律,使得总结构熵显著降低。但研究同时强调,空间整合引入了客户主动前往自提点的新移动模式,而传统熵值度量对此类新移动视而不见。因此,研究最终构建了系统-wide 熵(G_total)度量框架,将配送侧与取件侧的排列组合复杂度统一纳入考量,旨在全面评估空间整合策略对物流系统整体复杂度的真实影响,为平衡配送效率与客户取件负担提供理论依据。
中文摘要
摘要:最后一公里物流(LML)具有高度碎片化的特征,但现有研究将其视为外生约束,而非可量化且可优化的系统属性。本文提出了一种基于玻尔兹曼统计力学推导的结构熵框架,用于衡量 LML 的复杂性。与传统的关键绩效指标(如距离或成本)不同,结构熵量化了构型空间的基数,从而对系统固有的无序性进行诊断。我们建立了与香农熵的形式对偶关系,将绝对复杂性负担与分布平衡联系起来。我们将该熵框架应用于美国五个城市的 6,112 条亚马逊最后一公里路线。当前的运营表现出持续较高的归一化熵值,表明碎片化程度接近最大化。熵与路线距离之间稳定的非线性缩放关系验证了该指标作为运营难度预测指标的有效性。为评估空间整合,我们开发了一种系统级熵度量方法,涵盖承运商和客户的所有移动行为。我们确立了一个理论守恒原理:在理想化条件下,空间整合 merely 将熵从承运商重新分配给客户。然而,实践中这两个理想化条件均被违背,从而导致系统总熵增加。我们的系统级度量显示,在激进采用空间整合的情况下,承运商熵值可降低高达 40%,但由于激活了客户取件行程,系统总熵反而增加,尽管行程串联可在一定程度上减弱这一效应。相比之下,时间整合通过减少配送事件且不产生新的移动,真正降低了熵值。通过将碎片化形式化为可测量的结构属性,本研究为网络设计、整合政策制定及最后一公里系统性能评估提供了新的视角。
Paper Key Illustration
原文
On the Entropy in Last-Mile Logistics
Abstract: Last-mile logistics (LML) is characterized by high fragmentation, yet existing research treats this as an exogenous constraint rather than a quantifiable and optimizable system property. This paper introduces a framework for measuring LML complexity using structural entropy, derived from Boltzmann’s statistical mechanics. Unlike traditional KPIs such as distance or cost, structural entropy quantifies the cardinality of the configuration space, providing a diagnostic of inherent system disorder. We establish a formal duality with Shannon entropy, linking absolute complexity burden to distributional balance. We apply our entropy framework to 6,112 Amazon last-mile routes across five U.S. cities. Current operations exhibit persistently high normalized entropy, indicating near-maximal fragmentation. A stable non-linear scaling relationship between entropy and route distance validates the metric as a predictive indicator of operational difficulty. To evaluate spatial consolidation, we develop a system-wide entropy measure accounting for all movements by both carriers and customers. We establish a theoretical conservation principle: under idealized conditions, spatial consolidation merely redistributes entropy from carrier to customer. Both idealizing conditions are violated in practice, thereby increasing total system entropy. Our system-wide measure reveals that spatial consolidation reduces carrier entropy by up to 40% under aggressive adoption but increases total system entropy by activating customer collection trips, though trip chaining can diminish this effect. Temporal consolidation, by contrast, genuinely reduces entropy by decreasing delivery events without creating new movements. By formalizing fragmentation as a measurable structural property, this research provides a new lens for network design, consolidation policy, and evaluation last-mile system performance.
链接:https://arxiv.org/pdf/2605.00008
AI 深度解读
该研究提出了一种基于平均场(MF)理论的粒子滤波与积分微分(PID)控制框架,旨在解决大规模热控负载(TCL)群体的协同控制问题。研究首先通过标量 TCL 模型(Ornstein-Uhlenbeck 过程)展示了平均场桥接(MF bridge)方法相较于传统积分微分(IA)方法的优越性:MF 方法利用内生的群体均值进行自适应调节,而非依赖外生固定参考,从而在保持终端精度的同时显著降低了累积控制能耗。理论推导证明,在零漂移力(ft .= 0)和二次型势场条件下,平均场引导轨迹严格遵循连接初始与目标均值的线性插值路径,该结论独立于势场强度及分布几何形状。进一步地,研究构建了高斯混合模型下的显式得分函数,利用 Riccati 微分方程预先计算系数,实现了无需神经网络或迭代求解的闭式解析解。在需求响应场景下,该方法能够高效处理多子群(如占用与非占用建筑)的混合分布,为大规模建筑群的节能调度提供了兼具理论严谨性与计算高效性的解析工具。
中文摘要
独立样本生成是当前基于扩散的 AI 生成模型中的主流范式。我们提出一个不同的问题:样本能否通过共享的群体统计量进行\emph{协调},从而更高效地传输概率质量?我们引入了均值场路径积分扩散(MF-PID)框架,在该框架中,样本被提升为相互作用的智能体,其漂移项自洽地依赖于不断演化的群体密度。这种耦合将分布匹配问题转化为随机最优传输问题的 McKean–Vlasov 扩展形式,在统一的哈密顿–雅可比–贝尔曼/科尔莫戈罗夫–福克–普朗克对偶性下,将生成建模与多智能体控制融为一体。我们识别出两个解析上可处理的 regimes:一是线性 – 二次 – 高斯(LQG)基准情形,其中无限维的均值场系统简化为一组里卡蒂方程和线性常微分方程;二是由高斯混合分布主导的情形,其由分段常数协议控制,并保持闭式可解性。对于具有调度函数β_t且基础漂移为零的二次相互作用势,我们证明自洽的 MF 引导是初始全局均值与目标全局均值之间的\emph{精确}线性插值——该结论对任意初始和目标密度以及任意β_t均成立。将其应用于能源系统的需求响应控制,其中聚合为集合的智能体代表能源消费者(例如建筑内的热区),MF-PID 在匹配规定的终端分布的同时,相较于独立智能体基准方法,将累积控制能耗降低了 19%–24%,并揭示了协调机制如何在异质子群体之间重新分配执行努力。
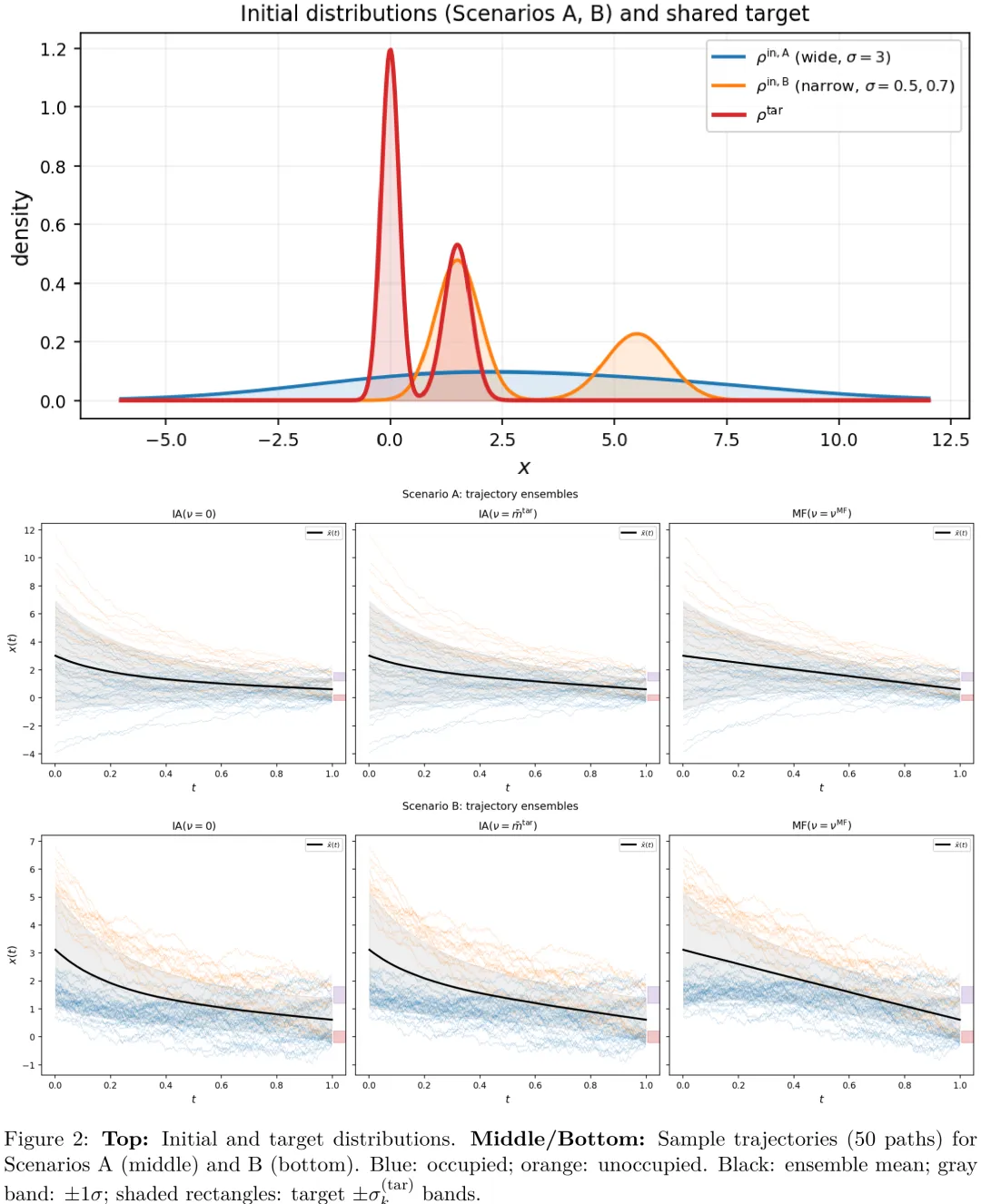
Paper Key Illustration
原文
Mean-Field Path-Integral Diffusion: From Samples to Interacting Agents
Abstract: Independent sample generation is the prevailing paradigm in modern diffusion-based generative models of AI. We ask a different question: can samples \emph{coordinate} through shared population statistics to transport probability mass more efficiently? We introduce Mean-Field Path-Integral Diffusion (MF-PID), a framework in which samples are promoted to interacting agents whose drift depends self-consistently on the evolving population density. The coupling converts distribution matching into a McKean–Vlasov extension of the stochastic optimal transport problem, unifying generative modeling and multi-agent control under the same Hamilton–Jacobi–Bellman/Kolmogorov–Fokker–Planck duality. We identify two analytically tractable regimes: a Linear–Quadratic–Gaussian (LQG) benchmark in which the infinite-dimensional mean-field system reduces to a finite set of Riccati and linear ODEs, and a Gaussian-mixture regime governed by a piecewise-constant protocol that preserves closed-form solvability. For a quadratic interaction potential with schedule β_t and zero base drift we prove that the self-consistent MF guidance is the \emph{exact} linear interpolant between initial and target global means — a result that holds for arbitrary initial and target densities and any β_t. Applied to demand-response control of energy systems, where agents aggregated into an ensemble are energy consumers (e.g.\ thermal zones within a building), MF-PID achieves 19–24\% reductions in cumulative control energy over independent-agent baselines while matching the prescribed terminal distribution exactly, and reveals how coordination redistributes actuation effort across heterogeneous sub-populations.
链接:https://arxiv.org/pdf/2605.00007
AI 深度解读
该研究聚焦于实时控制与感知系统(CPS)中的关键问题:如何在满足严格时间延迟和能量约束的前提下,优化感知模型在车载设备与云端之间的部署策略。研究以车辆紧急制动任务为例,构建了包含车载端和云端的两级计算架构。车载端虽无网络延迟但算力与能耗受限,云端则具备强大算力但受网络往返延迟影响。研究首先定义了部署时的可行性集合,即在帧间隔内满足延迟与能耗约束的模型 – 平台组合,并据此选择准确率最高的配置。针对传统平均情况分析无法应对现实网络波动与负载变化的问题,论文引入了基于 M/M/1 队列模型的分析方法,推导了考虑排队延迟后的总响应时间公式。核心结论表明,当网络传输延迟小于车载端与云端在排队效应下的有效推理延迟差值时,云端推理的总响应时间将优于车载端。这一发现揭示了在高帧率或高负载场景下,云端推理因能显著降低排队延迟而成为更优选择,从而为动态调整感知计算位置提供了理论依据。
中文摘要
摘要:随着深度神经网络(DNN)在信息物理系统(CPS)中的部署日益广泛,感知保真度得到了提升,但也给执行平台带来了巨大的计算需求,对实时控制截止时间构成了挑战。传统的分布式 CPS 架构通常倾向于在设备端进行推理,以避免远程平台上的网络波动及争用导致的延迟。然而,这种设计选择在本地硬件上造成了显著的能耗和计算负担。本文重新审视了“基于云的推理本质上不适合低延迟控制任务”这一假设。我们证明,当配备高吞吐计算资源时,云平台能够有效分摊网络延迟和排队延迟,使其在实时决策方面的性能能够匹配甚至超越设备端推理。具体而言,我们构建了一个形式化的分析模型,将分布式推理延迟表征为感知频率、平台吞吐量、网络延迟以及特定任务安全约束的函数。我们在自动驾驶紧急制动场景下实例化了该模型,并利用实时车辆动力学进行了广泛的仿真验证。我们的实证结果揭示了具体条件,在这些条件下,基于云的推理比其设备端对应方案更可靠地满足安全裕度。这些发现挑战了现有的设计策略,表明云平台不仅是可行的选项,而且往往是分布式 CPS 架构中首选的推理位置。由此可见,云并非传统认知中那般遥远;事实上,它比看起来更近。
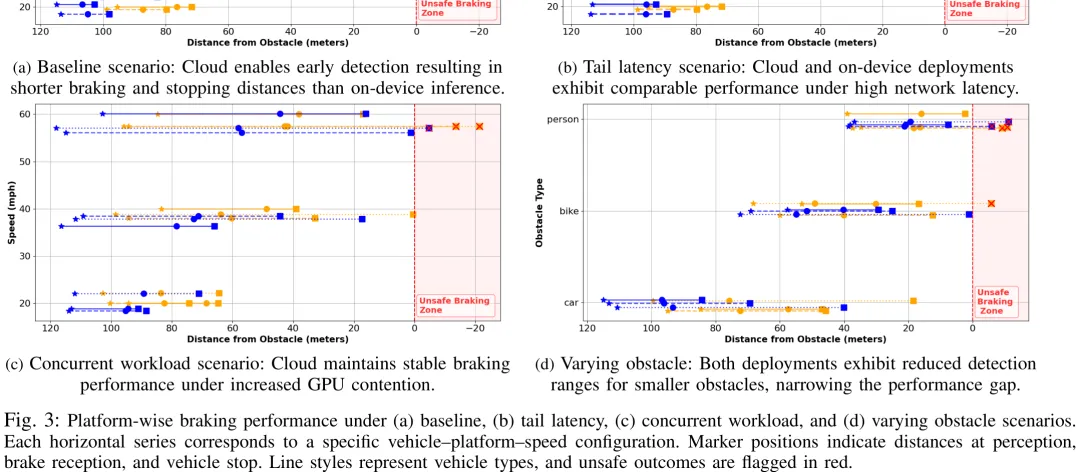
Paper Key Illustration
原文
Cloud Is Closer Than It Appears: Revisiting the Tradeoffs of Distributed Real-Time Inference
Abstract: The increasing deployment of deep neural networks (DNNs) in cyber-physical systems (CPS) enhances perception fidelity, but imposes substantial computational demands on execution platforms, posing challenges to real-time control deadlines. Traditional distributed CPS architectures typically favor on-device inference to avoid network variability and contention-induced delays on remote platforms. However, this design choice places significant energy and computational demands on the local hardware. In this work, we revisit the assumption that cloud-based inference is intrinsically unsuitable for latency-sensitive control tasks. We demonstrate that, when provisioned with high-throughput compute resources, cloud platforms can effectively amortize network and queueing delays, enabling them to match or surpass on-device performance for real-time decision-making. Specifically, we develop a formal analytical model that characterizes distributed inference latency as a function of the sensing frequency, platform throughput, network delay, and task-specific safety constraints. We instantiate this model in the context of emergency braking for autonomous driving and validate it through extensive simulations using real-time vehicular dynamics. Our empirical results identify concrete conditions under which cloud-based inference adheres to safety margins more reliably than its on-device counterpart. These findings challenge prevailing design strategies and suggest that the cloud is not merely a feasible option, but often the preferred inference location for distributed CPS architectures. In this light, the cloud is not as distant as traditionally perceived; in fact, it is closer than it appears.
链接:https://arxiv.org/pdf/2605.00005
AI 深度解读
本文针对多目标优化(MOO)问题,提出了一种基于同伦映射的预测 – 校正算法。研究首先将多目标优化中的 KKT 条件转化为一个包含同伦参数 t 的连续变形系统,该系统在 t=1 时对应于易于求解的初始状态,在 t →0 时退化为原始问题的 KKT 条件。通过构造包含加权项、约束梯度项及分数幂项的同伦函数,避免了平凡解并确保了数值稳定性。在满足线性独立约束规范(LICQ)及弱法锥条件(WNCC)等假设下,理论证明表明:对于几乎所有的初始点,该同伦映射的零集包含一条从初始点出发并延伸至原始问题解集的平滑曲线。该算法通过追踪此曲线,能够从已知解出发,全局收敛地获取多目标优化问题的帕累托前沿面上的多个有效解,有效解决了非线性多目标优化中常见的局部最优陷阱问题。
中文摘要
摘要:我们提出了一种基于同伦的框架,用于计算多目标优化问题的 Karush-Kuhn-Tucker (KKT) 点。所提出的同伦映射将易于求解的系统连续变形为与多目标问题相关的 KKT 条件,从而生成一种确定性且保持结构特性的延续路径。在满足温和正则性假设的前提下,我们证明了对于可行域内部任意选取的初始点,同伦轨迹均全局收敛于帕累托平稳解。数值实验表明,即使从非可行点初始化,该方法仍表现出鲁棒的收敛性,显示出超越理论保证的稳定性。我们采用高效的预测 – 校正延续策略来追踪同伦路径。在基准问题上的数值结果将所提方法与经典标量化方法及进化算法 NSGA-II 进行了对比,证明了其具有具有竞争力的计算效率和一致性的解的质量。这些结果凸显了同伦框架在约束多目标优化中的有效性,并推动了将其推广至更一般的问题设定及自适应参数策略。
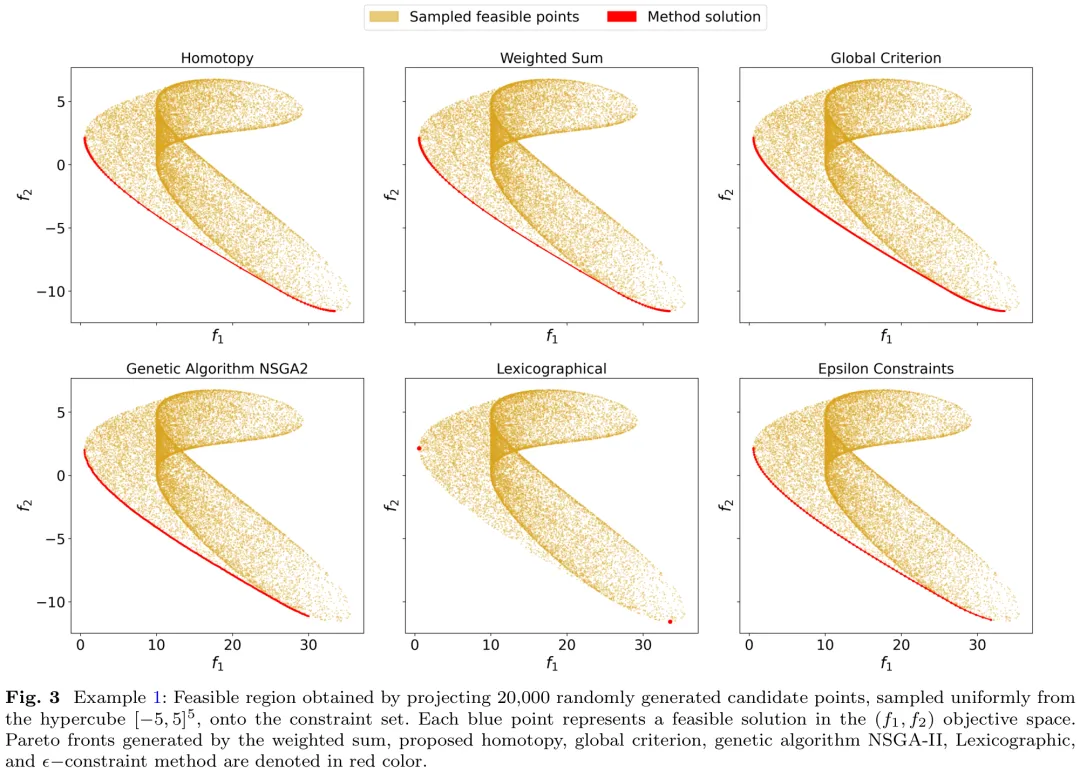
Paper Key Illustration
原文
A Homotopy Framework for Constrained Multiobjective Optimization
Abstract: We develop a homotopy-based framework for computing Karush-Kuhn-Tucker (KKT) points of multiobjective optimization problems. The proposed homotopy map continuously deforms an easily solvable system into the KKT conditions associated with the multiobjective problem, yielding a deterministic and structure-preserving continuation path. Under mild regularity assumptions, we establish global convergence of the homotopy trajectory to a Pareto-stationary solution for any initial point chosen in the interior of the feasible region. In numerical experiments, the method exhibits robust convergence even when initialized from nonfeasible points, indicating stability beyond the theoretical guarantees. Efficient predictor-corrector continuation strategies are employed to trace the homotopy path. Numerical results on benchmark problems compare the proposed approach with classical scalarization methods and the evolutionary algorithm NSGA-II, demonstrating competitive computational efficiency and consistent solution quality. These results highlight the effectiveness of the homotopy framework for constrained multiobjective optimization and motivate extensions to more general problem settings and adaptive parameter strategies.
链接:https://arxiv.org/pdf/2605.00003
Subscribe to arXiv’s Daily Preprint Notifications