 夜雨聆风
夜雨聆风





AI 不只是嘴上说说——工具调用、推理链与 Agent 的起源
【边界层 · 算法&论文】
前四期讲了模型的地基、规模化、对齐和知识边界外移。到这里,模型够强、够听话、还能查资料了——但它仍然只能”生成文字”。这一期讲的是,行业怎么让模型从”说”走向”做”。
编者按
2023 年下半年,一个词开始高频出现在每一场 AI 会议的议程里:Agent。
OpenAI 的 CEO Sam Altman 在多个场合提到,Agent 是他们最关注的下一个方向。Google DeepMind 的 Demis Hassabis 说 AI agent 是通往 AGI 的关键路径。几乎每一个大模型创业公司的路线图里,都有一个 Agent 相关的产品计划。
但如果你回到 2022 年初,这些说法会显得不太可信。当时的大语言模型能做的事情基本上就是一件:接收一段文字,返回一段文字。你问它”3.11 和 3.9 哪个大”,它可能答错。你让它查一下今天的天气,它做不到。你让它帮你订一张机票,更不可能。
从”生成文字”到”执行动作”,中间差了什么?
这一期讲的三组论文,分别打通了这条路上的三个关键环节。Chain-of-Thought 教会模型把复杂问题拆解为一步步的推理过程;Toolformer 让模型自己学会在生成过程中调用外部工具;ReAct 则把推理和行动交织在一起,让模型第一次能够在与外部环境的交互中完成多步任务。
它们不是在让模型”知道更多”——它们是在让模型”能做更多”。
一、Chain-of-Thought:先教模型”想清楚再回答”
大语言模型有一个反直觉的弱点:它们在很多”简单”任务上表现糟糕。
2022 年之前,研究者们已经反复观察到这个现象:模型能写出流畅的散文、能翻译复杂的句子,但在小学数学题上经常出错。原因其实不难理解——模型的训练目标是”预测下一个 token”,不是”先推理再回答”。当你问”一个商店有 23 个苹果,卖了 17 个,又进了 6 个,现在有多少?“,模型倾向于直接跳到答案,而不是先写出”23 – 17 = 6,6 + 6 = 12”这样的中间步骤。
2022 年 1 月,Google Brain 的 Jason Wei 等人发表了《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》,提出了一个极其简单但效果显著的方法:在 prompt 里给模型看几个包含中间推理步骤的示例,模型就能学会在回答时也展示推理过程——而且答案的准确率会大幅提升。
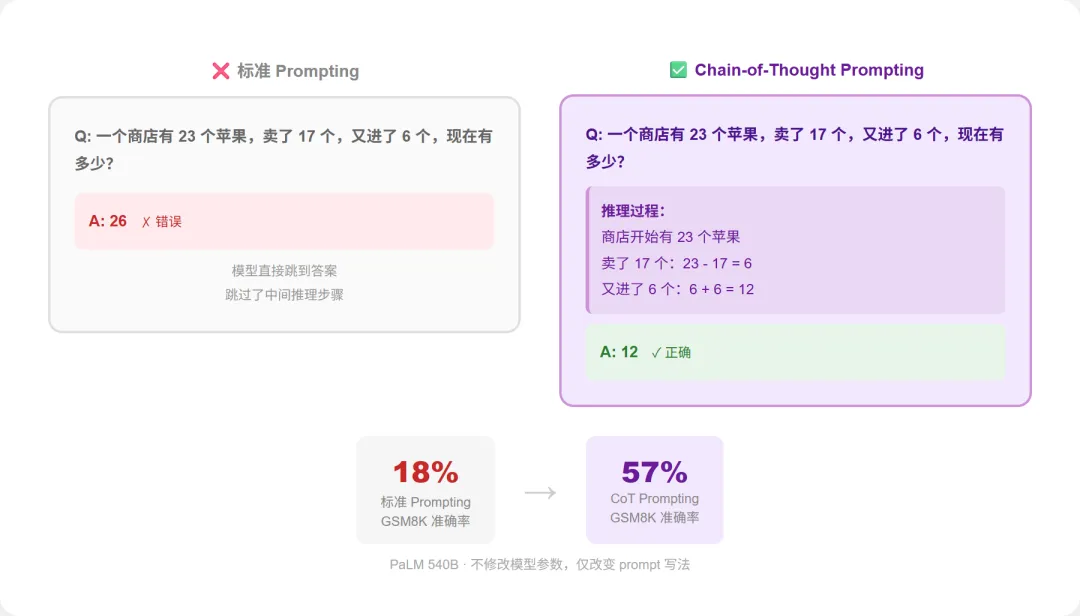
图1:标准 prompting vs Chain-of-Thought prompting 对比。左侧模型直接给出(错误的)答案,右侧通过展示逐步推理过程得到正确答案。这种方法不需要修改模型参数,只需要改变 prompt 的写法。来源:Wei et al. (2022)
这篇论文的核心数据非常有说服力:在 GSM8K(小学数学题集)上,PaLM 540B 的标准 prompting 准确率约 18%,加上 Chain-of-Thought 之后跃升到 57%。在多步推理任务上,效果提升更加明显。
Chain-of-Thought 的优雅之处在于它不需要修改模型的任何参数——你只需要在 prompt 里展示”怎么一步步想”,模型就能照着做。这让它成为了一种零成本的能力解锁手段。
但它揭示了一个更深层的发现:大语言模型不是不会推理,它是不知道该推理。 当你用适当的方式引导它,它展现出的推理能力远超直接问答时的表现。这个发现后来深刻影响了整个行业对”prompt engineering”的重视——怎么问,有时候比模型本身更重要。
Chain-of-Thought 也有明显的局限。首先,它主要在足够大的模型上才有效(论文中的实验集中在 100B+ 参数的模型)。其次,模型的”推理过程”并不总是可靠的——它可能写出看起来合理但逻辑有错的中间步骤,然后得到一个错误的结论。这种”看似在推理实则在编故事”的行为,后来被研究者们称为”忠实度”(faithfulness)问题。
但在 2022 年的语境里,Chain-of-Thought 最重要的贡献是打开了一扇门:如果模型能够拆解问题,它也许就能拆解任务。而拆解任务,是执行动作的前提。
二、Toolformer:模型自己学会了什么时候该用计算器
Chain-of-Thought 解决了”模型怎么把问题想清楚”,但一个更尖锐的问题随之而来:想清楚了之后呢?
如果推理过程中需要精确计算,模型还是会算错。如果需要查一个实时信息,模型还是不知道。如果需要翻译一段特定语言的文本,模型用自己的参数来翻不如调用专门的翻译 API。
2023 年 2 月,Meta 的 Timo Schick 等人发表了《Toolformer: Language Models Can Teach Themselves to Use Tools》,给出了一个令人印象深刻的解决方案:让模型自己学会在生成文本的过程中,在适当的位置插入 API 调用。

图2:Toolformer 的核心思路——模型在生成过程中自主决定何时插入 API 调用(如计算器、搜索引擎、翻译器等),调用返回结果后继续生成。模型通过自监督学习掌握”什么时候该用工具”的判断。参考:Schick et al. (2023)
Toolformer 的训练方式很巧妙。研究者先让模型(基于 GPT-J 6.7B)对大量文本标注”在哪些位置插入 API 调用会让预测更准确”,然后用这些标注数据做微调。关键在于,这个标注过程是自监督的——不需要人工标注,模型自己判断在哪个位置调用什么工具会带来最大的信息增益。
论文中展示的工具包括:计算器、问答引擎、搜索引擎、翻译器和日历。训练后的模型能够在生成过程中无缝地切换”自己想”和”调工具”——遇到数学题就调计算器,遇到”今天星期几”就调日历,遇到事实性问题就调搜索引擎。
这听起来像是一个技术细节的改进,但它代表了一个范式转折:模型的能力边界不再等于它参数内编码的知识和技能,而是等于它能调用的所有工具的能力之和。
如果你做过软件开发,这个逻辑应该很熟悉——它本质上和”微服务架构”是同一种思路:与其让一个巨大的单体应用什么都做,不如让它知道什么时候该调用什么外部服务。
Toolformer 的局限在于它是基于一个相对较小的模型(6.7B)训练的,在更复杂的工具编排场景下能力有限。而且它的工具调用是单步的——模型在一个位置调用一次工具,拿到结果后继续生成,但不支持多步的工具链式调用。
但 Toolformer 奠定的方向是确定的:模型不应该只是一个文本生成器,它应该是一个可以调度外部能力的中枢。这个方向在后来的 GPT-4 function calling、Claude tool use、以及各种 Agent 框架中得到了全面展开。
三、ReAct:把推理和行动交织在一起
Chain-of-Thought 教会了模型”想清楚”,Toolformer 教会了模型”用工具”。但要完成一个真实世界的复杂任务——比如”帮我查一下 XX 公司最近一季度的营收,和上一季度对比,写一段分析”——模型需要的不只是想一步或者用一次工具,而是在推理和行动之间反复切换:先想想需要什么信息 → 去查 → 看查到的结果 → 再想下一步该做什么 → 再行动。
2022 年 10 月,Princeton 的 Shunyu Yao 等人发表了《ReAct: Synergizing Reasoning and Acting in Language Models》,直接解决了这个问题。

图注:ReAct 框架——模型在解决问题时交替进行 Thought(推理)和 Action(行动),每一步行动的 Observation(观察结果)会作为下一步推理的输入。这种交织方式让模型能够在与外部环境的交互中逐步完成复杂任务。来源:Yao et al. (2022)
ReAct 的核心设计很简洁:在 prompt 中定义三种类型的步骤——Thought(推理)、Action(行动)、Observation(观察)——让模型按照”想 → 做 → 看 → 想 → 做 → 看”的循环来解决问题。Action 可以是搜索、查表、调用 API 等任何外部操作;Observation 是 Action 返回的结果;Thought 是模型基于当前信息的推理和规划。
这个设计看似简单,但它解决了之前两种方法各自的局限:
纯 Chain-of-Thought 的问题 是模型在”想”的时候可能基于错误的假设一路走下去,没有外部信息的校正。ReAct 通过在推理过程中插入真实的外部交互,让模型的推理始终建立在真实信息之上。
纯工具调用(如 Toolformer)的问题 是模型缺少对”为什么要在这个时候调这个工具”的解释。ReAct 通过显式的 Thought 步骤,让模型在每次行动之前都说明自己的推理依据,这让整个过程更可解释、更可调试。
论文在 HotpotQA(多跳问答)和 FEVER(事实验证)等任务上验证了效果,ReAct 不仅在准确率上优于纯推理或纯行动的方案,而且产生的推理轨迹更可解释、更容易发现错误。
ReAct 更大的影响在论文之外。它直接催生了 LangChain 中 Agent 模块的设计范式。如果你在 2023 年用过 LangChain 的 Agent,它的底层逻辑就是 ReAct 循环:模型接收用户请求 → 思考需要什么信息或行动 → 调用工具 → 根据返回结果继续推理 → 直到任务完成。后来 AutoGPT(2023 年 3 月)和 BabyAGI(2023 年 4 月)引发的 Agent 热潮,在技术底层上也大量借鉴了 ReAct 的范式。
对企业来说,ReAct 范式开启了一个全新的可能性空间:模型不再是一个”你问我答”的工具,它可以是一个能够自主规划和执行多步任务的代理。从”对话助手”到”任务执行者”,这是使用方式的根本转变。
但这个转变也带来了新的挑战:当模型有了行动能力,一次错误的决策可能导致真实世界的后果。在对话场景里,模型说错了用户自己会判断;在 Agent 场景里,模型可能直接发出一封错误的邮件、删除了不该删的文件、或者执行了一次错误的交易。自主性越大,安全边界的设计就越重要。
四、从生成到行动:范式转移和新的边界
把这三组论文放在一起,它们标记了大模型发展的一个关键转折点:
Chain-of-Thought 证明了大语言模型具备被引导出来的推理能力。你不需要训练一个专门的推理模型——你只需要在 prompt 中展示”怎么想”,模型就能照着做。这为后续所有需要多步思考的能力奠定了基础。
Toolformer 把模型从一个封闭的文本生成器变成了一个可以调用外部工具的中枢。它的能力边界不再是参数内编码的知识,而是所有可用工具的能力之和。
ReAct 把推理和行动交织在一起,让模型第一次能够在与真实环境的交互中完成多步复杂任务。它是后来所有 Agent 框架的直接理论源头。
这三步加在一起,完成了一次范式转移:大语言模型从一个”生成器”变成了一个”行动者”。
这个转变在 2023–2024 年迅速从论文走向产品。OpenAI 在 2023 年 6 月给 GPT-4 加入了 Function Calling 能力,本质上就是 Toolformer 思路的产品化。Google 推出的 Gemini 也内置了工具调用和多步推理能力。Anthropic 的 Claude 在 2024 年加入了 Computer Use 功能——模型不只是调用 API,它可以直接操作屏幕上的图形界面。
开源社区的响应更加激进。2023 年 3 月,AutoGPT 在 GitHub 上线不到一周就拿到了超过 10 万 stars,成为 GitHub 历史上增速最快的项目之一。它的核心理念直接来自 ReAct 范式:给模型一个目标,让它自己规划步骤、调用工具、执行任务,人类只需要在关键节点审核。虽然 AutoGPT 本身在实际效果上远未达到它的愿景——任务成功率很低、成本很高、容易陷入循环——但它引爆的想象力是真实的。
到 2024–2025 年,Agent 的落地开始从”炫酷 Demo”走向”实际可用”。Coding Agent(比如 GitHub Copilot Agent、Cursor 的 Agent 模式)能够自主阅读代码库、定位 bug、提交修复。Customer Service Agent 能够在多轮对话中查订单、改地址、发起退款。Data Analysis Agent 能够接收一个分析需求,自动拉取数据、写 SQL、生成图表、撰写摘要。
但行业也在这个过程中学到了一些教训。
可靠性比自主性更重要。 在企业场景里,一个 90% 准确但 10% 会出严重错误的 Agent,不如一个 80% 准确但错误可控的 Agent。现在的最佳实践是”Human-in-the-Loop”——Agent 可以自主执行大部分步骤,但在关键决策点需要人类确认。
评估体系远未成熟。 怎么评估一个 Agent 的表现?不能只看最终结果对不对,还要看过程是否合理、成本是否可接受、在边界情况下的行为是否安全。这方面行业还在探索。
系统设计比模型选择更重要。 Agent 的表现不只取决于底层模型的能力,还取决于工具定义的清晰度、上下文管理策略、错误恢复机制、以及整体的编排逻辑。最好的模型配上糟糕的系统设计,效果不如次好的模型配上精心设计的工作流。
边界层笔记
-
Chain-of-Thought 的发现意义远超”一种 prompt 技巧”。它证明了大语言模型的推理能力是可以通过恰当的引导被激活的,这改变了行业对”模型能做什么”的判断框架。 -
Toolformer 提出的”模型自己学会用工具”的范式,后来在 GPT-4 Function Calling、Claude Tool Use 等产品中全面落地。模型的能力边界 = 参数能力 + 可调用工具的能力,这个等式现在已是行业共识。 -
ReAct 是 Agent 浪潮的学术起点。LangChain Agent、AutoGPT、BabyAGI 的底层逻辑都可以追溯到”推理-行动-观察”的循环范式。 -
Agent 落地的最大教训不是”模型不够强”,而是”系统设计跟不上”。工具定义、上下文管理、错误恢复、人机协作边界——这些工程问题往往比模型能力本身更决定最终效果。 -
从文本生成到自主行动,这是大模型发展最大的范式跃迁。但自主性越大,安全边界的设计就越重要。在”让 AI 做更多”和”确保 AI 不做错”之间的平衡,将是未来几年行业最核心的命题。
参考资料
-
Wei et al., Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS 2022. -
Schick et al., Toolformer: Language Models Can Teach Themselves to Use Tools, NeurIPS 2023. -
Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models, ICLR 2023. -
Karpas et al., MRKL Systems: A Modular, Neuro-Symbolic Architecture that Combines Large Language Models, External Knowledge Sources and Discrete Reasoning, arXiv 2022. -
Wang et al., Voyager: An Open-Ended Embodied Agent with Large Language Models, arXiv 2023. -
Significant Gravitas, AutoGPT: An Autonomous GPT-4 Experiment, GitHub 2023.
科里 Coralyx · 2026-04
论文影响力地图 #1|Transformer、BERT、GPT-3:大模型时代的三块地基
论文影响力地图 #2|460 万美元训一次,值吗?规模化的账本、配方和折衷