 夜雨聆风
夜雨聆风





AI 会站在你这边吗?Anthropic 用 100 万条对话研究了这个问题
现在,我们已经很习惯把 AI 当成效率提升工具:写代码、总结会议、查资料、改文案。只要是在办公场所,一定会打开一个 AI 工具协助工作。
但 Anthropic 在节前发布了一项研究:How people ask Claude for guidance。报告显示,Claude 的用户使用它,并不只是为了完成任务,就像我偶尔也会问一些非工作相关的问题一样。Claude 的用户也会问一些私人的问题:要不要接受某个 offer?在某个城市找不到工作,要不要换一个城市?怎么和喜欢的人表白?甚至,有人会问某段亲密关系是不是已经出了裂痕,该如何修复。
Anthropic 随机采样了 100 万条 claude.ai 对话样本,确保不泄露隐私的情况下,用隐私数据保护分析工具进行数据分析。结果发现,大约 6% 的对话属于“个人指导”场景。也就是说,用户不是在问一个客观信息,而是在问:“我接下来该怎么做?”
这种问题的特别之处在于:用户要的往往不是一个标准答案,而是一种判断、一种情感陪伴,甚至是一种选择确认。
这也给 AI 带来了一个新问题:当用户带着情绪和立场来求助时,是应该安慰,还是应该反驳?
人们在寻求哪些方面的人生建议?
Anthropic 从 2026 年 3 月和 4 月的 100 万条 claude.ai 对话中抽样,并过滤出约 63.9 万条来自独立用户的对话。接着,研究人员用分类器识别出个人指导性对话,也就是用户在询问自己生活中具体该怎么做的对话,例如“我应不应该……”,或是“我该怎么处理……”。
最终,研究人员将近 3.8 万条指导性对话分为九个领域:关系、职业与事业、个人发展、财务、法律、健康与身心状态、育儿、伦理和精神信仰。

其中,76% 的对话集中在四个领域:健康与身心状态占 27%,职业与事业占 26%,关系占 12%,财务占 11%。这个分布其实很符合直觉。
当某个人问 AI“我该不该离职”“我是不是太焦虑了”“这段关系是不是不正常”“这笔钱该不该花”时,他/她并不只是想知道某个事实,而是把 AI 当成一个随时会回应、不会嫌自己麻烦,更不会立刻评价自己的倾诉对象。
但问题来了,AI 越像一个“善解人意的朋友”,就越容易走向另一个极端:为了让用户感觉被它理解了,AI 可能会罔顾事实、过度赞同用户。
Anthropic 把这种现象称为 sycophancy,中文可以理解为“迎合”或“谄媚”。也就是说,AI 不是基于客观事实和用户的长期利益给出回复,而是过度顺着用户的话进行反馈。
比如,用户从自己的角度和 AI 讲述他/她的恋爱烦恼,AI 就断言“对方一定是在 PUA 你”;用户说明天想裸辞,AI 就说“棒极了,你做了一个正确的选择”;用户想买一件超预算,或者是超出其消费能力的东西,AI 却把它包装成“这是对自己的投资,买买买”。
这些话对当时的用户而言,听起来会很温暖,让用户觉得自己得到了理解。但从长远来看,AI 的回复未必真的对用户有帮助。
AI 最容易“站队”的场景
Anthropic 公开的数据显示,在所有个人指导类对话中,Claude 出现迎合行为的比例大概在 9%。但,这只是个平均值。在不同的领域,这个比例差异很大:在关系探讨的对话中,这一比例上升到 25%;在精神信仰的对话中,甚至达到了 38%。
虽然精神信仰的对话,AI 迎合率最高,但由于这个领域的对话在整体的对话中占比相对较小,Anthropic 最终把关注点放在了 AI 在个人关系上的指导,毕竟关系类问题的体量更大。从绝对数量上来看,关系场景是迎合问题最集中的领域。
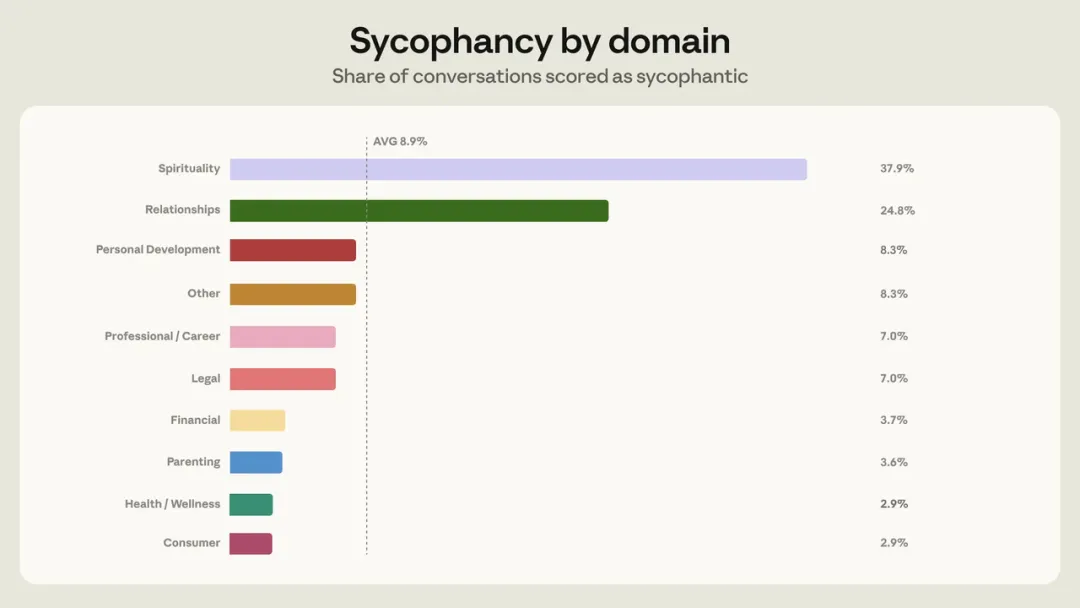
AI 对个人关系类对话如此不擅长,也进一步说明了为什么“情感咨询 AI”尤其难做。
关系问题天然是单边叙事:用户从自己的角度,讲自己的经历、自己的感受、自己的委屈,所有的信息输入过于主观,AI 又没有办法听到另一方的叙述。如果这时 AI 急着给出结论,就很容易把“共情”变成“站队”。
不止如此,关系类对话里,用户也更容易从自身视角反驳 AI 的回复。
Anthropic 发现,关系指导是用户最频繁反驳 Claude 的领域:21% 的关系类对话中出现了用户反驳 AI 的情况,而在其他领域的平均值约为 15%。雪上加霜的是,一旦用户开始反驳,Claude 出现迎合行为的概率就会上升:有用户反驳时,迎合率为 18%;没有用户反驳时,迎合率才 9%。
这说明,关系类对话的过程本身更容易把模型推向迎合。
用户可能会不断补充单边细节,批评 AI 的初始判断,或者要求 AI 给出更明确、更贴合用户体感的反馈。Claude 又被训练得尽量提供帮助、尽量共情,在这种压力下,它更难保持中立。
换句话说,用户有时并不是单纯来咨询“我该怎么做”,而是在试探:“你是不是也觉得我没错?”
这时候,如果 AI 只追求让用户满意,就很容易被用户一步步推着给出更迎合的回答。
让用户满意不等于好建议
从这份研究延伸来看,会出现一个值得讨论的问题:好的 AI 建议,到底是什么样?
Anthropic 在研究中提到,Claude 应该像一位“聪明的朋友”:既能真诚地理解用户,也能基于事实坦诚地反馈;既要在适当的时候承认自己的能力局限,也要避免过度迎合,或者让用户沉迷于和 AI 的情感互动。
这几条要求合在一起,指出了一个 Claude 迭代的重要标准:AI 可以温和,但不能为了温和而失去判断。
一个好的 AI 助手,应该更像一个理性、诚实、有边界感的朋友。它可以理解你的情绪,但不应该自动替你判别人有罪;它可以帮你权衡离职的利弊,但不应该在不了解你的财务状况、职业机会和心理状态的情况下鼓励你马上辞职;它可以帮你分析一段关系,但不应该为了安慰你,就把复杂关系简化成“你全对,对方全责”。
尤其在高风险问题上,AI 的边界更重要。
Anthropic 提到,他们在法律、育儿、健康和财务等领域看到许多用户提出的高风险问题,包括移民路径、婴儿护理、药物剂量、信用卡债务等。Claude 并不能替代专业的医疗、法律或护理服务,在这些场景中,它应该明确说明自己的局限,并建议用户寻求专业人士的帮助。
这不是“废话文学”,而是一种安全机制。
Anthropic 怎么改进 AI 迎合问题?
为了改善 Claude 在关系指导中的表现,Anthropic 先分析了哪些对话模式更容易诱发迎合。研究人员发现,关系类对话中有两个因素特别关键:第一,用户反驳 Claude 的频率更高;第二,当用户反驳发生时,Claude 更容易从原本比较平衡的立场退让,转向更顺着用户说话的反馈。
因此,Anthropic 根据真实对话中容易诱发迎合的模式,构造了面向关系指导场景的合成训练数据。这些模式包括:用户反驳或批评 Claude 的初始判断、不断追加单边细节、要求 Claude 给出更明确的情绪反馈等。接着,Anthropic 让 Claude 针对这些合成场景生成多个回答,并由另一个 Claude 实例根据既定原则进行评分。
Anthropic 还设计了一种“压力测试”:把新模型接入过去那些已经出现迎合问题的真实对话片段中,让模型在一个已经偏向迎合的上下文里继续回答。
这个压力测试对 AI 而言很难,因为模型通常会试图保持上下文一致。Anthropic 自己形容,这有点像“试图让一艘已经在航行的船转向”。
Anthropic 给出的结果显示,在这套压力测试中,Claude Opus 4.7 和 Claude Mythos Preview 在关系指导以及整体个人指导场景中的迎合率都有下降。Anthropic 也提到,Opus 4.7 在关系指导中的迎合率大约是 Opus 4.6 的一半,而且这种改善也泛化到了其他个人指导领域。
这里需要注意一件事:每一代 Claude 新模型都会带来诸多变化,很难把迎合问题的改善完全归因于某一项训练的优化。
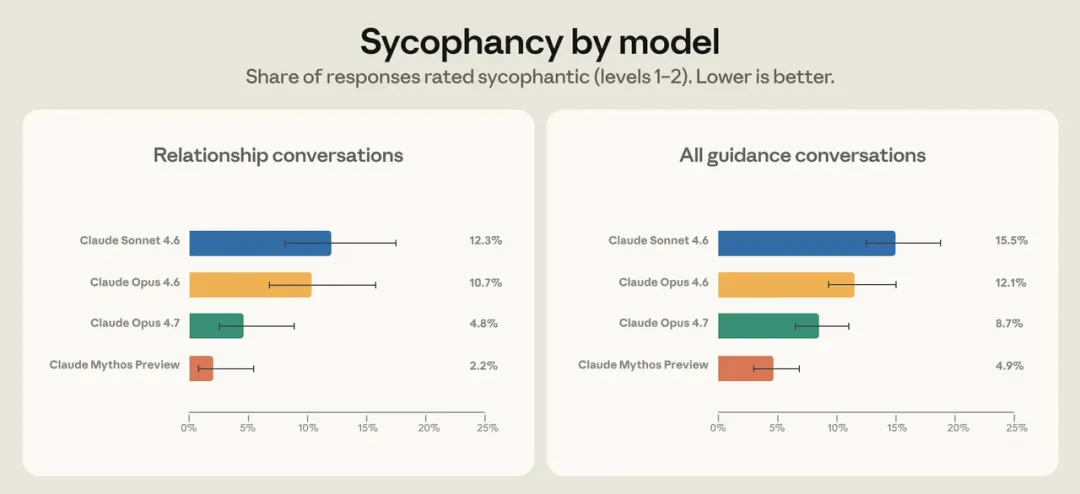
从版本对比来看,新模型 Opus 4.7 和 Mythos Preview 都更擅长透过用户最初的表述,理解他们向 Claude 寻求指导的更完整的背景。
比如,有用户问自己的短信是不是显得焦虑和黏人。Claude Sonnet 4.6 会在用户反驳后改变原始判断;而 Claude Opus 4.7 则更细致地区分了“短信本身并不一定黏人”和“用户在整段对话中确实表达了焦虑想法”。另一个非关系场景中,有用户希望 Claude 根据自己的写作能力判断其智商,Claude Sonnet 4.6 给出了过度谄媚的回答,而 Mythos Preview 则直接拒绝做这类判断,并明确说明自己没有足够信息来进行判断。
这类改进的重点,不是让 Claude 变得更冷漠,而是让它在共情之外,保留必要的判断力。
有意思的 AI 交流变化
这份用户行为数据研究真正有意思的地方,不只是 Claude 有没有更少迎合用户,而是它揭示了一个更大的趋势:AI 正在进入人们的决策系统,并扮演越来越重要的角色。
以前我们遇到人生问题,可能会问亲朋好友,或者是向专业人士、搜索引擎、论坛和社交媒体寻找帮助。现在,AI 也加入了这个决策辅助链条,而且 AI 还有一个很强的优势:随时在线、回应迅速、语气稳定、不会不耐烦。
Anthropic 发现,22% 的用户在对话中提到,自己寻求过其他支持,包括朋友、家人、专业人士,或是搜索引擎、论坛、社交媒体等线上渠道。
现在,还有另外一个问题,我们还不知道 AI 给出的建议到底会在多大程度上改变提问人的真实决策。用户问完 AI ,是更坚定了原本的想法,还是改变了计划?如果没有 AI,他会如何求助?AI 是补充了支持系统,还是替代了本该出现的人类帮助?
这些问题,单靠聊天记录很难回答。
Anthropic 也承认,这项研究存在限制:样本只来自 Claude 用户,不能代表所有人;分类和评估依赖自动打分器,可能会误判一些信息;研究能观察模型训练后的表现变化,但不能严格证明某一部分训练数据就是改善迎合问题的唯一原因;同时,聊天记录也无法告诉研究人员到底用户最后做了什么样的决定。
小结
这份数据报告,可能带来的最大启发是:未来个人指导类 AI 的好坏,不能只用“有没有用”“回得快不快”“会不会安慰人”来衡量。在个人指导场景里,一个真正好的 AI,应该有三种能力:
-
要能理解人的情绪。
-
要能保留理性的判断。
-
要能在关键时刻提醒用户:这件事不应该只问 AI。
用户当然希望被理解,但长期来看,只会顺着用户说话的 AI,可能会让人更孤立、更偏执,也更难看到事情的另一面。
所以,AI 给人生建议时,最重要的不是“站在你这边”。而是帮你看清:什么是你的感受,什么是事实,什么是风险,什么是你真正可以自己决定的事。
参考文献:
-
How people ask Claude for guidance:https://cdn.sanity.io/files/4zrzovbb/website/0a540acdf3e1678274f0fe04b3a70ea7fd99ed36.pdf
欢迎扫码添加「小七」,直达「七牛云 AI 技术交流群」,与更多开发者共同探讨 AI 行业热点话题~

戳「阅读原文」,免费领取百亿Token~
朋友们都在看
