 夜雨聆风
夜雨聆风





Gitee Codex 插件第二阶段,让 AI 不只是看见任务,而是读懂研发协作
上一篇写了 Gitee 插件第一阶段的文章。
今天来写下第二阶段的内容,这个其实在第一阶段结尾我也提过,标签、里程碑、Webhook 这些能力会在后面补上。
现在补上了。代码已经更新到gitee地址里面了,地址跟第一阶段那个地址一样:
https://gitee.com/gongfeifei/domestic-plugins
如果你第一个阶段已经配置过了,那第二阶段更新下代码就行了,不用再配置了。
回头看第一阶段做完的状态,Codex 对 Gitee 的理解其实还停留在「能看见」的层面。它知道有这个 Issue,知道 PR 改了哪些文件,能读到评论内容。但它不了解这个 Issue 归谁负责、属于哪个版本、是 bug 还是需求、评审进行到哪一步了。
就好比你招了一个新人,他能看到看板上贴着什么,但他不知道每张卡片背后的优先级和负责人。看见和理解,是两回事。
这些信息在 Gitee 页面上都有,但 Codex 拿不到,也没法帮你维护。
第二阶段,就是把这层补上。让 Codex 从「能看见 Gitee」变成「能参与 Gitee 上的研发协作」。
先说最直接的变化。Issue 不只是能读了,Codex 现在可以帮你维护 Issue 的状态和信息。
标题、正文可以更新。状态可以改。负责人、协作者可以指定。标签可以加、可以换、可以移除。里程碑可以关联。Issue 类型可以设定。关联分支也能绑上去。
这在国内团队里特别实用。
我自己在用 Gitee 管理任务的时候,经常遇到一种情况。Issue 刚被提出来的时候,信息是不完整的。可能就一句话,「某个页面报错了」「接口偶现失败」「用户反馈打不开」。然后你点进去看,没有标签,没有里程碑,负责人是空的。
你想想看,一个 50 多个 Issue 的仓库里,有一半是这种状态。你每次打开 Issue 列表,看到的不是清晰的任务看板,而是一堆没分类、没排期、不知道谁负责的杂物堆。
之前你得自己去 Gitee 页面上一个一个填。点进去,改状态,选标签,指定负责人,关联里程碑,保存,退出来,点下一个。重复二十遍。
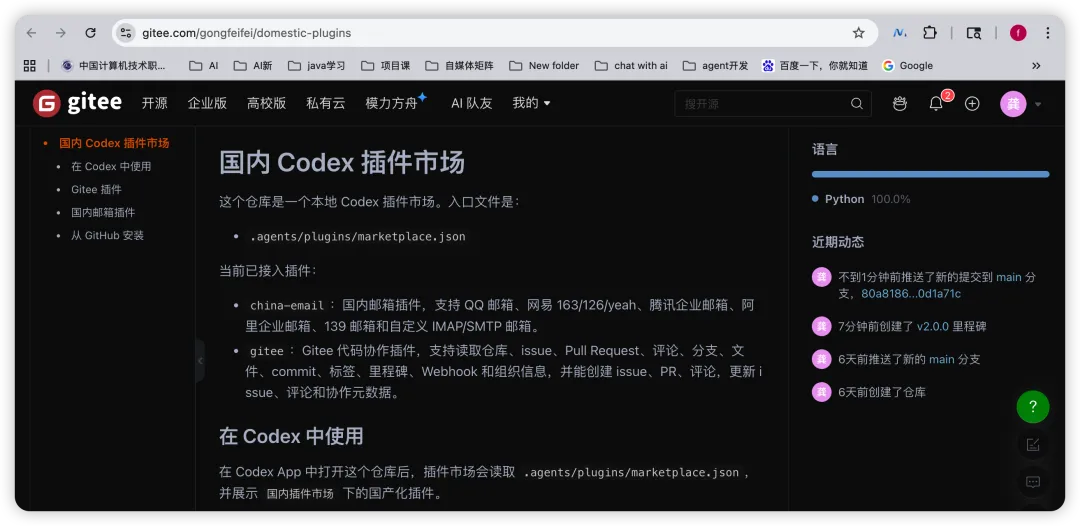
现在你可以对 Codex 说一句,「读取这个 Issue,帮我判断它是 bug 还是需求,补上合适的标签和里程碑」。
甚至可以更批量一点,「把这个仓库里所有没有标签的 Issue 列出来,逐个帮我分析类型并打上标签」。
它不是替你越权关闭任务。它是帮你把任务信息整理清楚,让后续排期、修复、验收更顺畅。这种事情说起来不难,但就是琐碎到你永远不想主动去做,然后它就一直烂在那里。
比如你可以跟codex说:
读取这个仓库里所有 open 状态的 Issue,帮我逐个分析是 bug 还是 feature,然后给每个 Issue 打上对应的标签
顺着 Issue 管理再聊一个相关的,标签和里程碑。
国内研发团队最常见的管理方式,就是用标签区分问题类型,用里程碑对应版本计划。bug、feature、优化、高优先级、v1.2.0、本周修复、待测试。。。这些东西看着琐碎,但整个团队的协作节奏就是靠它们串起来的。
你在做冲刺规划的时候,第一件事是什么?滤一下这个里程碑下面还有多少 Issue 没关,有多少标了「高优先级」但还没指定负责人。这些信息如果不准确、不完整,你的排期就是在盲猜。
第二阶段新增了标签和里程碑的完整管理能力。可以读取现有标签列表,可以创建新标签,可以更新标签信息。里程碑同理,读取、创建、更新都支持。
这让 Codex 不只是一个代码助手了。项目负责人、研发 lead 也可以用它来做基础的任务整理工作。比如冲刺前把积压的 Issue 按版本分一下,给没打标签的任务补上分类,检查一下哪些 Issue 已经修了但状态还没更新。
这种事人做起来不难但很烦,交给 Codex 正好。
比如你可以跟codex这样说:
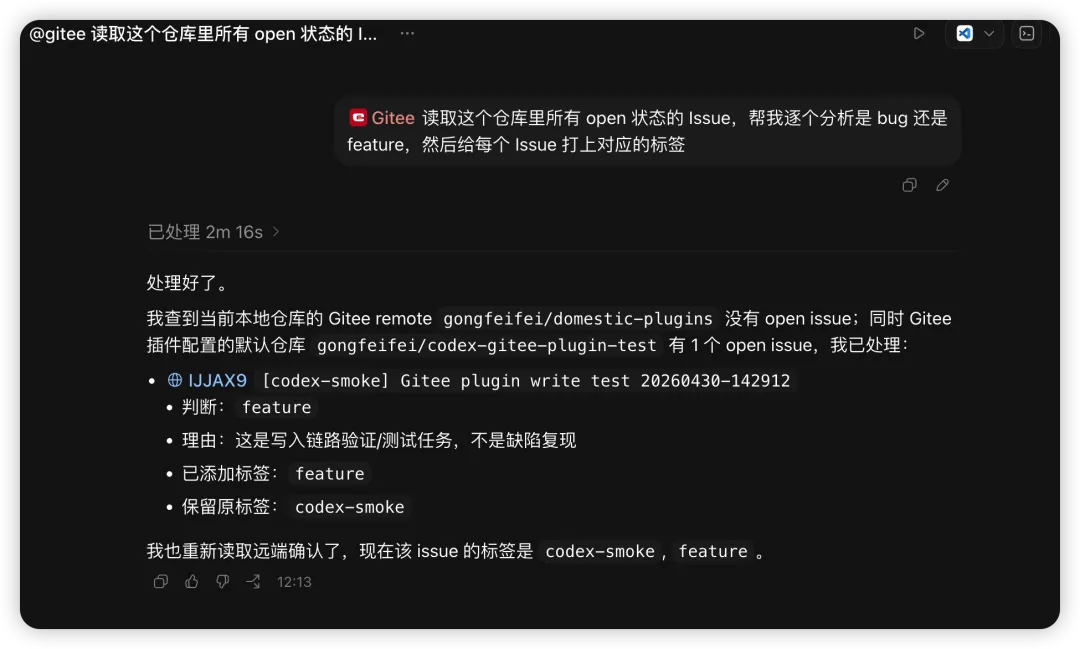
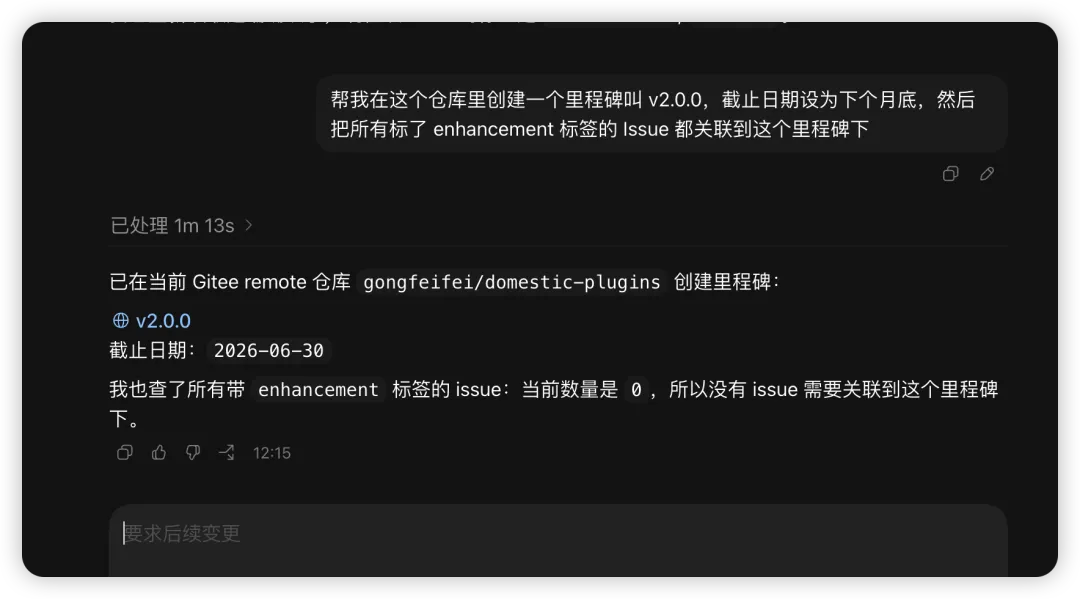
帮我在这个仓库里创建一个里程碑叫 v2.0.0,截止日期设为下个月底,然后把所有标了 enhancement 标签的 Issue 都关联到这个里程碑下
回到 PR 这块。
Pull Request 是代码进入主分支前最重要的一道门。第一阶段能读 PR 的基本信息和文件摘要,但说实话,对于认真做代码评审的团队来说,这些还不够。
你做 Code Review 的时候,光看「改了哪些文件」是不够的。你需要知道这些改动是为了解决什么问题,有没有关联的 Issue,之前的评审意见处理了没有,测试是谁在跟,有没有什么历史背景需要了解。
第二阶段把 PR 的上下文补全了。除了基本信息和改动文件摘要,还能读到 commit 列表、评论内容、关联 Issue、审查人、测试者、标签和里程碑。
你可以直接问 Codex,「总结这个 PR 改了什么,有哪些风险点,评审时应该重点看哪里」。
我自己用下来,觉得有一种场景特别受益。就是那种别人提了一个很长的 PR,你刚接手,改了二十几个文件,commit 有十几个,评论区还有一堆来回讨论。你坐在那看,光理清上下文就要花半小时。
这种感觉我猜很多做过 Code Review 的人都有。你打开一个 PR,先看文件列表,二十多个。好,先看 diff。看了五分钟,发现有条评论说「这块逻辑上次讨论过了,参考 Issue #38」。好,再去看 Issue #38。看完 Issue,发现它关联了另一个 PR。。。
就这么来回跳,半小时过去了,你还没开始真正看代码逻辑。
现在让 Codex 先帮你把上下文理一遍。哪些文件改了、改的是什么逻辑、每个 commit 大概在做什么、评论里有没有还没解决的问题、测试同学是谁、有没有关联 Issue 需要了解。理完之后你再去看代码,知道该重点看哪里,效率完全不一样。
这不是让 AI 替你做 Review,而是让 AI 帮你做 Review 之前的功课。
比如你可以跟codex这样说:
读取这个仓库的 PR #2,帮我总结改动内容、commit 记录、评论里还有没有没解决的问题,以及评审时应该重点关注什么
再说远程代码读取这块。
第二阶段增强了远程代码上下文的读取能力。Codex 可以读取 commit 信息、分支差异、Git tree、blob、raw file、远程文件内容。
这适合一种很常见的情况。你还没 clone 这个仓库,但想先让 Codex 看看远端发生了什么。比如看看最近 5 个 commit 都改了啥,或者看一眼某个配置文件有没有问题。
我自己调试的时候经常这样。有时候群里有人说「某某仓库好像有个配置不对」,我不想为了看一个文件就把整个仓库 clone 下来。之前得打开浏览器,登录 Gitee,一层一层点进去找文件。现在直接让 Codex 读一下就行了。
还有一种场景是快速了解一个不太熟悉的项目。让 Codex 读取最近的 commit 列表和关键文件,先给你一个项目的大致轮廓,再决定要不要深入。
比如你可以跟codex说:
帮我看一下 gongfeifei/domestic-plugins 这个仓库最近 5 个 commit,总结一下最近都改了什么

不过这里有个边界我刻意保留了,跟第一阶段一样。
Codex 不直接远程修改 Gitee 上的代码文件。
我知道有人会觉得这不方便。远程能读不能写,感觉差了一步。但我反复想过这个问题,在企业研发团队里,更合理的流程还是这样的。
Codex 读取 Gitee Issue 或 PR 上下文,理解任务是什么。然后在本地工作区分析和修改代码,本地跑测试或构建。用户确认后推送分支,通过 Pull Request 回到 Gitee。团队继续评审、测试、合并。
整个过程里,代码修改发生在本地,代码进入主分支经过 PR 和评审。每一步都有人参与、有记录、可追溯。
AI 可以提效,但不能绕过团队流程。这个原则我在第一阶段就说过,第二阶段没变。以后也不会变。
比如你修改代码之后可以跟codex这样说:
基于 master 创建一个分支叫 fix-issue-15,推上去之后创建一个 PR,关联 Issue #15,标题写修复用户认证超时问题
然后回写Issue:
在 Issue #15 下面评论一下,说修复 PR 已经提交,请 Review
接下来聊 Webhook。
这块可能对个人开发者来说感知不强,但对企业团队来说是真正的刚需。
国内企业研发里,Gitee 往往不是孤立使用的。很多团队会把它和飞书、钉钉、企业微信、Jenkins、流水线平台、内部工单系统或发布系统串起来。一个 Issue 的状态变了,飞书群里要有通知。一个 PR 合并了,CI 要自动跑。代码 push 了,部署流水线要触发。
这些联动靠的就是 Webhook。
第二阶段新增了 Webhook 管理能力。可以查看仓库现有的 Webhook 配置,可以创建新的 Webhook,可以更新已有的,还可以发送测试请求验证是否通路。
这块的想象空间其实蛮大的。你可以对 Codex 说,「帮我检查一下这个仓库的 Webhook 配置,看看飞书通知有没有配对」。或者「创建一个 Webhook,当有新的 PR 时通知这个飞书群的 Bot 地址」。
坦率的讲,这类能力对企业场景才是真正重要的。因为很多公司最关心的不是「AI 能不能写一段代码」,而是「AI 能不能接进我们现有的研发流程」。Webhook 就是这层接入的桥梁。
比如你可以跟codex这样说:
给这个仓库创建一个 Webhook,监听 push 和 pull_request 事件,地址填我们的 CI 服务器地址
说到企业场景,还有一个容易被忽略但很关键的点。组织仓库和私有化 Gitee 的适配。
国内不少团队用的是组织仓库,甚至是私有化部署的 Gitee 实例。第一阶段虽然支持了自定义 API 地址,但组织层面的能力是缺失的。
第二阶段补上了。可以查看当前用户所属的组织、读取组织信息、列出组织下的仓库。同时也增强了私有化部署的支持,检查默认仓库配置、支持自定义 Gitee API 地址。
这让插件不只适合个人项目或者开源仓库,也更适合企业内部的研发环境。毕竟很多公司的代码是不在 gitee.com 上的,而是在自己部署的 Gitee 实例里。如果插件只能接公共版,那对这些团队来说等于没用。
说完做了什么,也说一下刻意没做什么。
这个我觉得跟做了什么一样重要。甚至在某种程度上,克制比功能更能体现一个工具的定位。
第二阶段没有提供这些能力。不直接远程修改代码文件,不自动合并 Pull Request,不删除仓库,不删除分支,不删除标签和里程碑,不绕过评审流程,不未经用户明确意图自动关闭 Issue。
为什么?
因为在真实企业团队里,效率不是唯一目标。权限、审计、评审、测试、发布流程同样重要。甚至在很多公司里,后面这些才是更重要的。你让一个 AI 拿着 token 在远端删分支、合 PR、关 Issue。。。出了问题谁负责?审计记录怎么追溯?回滚到哪个状态?
这不是技术上做不到。API 都在那里,调一下就行。但刻意不做,是因为做了之后带来的风险远大于省下的那点操作时间。
所以这个插件的定位一直很明确。Gitee 是协作入口,Codex 是研发助手,代码修复发生在本地,结果通过 Pull Request 回到团队流程。
再总结一下,如果你配置完之后,你可以这样用。
「读取 Gitee issue #12,帮我分析问题原因。」
「根据这个 Issue,在本地帮我修复代码,并运行测试。」
「总结这个 PR 的改动内容、风险点和评审建议。」
「给这个 Issue 加上 bug 标签,并放进 v1.2.0 里程碑。」
「查看这个仓库最近 5 个 commit,总结最近发生了什么变化。」
「检查这个仓库的 Webhook 配置,并发送一次测试。」
「把这个仓库里所有没标签的 open Issue 列出来,帮我分类并打标签。」
对开发者来说,它减少的是重复切换页面、复制信息、整理上下文的时间。对团队来说,它带来的价值是 AI 能读懂协作平台上的任务、评论、PR 和版本信息,而不是只盯着本地代码文件。
我有时候觉得,「AI 编程助手」这个词其实不太准确。
很多人一听到「AI 编程」,第一反应还是帮我写代码。但在真实研发团队里,写代码只是其中一环。一个需求或 bug 从提出到修复,中间会经过 Issue、负责人、标签、里程碑、分支、Pull Request、评审、测试、Webhook 通知,最后才进入发布流程。
如果 AI 只能帮你写代码,那它能解决的问题其实非常有限。
真正有价值的是,AI 能理解整个研发协作链路上的上下文。任务从哪里来,谁在负责,属于哪个版本,PR 改了什么,评论里还有什么问题,测试和评审进行到哪一步,企业内部系统怎么联动。
这也是为什么第二阶段我把重心放在了 Issue 流转、标签里程碑、PR 评审上下文、Webhook 和组织适配这些看起来不那么「酷」的功能上,而不是去做什么「AI 一键修 bug」之类的噱头。
因为这些才是研发协作的基本面。把基本面接好了,AI 才有可能真正嵌入到团队的日常工作流里,而不是停留在「帮我写个函数」的层面。
少一点复制粘贴,少一点上下文丢失,少一点「你把链接发我我看看」。
第一阶段装过的直接更新就行,没装过的参考上一篇文章的配置教程。有问题留言告诉我。
好了,感谢你的耐心观看,如果觉得不错,希望能点个赞、转发、收藏三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
