 夜雨聆风
夜雨聆风





AI Infra 消息速报 · 2026-05-06
⚡ AI Infra 消息速报
2026-05-06 · 每日一报,聚焦前沿
[1] 本周 AI Infra 相关项目 Top 3
#框架
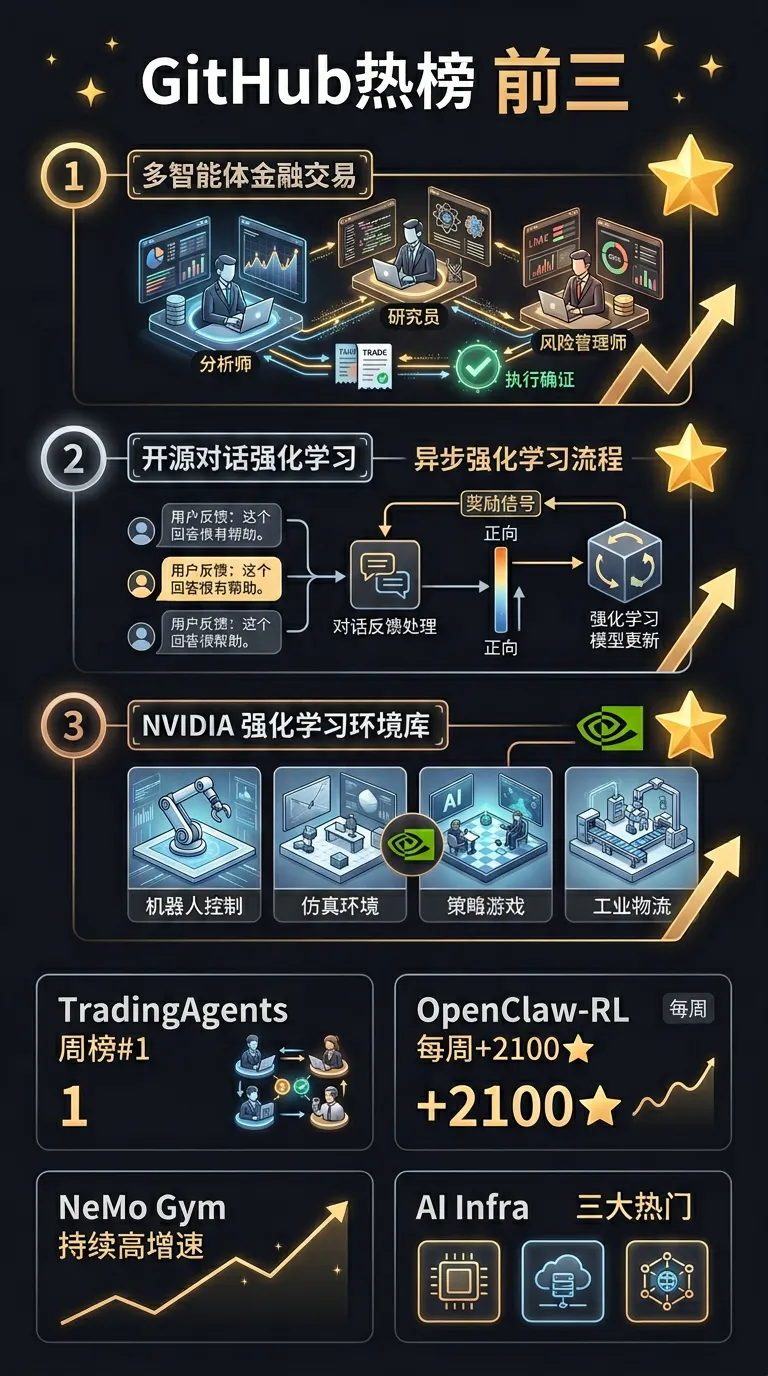
| 项目 | 一句话介绍 | Stars/周 |
|——|———–|———-|
| TradingAgents | 多 Agent LLM 金融交易框架,模拟分析师/研究员/风控等角色协作决策 | 周榜 #1 |
| OpenClaw-RL | 全异步 RL 框架,通过自然对话反馈训练个性化 AI Agent | +2,100/周 |
| NVIDIA-NeMo/Gym | 面向 RL 训练的环境与数据集集合,兼容主流 RLVR 框架 | 持续高增速 |
这些工具怎么用:
• TradingAgents:多 Agent 分工协作模式可迁移到代码评审流水线,分别扮演”安全审查员”、”性能分析师”、”架构评审人”,比单一 Agent 覆盖更全面
• OpenClaw-RL:适合从真实用户对话持续微调私有模型的场景,无需大规模人工标注
• NeMo Gym:国产芯片做 RLVR 适配时可直接复用其环境接口标准,减少重复造轮子
🔗 https://github.com/trending
[2] WindowQuant:基于窗口级相似度的 VLM KV Cache 混合精度量化
#训练推理算法
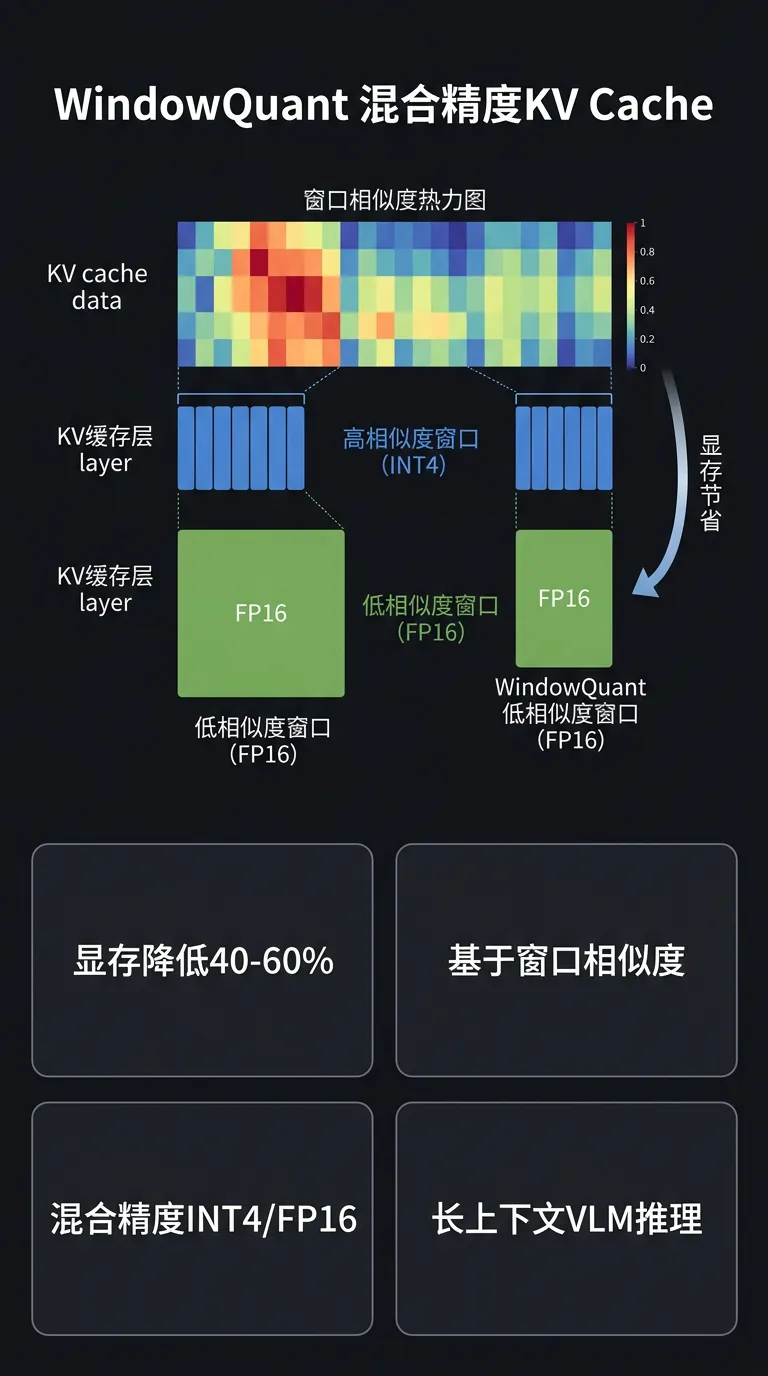
arXiv 2605.02262(5/5):针对 VLM(视觉语言模型)推理优化,发现 KV Cache 中不同窗口的 token 相似度差异显著——相似度高的窗口用 INT4 存储,相似度低的保留 FP16,在相同精度损失下显存降低 40-60%,长上下文 VLM 推理吞吐提升明显。Infra 意义:混合精度 KV 方案需要 serving 层支持动态精度选择,国产芯片需确认 INT4/FP16 混合访存 kernel 实现。
🔗 https://arxiv.org/abs/2605.02262
[3] RadixArk 完成 1 亿美元种子轮:SGLang 团队打造开放 AI 基础设施
#行业风向
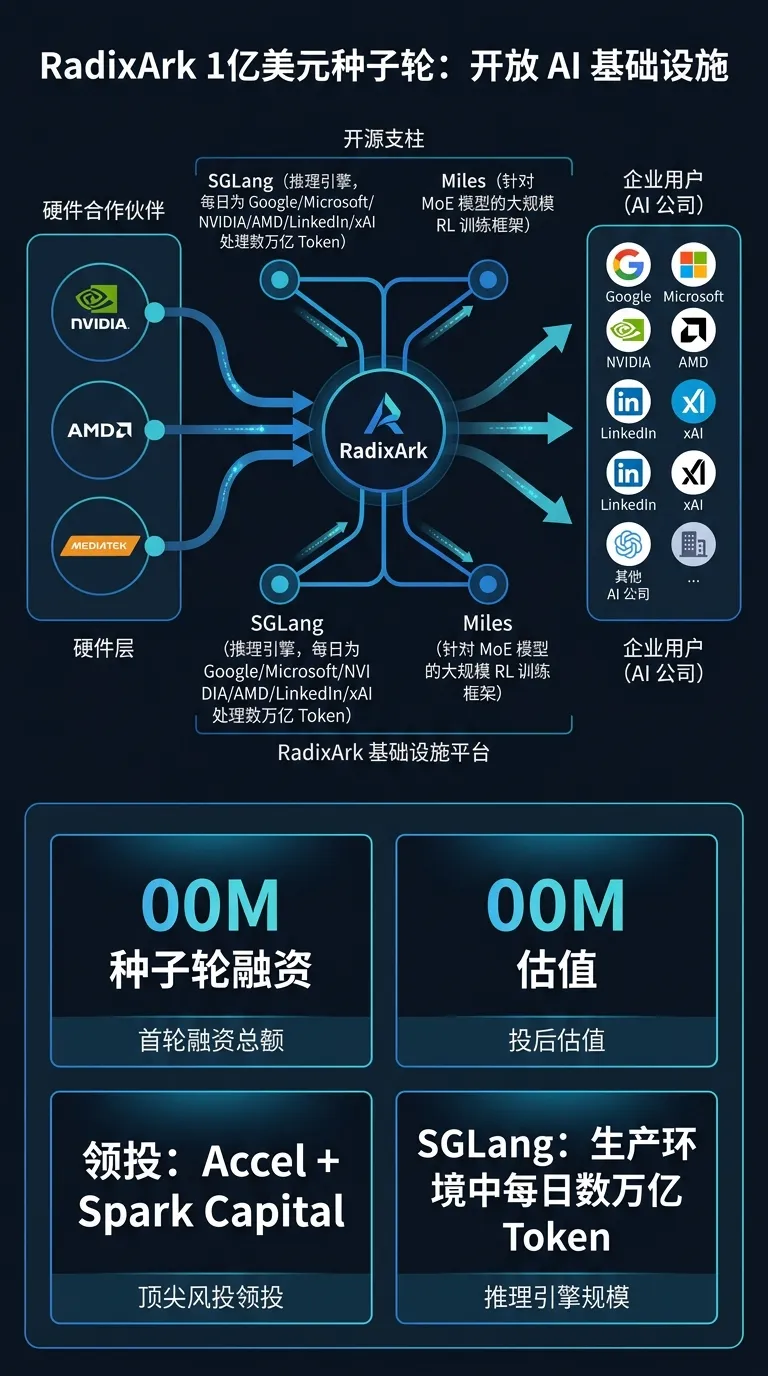
SGLang 核心开发者与维护者创立的 RadixArk 正式宣布完成 1 亿美元种子轮融资,投后估值 4 亿美元。本轮由 Accel、Spark Capital 领投,英伟达(NVentures)、AMD、联发科等参投,天使投资人包括 John Schulman(前 OpenAI 联创)、Soumith Chintala(PyTorch 联创)、Lilian Weng(OpenAI 前技术负责人)等 AI 核心人物。
核心技术根基:推理引擎 SGLang(每天为谷歌、微软、英伟达、AMD、xAI 等提供数万亿 token 推理服务)+ 大规模 RL 训练框架 Miles(专为 MoE 模型设计)。直指行业痛点:几乎所有 AI 公司都在重复构建相同推理/训练/编排基础设施,造成大量工程资源浪费。
核心目标:让构建、训练和运行前沿模型的成本降低 10 倍、可及性提升 10 倍。英伟达、AMD、联发科全系芯片厂商集体参投,侧面印证其技术路线的硬件无关性——对国产芯片 Day-0 适配路径同样具有参考价值。
🔗 https://mp.weixin.qq.com/s/R00g-5Al5z-syXDi5VkKwQ
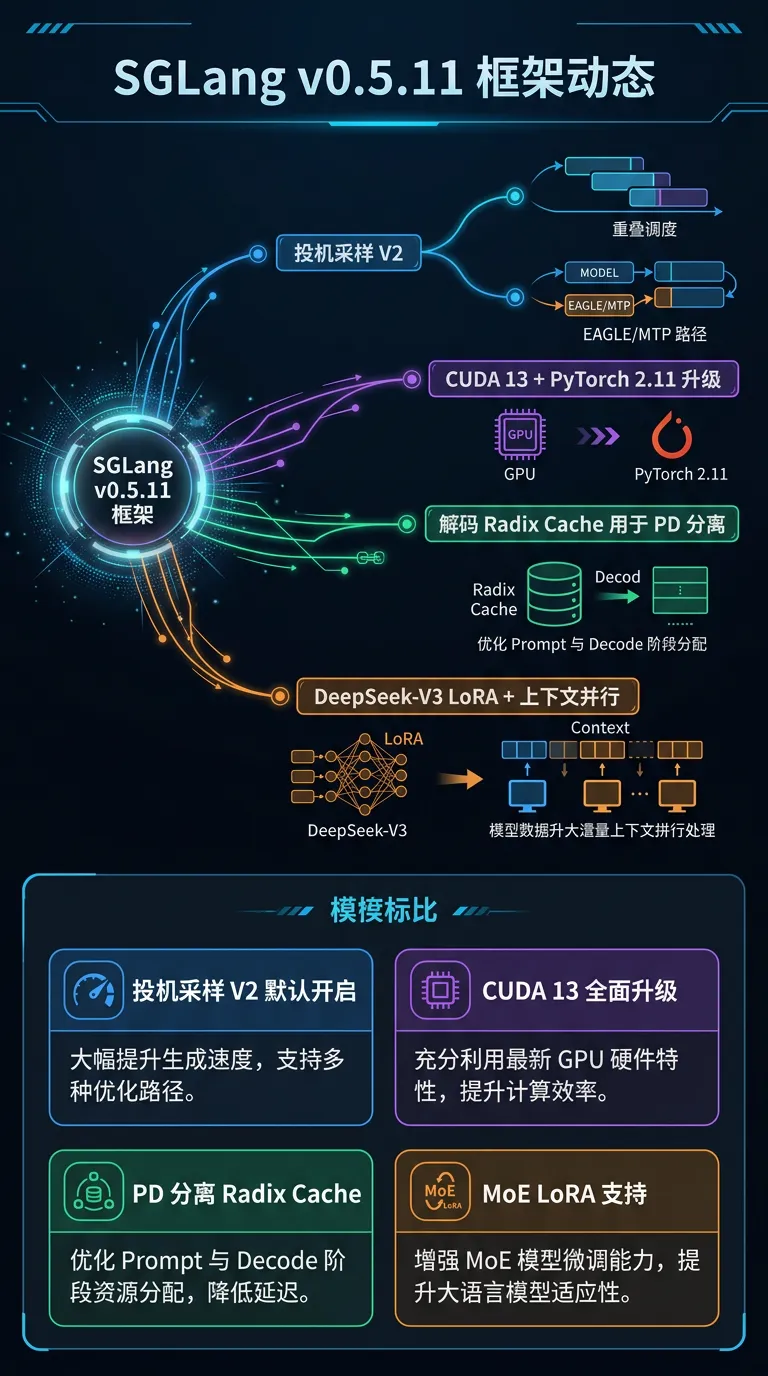
[4] SGLang v0.5.11:Speculative Decoding V2 默认开启 + CUDA 13 升级
#框架
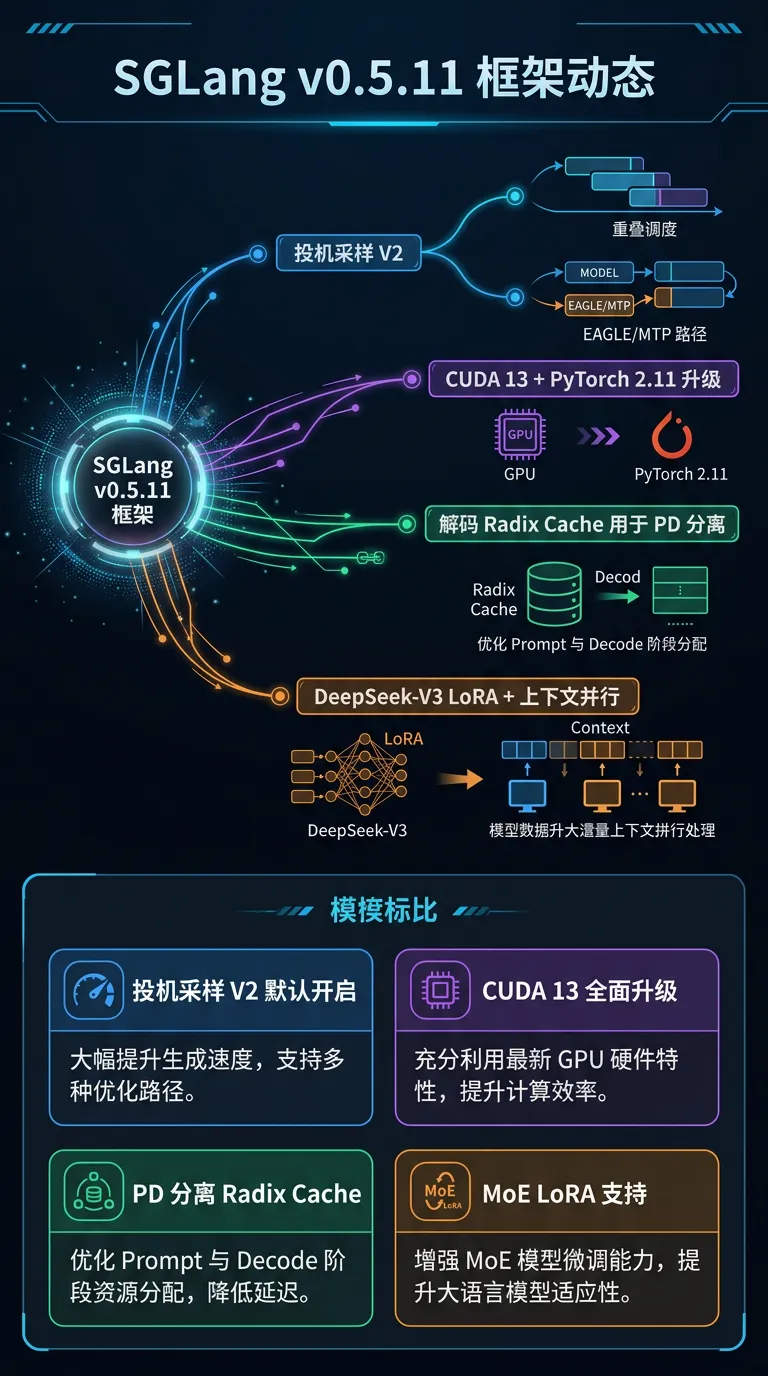
重要新 feature:
• Speculative Decoding V2 默认开启:overlap scheduling 隐藏 CPU 开销,EAGLE/MTP/DFLASH 路径每步 CPU 代价大幅降低,吞吐直接提升
• CUDA 13 + PyTorch 2.11 全面升级:Docker 镜像、sgl-kernel 全部随之升级,解锁新 kernel 能力
• Decode Radix Cache for PD 分离部署:Decode 侧 prefix cache 在 prefill/decode 分离架构下正常工作,长共享前缀场景 TTFT 显著改善
• DeepSeek-V3 / Kimi-K2 LoRA 支持:MLA-based 超大 MoE 模型首次支持 adapter fine-tuning
• Context Parallel 增强:All-reduce + RMSNorm 融合,MoE 并行度与 Attention 并行度可独立调节
Infra 需要做什么:升级 Docker 镜像须同步切换到 CUDA 13 驱动;已用 Spec Decode 的部署无需改配置,V2 自动生效;PD 分离集群建议开启 Decode Radix Cache 补回 cache hit rate;国产芯片适配层需关注 CUDA 13 driver API 变化。
🔗 https://github.com/sgl-project/sglang/releases/tag/v0.5.11
[5] vLLM v0.20.1:DeepSeek V4 专项稳定 + MXFP8 all-to-all
#框架
重要新 feature:
• DeepSeek V4 Base 模型支持 + multi-stream pre-attention GEMM,大 MoE 场景显存利用率提升
• MXFP8 all-to-all 通信支持:FlashInfer one-sided communication 路径新增 BF16/MXFP8,降低专家间通信带宽消耗
• FP32→FP4 转换加速:PTX cvt 指令直接用于量化路径,Blackwell FP4 工作流更顺滑
• 持久 TopK 协作锁死 bug 修复(TopK=1024 场景)、BailingMoE V2.5 MLA RoPE rotation 修复
Infra 需要做什么:跑 DeepSeek V4 的集群建议升级至 v0.20.1;MXFP8 all-to-all 需确认网卡驱动支持 MX 格式;国产芯片 FP4 路径暂不适用 PTX 指令,需走自定义量化 kernel。
🔗 https://github.com/vllm-project/vllm/releases/tag/v0.20.1
[6] MLA + MoE 重塑 LLM 推理瓶颈:从 Attention 转向 Compute 与 Expert 路由
#训练推理算法
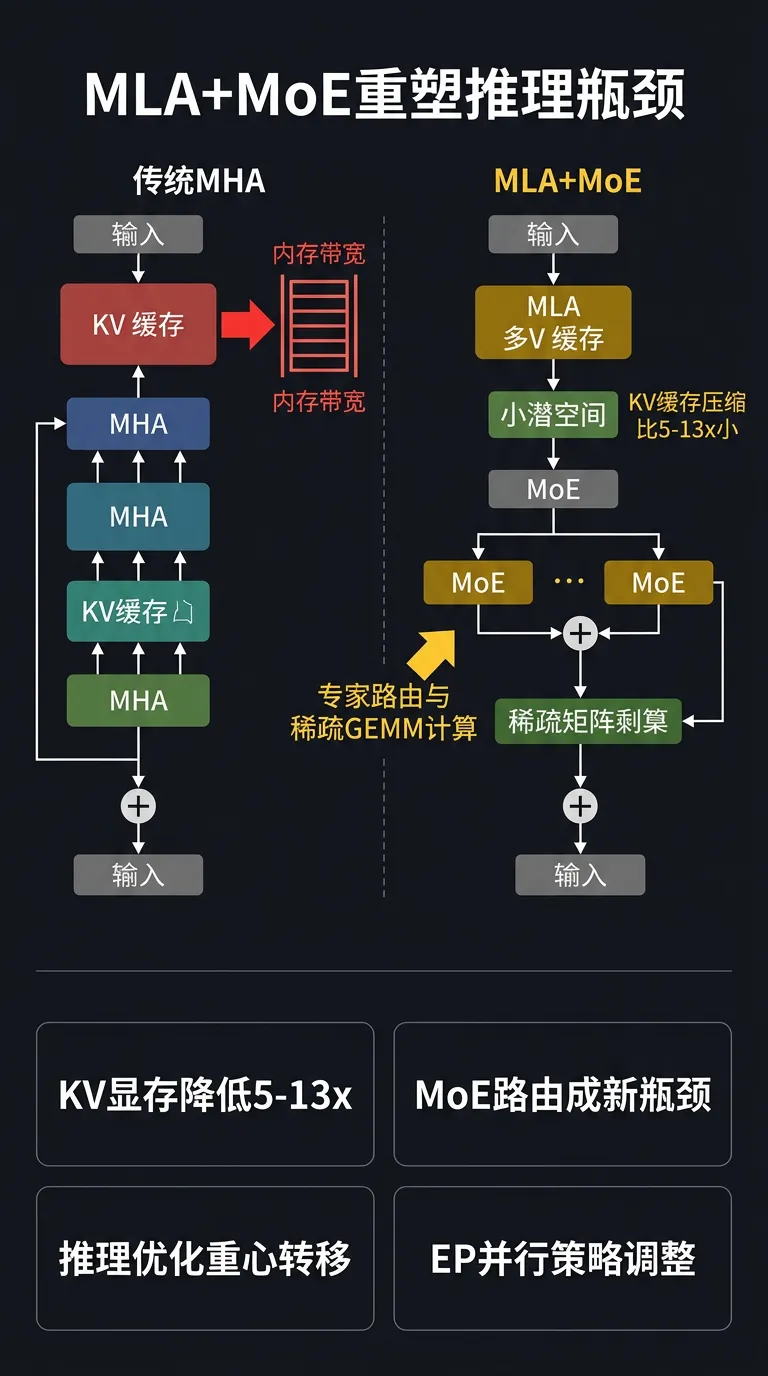
算法改进:arXiv「Rethinking LLM Inference Bottlenecks」指出,传统优化针对 MHA 的内存带宽瓶颈(KV cache 访问),但 MLA 将 KV 压缩到 latent space,内存压力大幅下降;MoE 把瓶颈转移到专家路由和稀疏激活的计算调度上。
质量/效率收益:MLA 推理下 KV 内存需求可降低 5-13x;但 Expert 路由引入新的 load imbalance 和通信开销,部分场景成为新的主要瓶颈。
pipeline/serving 适配:serving 层需重新 profile 瓶颈位置——MLA 模型可以减少 KV offload 预算,但需增加 Expert 并行度(EP)优化;针对国产芯片的 kernel 优化重心应从 bandwidth-bound attention 转向 compute-bound MoE GEMM。
🔗 https://arxiv.org/abs/2507.15465
[7] OpenClaw-RL:全异步 RL 框架,用自然对话反馈训练个性化 Agent
#训练推理算法
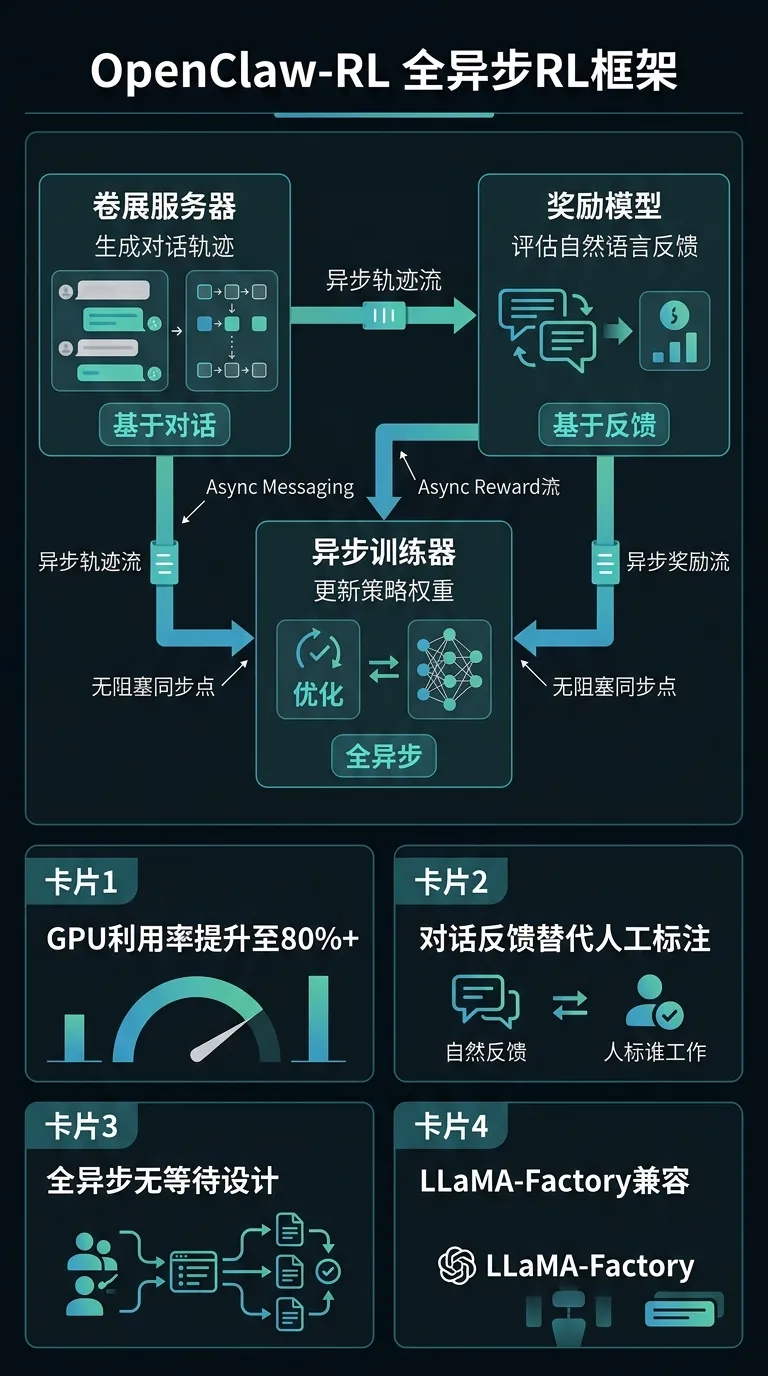
算法改进:基于对话反馈(natural conversation feedback)实现全异步强化学习,Actor/Critic/Environment 完全解耦异步运行,避免同步等待导致的 GPU 空转;适配 LLaMA-Factory 配置接口,支持全参数 fine-tuning + policy optimization。
质量/效率收益:异步架构可将 GPU 利用率从传统同步 RL 的 40-60% 提升到 80% 以上;对话反馈取代人工标注,大幅降低标注成本。
pipeline/serving 适配:训练 pipeline 需部署独立的 Rollout Server(异步采样)+ Trainer(参数更新);国产芯片适配时需关注异步通信原语的支持情况(NCCL async 等价实现)。
🔗 https://github.com/Gen-Verse/OpenClaw-RL
由 dodo · AI Infra 消息速报 自动生成 | 2026-05-06