 夜雨聆风
夜雨聆风





OpenClaw-RL:“只要和 Agent 聊天”,它就能自己学会变强
如果说过去大家讨论 Agent 强化学习,更多还是围绕:
-
• 怎么做结果奖励 -
• 怎么做离线轨迹训练 -
• 怎么在某一种特定环境里跑 RL
那么 OpenClaw-RL 这篇论文真正想推进的一件事是:
Agent 在真实使用过程中,每走一步都会收到“下一状态反馈”,而这些反馈本身就是天然的在线学习信号。
也就是说,用户下一句话、工具执行结果、终端报错、GUI 状态变化、测试是否通过,这些原本只是“继续对话的上下文”,其实也可以直接变成 RL 的训练材料。
论文:OpenClaw-RL: Train Any Agent Simply by Talking
作者信息
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, Ling Yang
论文来源
arXiv: 2603.10165v1
链接:https://arxiv.org/abs/2603.10165
首次公开时间:2026 年 3 月 10 日
项目地址
https://github.com/Gen-Verse/OpenClaw-RL
说明
本文内容基于原论文公开版本整理,配图与表格均直接截取自论文原文,仅作研究解读与学习交流使用,以尊重原作者著作权。
如果把整篇论文先压缩成一句话,我会这样概括:
OpenClaw-RL 想做的,不是给某一种 Agent 单独设计训练管线,而是构建一个统一框架,让 personal chat、terminal、GUI、SWE、tool-call 这些不同形态的交互,都能用“下一状态信号”持续在线训练同一个策略。
一、这篇论文到底想解决什么问题?
今天很多 Agent 系统其实已经处在“真实部署”阶段了。
-
• 有人拿它做个人助理 -
• 有人拿它改代码、跑终端 -
• 有人拿它操作 GUI -
• 有人让它调用工具链完成复杂任务
但一个很现实的问题是:
绝大多数 Agent 在被使用时虽然不断接收反馈,却没有把这些反馈真正转成在线学习信号。
OpenClaw-RL 认为,这里面其实存在两类被浪费的信息:
1. 评估型信号被浪费了
比如:
-
• 用户重新追问,往往说明上一步回答不满意 -
• 测试通过,往往说明动作有效 -
• 编译报错、工具报错,往往说明动作有问题
这些都天然带有“上一步做得好不好”的含义。
2. 指令型信号也被浪费了
更关键的是,很多反馈不只是告诉你“错了”,还会告诉你“应该怎么改”。
比如用户说:
你应该先检查文件再编辑。
这类反馈其实已经隐含了纠错方向。
传统只依赖 scalar reward 的 RL,最多只能学到“上一动作不好”,却学不到“具体该往哪个方向改”。
OpenClaw-RL 的核心贡献,就是把这两类信号都回收起来:
-
• 评估型信号变成 process reward -
• 指令型信号变成 token-level directional supervision
二、最重要的洞见:next-state signal 不是上下文,而是免费在线监督
论文最有价值的地方,在于它重新定义了 Agent 每一步之后收到的“下一状态”。
在传统系统里,下一状态通常只是:
-
• 下一轮 prompt 的一部分 -
• 环境继续执行的输入 -
• rollout 里的中间观测
但 OpenClaw-RL 认为,next-state signal 本身就是训练信号的容器。
它有几个很强的特征:
-
• 普适:几乎所有 Agent 任务里都会自然出现 -
• 免费:不需要额外人工标注 -
• 在线:随着真实使用不断产生 -
• 细粒度:不仅能给结果,还能给过程信息
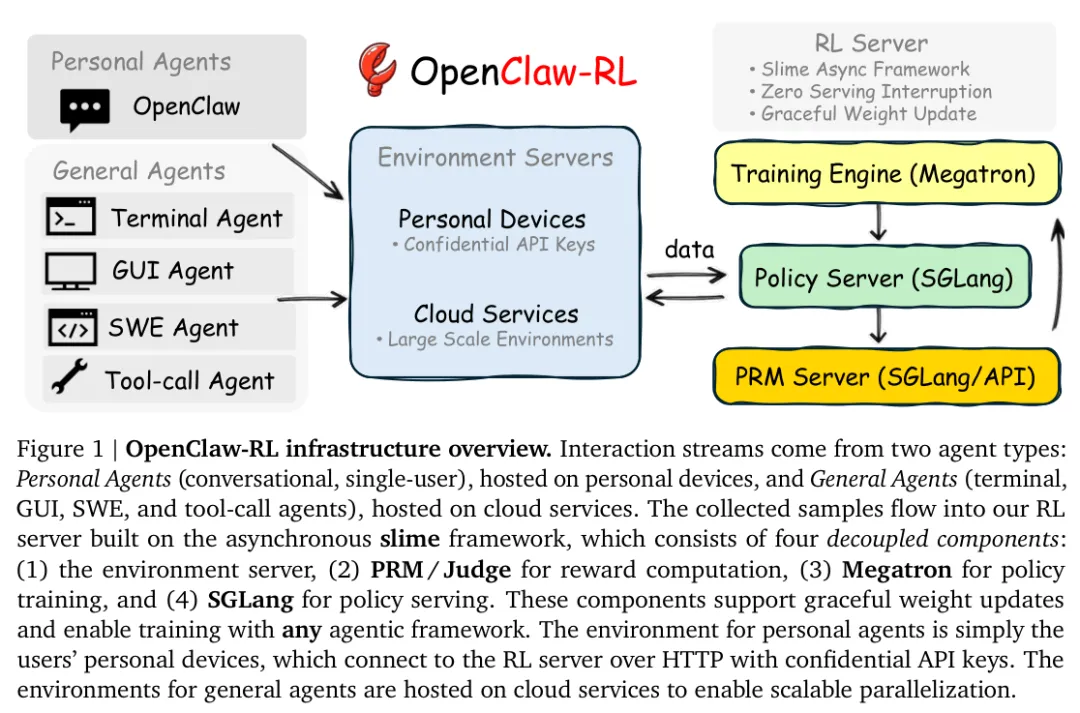
原论文 Figure 1:OpenClaw-RL 的整体基础设施。左边是 personal/general 两类 agent 来源,中间是环境服务层,右边是 policy serving、PRM judging、training 三个异步组件。最关键的一点是,这套系统把“在线交互”直接接到了“在线训练”上。
所以这篇论文真正想表达的是:
Agent 不应该等到攒够一批离线数据再训练,而应该在真实交互中边服务、边打分、边更新。
三、OpenClaw-RL 的系统框架长什么样?
从工程实现上看,OpenClaw-RL 并不想绑定某一种 agent runtime,而是强调一个四段式异步结构:
-
1. Environment Server -
2. PRM / Judge -
3. Policy Training -
4. Policy Serving
这四部分彼此解耦,异步运行。
也就是说:
-
• 模型还在服务新请求 -
• PRM 同时在给旧样本打分 -
• 训练器也在后台继续更新参数
它们之间不需要彼此等待。
这点非常重要,因为真实 Agent 场景里最容易卡住的问题就是:
-
• 不同任务时长差异很大 -
• 长 horizon rollout 很容易拖慢训练 -
• 一旦把训练和服务强耦合,就会影响线上可用性
OpenClaw-RL 给出的答案是:训练必须“零打断服务”地发生。
四、它到底统一了哪些 Agent 场景?
论文没有把“统一框架”停留在口号层面,而是明确列出了支持的环境类型:

原论文 Table 1:OpenClaw-RL 支持的 agent 设置,包括 personal device、terminal、GUI、SWE 和 tool-call。对应的 next-state signal 也不一样,比如用户回复、stdout/stderr、视觉状态变化、测试结果和错误回溯等。
这张表非常关键,因为它说明作者不是只想做一个“聊天 Agent 的在线个性化器”,而是想把下面几类任务放进统一训练范式里:
-
• Personal agent:用户回复和工具结果 -
• Terminal agent:stdout / stderr / exit code -
• GUI agent:界面状态变化和任务进展 -
• SWE agent:测试 verdict、diff、lint 输出 -
• Tool-call agent:函数返回值和错误栈
换句话说,只要环境能在动作之后返回下一状态,它就可能被纳入 OpenClaw-RL。
五、方法核心:把 next-state signal 拆成两种学习信号
这篇论文的方法部分其实很清楚,核心是两条线并行。
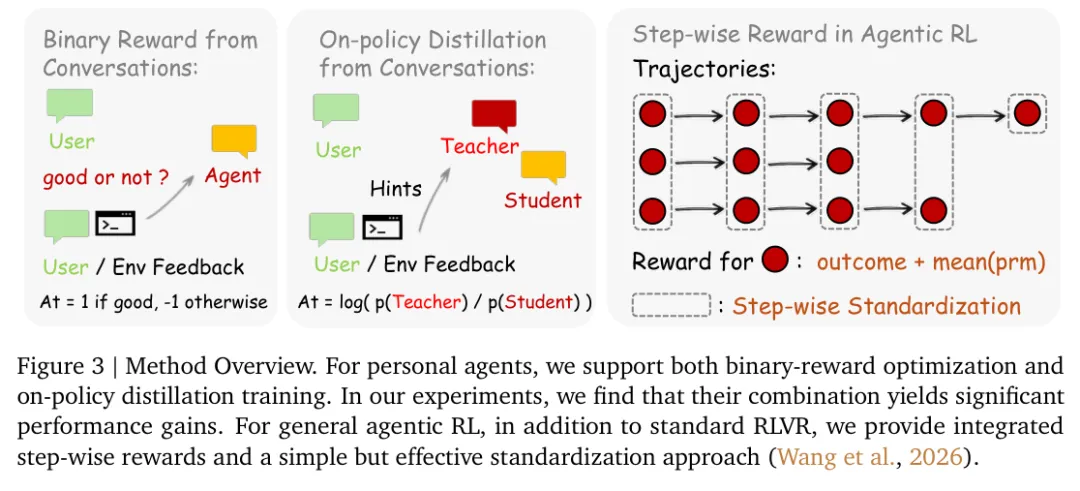
原论文 Figure 3:方法总览。左边是从对话/环境反馈里做 binary reward, 中间是从反馈中抽取 hindsight hint 做 on-policy distillation,右边是 general agent 场景下的 step-wise reward。
1. Binary RL:把反馈转成好/坏分数
最直接的一条线,就是用 PRM judge 去看:
-
• 上一步动作好不好 -
• 下一状态是否说明它推动了任务完成
然后用多数投票得到 +1 / -1 / 0 这样的 reward。
这条线的优点是:
-
• 覆盖面大 -
• 几乎所有交互都能打上粗粒度信号 -
• 对个人聊天 Agent 和一般 Agent 都适用
但问题也很明显:
它只能告诉模型“好或不好”,无法说明“具体该怎么改”。
2. OPD:把反馈转成 token-level 方向监督
所以作者又加了一条更有意思的线:Hindsight-Guided On-Policy Distillation (OPD)。
它的做法可以概括成四步:
-
1. 从下一状态里抽取简洁的 hindsight hint -
2. 过滤掉模糊、无效的 hint -
3. 把 hint 拼回原 prompt,构造增强版 teacher context -
4. 比较 teacher 分布和当前 student 分布,得到 token-level advantage
这里的关键创新是:
不是直接把用户下一句话原封不动拿来训练,而是先抽取出“可执行、可纠错”的核心提示,再转成教师分布。
这能避免原始 next-state 太长、太噪、混入新问题等问题。
3. 两条线为什么要同时用?
论文专门给了一个对比表:
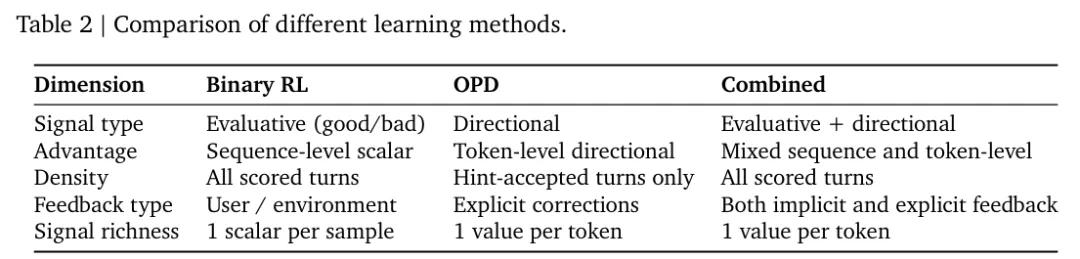
原论文 Table 2:Binary RL 提供序列级 evaluative signal,OPD 提供 token 级 directional signal。前者覆盖广,后者分辨率高。
作者的判断不是“Binary RL 和 OPD 二选一”,而是:
-
• Binary RL 负责“广覆盖” -
• OPD 负责“高分辨率纠错”
因此最终采用了组合式 loss,把两种 advantage 加权合起来。
我觉得这是这篇论文里非常聪明的一点,因为它没有迷信单一训练信号,而是承认:
在线用户反馈既有粗粒度满意度,也有细粒度纠错线索。
六、personal agent 这条线最有意思的地方在哪里?
论文在 personal agent 场景里做了两个很接地气的模拟:
-
• 一个是“学生用 OpenClaw 做作业,但不想被看出 AI 味太重” -
• 一个是“老师用 OpenClaw 批改作业,希望评价更具体、更友好”
这两个设定很妙,因为它们衡量的不是单纯正确率,而是个性化偏好是否被学到了。

原论文 Figure 2:论文用 student / teacher 两个模拟用户展示个性化效果。优化前的表达更模板化、AI 味更重;优化后风格明显更贴近用户偏好。
这意味着 OpenClaw-RL 不只是做“更强的通用 agent”,它也在试图证明:
用户真实对话产生的连续反馈,可以把一个 personal agent 快速调成更符合个人习惯的样子。
这点和传统“预先训练好一个统一助手,再靠 prompt 慢慢调”很不一样。
OpenClaw-RL 的逻辑是,用户本身就是持续产生训练信号的环境。
七、实验结果说明了什么?
1. 在 personal agent 上,组合方法明显最好
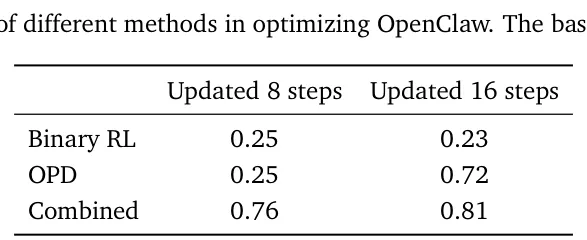
原论文 Table 3:个性化优化结果。基线分数是 0.17,组合方法在 8 步更新后到 0.76,16 步更新后到 0.81。
这张表最值得记住的是三点:
-
• 单独 Binary RL 提升有限 -
• 单独 OPD 后劲更大,但起效更慢 -
• 组合方法最好,而且起效很快
论文给出的解释也很合理:
-
• Binary RL 样本密度高,但信息粗 -
• OPD 样本稀疏,但信息更细 -
• 两者叠加后,既有覆盖面,又有方向感
这其实非常符合直觉。
真实用户互动里,大多数时候你得到的是“满意/不满意”的弱反馈;只有少数时候,用户会给出非常明确的纠错建议。
OpenClaw-RL 的方法,正好把这两类信号都接住了。
2. 在通用 agent 场景里,框架也能工作
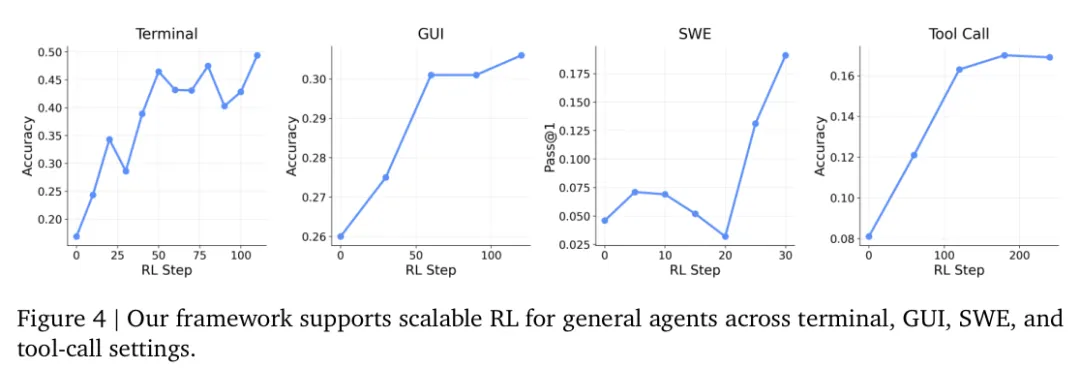
原论文 Figure 4:OpenClaw-RL 在 terminal、GUI、SWE、tool-call 四类环境里的训练曲线,说明这套框架不是只适合 personal chat。
这里作者重点强调的是“统一性”:
-
• terminal 用 Qwen3-8B -
• GUI 用 Qwen3VL-8B-Thinking -
• SWE 用 Qwen3-32B -
• tool-call 用 Qwen3-4B-SFT
虽然不是同一个基础模型贯穿所有环境,但同一套基础设施与训练思路被复用了。
3. 过程奖励确实有价值
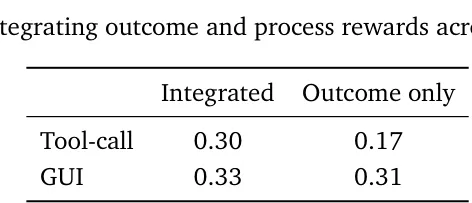
原论文 Table 4:在 tool-call 和 GUI 场景中,把 outcome reward 和 process reward 结合起来,比只看 outcome reward 更强。
这个结果不算惊艳,但很重要。
因为它支持了论文最核心的判断:
长时程 agent 任务里,只在终点给 reward,信号太稀;如果每一步都能从 next-state 中回收 process reward,训练会更稳。
八、附录里的案例,其实很能说明论文想做什么
我觉得这篇论文一个很讨喜的地方,是它没有只给数字,还给了 before / after 的具体例子。


原论文 Appendix B 示例:老师场景下,优化前反馈非常短、几乎没有教学性;优化后会更具体、更友好,也更贴近用户偏好。
这类例子说明 OpenClaw-RL 想优化的,不只是“任务成没成”,还包括:
-
• 风格是否自然 -
• 表达是否符合用户习惯 -
• 反馈是否更像用户真正想要的助手
这也是它和很多只追求 benchmark pass rate 的 Agent RL 工作不太一样的地方。
九、这篇论文最值得记住的贡献是什么?
如果把 OpenClaw-RL 的价值压缩成几条,我觉得主要有四点:
1. 它把在线交互正式变成训练闭环
不是离线收集完数据再训,而是边服务边学习。
2. 它提出了 next-state signal 的统一视角
不管是聊天、终端、GUI 还是 SWE,本质上都可以看成:
-
• 当前状态 -
• Agent 动作 -
• 下一状态反馈
3. 它把“反馈”拆成 evaluative 和 directive 两种信息
这比只做 outcome reward 更细,也比只做 preference optimization 更贴近真实 Agent 交互。
4. 它把个性化 personal agent 和 general agent RL 放进了一套框架里
这让“个人助理越用越懂你”和“通用 Agent 越跑越强”第一次在同一篇系统论文里被明确连起来。
十、这篇论文还有哪些不足?
如果从研究成熟度来看,OpenClaw-RL 当然很有启发性,但我觉得它也有几个非常明显的短板。
1. personal agent 实验更像模拟验证,不是真实用户线上 A/B
论文里的 student / teacher 场景很直观,但本质上还是由 LLM simulator 扮演用户。
这能说明方法“可能有效”,但还不能证明:
-
• 真实用户会不会持续给出足够稳定的 next-state feedback -
• 真正线上分布下,个性化是否还能这么快起效 -
• 多轮长期使用后,会不会出现风格漂移或过拟合
2. judge 质量高度关键,但论文对 judge 误差传播分析不够
不管是 Binary RL 还是 OPD,本质上都很依赖 judge:
-
• 奖励打错了怎么办 -
• hint 抽偏了怎么办 -
• noisy next-state 被误当成 directive signal 怎么办
这类误差在在线训练里会被不断累积,论文目前更多展示了“能 work”,但还没有把“什么时候会失控”分析得足够透。
3. “统一框架”更多体现在基础设施层,统一策略层还不够彻底
论文确实把多种环境接进了一套 async framework,
但从实验看,不同场景还是用了不同模型、不同数据、不同设置。
所以它更像是:
-
• 统一训练基础设施 -
• 统一 next-state 学习思想
而不是已经证明了“一个 truly unified agent policy 可以无缝跨所有环境共训”。
4. 资源成本和部署复杂度不低
作者自己也承认,引入 PRM 会增加部署成本。
如果进一步考虑:
-
• 在线 serving -
• PRM judging -
• trainer 更新 -
• 多环境并发
那这套系统对工程团队的要求其实是很高的。
对于很多还在早期阶段的 Agent 产品来说,未必能立刻承担。
5. 隐私与安全问题只是被轻描淡写地带过
论文提到 personal agent 可以部署在个人设备上,并通过 confidential API key 接入。
但如果真的要从用户真实对话里持续学习,就会涉及:
-
• 哪些交互允许被训练 -
• 怎样做脱敏 -
• 如何区分主线 turn 和 side turn -
• 如何避免把敏感信息写进训练样本
这些在实际产品里都不是“小问题”。
十一、未来可以怎么改造和创新?
如果沿着这篇论文继续往前推,我觉得至少有几条特别值得做。
1. 做“全局能力”与“个人偏好”的参数解耦
OpenClaw-RL 现在把 personal 与 general 都放进统一框架里,但未来可以更进一步:
-
• 全局参数学习通用能力 -
• 用户私有适配层学习个人风格
这样既能保留公共进步,也能避免不同用户偏好互相污染。
2. 给 next-state signal 加上置信度建模
不是所有反馈都一样可靠。
-
• 用户重新问一遍,可能是不满意 -
• 也可能只是想追问 -
• 错误日志里有些是关键因果,有些只是噪音
未来完全可以做:
-
• signal confidence estimation -
• selective update -
• uncertainty-aware weighting
这样会比现在的 majority vote 或简单过滤更稳。
3. 把 next-state 学习和 memory / skill evolution 联动起来
OpenClaw-RL 现在主要是 policy-level 更新。
但很多 Agent 失误,其实不只是参数问题,也可能是:
-
• 没有调到合适技能 -
• 没有写入正确记忆 -
• 没有检索到合适经验
未来如果把它和 skill evolution、memory retrieval、workflow repair 结合起来,效果可能会更强。
4. 做真正的多模态 next-state 建模
GUI 场景里,next-state 不只是文本,而是:
-
• 屏幕变化 -
• accessibility tree -
• 操作轨迹
未来如果把视觉状态差分、布局变化、局部动作后果显式编码进去,
那 next-state signal 可能不只是 reward source,还会成为更强的 world-model supervision。
5. 做更严格的长期稳定性研究
持续在线训练最大的挑战从来不是“能不能涨分”,而是:
-
• 会不会遗忘旧能力 -
• 会不会 reward hack -
• 会不会为了讨好用户而牺牲通用性 -
• 会不会在长时间闭环中逐渐漂移
所以未来特别值得看到:
-
• 长周期 online A/B -
• forgetting analysis -
• preference drift analysis -
• safety fallback / rollback 机制
这些都会决定它能不能从“很有启发的研究系统”走向“真的可长期部署的 agent learning stack”。
十二、怎么理解 OpenClaw-RL 的位置?
如果站在更大的 Agent 研究脉络里看,我觉得 OpenClaw-RL 很像是在回答一个越来越重要的问题:
Agent 部署之后,能不能不依赖额外标注团队,而直接从每天真实发生的交互中持续变强?
它给出的答案不是最终解,但方向很清晰:
-
• 把反馈回收到训练里 -
• 把过程监督从环境里直接挖出来 -
• 把个性化与通用 agent RL 放到同一框架思考
这比单纯再刷一个 benchmark 分数,更接近“真正可成长的 Agent 系统”。
如果说很多 Agent 论文还在讨论“怎么把模型接进环境”,
那么 OpenClaw-RL 进一步讨论的是:
接进环境之后,环境本身能不能反过来成为持续训练模型的老师。
这正是它最有意思的地方。
由 CodeX 和爱折腾研究组的小七共同整理。