 夜雨聆风
夜雨聆风





使用AI生成测试用例,到底需不需要知识库?
在测试用例生成场景中引入AI能力时,一个核心问题始终无法回避:是否需要为AI搭建专门的测试知识库?这个问题的答案并非非黑即白——不同业务场景、不同质量要求下,知识库的投入产出比差异巨大。本文从实测数据出发,系统分析知识库在AI生成测试用例场景中的实际价值与适用边界。
一、纯Prompt模式的能力边界
纯Prompt模式指的是直接通过优化Prompt引导大模型生成测试用例,不依赖外部知识库提供上下文增强。这种模式的核心优势在于实现成本低、响应速度快——输入需求描述和格式要求,大模型即可返回用例结果。
从实际测试来看,纯Prompt模式在以下三类场景中表现稳定:
第一类:输入结构化的标准化接口。 当待测对象是输入输出格式固定的HTTP接口、明确的CRUD操作时,大模型能够基于通用知识生成较为完整的参数校验用例。这类接口的共同特征是:数据结构清晰、错误码体系标准、业务逻辑属于行业通用范畴(如手机号格式校验、邮箱格式校验)。以标准用户注册接口为例:
# 接口定义POST /api/v1/users/registerBody: { username, password, email, phone }# 纯Prompt模式下AI可稳定生成的用例类型def generate_basic_cases():"""纯Prompt模式生成的基础用例"""cases = []# 必填字段缺失组合for field in ['username', 'password', 'email', 'phone']:cases.append({'name': f'缺少{field}字段','body': {k: v for k, v in {'username': 'test_user','password': 'Pass123!','email': 'test@example.com','phone': '13800138000'}.items() if k != field}})# 格式校验用例cases.extend([{'name': '无效邮箱格式', 'body': {'email': 'invalid-email'}},{'name': '无效手机号格式', 'body': {'phone': '12345'}},{'name': '密码强度不足', 'body': {'password': '123'}},])return cases
对于这类标准化接口,纯Prompt模式的用例生成正确率可达85%-92%,基本满足日常测试的覆盖需求。
第二类:通用校验规则覆盖。 大模型基于预训练知识,能够覆盖常见的边界值分析、等价类划分等测试方法,在没有特殊业务约束的情况下,生成合理的基础测试用例。
第三类:快速探索与原型验证。 当需求尚未完全明确、测试目标尚在探索阶段时,纯Prompt模式可以快速产出用例初稿,帮助团队摸清系统行为边界。
然而,当业务复杂度提升时,纯Prompt模式的局限性开始显现:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这些问题并非Prompt优化可以根本解决——大模型不知道你们公司半年前踩过什么坑、评审时被指出过什么问题、哪些边界值是产品经理拍脑袋定的且经常出Bug。
二、知识库带来了什么改变
知识库在测试用例生成场景中的核心价值,可以归纳为三个层次:
第一层:业务规则精准召回。 以积分系统为例,知识库中可能包含:积分获取规则(签到奖励、购物返积分、活动额外奖励)、积分扣减规则(兑换商品、退款处理、过期清零)、叠加限制规则(哪些商品不支持积分抵扣)、历史缺陷记录(用户反馈的边界Bug时间线)。当需要生成积分相关测试用例时,系统会先检索这些内容:
【检索意图】生成积分兑换功能测试用例【召回内容】- 文档片段A: "连续签到第7天额外奖励50积分,与新手礼包不叠加"- 文档片段B: "历史Bug记录: 2024-03-15 23:59:59签到积分未到账"- 文档片段C: "积分过期规则: 每年12月31日清零上一年度积分"【增强效果】生成用例时自动覆盖历史Bug场景、叠加规则边界
第二层:项目上下文沉淀。 每个长期项目都积累了大量隐性知识:用例模板规范、评审时积累的经验、哪些模块历史上容易出什么问题、核心链路的定义。将这些沉淀到知识库中,AI生成的用例会越来越”像你们团队写的”,而非泛泛的通用模板。
第三层:跨模块关联推理。 这是纯Prompt模式最难实现的。当测试”订单模块优惠券使用”时,知识库可能关联到:优惠券模块的配置文档、历史缺陷记录ORD-2024-0523(优惠券叠加计算错误)、关联的测试用例ORD_TC_023。AI生成订单模块用例时,会自动带上”优惠券叠加”这个关联场景的覆盖。
知识库加持后的质量提升效果显著:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三、RAG模式与纯Prompt的量化差异
为了更直观地展示两种模式的差异,我们针对电商订单模块进行了对照实验。该模块包含15个核心接口,测试指标涵盖:用例数量、业务规则覆盖率、边界值准确率、可执行率。
实验设计
class TestCaseComparison:"""测试用例生成对比实验"""def __init__(self, module_name: str):self.module_name = module_nameself.pure_prompt_cases = []self.rag_cases = []def generate_pure_prompt(self, requirement: str) -> list:"""纯Prompt模式生成"""prompt = f"""请为以下需求生成测试用例:需求:{requirement}要求:用XPath格式输出,包含前置条件、测试步骤、预期结果"""# 调用大模型...return self._parse_cases(llm.invoke(prompt))def generate_rag(self, requirement: str, top_k: int = 5) -> list:"""RAG增强模式生成"""# 1. 检索相关知识docs = self.vectorstore.similarity_search(requirement, k=top_k)# 2. 关键词检索keyword_docs = self.keyword_search(requirement)# 3. 融合召回fused_docs = self.rerank(docs + keyword_docs, top_k)# 4. 构建增强Promptcontext = self._build_context(fused_docs)enhanced_prompt = f"""请基于以下知识生成测试用例:需求:{requirement}相关知识(来自知识库):{context}要求:用XPath格式输出,包含前置条件、测试步骤、预期结果"""return self._parse_cases(llm.invoke(enhanced_prompt))def evaluate(self) -> dict:"""评估指标计算"""return {'pure_prompt': self._calc_metrics(self.pure_prompt_cases),'rag': self._calc_metrics(self.rag_cases)}
实测数据
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
+28pp |
|
|
|
|
+36pp |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键发现
发现一:业务规则覆盖差距显著。 纯Prompt模式漏掉了26条业务规则,RAG模式只漏掉7条。漏掉的7条主要是非常边缘的规则,如”虚拟商品不支持优惠券”、”跨境订单有额外校验”等。
发现二:边界值准确率是最大差距来源。 纯Prompt模式生成的边界值有一半是AI基于通用知识”合理推断”的,与实际系统行为不符。RAG模式因为能查询历史Bug记录,边界值基本与实际系统行为对齐。
发现三:时间成本增加但整体划算。 RAG模式多了检索环节,单次生成时间增加73%。但考虑到用例后续修改的人工成本(返工率从11%降至4%),整体ROI仍然可观。
典型用例对比
以”用户使用优惠券下单”场景为例:
纯Prompt模式生成的用例:
用例1:验证用户使用有效优惠券下单用例2:验证用户使用过期优惠券下单用例3:验证用户使用已用完的优惠券下单
RAG模式生成的用例:
用例1:验证用户使用有效优惠券下单用例2:验证用户使用过期优惠券下单用例3:验证用户使用已用完的优惠券下单用例4:验证优惠券与满减活动叠加计算(关联Bug: ORD-2024-0523)用例5:验证虚拟商品不支持使用优惠券(业务特殊规则)用例6:验证优惠券与积分抵用同时使用(2024-08规则变更)
RAG模式多生成的3个用例,都来自知识库中的历史经验,而非Prompt输入。
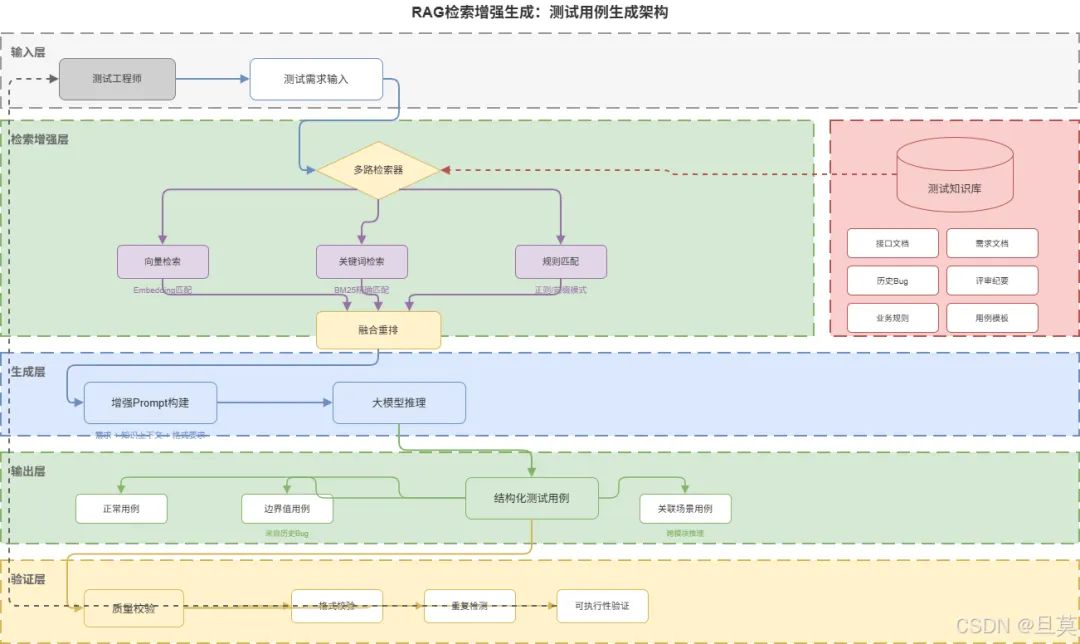
四、知识库必要性评估框架
基于上述分析,我们可以建立一套系统化的决策框架。判断是否需要知识库,核心看两个维度:

维度一:业务规则复杂度。 包括规则数量(一个满减活动可能有十几种叠加情况)、变更频率(运营随时可能调整规则)、边界情况数量。
维度二:用例准确性要求。 涉及是否影响核心业务、容错空间大小、问题暴露后的修复成本。
必须使用知识库的场景
场景一:营销与权益系统。 优惠券、满减、会员等级、积分体系这类业务的核心特征是:规则多且相互叠加、变更频繁、边界情况复杂。运营上周刚加的”店铺券和平台券不能同时使用”规则,Prompt里不可能每次都写。
场景二:高准确性要求的系统。 金融交易、医疗系统、核心订单处理这类系统,边界值必须精准。纯Prompt生成的边界值有一半是AI”合理推断”的,放在这些系统里风险太高。
场景三:长期维护的核心系统。 这类系统积累了大量的历史Bug记录、评审纪要、踩坑经验。将这些历史积累利用起来,AI生成的用例会自然覆盖历史上的”危险地带”。
纯Prompt就够的场景
场景一:标准化程度高的简单接口。 纯CRUD、配置查询这类接口,输入输出结构固定,业务规则简单(基本就是参数校验)。纯Prompt模式生成质量已经能达到85%+,上知识库投入产出比不划算。
场景二:探索性测试初期。 当需求不明确、测试目标尚在探索时,先用纯Prompt快速产出用例,摸清系统行为后再考虑知识库增强。
场景三:一次性项目。 如果一个项目用完就不再维护,没必要花时间整理知识库。
核心判断逻辑:业务规则越复杂、越容易变、越需要准确,越需要知识库;简单标准接口、快速探索、一次性的项目,纯Prompt就够。
五、低成本知识库搭建路径
如果确定需要知识库,如何以较低成本启动?以下是经过验证的渐进式方案。
第一阶段:文档整理(1-2周)
首先梳理”值得存”的知识,按优先级分类:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键原则:只存”能被检索用到”的知识,避免知识库变成垃圾场。
第二阶段:检索策略设计(核心)
知识库的价值不在”存”,在”查”。检索策略决定了召回质量。
class HybridRetriever:"""混合检索策略1. 语义检索:向量相似度匹配2. 关键词检索:BM25精确匹配3. 规则匹配:特定模式匹配"""def __init__(self, vectorstore, bm25_index):self.vectorstore = vectorstoreself.bm25_index = bm25_indexdef search(self, query: str, top_k: int = 5) -> list:results = []# 语义检索 - 处理自然语言查询semantic_results = self.vectorstore.similarity_search(query, k=10)results.extend(semantic_results)# 关键词检索 - 处理专业术语、精确概念keyword_results = self.bm25_index.search(query, k=5)results.extend(keyword_results)# 规则匹配 - 处理特定模式rule_results = self.pattern_match(query, ['BUG_', 'TC_', 'REQ_', 'ORD_', 'BUG:'])results.extend(rule_results[:3])# 去重 + 重排序return self.rerank_and_dedupe(results, top_k)def pattern_match(self, query: str, patterns: list) -> list:"""处理特定前缀的精确匹配"""results = []for pattern in patterns:if pattern.lower() in query.lower():results.extend(self._fetch_by_pattern(pattern))return results
第三阶段:知识库目录结构
test_knowledge_base/├── 01_项目文档/│ ├── 接口文档/│ │ ├── 订单模块_API_v2.3.yaml│ │ └── 用户模块_API_v1.8.yaml│ └── 需求文档/│ └── PRD_会员体系_v3.1.md├── 02_历史用例/│ ├── 评审通过/│ └── 评审未通过/├── 03_缺陷记录/│ ├── 按模块分类/│ └── 按根因分类/├── 04_业务规则/│ ├── 积分规则.md│ └── 优惠券规则.md└── 05_测试规范/└── 用例模板.md
第四阶段:RAG调用集成
from langchain_community.vectorstores import Chromafrom langchain_community.embeddings import OpenAIEmbeddingsfrom langchain_openai import ChatOpenAIclass TestCaseRAG:def __init__(self, knowledge_base_path: str):self.embeddings = OpenAIEmbeddings()self.vectorstore = Chroma(persist_directory=knowledge_base_path,embedding_function=self.embeddings)self.llm = ChatOpenAI(model="gpt-4", temperature=0.3)self.retriever = HybridRetriever(self.vectorstore, self.bm25_index)def enhance_prompt(self, requirement: str, top_k: int = 5) -> str:"""检索相关知识,增强Prompt"""# 1. 混合检索docs = self.retriever.search(requirement, top_k)# 2. 构建上下文context_parts = []for i, doc in enumerate(docs, 1):context_parts.append(f"【相关知识{i}】来源: {doc.metadata.get('source', '未知')}\n"f"内容: {doc.page_content}\n")context = "\n".join(context_parts)# 3. 构建增强Promptenhanced_prompt = f"""你是一个专业的测试工程师。根据以下信息生成测试用例。## 当前需求{requirement}## 相关知识(来自知识库){context if context else '(无相关知识)'}## 生成要求1. 优先覆盖知识库中标注的历史Bug场景2. 参考知识库中的业务规则3. 用例格式参考项目规范4. 标注每条用例对应的知识来源"""return enhanced_promptdef generate_test_cases(self, requirement: str) -> list:"""生成测试用例"""enhanced_prompt = self.enhance_prompt(requirement)response = self.llm.invoke(enhanced_prompt)return self._parse_cases(response)
第五阶段:日常维护机制
知识库建起来不难,难在持续维护。建议建立以下机制:
每日:自动化脚本同步测试执行结果,失败的用例自动记录。
每周:用例评审后,评审意见归档;新发现的Bug及时录入。
每月:检索效果评估(查不到有用知识的原因分析);文档更新检查(过期的清理、新的补上)。
关键点:把知识库维护变成日常工作的一部分,而不是”有空再做”。
六、实践建议
投入产出评估
在决定是否引入知识库时,建议先进行小范围验证:
第一周:梳理核心模块的历史Bug记录,整理成Markdown文档第二周:选定工具(建议从文件夹+Markdown开始,跑通检索流程)第三周:接入RAG,用同一批需求对比测试(有知识库 vs 无知识库)第四周:根据对比结果,决定是否扩展知识库覆盖范围
常见误区
误区一:知识库变成垃圾场。 什么都往里存,结果什么都查不到。建议:只存”能被检索用到”的知识,定期清理。
误区二:检索策略设计失败。 知识库有,但查出来的都是噪音。建议:从实际查询出发设计检索策略,不要从文档出发。
误区三:知识库建设半途而废。 热情期一过,知识库就没人维护了。建议:把维护纳入日常工作流。
误区四:过度工程化。 一上来就要搭完整的向量数据库、RAG平台。建议:从简单开始,用文件夹+Markdown都能跑通核心逻辑,再上复杂工具。
技术选型参考
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结
在AI生成测试用例的场景中,知识库并非必需品,但确实是突破质量天花板的必要手段。
纯Prompt模式的价值: 简单标准接口、快速探索、一次性项目,投入产出比最优。85%以上的用例生成正确率,可以覆盖大量日常测试需求。
知识库的价值: 解决”业务规则精准召回”和”历史经验复用”两个核心问题。在业务复杂、规则多、准确性要求高的场景中,知识库带来的质量提升是纯Prompt无法企及的。
决策建议: 与其纠结”要不要上知识库”,不如先用现有文档跑一轮测试,量化当前的质量问题,再针对性决定投入方向。右上角场景(高复杂度+高准确性要求)建议优先考虑知识库;左下角场景(简单接口、快速探索)纯Prompt就够。