 夜雨聆风
夜雨聆风





未来的软件,必须为 LLM 重新设计
软件行业正在迎来一次真正的重构。
这次重构,不是界面换了一种颜色,不是按钮移动了一个位置,也不是产品里多了一个 AI 聊天框。真正的变化在于:软件的设计对象变了。
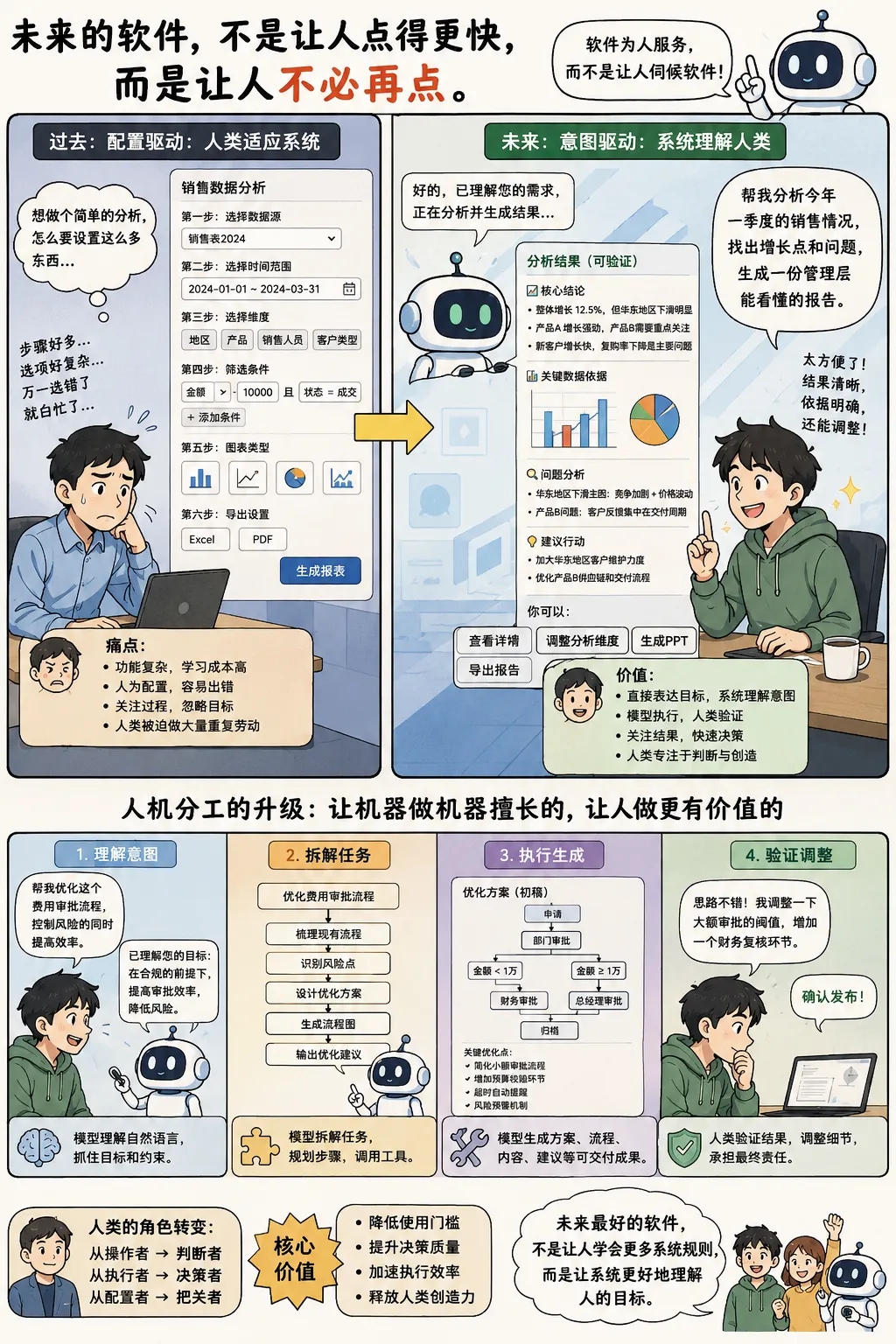
过去的软件,是为人类直接操作而设计的。按钮、菜单、表单、字段、权限、流程、配置项,本质上都是为了让人一步步把自己的意图翻译成机器能够理解的指令。人想完成一件事,必须先学会系统的语言,再按照系统的规则,把目标拆解成一个个可被执行的动作。
但 LLM 出现之后,这个前提正在崩塌。
当模型能够理解自然语言、业务上下文、文档内容、数据关系和工具能力时,软件就不应该再要求人类像机器一样工作。过去,人类负责理解系统;未来,系统必须学会理解人。过去,人类在软件里扮演的是操作者、配置者和流程维护者;未来,人类更应该成为目标提出者、结果判断者和风险验证者。
软件真正的进化,不是让人点得更快,而是让人不必再点。
因此,未来的软件不会只是“接入 AI”,而是会围绕 LLM 被重新设计。传统的配置驱动模式会逐渐让位于意图驱动模式,“模型执行、人类验证”会成为下一代软件的主流交互方式。那些仍然让用户面对复杂配置、反复点击、手动拼接流程的软件,会逐渐显得笨重、落后,甚至不合时宜。
内容总览:软件的中心,正在从“操作”转向“意图”
过去几十年,软件的基本逻辑是让人操作系统。一个人想完成某项工作,就必须知道功能在哪里、参数怎么填、规则怎么设、流程怎么走。软件把能力拆成一个个模块,把任务拆成一个个页面,把人的目标拆成一个个配置项。表面上看,这是产品设计;本质上看,这是机器无法理解人类意图时,人类被迫做出的妥协。
这种妥协持续了太久,以至于很多人已经习惯了它。我们习惯了为了生成一张报表而选择数据源、拖拽字段、设置筛选条件;习惯了为了做一次营销活动而配置人群、渠道、时间、触发规则;习惯了为了跑通一个审批流程而设置角色、权限、阈值、异常处理。久而久之,用户甚至忘了,自己真正想要的并不是“配置系统”,而是“完成目标”。
LLM 改变的正是这一点。未来的软件入口,不应该只是功能菜单,而应该是人的意图。用户不需要先想清楚该点哪个按钮,而是可以直接表达自己要达成什么结果。系统要做的,不是把一堆选项扔给用户,而是理解目标、拆解任务、调用工具、生成方案,并让人类在关键节点进行验证。
过去的软件,是让人适应机器;未来的软件,是让机器理解人。
这不是一次普通的交互优化,而是软件分工的重写。人类不应该继续承担那些重复、机械、低价值的配置劳动,模型也不应该只是停留在回答问题的层面。真正面向未来的软件,应该把 LLM 变成新的交互层,把软件能力变成可被模型调用的工具,把最终结果变成可被人类验证的对象。
一、传统软件最大的问题,是把复杂性伪装成了功能
传统软件有一个长期存在的问题:它常常把复杂性包装成功能,把难用解释成强大,把用户的负担说成灵活。
一个系统越想适配复杂业务,就会提供越多配置项;越想满足不同场景,就会设计越多规则、字段、权限和流程。于是,产品看起来越来越完整,功能列表越来越长,后台越来越庞大。但对用户来说,这些所谓的“灵活性”,往往意味着更高的学习成本、更重的操作负担和更多出错机会。
很多时候,软件不是在帮用户解决问题,而是在要求用户替它完成理解问题的工作。
比如,一个销售负责人想找出最近有流失风险的高价值客户。他真正关心的是:哪些客户有风险,为什么有风险,谁应该去跟进,什么时候跟进,用什么方式跟进。但在传统系统里,他往往要自己筛选时间范围、选择客户分组、设定指标阈值、导出数据、制作报表,再凭经验判断哪些客户值得优先处理。这个过程看似是在“使用软件”,实际上是在替软件完成分析、判断和翻译。
运营人员也一样。一次用户召回,真实目标可能只是“把快要流失但仍有转化可能的用户找回来”。但传统软件会把这个目标拆成一堆配置动作:选择人群、设置触发条件、配置发送渠道、填写文案字段、设定时间窗口、检查数据回流。用户真正关心的是结果,系统却要求用户先完成一整套机器能够理解的动作。
配置,本质上是人类替机器打工。
过去这样做,是因为机器没有理解能力。传统软件听不懂“流失风险”,也听不懂“高价值客户”,更听不懂“适合管理层阅读”或“下周优先跟进”。它只能接受明确的参数、规则和流程。所以,人类只能把自己的业务目标翻译成系统语言,像一个夹在业务和机器之间的人工编译器。
但 LLM 出现之后,这种分工已经不再合理。如果模型能够理解自然语言和业务上下文,那么继续让人类填写大量配置项,就是一种落后的产品惯性。未来的软件不应该再默认用户必须理解系统结构,而应该让系统主动理解用户目标。用户不应该为了完成一项任务,先学习一套后台规则;软件应该把人的目标转化为可执行的系统动作。
真正先进的软件,不是把复杂配置做得更精致,而是让复杂配置从用户面前消失。
二、未来软件的核心,不是功能驱动,而是意图驱动
传统软件是功能驱动的。它把能力拆成不同模块,再让用户自己选择:数据在数据模块,审批在流程模块,营销在营销模块,报表在分析模块,权限在管理后台。用户进入系统以后,要先判断自己该用哪个功能,再决定这些功能应该如何组合,最后还要自己检查结果是否正确。
这种模式的本质,是软件只提供工具,不负责理解目标。它默认用户已经知道路径,只需要一个地方完成操作。但现实情况恰恰相反,很多用户知道的是目标,而不是路径。一个管理者知道自己想提升经营效率,却不一定知道该先分析哪个指标;一个销售负责人知道自己想减少客户流失,却不一定知道该设置哪些预警规则;一个运营人员知道活动效果不好,却不一定知道问题出在渠道、用户分群还是触达时机。
这就是传统软件的局限:它给了用户很多工具,却把“如何解决问题”这件事留给用户自己。
未来的软件必须从功能驱动转向意图驱动。用户不再从菜单入口开始,而是从目标表达开始。比如,“帮我分析这个季度营收增长放缓的原因”“帮我找出最需要销售跟进的客户”“帮我根据这份合同标出风险条款”“帮我生成一份适合管理层阅读的项目汇报”。这些表达不是传统意义上的操作指令,而是人的真实意图。
LLM 的价值,就在于它可以把这些意图转化为任务结构。它需要理解用户想要什么,判断需要调用哪些工具,决定应该读取哪些数据,选择合适的分析路径,并把结果组织成人类能够理解和判断的形式。此时,模型不再只是一个问答助手,而是人类意图与软件能力之间的新中间层。
未来的软件,不是让用户在系统里寻找功能,而是让模型在系统里组织能力。
这也意味着,仅仅给旧软件加一个聊天框,并不等于完成了 AI 化。如果一个 AI 只能回答问题,却不能理解系统能力,不能调用真实工具,不能读取业务上下文,不能生成可验证结果,那它只是一个漂亮的外挂,而不是软件的下一代形态。
真正为 LLM 重新设计的软件,必须让自己的能力能够被模型理解和调用。每个功能都要有清晰的输入、输出、权限、限制和风险说明;每个任务都要能够被拆解、编排和追踪;每个结果都要能够被解释、修改和确认。过去我们评价软件,主要看页面是否清楚、功能是否丰富、流程是否完整;未来还要看它是否能被模型稳定调用,是否能承接复杂意图,是否能把任务过程变成可信结果。
未来的软件竞争,不再只是功能数量的竞争,而是意图承接能力的竞争。
谁能更好地理解用户目标,谁能更稳定地把目标转化为行动,谁能让人类更轻松地验证结果,谁就更接近下一代软件的核心。
三、主流交互方式,会从“配置—执行”变成“生成—验证”
传统软件最典型的交互模式,是“配置—执行”。用户先设置参数、填写字段、选择条件、配置规则,然后点击提交,系统再按照配置执行。这种模式看似严谨,但它有一个明显缺陷:它要求用户在执行之前,就必须准确知道自己想要什么,并且能把想法精确表达成系统规则。
这在现实工作中并不自然。很多需求一开始都是模糊的,用户知道目标,但未必知道最佳路径。一个管理者可能知道团队效率出了问题,但不一定知道应该先看人效、流程、项目周期还是沟通成本;一个财务人员可能知道预算需要优化,但不一定知道应该从渠道、区域、部门还是项目维度切入;一个法务人员知道合同需要审查,但不一定希望自己从零开始逐条寻找风险。
人类并不擅长在空白状态下精确配置复杂系统。人类更擅长的是看到一个结果,然后判断它哪里正确、哪里错误、哪里需要修改。换句话说,人类不一定擅长从零搭建规则,但非常擅长验证一个方案。
所以,未来更自然的交互模式,是“生成—验证”。
用户先表达目标,系统先生成一个可讨论、可修改、可追踪的方案,然后由人类判断、调整和确认。比如,用户说“帮我设计一个新的费用审批流程”,未来的软件不应该直接把一堆配置页面交给用户,而应该先生成一个流程草案:不同金额对应哪些审批节点,哪些情况需要财务复核,哪些情况需要总经理确认,超时多久提醒,异常情况如何升级,哪些环节存在合规风险。用户再根据公司实际情况进行验证和修改。
这才是 LLM 时代更合理的交互方式。系统负责把复杂过程先跑一遍,人类负责判断这条路是否正确。系统负责生成初稿,人类负责校准方向。系统负责处理细节,人类负责把关结果。
未来的软件,不应该让人从零开始配置,而应该让人从一个可验证的方案开始判断。
但这里有一个关键前提:生成的结果必须能够被验证。没有验证机制的自动化,只是新的黑箱;没有解释能力的智能,只会制造新的不信任。一个 AI 财务系统不能只说“建议削减市场预算 20%”,它必须说明这个建议基于哪些数据,哪些渠道回报下降,哪些地区增长放缓,削减预算可能带来什么影响,是否存在替代方案。一个 AI 法务系统也不能只说“这份合同有风险”,它必须指出风险条款在哪里、风险类型是什么、可能造成什么后果、如何修改更稳妥。
可验证,不是 AI 软件的附加功能,而是 AI 软件进入现实世界的通行证。
未来真正可靠的软件,不会要求用户盲目信任模型,而是会让用户清楚地看到模型为什么这样判断、依据是什么、不确定性在哪里、哪些地方可以修改、哪些地方必须确认。信任不是靠一句“AI 已完成”建立的,信任来自证据、解释、边界和可控性。
四、人类不会被软件取代,真正被淘汰的是低价值操作
很多人一谈到 LLM 和自动化,就会担心人类是否会被边缘化。但更准确地说,人类不会退出软件系统,人类只是会从低价值操作中退出。
过去,人类在软件中承担了太多本不该由人承担的工作。复制数据、筛选字段、设置规则、调整格式、拼接流程、检查异常、导出报表,这些动作消耗了大量时间,但并不总是创造真正的价值。它们更像是机器尚不够聪明时,人类被迫补上的那一部分劳动。
未来,LLM 和软件系统会越来越多地承担这些机械环节。模型负责理解用户意图,软件负责提供可调用能力,系统负责执行流程并生成结果。人类真正需要做的,是判断目标是否正确、方案是否合理、结果是否可信、风险是否可接受。这些事情仍然必须由人参与,因为它们涉及业务经验、组织目标、价值取舍、伦理边界和责任归属。
这是一种更合理的人机分工。机器适合处理细节、调用工具、执行流程、生成初稿;人类适合定义方向、判断取舍、承担责任、控制风险。过去的软件让人不得不像机器一样操作,未来的软件应该让机器承担机器擅长的事,让人回到人真正擅长的位置。
LLM 时代不会淘汰人,淘汰的是让人像机器一样工作的软件。
这句话背后,是软件设计理念的彻底变化。过去,用户要围着系统转;未来,系统要围着目标转。过去,用户要学习软件的规则;未来,软件要理解用户的语境。过去,人类是流程里的执行者;未来,人类应该是系统输出的判断者。
因此,未来的软件不是要削弱人的作用,而是要提升人的位置。人类从“系统配置员”变成“结果验证者”,从“流程操作者”变成“目标定义者”,从“被软件牵着走的人”变成“对软件输出进行判断和把关的人”。这不是人的退场,而是人的升级。
真正好的自动化,不是把人排除在外,而是把人放在更重要的位置上。
总结:未来的软件,不是 AI 加持旧系统,而是重新定义软件本身
LLM 时代的软件革命,本质上不是多了一个智能助手,而是人机关系的重新分工。过去,因为机器听不懂人,所以人必须学习机器的语言;未来,因为模型开始理解人的语言,软件就应该承担更多从目标到行动的转换工作。
过去的软件要求用户点击、配置、筛选、填写、拖拽和调试;未来的软件应该允许用户直接表达目标,并把复杂过程转化为可验证的结果。过去的软件以功能为中心,未来的软件以意图为中心;过去的软件依赖人工操作,未来的软件依赖模型执行;过去的软件追求流程自动化,未来的软件必须追求结果可验证。
这也意味着,下一代软件不会只是今天的软件外面套一层 AI 外壳。真正的重构会发生在更深处:软件能力要重新结构化,系统上下文要重新组织,交互模式要重新设计,权限、风险、解释和验证机制也要重新嵌入产品之中。一个软件能不能被 LLM 理解、调用、编排和解释,将成为它能否进入下一代的关键。
未来会有一类软件逐渐落后:它们功能很多,但用户依然要面对复杂配置;它们流程完整,但用户依然要手动拼接任务;它们号称灵活,但实际上只是把复杂性甩给了人。这样的软件,在 LLM 时代会越来越显得笨重。
与此同时,另一类软件会成为主流:它们能够理解人的意图,能够自动生成方案,能够调用真实工具,能够展示判断依据,能够让人类快速验证和修正结果。它们不再要求人类迁就机器,而是让机器主动靠近人的表达方式、思考方式和决策方式。

未来最好的软件,不是让人学会更多系统规则,而是让系统更好地理解人的目标。
未来最好的交互,不是让人操作得更熟练,而是让人判断得更高效。
未来最好的产品,不是把复杂性展示给用户,而是把复杂性消化在系统内部。
所以,LLM 时代的软件变革,最终改变的不是一个按钮、一个页面或一个入口,而是人和软件之间的关系。
过去,人类操作软件。
未来,人类定义目标,模型组织过程,软件完成执行,人类验证结果。
这才是下一代软件真正的形态。