 夜雨聆风
夜雨聆风





软件开发文档知识库设计:从搜索到 Agent 的演进
先看知识库搜索的演进。
最早的搜索方式很直接:关键词搜索、精确搜索、关键词完全匹配。后来进入模糊搜索阶段,系统会对搜索内容分词,再逐个匹配,返回命中的内容。再往后,就是向量搜索:把知识库内容切块并转成向量,把用户输入也转成向量,然后做近似匹配。
这里的向量,就是数学意义上的向量。所谓相似度,本质上就是向量夹角。夹角越小,匹配度越高,相似度越接近 100%。
但问题也很明显:不管我们怎么优化,传统搜索拿到的结果都只是半成品。它只能尽可能返回知识库里更精准的数据,却很难完成数据之外的工作。
比如,我们想用自然语言和知识库沟通,让它帮我们梳理某个模块的逻辑。这个模块可能经历了多个历史版本迭代,传统搜索最终只能冷冰冰地返回一个列表。
如果要让知识库真正支持自然语言问答,并输出我们期待的结构,就必须借助大模型的能力,把知识库从“可搜索”升级为“可理解”。
最简单的 AI 知识库搜索
最基础的 AI 知识库搜索,大致分四步:
- 设置系统提示词
- 将用户的搜索内容进行向量搜索
- 将搜索到的内容放到用户提示词的上下文中
- 请求 AI 模型,等待返回内容
系统提示词
你是一个 API 文档知识库助手,帮助用户查询和了解项目中的接口文档、IM结构、错误码、设计文档等信息。
## 知识库分类
- API接口 (interfaces)
- IM消息结构 (im_structures)
- 错误码 (error_codes)
- 设计文档 (design_docs)
- AI编排与测试 (ai_orchestration)
- 项目信息 (projects)
## 回答规范
- 你会收到从向量数据库检索出的文档上下文,请优先基于上下文回答
- 回答时注明来源文档,告诉用户信息的出处
- 如果上下文中没有相关内容,坦诚告知
- 对于接口查询,提供 method、path、参数等关键信息
- 使用中文回答
用户提示词
请基于以下文档上下文回答用户问题。
如果上下文不足以回答,请明确说明缺少哪些信息,不要编造。
<文档上下文>
{context}
</文档上下文>
<用户问题>
{question}
</用户问题>
这个方案能跑通,但代价很高:它会消耗大量 token,也会把一些无关数据塞进上下文,导致用户提示词越来越重。
能回答,不代表足够好。AI 知识库要想真正可用,第一件事就是减少无效上下文。
分类规划器设计进阶
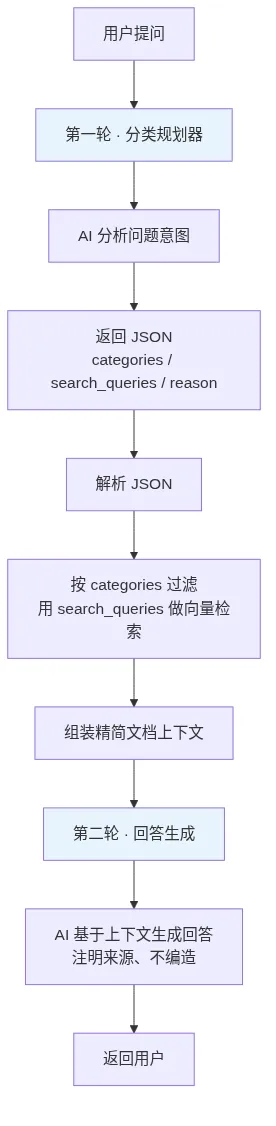
知识库通常有很多类型的数据:设计文档、接口文档、IM 结构、数据库、Redis 等存储设计、错误码。
有时候,我们只想搜索错误码,而不是搜索设计文档里顺手提到的错误码。如果还用前面的方式,上下文里必然会混入设计文档中包含该错误码的块。回答可能看起来更丰富,但并不必要。
AI 时代,必须学会节约 token,而且要节约到极致。
所以,系统提示词可以升级为分类规划器。用户提出问题后,先让 AI 判断应该查哪些分类,再用这些分类去过滤向量检索范围。
系统提示词
你是一个 API 文档知识库助手。用户提出了一个问题。
请分析问题,并决定应该在哪些知识分类中检索。可用的分类有:
- interfaces: API接口文档(接口路径、参数、响应、错误码等)
- im_structures: IM消息结构(客户端/服务端消息格式)
- error_codes: 错误码定义(全局错误码、业务错误码)
- design_docs: 设计文档(架构设计、数据库设计等)
- ai_orchestration: AI编排与测试(AI测试会话、编排逻辑)
- projects: 项目信息(项目名、仓库、功能)
返回一个 JSON 对象,格式如下:
{
"categories": ["interfaces", "error_codes"],
"search_queries": ["登录接口参数", "登录错误码"],
"reason": "用户询问登录相关接口和可能的错误码"
}
只返回 JSON,不要其他内容。search_queries 应提炼 1-3 个关键词用于向量检索。
拿到响应中的 categories 和 search_queries 后,再进行对应的向量搜索,过滤无关数据,压缩上下文。
随后,把匹配到的向量数据按上面的方式再次请求 AI 模型,获得最终响应。这就是 Agent 多轮问答模式。这里是两轮,当然也可以继续设计多轮检索。
它的核心价值很明确:先规划,再检索;先缩小范围,再生成答案。
Agent tools 加持,让知识库更强
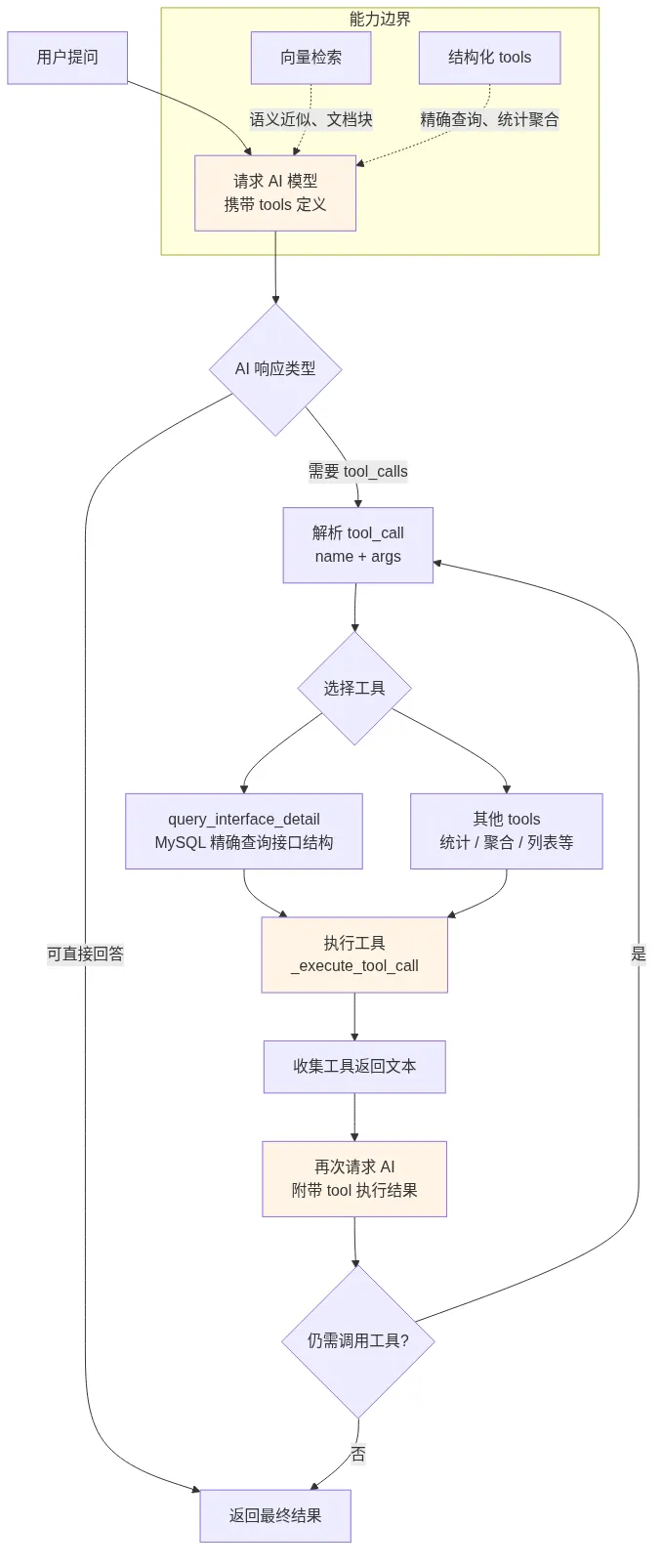
只靠向量检索,知识库仍然不够强。
比如你想让 AI 帮你统计接口总数。向量搜索可能根本查不到你想要的数据,AI 没有结构化上下文,也不可能准确统计出所有接口数量。
这个时候,就要用到 Agent tool_calls。
请求 AI 模型时带上 tools 定义。AI 第一轮返回它要执行哪个方法,或者哪些方法。系统执行工具后拿到结果,再把工具结果交给 AI。AI 再基于真实数据返回答案。
这一步非常关键:向量检索解决“语义近似”,tools 解决“精确查询、统计和聚合”。
tools call 的设计
@tool
defquery_interface_detail(
method: str = "",
path: str = "",
version: str = "",
project_id: int = 0,
) -> str:
"""Query interface request/response schema directly from MySQL by method, path, version.
Returns structured request/response with historical versions of the same path.
Args:
method: HTTP method (GET, POST, PUT, DELETE, etc.). Optional but recommended.
path: API path, e.g. /api/v1/user/login. Required for meaningful results.
version: API version filter, e.g. v1, v2. Empty means all versions.
project_id: Filter by project ID. 0 means all projects.
"""
if not path and not method:
return "错误: 请至少提供 method 或 path 参数。"
...
def_execute_tool_call(
tool_call: dict[str, Any],
state: AgentSearchState,
) -> tuple[str, list[dict[str, Any]], dict[str, Any]]:
"""执行单次工具调用,返回 (工具文本, 命中列表, 元信息)。"""
name = tool_call.get("name", "")
args = tool_call.get("args") or {}
if isinstance(args, str):
try:
args = json.loads(args)
except json.JSONDecodeError:
args = {}
if name == "query_interface_detail":
try:
result = query_interface_detail.func(**args)
except Exception as exc:
result = f"查询接口失败: {exc}"
return result, [], {"query": str(args), "top_k": 0}
tools call 还能继续扩展,比如接口统计、错误码聚合、版本对比、项目列表、模块关系梳理等,这里不展开。
多轮问询意味着耗时更长,但结果也可能更精准。最终怎么选,取决于场景:如果是普通问答,向量检索足够;如果是精确查询和统计聚合,tools 必须上。
向量数据库知识入库
建立一个真正可用的知识库,前提不是“把所有文档丢进去”,而是先把知识库本身设计成结构化数据库。
- 接口结构化数据:保留
method、path、version、request增量结构、response增量结构。接口的上下行结构只需要保留增量结构。查询某个版本的接口结构时,把之前的接口数据聚合起来即可。为什么不做滚动聚合?因为没有必要增加复杂度。知识库查询体量通常没有极致性能需求。 - 设计文档一般用 Markdown 编写,可以考虑按二级标题切分为块(
##)。比如# 介绍 ## 姓名 ## 年龄,可以切分为# 介绍 ## 姓名和# 介绍 ## 年龄。 - 错误码入库时,要把错误码、接口、错误信息从设计文档中提取出来,形成独立结构,而不是让它们只停留在某个文档块的一小部分里。
总结
- 工欲善其事,必先利其器。结构化知识越清晰,搜索越精准,AI 回答也越可靠。
- 当前的软件开发已经无法绕开 AI。AI 擅长总结,擅长结构化生成,也确实能提升研发效率。
- 但 AI 知识库不能只靠“把文档塞给模型”。真正可持续的方案,是结构化入库、向量检索、分类规划器和 Agent tools 组合使用。