 夜雨聆风
夜雨聆风





AI 时代的软件工程(1):未来产研模式的深度讨论
作者:腾讯广告技术-投放平台架构团队

导语
来自作者的声明:本文是个人的想象和思考,不代表任何组织的观点或立场。这里没有内幕消息,没有路线图剧透——只是一个工程师面对正在发生的变化,试着往前看了几步。写这些不是为了贩卖焦虑,恰恰相反——焦虑来自不理解,而思考是焦虑的解药。浪潮不以个人意志为转移,但冲浪的姿势可以选择。觉得有道理就看看,没道理就一笑了之。
核心命题:AI 不会取代软件工程,而是重新定义它。 我们正在经历的不是“工程师被 AI 替代”,而是整个产研系统的结构性重组。
00
软件工程 1.0 → 2.0 → 3.0:三次范式跃迁

图0-1 软件工程三次范式跃迁图示

在展开具体讨论之前,先回答一个根本问题:我们站在软件工程演进的什么位置上?

软件工程在过去五十多年里经历了两次范式跃迁,现在正在进入第三次。每一次跃迁都不是方法论的小修小补,而是“谁来做”和“怎么协作”的底层假设被更换了。
一、软件工程 1.0:瀑布流——线性分工,文档驱动(1968 — ~2001)
1968 年 NATO 软件工程会议的核心焦虑是:软件项目为什么总是延期、超预算、质量失控? 答案是“缺少工程纪律”。于是瀑布模型诞生了——把软件开发类比为建筑施工:
需求分析 → 系统设计 → 详细设计 → 编码实现 → 测试验证 → 运维交付↓ ↓ ↓ ↓ ↓ ↓需求文档 → 概要设计 → 详细设计 → 源代码 → 测试报告 → 上线
(一)核心假设
-
需求可以在开发前被完整定义
-
每个阶段的产出是下一阶段的输入,回头成本极高
-
人的角色是“按文档执行”——需求分析师写需求,架构师画蓝图,程序员照着写代码
(二)1.0 做对了什么
建立了“软件开发是工程活动而非艺术创作”的认知,引入了阶段评审、文档规范、测试体系,奠定了整个行业的基础。
(三)1.0 的天花板
-
假设了需求不变,但真实世界的需求永远在变
-
反馈周期太长——写完需求到看见可运行的软件,可能隔了 6-12 个月
-
文档成了目的而非手段——团队花更多时间维护文档而不是解决问题
-
人被流程困住了——每个角色都在等上游的文档,串行阻塞
瀑布流的本质困境是:它假设软件开发是确定性问题,但软件开发本质上是探索性活动。
二、软件工程 2.0:敏捷 + DevOps——快速迭代,持续交付(2001 — ~2024)
2001 年,17 位开发者在犹他州雪鸟镇签署了《敏捷宣言》,核心观点只有一句话:拥抱变化比遵循计划更重要。
这不是对 1.0 的修补,而是底层假设的翻转:
|
|
1.0 瀑布流 |
2.0 敏捷 + DevOps |
|
对需求的假设 |
需求可以预先定义完整 |
需求在迭代中逐步浮现 |
|
反馈周期 |
月 → 年 |
天 → 周(Sprint) |
|
文档角色 |
阶段交付物,必须完整 |
够用就好,代码即文档 |
|
开发与运维 |
分离(“扔过墙”) |
融合(You build it, you run it) |
|
质量保障 |
阶段末的测试 |
持续集成 + 自动化测试 |
|
团队形态 |
职能部门(开发部/测试部/运维部) |
跨职能小团队(Scrum/Squad) |
表0-1 软件工程1.0与2.0对比
敏捷解决了“需求会变”的问题;DevOps 解决了“代码写完到用户手里太慢”的问题。CI/CD、基础设施即代码(IaC)、监控告警、蓝绿发布——这些实践让“从 commit 到生产”的时间从数周压缩到数小时甚至数分钟。
(一)2.0 做对了什么
-
把反馈循环从月级压缩到天级;
-
打破了开发与运维的墙——DevOps 让“交付”成为工程文化的一部分;
-
催生了微服务、容器化、Kubernetes 等基础设施革命;
-
让“小团队快速迭代”成为行业共识。
(二)2.0 的天花板
敏捷 + DevOps 优化了人与人之间的协作效率,但有一个前提从未被触碰——代码还是人写的。
-
Sprint 再短,一个功能还是需要人写几天代码;
-
CI/CD 再快,pipeline 里跑的还是人写的测试;
-
微服务拆得再细,每个服务还是需要人来维护;
-
Scrum 站会再高效,本质上还是人在同步信息、拆任务、分工。
(三)2.0 把“人写代码”这件事的效率和协作优化到了接近极限——但人本身的产出速度,成了新的瓶颈
-
一个 Senior 工程师一天能写多少行高质量代码?答案在过去 20 年几乎没变。敏捷让他不做无用功了,DevOps 让他的代码秒级上线了,但他写代码本身的速度——没变。
三、软件工程 3.0:人 + 数字员工协作交付(2024 — )
2024 年开始,大语言模型 + Agent 框架带来了第三次跃迁。这次改变的不是“需求怎么管理”或“怎么更快上线”,而是一个更根本的问题——代码不再只由人来写了。
软件工程 3.0 的核心假设:人定义意图和约束,数字员工(Agent)交付实现。
|
|
1.0 瀑布流 |
2.0 敏捷+ DevOps |
3.0 人 + 数字员工 |
|
时代 |
1968— ~2001 |
2001— ~2024 |
2024— |
|
核心假设 |
需求可预定义,按计划执行 |
需求在迭代中浮现,拥抱变化 |
人定义意图,Agent 交付实现 |
|
代码由谁写 |
人(100%) |
人(100%),工具辅助 |
人 + Agent 协同(L1-L4 分级) |
|
反馈周期 |
月 → 年 |
天 → 周 |
分钟 → 小时 |
|
质量保障 |
阶段末测试 |
CI/CD + 自动化测试 |
自动化门禁 + 置信度评分 + 人审查 |
|
架构治理 |
架构师画图,评审会口述 |
轻量文档 + ADR |
Architecture-as-Code,Agent 可读 |
|
组织形态 |
职能部门(50-100 人) |
跨职能小团队(5-9 人) |
1-3 人 + 数字员工编制(Pod) |
|
瓶颈 |
需求变更和返工 |
人的编码速度 |
人的判断力、品味和架构能力 |
|
解决的核心问题 |
“怎么有纪律地开发” |
“怎么快速响应变化” |
“怎么让人的判断力放大 10 倍” |
表0-2 两种Spec组织方案对比
这不是渐进式的改良。1.0 → 2.0 改变了“人和人怎么协作”,3.0 改变了“人和谁协作”。当你的团队里多了一类新成员——不知疲倦、秒级执行、可以并行几十个任务的数字员工——整个产研系统的运作逻辑都得重新设计。
但在展开之前,有一个极其重要的认知需要先锚定:
第一性原理:业务复杂度不会因 AI 而消失。
一套广告投放系统的领域划分(计划、创意、出价、审核、报表),不会因为有了 Agent 就变简单;一套金融清算系统的对账逻辑,不会因为代码是 Agent 写的就减少边界情况;一套电商系统的库存-订单-物流三角关系,不会因为实现更快就变得不纠结。
合理的解决方案不会发生根本性改变。 微服务该拆的还是得拆,领域边界该划的还是得划,分布式事务该处理的还是得处理。DDD 的战略设计、CQRS 的读写分离、Event Sourcing 的溯源机制——这些不是“人的效率低下的产物”,而是业务复杂度本身的映射。
改变的是实现方式,而非实现目标。 以一套复杂系统的业务领域划分为例:子域边界在哪里、限界上下文怎么切、哪些是核心域哪些是支撑域——这些决策仍然由人来做。但拿到这个决策之后,每个子域内部的编码实现、接口对接、测试覆盖——这些可以由数字员工来完成。
理解了这一点,你会发现 1.0 → 2.0 → 3.0 的跃迁有一条清晰的红线:软件工程的“硬核”(分析复杂度、设计合理架构、做正确决策)从未改变,改变的是围绕这个硬核的执行层——从人手动执行,到人敏捷迭代,到人 + 数字员工并行交付。
三点需要特别说明:
第一,3.0 不是否定 2.0,而是站在 2.0 的肩膀上。
敏捷的核心价值观(拥抱变化、持续反馈、个体与交互)在 3.0 时代不但没过时,反而更重要——只不过“个体”从纯人变成了人 + 数字员工,“交互”从人与人之间扩展到了人与 Agent 之间。DevOps 的 CI/CD 管线在 3.0 中被扩展为 AI-Ops(第 3 节),不是替代而是升级。
第二,每次跃迁都伴随着“人的角色”的根本性重定义。
-
1.0:人是“按文档执行的工人”——需求分析师告诉你做什么,你照着写
-
2.0:人是“自组织的手艺人”——在小团队里自己决定怎么做,对交付负责
-
3.0:人是“数字员工的管理者和品质守护者”——定义意图、把控方向、审查质量、做 Agent 做不了的决策
每一次,人做的事情都在变“少”但变“贵”。1.0 你得写每一行代码;2.0 你可以复用框架和库;3.0 你甚至不用写大部分代码了——但你需要的判断力、架构思维和品味,比以往任何时候都重要。
第三,3.0 的真正挑战不在技术,而在组织和认知。
技术侧,Agent 的能力在快速提升。真正的瓶颈在于:
-
组织准备好了吗?绩效体系、晋升标准、团队编制——都还是 2.0 时代的设计;
-
人的心智模型转换了吗?从“我是写代码的”到“我是管理数字员工的”,这个认知跃迁比从瀑布到敏捷更难;
-
架构支撑了吗?Agent 需要可机读的架构上下文(Architecture-as-Code),而大多数团队的架构知识还停留在人脑里和过期的 wiki 中。
这篇文章,就是在讨论软件工程 3.0 的落地路径。后续每一节都可以映射到这个范式跃迁的框架中:
-
第 1 节(人 + Agent 协作范式):3.0 的核心工作模式——L1-L4 分级、需求自动路由、人机并行;
-
第 2 节(架构治理):从 1.0 的“架构师画图”、2.0 的“轻量 ADR”到 3.0 的“Architecture-as-Code”;
-
第 3 节(DevOps 进化):从 2.0 的 CI/CD 到 3.0 的 AI-Ops;
-
第 4 节(岗位重塑):2.0 的“全栈工程师”→ 3.0 的“数字员工管理者”;
-
第 5 节(新挑战):3.0 带来的独有问题——信任边界、安全合规、Agent plateau;
-
第 6 节(全景图):3.0 的终局想象——One Person Company。
写在正式开始之前
导读:从「人用工具」到「人 + 数字员工」
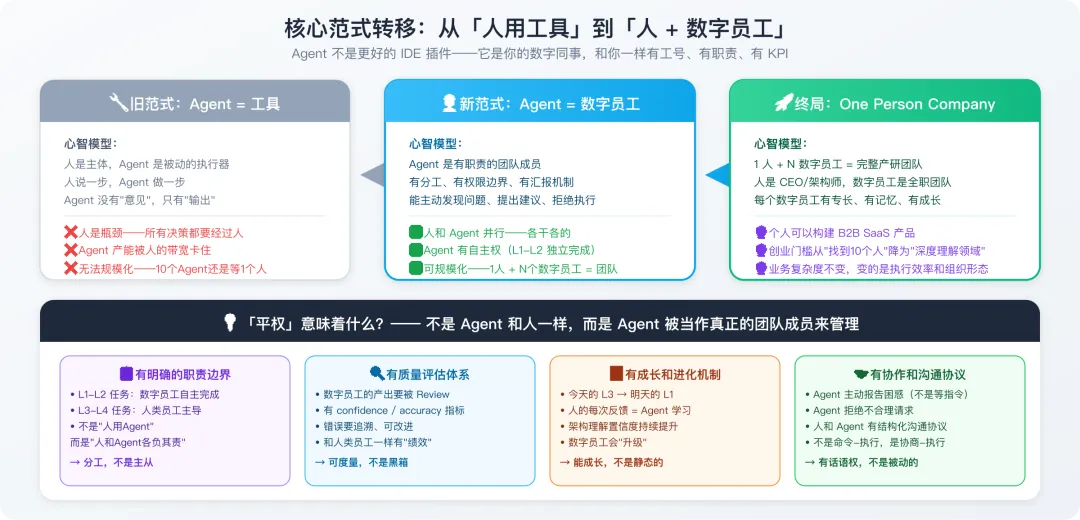
图0-2 核心范式转移图示
在开始之前,需要先建立一个贯穿全文的核心概念:数字员工。
我们习惯把 AI Agent 叫做“工具”——更好的 IDE 插件、更聪明的自动补全。但这个心智模型正在过时。当一个 Agent 能独立完成一个模块的编码、测试、部署,能主动发现架构问题并报告给你,能在你不在的时候持续监控系统健康——它还只是“工具”吗?
Agent 正在从工具变成你的数字同事
这不是比喻,而是一种实质性的组织变革。当我们说“数字员工”时,意味着:
-
有明确的职责边界——不是“人用 Agent”,而是人和 Agent 各负其责。L1-L2 任务数字员工自主完成,L3-L4 任务人类员工主导(具体分级见第 1 节);
-
有质量评估体系——数字员工的产出要被 Review,有 confidence 指标,错误可追溯、可改进——和人类员工一样有“绩效”;
-
有成长和进化机制——今天的 L3 任务,可能半年后数字员工就能自主处理(降级为 L1)。人的每次反馈都是 Agent 的学习信号;
-
有协作和沟通协议——Agent 主动报告困惑,拒绝不合理请求,和人有结构化的沟通方式——不是命令-执行,是协商-执行;
“平权”不是说 Agent 和人一样,而是 Agent 被当作真正的团队成员来管理
这个视角会改变你对全文的理解:
-
第 1 节的 L1-L4 分级,本质上是在定义数字员工的岗位职级;
-
第 2 节的架构治理,本质上是在建立人类员工和数字员工的协作制度;
-
第 4 节的岗位重塑,本质上是在回答人类员工如何与数字员工分工;
-
第 6 节的 One Person Company,则是这一切的终局——1 个人 + 完整数字员工编制 = 一个完整的产研团队。
带着这个视角,我们开始。
01
人 + Agent:新型协作范式
一、从“人写代码”到“人 + Agent 协同交付”
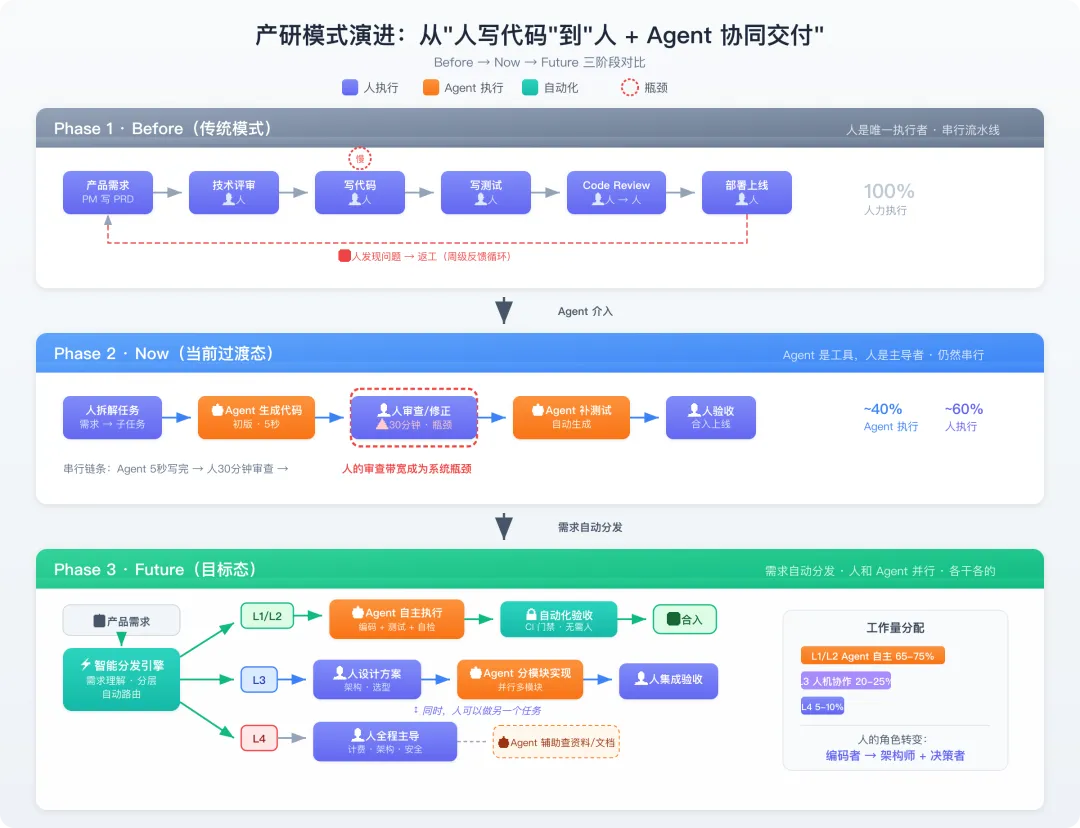
图1-1 产研模式演进图示
传统软件工程的基本假设是:代码由人编写、人审查、人维护。所有的流程、工具链、质量体系都围绕这个假设设计。
但这个假设正在被打破——而且不是一步到位,而是分阶段演进的:
(一)Before(传统模式):人是唯一执行者
产品需求 → PM 写 PRD → 技术评审 → 人写代码 → 人写测试 → 人 Code Review → 人部署↑ │└──────────── 人发现问题,返工 ─────────────────────────────┘
特征:串行流水线,每个环节都是人,瓶颈在人的产出速度。
(二)Now(当前过渡态):Agent 是工具,人是主导者
产品需求 → 人拆解任务 → Agent 生成初版代码 → 人审查/修正 → Agent 补全测试 → 人验收特征:人仍然主导全流程,Agent 在人的指令下执行子任务。 本质上还是串行的——Agent 只是加速了“写”这个环节,但需求拆解、审查、验收仍然是人。
问题:这个模式的天花板很明显——人成了瓶颈。 Agent 5 秒写完代码,但人要花 30 分钟审查。Agent 的产能被人的审查带宽卡住了。
(三)Future(目标态): 需求自动分发,人和 Agent 并行
┌─── L1/L2 任务 ──→ Agent 自主执行 ──→ 自动化验收 ──→ 合入│ (写代码+测试+自检) (CI 门禁)产品需求 → 智能分发引擎 ──----┤(需求理解+ │分层+分配) ├─── L3 任务 ───→ 人设计方案 ──→ Agent 分模块实现 ──→ 人集成验收│ ↕ 并行│ 人做另一个任务│└─── L4 任务 ───→ 人全程主导(Agent 辅助查资料/写文档/补测试)
特征:不再是人指挥 Agent 的串行模式,而是需求自动路由、人和 Agent 各干各的并行模式。
(四)Agent 协作分级(L1-L4)定义 —— 类比自动驾驶
自动驾驶有 L0-L5 分级,我们的 Agent 协作同样需要清晰的分级定义。两者的底层逻辑是一致的:自动化程度越高,人的角色从“执行者”变为“监督者”再变为“乘客”。
|
级别 |
自动驾驶 |
Agent协作(软件工程) |
人的角色 |
|
L0 |
无自动化:人完全操控 |
2001— ~2024 |
2024— |
|
L1 |
辅助驾驶:定速巡航、车道保持(单一功能) |
Agent 自主完成:单文件/模板化任务(单测生成、配置修改、UI组件、proto 字段追加) |
最终确认(5 min Review)类似看一眼仪表盘 |
|
L2 |
部分自动:同时控制转向+加速,但人必须随时接管 |
Agent 主导 + 人审查:模式清晰但需业务判断(新增 RPC 接口、DDD 新功能、AI 模型脚手架) |
审查业务正确性(30 min-1h)类似手放方向盘但眼睛盯路 |
|
L3 |
有条件自动:特定场景 Agent 驾驶,但人要能快速接管 |
人 + Agent 协作:跨模块/跨服务,需系统全局理解(跨服务链路变更、Schema 变更、性能优化) |
架构设计 + 方案选型(数小时-数天)类似在高速上,偶尔要接管 |
|
L4 |
高度自动:特定区域无需人干预 |
人主导:架构决策、计费/出价核心、安全合规Agent 仅辅助查资料/写文档/补测试 |
全程主导(数天-数周)类似手动开过复杂路口 |
|
L5 |
完全自动:无方向盘 |
Agent 完全自主:需求→设计→编码→测试→部署(目前不存在,是 Phase 4 愿景) |
只定义目标和约束类似告诉车目的地 |
表1-1 自动驾驶与Agent协作的 L0-L5 分级
从导读中「数字员工」的视角看,L 分级同时定义了数字员工的能力等级和自主权范围——L1 是实习生(只做模板化工作,人看一眼即可),L2 是初级员工(能独立干活但需要 mentor 审查),L3 是高级员工(能协作但关键决策要汇报),L4 是目前还不存在的“专家级数字员工”。整篇文章中,L 分级不仅用于任务分类,还会复用到架构治理(第2节)、主动报告(第2节③)、模块风险评估(architecture-snapshot)——一套标准,多处复用。
(五)分级的三个判断维度(决定一个任务属于哪个级别)
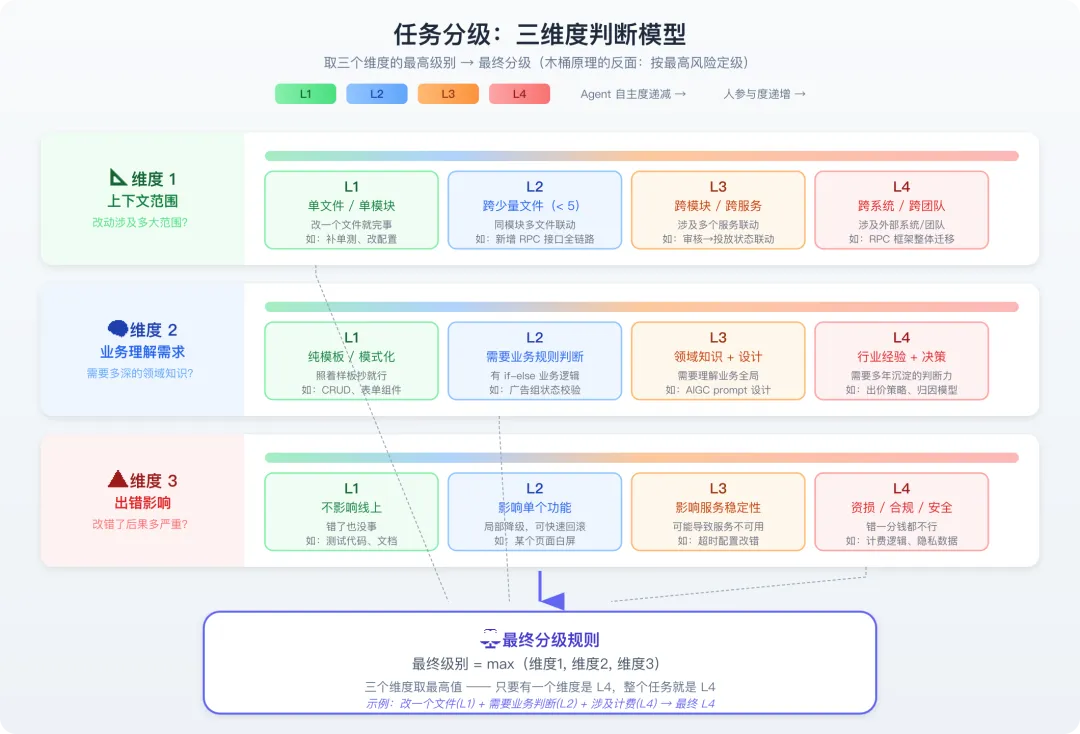
图1-2 三维度判断模型图示
三个维度各自独立判断后,取最高级别作为最终分级——只要有一个维度是 L4,整个任务就是 L4。
┌───────────────────────────────────────────┐│ 任务属于哪个级别? ││ ││ 维度 1: 上下文范围 ││ ├── 单文件/单模块 ─────────→ L1 ││ ├── 跨少量文件(< 5 个)──→ L2 ││ ├── 跨模块/跨服务 ────────→ L3 ││ └── 跨系统/跨团队 ────────→ L4 ││ ││ 维度 2: 业务理解需求 ││ ├── 纯模板/模式化 ────────→ L1 ││ ├── 需要业务规则判断 ──────→ L2 ││ ├── 需要领域知识 + 设计 ──→ L3 ││ └── 需要行业经验 + 决策 ──→ L4 ││ ││ 维度 3: 出错影响 ││ ├── 不影响线上 ───────────→ L1 ││ ├── 影响单个功能 ─────────→ L2 ││ ├── 影响服务稳定性 ───────→ L3 ││ └── 涉及资损/合规/安全 ───→ L4 ││ ││ 取三个维度的最高级别作为最终分级 │└───────────────────────────────────────────┘
和自动驾驶的关键差异:
-
自动驾驶的 L3→L4 跨越主要受限于感知技术(传感器能不能覆盖所有场景);
-
Agent 协作的 L3→L4 跨越主要受限于意图理解(Agent 能不能理解业务为什么要这样做);
-
注意 L4 的映射方向相反:自动驾驶 L4 = 车自己开,人更少参与;Agent 协作 L4 = 人必须主导,因为出错代价太高。方向虽反,逻辑一致——越高风险,越需要最有能力的角色主导;
-
共同点:两者的分级都不是固定的——同一个任务,随着 Agent 能力提升和上下文完善,今天的 L3 可能明年变成 L2。
(六)核心变化
|
维度 |
Before |
Now(过滤态) |
Future(目标态) |
|
需求分配 |
PM → 人 |
PM → 人 → 人把子任务给 Agent |
智能分发引擎自动路由 |
|
执行模式 |
人串行 |
人+Agent 串行(人指挥Agent) |
人和Agent并行(各干各的) |
|
代码产出者 |
人 |
人 + Agent(人主导) |
Agent 为主(L1/L2),人为主(L3/L4) |
|
质量把关 |
CR (人→人) |
CR (人→Agent产出) |
分层质检:L1 自动门禁 L2 人抽检 L3+ 人深度审查 |
|
设计决策 |
人 |
人(Agent 提供选项) |
人(但 Agent 能推荐历史方案) |
|
重复性工作 |
人(痛苦地) |
Agent |
Agent(人甚至不感知) |
|
上下文理解 |
人脑中 |
部分文档化 |
Context-as-Code:完整机器可读 |
|
人的角色 |
编码者 |
编码者 + 审查者 |
架构师 + 决策者 + 质量守护者 |
表1-2 核心变化对比
关键洞察:从 Now 到 Future 的跳跃,不只是 Agent 能力的提升——更需要三个基础设施:
-
需求的结构化表达:产品需求必须足够精确,才能被机器理解和自动分类(这就是 Spec-as-Code)
-
分层标准的机器可判断:L1/L2/L3/L4 的分类不能靠人判断,要有自动化的分类引擎
-
自动化验收能力:L1 任务的验收不能依赖人,必须有足够强的自动化测试 + CI 门禁
二、需要解决的核心问题
(一)问题 1:Agent 产出的代码谁负责?
传统 Code Review 有一个隐含契约——“谁提交谁负责”。当 Agent 产出了 60% 的代码,出了线上事故,责任怎么算?
这不只是管理问题,更是工程文化问题。可能的演化方向:
-
“飞行员模式”:Agent 是自动驾驶,人是飞行员。自动驾驶可以飞,但机长对安全负最终责任;
-
“分级审查”:Agent 产出的代码标记 confidence level,低置信度的强制人工审查,高置信度的自动合入;
-
新的 Code Review 范式:审查重心从“这行代码对不对”转向“Agent 的理解是否正确、设计决策是否合理”。
(二)问题 2:上下文传递的瓶颈
Agent 最大的弱点不是写不好代码,而是不理解系统的历史决策和隐含约束。
一个资深工程师脑中的知识包括:
-
“这个模块三年前做过一次大重构,那次踩了哪些坑”;
-
“这个接口不能改返回值,因为下游有 50 个服务依赖”;
-
“老板说了这个功能下个季度要砍”……
传统思路是“人写文档喂给 Agent”——但这把瓶颈从写代码转移到了写文档,而且文档天然会过期。
真正的解法不是人喂 Context,而是让 Agent 自己构建和维护对系统的理解。
解决方案:Architecture Understanding Agent(架构理解 Agent)
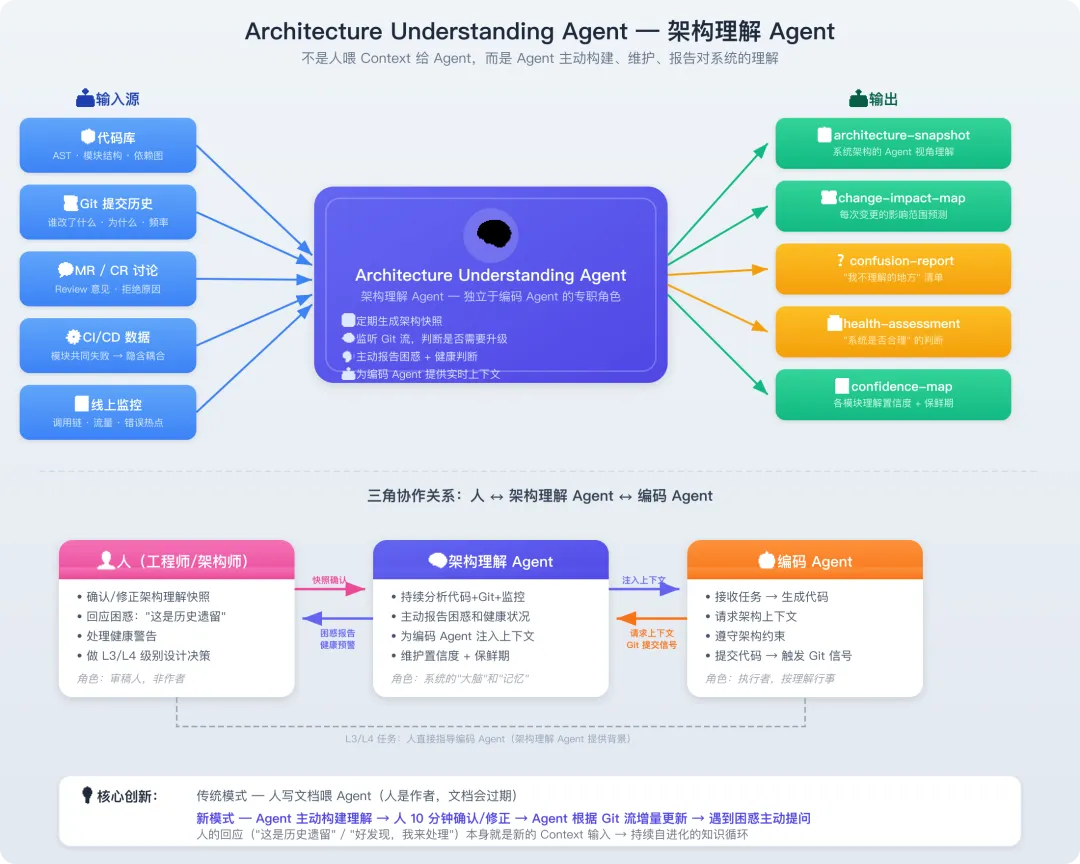
图1-3 架构理解 Agent图示
这是一个独立于编码 Agent 的专职 Agent,它的唯一职责是:理解系统架构,并保持这个理解的准确性。
┌─────────────────────────────────────────────────────────────────┐│ Architecture Understanding Agent ││ ││ 输入源: ││ ├── 代码库(AST、模块结构、依赖图、接口定义) ││ ├── Git 提交历史(谁改了什么、为什么改、频率多高) ││ ├── MR/CR 讨论(人在 Review 中说了什么、拒绝了什么) ││ ├── CI/CD 数据(哪些模块经常一起失败 → 隐含耦合) ││ └── 线上监控(调用链、流量分布、错误热点) ││ ││ 核心能力: ││ ├── 1. 定期生成架构理解快照 → 人确认/修正 ││ ├── 2. 监听 Git 提交流,判断是否需要架构理解升级 ││ ├── 3. 主动报告"我觉得这里不合理"/ "我理解不了这个设计" ││ └── 4. 为编码 Agent 提供实时、准确的架构上下文 ││ ││ 输出: ││ ├── architecture-snapshot.md — 当前系统架构的 Agent 视角理解 ││ ├── change-impact-map — 每次变更的影响范围预测 ││ ├── confusion-report — "我不理解的地方"清单 ││ ├── health-assessment — "我觉得系统是否合理"的判断 ││ └── confidence-map — 各模块理解置信度 + 保鲜期 │└─────────────────────────────────────────────────────────────────┘
(三)关键设计原则
① 定期生成 + 人确认(而非人编写)
传统:人写架构文档 → 喂给 Agent → 文档过期 → Agent 用错误 Context 生成错误代码新模式:Agent 自己读代码+Git → 生成架构理解 → 人花 10 分钟确认/修正 → 循环
人的角色从作者变为审稿人——工作量从“写10页文档”降低到“审10页文档”,而且 Agent 不会忘记更新。
② 基于 Git 提交流的增量更新
不是每次都做全量分析,而是监听 Git 提交,智能判断:
|
Git 信号 |
Agent 判断 |
动作 |
|
小范围改动(单文件、< 100行) |
不影响架构理解 |
不更新 |
|
新增模块/目录 |
架构结构变化 |
生成增量更新,请人确认 |
|
proto/IDL 变更 |
接口契约变化 |
主动告警 + 更新依赖图 |
|
大批量文件删除/移动 |
可能是重构 |
触发全量架构理解刷新 |
|
新增 thirdparty 依赖 |
技术栈变化 |
更新技术栈画像 |
|
同一模块连续多天高频改动 |
可能是大型功能开发或重构 |
标记观察,完成后请人确认新架构 |
表1-3 基于 Git 提交流的增量更新
③ 主动报告困惑和判断(最关键的创新点)
传统 Agent 只会执行——你问它才答。但 Architecture Understanding Agent 应该主动说话。
它有两种触发模式,但共用同一套 L1-L4 分级(不引入新概念):

图1-4 两种触发模式图
模式 A:实时检测 — 每次 MR / Git Push 时触发
类比:飞行中的实时告警系统。快,针对”这个 MR 有什么问题”。
|
L级别 |
优点 |
缺点 |
|
L1 |
变更自检通过,无架构影响 |
自动放行,记录变更摘要 |
|
L2 |
变更涉及不确定的设计意图 — “这个 MR 修改了 dpmanage 和 dpsmart 的共享代码,但我不确定它们是否应该共享” |
推送问题卡片给 Owner |
|
L3 |
变更可能导致跨服务影响 — “这个 proto 变更影响 scoring + ranking + display 三个服务” |
要求同步验证下游兼容性 |
|
L4 |
变更触及高危区域 — “bid_strategy.cc 被修改但未标记为 L4 审查” / “proto 字段被删除” |
立即阻断 MR + 通知 Owner + 告警 |
表1-4 模式A各级别优缺点对比
模式 B:全量扫描 — 定期(每周)/ 大版本前 / 架构师手动触发
类比:年度体检报告。深度分析“系统整体有什么趋势性问题”。
|
L级别 |
优点 |
缺点 |
|
L1 |
代码卫生 — 重复代码、过期文档、未使用依赖、可升级版本 |
自动生成清理 MR,人周报浏览即可 |
|
L2 |
Agent 的困惑 — “mixer/ 下 3 种混排策略,什么场景用哪个?” / “Flare 和 tRPC 共存是过渡态还是长期设计?” |
推送问题卡片,人的回答即新 Context |
|
L3 |
架构健康退化 — “scoring 循环依赖本月从 3 增加到 7” / “creative 48 子模块 7 种语言,接口风格不一致” |
生成架构治理提案(含方案 A/B/C) |
|
L4 |
系统性风险 — “review-java 16 微服务共享一个 DB 连接——单点风险” / “proto 中 30% 字段从未被引用” |
升级到架构评审会 |
表1-5 模式B各级别优缺点对比
两种模式的区别仅在于触发时机和分析范围,分级标准和响应链路完全一致:
|
|
模式A(实时) |
模式B(全量) |
|
看什么 |
这一次变更 |
整个代码库 |
|
多快 |
秒级(MR 提交时) |
小时级(定期任务) |
|
发现什么 |
单点风险 |
趋势性问题 |
|
L分级 |
同一套 L1-L4 |
同一套 L1-L4 |
|
响应链路 |
同一套 响应机制 |
同一套 响应机制 |
表1-6 两种模式的区别对比
核心洞察:闭环让系统越来越聪明。
-
人对 L2 困惑的每一个回答,都自动变成新的 Context——Agent 下次不会再问同样的问题
-
L3 的架构决策写入 ADR,Agent 的理解置信度提升
-
L4 的复盘产生新的护栏规则,防线越来越厚
-
今天的 L3 问题,可能半年后 Agent 已经能自动处理(降级为 L1)——这就是系统的自我进化
④ 为编码 Agent 提供实时上下文
当编码 Agent 要修改某个模块时,不需要人写 prompt 描述上下文,Architecture Understanding Agent 自动注入:
编码 Agent 请求:"我要修改 scoring/server/bid_strategy.cc"Architecture Understanding Agent 自动提供:├── 这个文件属于精排出价模块,owner 是 XXX├── 最近 3 个月改了 47 次,是高频变更文件├── 上下游依赖:被 ranking/server 和 display/server 调用├── 相关的 proto 定义在 ad_protos/bid_strategy.proto├── 注意:这个模块涉及计费核心逻辑,任何修改需要 L4 级别审查├── 历史坑点:2025-09 因浮点精度问题导致出价偏差 0.1%(见 ADR-017)└── 当前架构理解置信度:85%(上次确认:3天前)
⑤ 理解的“置信度”和“保鲜日期”
Agent 的每一条架构理解都应该有置信度和保鲜期:
以下为设计提案示例(ads-main 中尚不存在),展示 Architecture Understanding Agent 应产出的架构快照格式。 模块结构和 OWNERS 来自 adq/delivery 仓库真实代码扫描(2026-03-24),其余字段为提案设计。
# architecture-snapshot.yaml(提案示例 — 基于 adq/delivery 真实代码结构,因为篇幅原因做了删减)# 由 Architecture Understanding Agent 自动生成,人确认后生效# 生成时间: 2026-03-24T10:00:00+08:00# 代码库: ads-main/adq/deliverymeta:schema_version: "1.0"generated_by: "architecture-understanding-agent"scan_scope: "adq/delivery/"last_full_scan: 2026-03-24next_scheduled_scan: 2026-03-31 # 全量扫描周期:每周# ========== 系统级架构理解 ==========system:name: "delivery-platform"description: "广告投放平台 — 从流量接入到广告全生命周期管理的完整链路"architecture_style: "微服务 + CQRS + BFF"tech_stack:backend: ["Go (trpc-go, gorm)", "Java (delivery_data)"]frontend: ["TypeScript (React)"]protocol: ["gRPC / tRPC + Protocol Buffers"]infra: ["MySQL (分库分表+主从)", "Redis", "Pulsar", "Prometheus"]confidence: 0.95last_verified: 2026-03-20 # 人最后确认日期stale_after: 30d # 系统级理解保鲜期较长# Agent 发现的分层约束(来自 _spec/modules/delivery/_baseline/constitution.md)constraints:- rule: "服务间接口必须通过 .proto 文件定义,禁止非类型化 JSON"source: "constitution.md"confidence: 0.99# 服务调用拓扑(Agent 通过代码扫描+proto分析自动生成)call_graph:- from: "dpbff"to: ["dpmain", "dpasset", "dporder", "dptask", "dpmanage"]protocol: "gRPC"- from: "dpmain"to: ["dpasset", "dporder"]protocol: "gRPC"confidence: 0.88 # 调用关系部分来自代码分析,可能遗漏动态调用open_questions:- "dpsmart 与 dpmain 之间是否存在双向调用?代码中有 import 但未找到实际 RPC 调用"# ========== 模块级架构理解(示例) ==========modules:dpmain:description: "广告管理核心"path: "delivery/server/dpmain"lang: "Go"scale: {go_files: 1126} # 最大的后端服务owners: ["J"]confidence: 0.90last_verified: 2026-03-20stale_after: 14d # 核心模块保鲜期短——变更频繁change_frequency: "高 (近30天 184 次文件变更)"risk_level: "L4" # 涉及出价/预算/风控核心逻辑dependencies:upstream: ["dpbff"]downstream: ["dpasset", "dporder"]open_questions:- "竞价逻辑中 legacy_mode 分支是否还有流量?代码中有但注释说'待下线'"- "预算控制的分布式锁实现跨了 Redis 和 MySQL,一致性保证机制不清楚"dpmanage:description: "广告管理查询子服务 — 只读,提供广告列表/账户信息/报表数据"path: "delivery/server/dpmanage"lang: "Go"scale: {go_files: 794}owners: ["C"]confidence: 0.93last_verified: 2026-03-20stale_after: 14dchange_frequency: "中 (近30天 78 次文件变更)"risk_level: "L2" # 只读服务,影响范围可控constraints_local:- "只读服务,禁止实现写操作(写属于 dpmain)"- "批量查询必须支持分页,禁止返回全量数据"dependencies:upstream: ["dpbff"]downstream: ["MySQL从库", "Redis"]open_questions:- "dpmanage 和 dpmain 共享了部分代码(delivery/delivery/ 公共库),修改公共库时两边是否都需要回归?"# ========== Agent 困惑清单(全局) ==========confusion_report:generated_at: 2026-03-24items:- id: "C002"level: "L2"question: "dpmanage 和 dpmain 共享 delivery/delivery/ 公共库的边界?"context: "两个服务都 import 了 delivery/delivery/client/ 和 delivery/delivery/filter/"suggested_action: "明确公共库的 Owner 和变更影响范围"# ========== 健康度评估 ==========health_assessment:generated_at: 2026-03-24overall: "良好(存在可控风险)"scores:modularity: 0.82 # 模块划分清晰consistency: 0.75 # 部分模块共存拉低一致性documentation: 0.70 # _spec 基线覆盖了核心模块,但 dpsmart 等新模块缺失test_coverage: null # 需要 CI 数据,暂无法评估risks:- severity: "中"description: "dpasset (1589 Go文件) 可能成为'巨石服务',建议关注模块内聚度"
置信度低 + 过期的模块,编码 Agent 在修改前会自动提醒人:“我对这个模块的理解可能过时了,建议先确认”。
这个示例的关键特征:
|
特征 |
说明 |
|
数据来源真实 |
模块名、OWNERS、文件数、变更频率均来自 adq/delivery 仓库实际扫描 |
|
置信度分层 |
来自明确文档(constitution.md)的约束置信度 0.99,Agent 推断的调用关系 0.88,新模块理解 0.75 |
|
保鲜期差异化 |
高频变更模块 7d,核心模块 14d,稳定基础设施 21-30d |
|
困惑即价值 |
confusion_report 不是 bug——每个困惑被人回答后,都变成新的 Context |
|
风险分级复用 L1-L4 |
每个模块的 risk_level 复用同一套 L1-L4 分级标准 |
表1-7 示例关键特征与说明
(四)问题 3:人的能力转型
当 Agent 能写 CRUD、能补测试、能做简单重构时,工程师的核心竞争力是什么?
-
系统思维:理解复杂系统的整体行为,Agent 只看局部;
-
领域知识:业务逻辑、行业规则、合规要求;
-
判断力:在多个技术方案中做取舍,平衡短期收益和长期可维护性;
-
沟通力:将模糊的业务需求翻译成精确的技术规约(而这恰恰是喂给 Agent 的“prompt”)。
三、新的工程实践
|
实践 |
说明 |
|
Prompt Engineering as Spec |
需求文档本身就是给 Agent 的高质量 prompt,精确度要求远超传统 PRD |
|
Agent-Aware Code Review |
审查者需要理解 Agent 的行为模式,知道它容易犯什么错 |
|
Human-in-the-Loop Testing |
Agent 生成代码 + 测试,人验证测试的充分性和边界条件 |
|
Context-as-Code |
系统上下文、架构约束、隐含规则以代码/配置形式存储,Agent 可读取 |
表1-8 新的工程实践与说明
02
架构治理:不会消失,反而更重要
一、为什么 Agent 时代架构更重要?
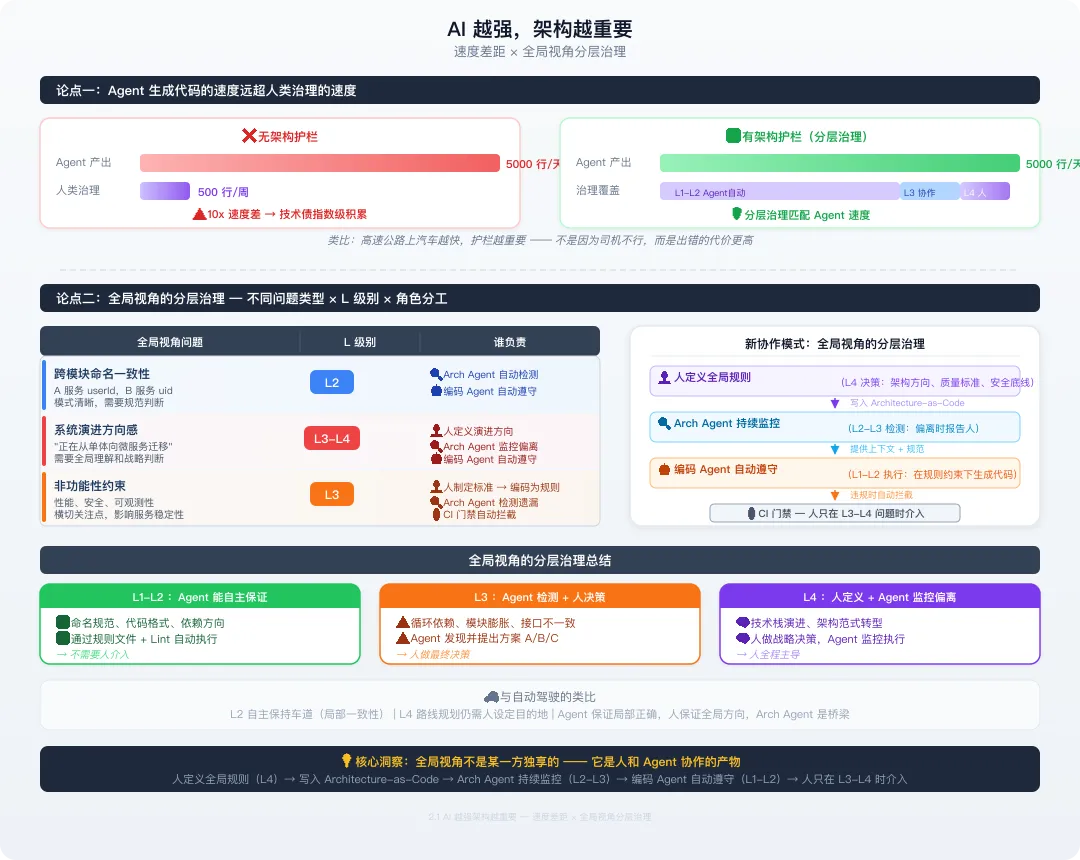
图2-1 速度差距 X 全局视角分层治理图示
一个反直觉的结论:AI 越强,架构越重要。
回到导读的核心概念——当 Agent 从“工具”变成“数字员工”,产出速度提升 10 倍时,如果没有架构护栏,技术债的积累速度也是 10 倍。数字员工越能干,管理制度(架构治理)越重要。
原因在于——
Agent 生成代码的速度远超人类治理的速度。
-
以前一个工程师一周写 500 行有效代码,架构师有时间审查和治理;
-
现在 Agent 一天生成 5000 行代码,如果没有架构护栏,技术债的积累速度是指数级的。
类比:就像高速公路上的汽车越快,护栏越重要——不是因为司机不行,而是出错的代价更高。
全局视角:不是 Agent 做不到,而是需要人机协同。
一个常见的误解是“Agent 天然缺乏全局视角”——但这不是 Agent 的本质限制,而是当前编码 Agent 的使用方式导致的。编码 Agent 被喂入的 Context 通常是局部的(一个文件、一个函数),所以它的产出自然是局部最优的。
真正的问题是:谁负责提供全局视角?
在第 1 部分中,我们提出了 Architecture Understanding Agent 作为上下文传递瓶颈的解决方案。它同样是全局视角问题的解法——但需要结合 L 分层任务来理解:
|
全局视角问题 |
本质是什么级别的任务 |
谁负责 |
|
跨模块命名一致性 A 服务叫 userId,B 服务叫 uid |
L2:模式清晰,需要规范判断 |
Architecture Understanding Agent 自动检测 + 推送规范建议 编码 Agent 在生成时自动遵守命名规则 |
|
演进方向感 “我们正在从单体向微服务迁移” |
L3-L4:需要系统全局理解和战略判断 |
人定义演进方向 → 写入 Architecture-as-Code Architecture Understanding Agent 监控偏离 → 编码 Agent 自动遵守 |
|
非功能性约束 性能、安全、可观测性 |
L3:横切关注点,影响服务稳定性 |
人制定标准 → 编码为可执行规则 Architecture Understanding Agent 检测遗漏 → CI 门禁自动拦截 |
表2-1 全局视角问题的任务分级与责任分配矩阵
核心洞察:全局视角不是某一方独享的——它是人和 Agent 协作的产物。
传统思维(错误):人有全局视角 → 人审查一切 → 人成为瓶颈新的协作模式:人定义全局规则(L4 决策)↓ 写入 Architecture-as-CodeArchitecture Understanding Agent 持续监控(L2-L3 检测)↓ 发现偏离时报告编码 Agent 自动遵守(L1-L2 执行)↓ 违规时 CI 自动拦截人只在 L3-L4 问题时介入
这实质上是全局视角的分层治理:
-
L1-L2 层的全局一致性(命名、格式、依赖方向)→ Agent 能自主保证,通过规则文件和 Lint;
-
L3 层的架构健康(循环依赖、模块膨胀、接口风格不一致)→ Agent 检测 + 人决策;
-
L4 层的战略方向(技术栈演进、架构范式转型)→ 人定义 + Agent 监控偏离。
与自动驾驶的类比:自动驾驶车辆在 L2 级别可以自主保持车道(局部一致性),但在 L4 级别的路线规划仍需要人设定目的地。Agent 协作也是如此——Agent 保证局部执行正确,人保证全局方向正确,Architecture Understanding Agent 是两者之间的桥梁。
二、架构治理的新形态:人机共治
传统的架构治理是纯人工系统:文档 + 评审会 + 口口相传。AI 时代不是把人替换掉,而是变成人机协作的治理体系:
传统:架构师写《微服务设计规范》PDF → 没人看 → 系统腐化↑ 瓶颈:人写、人读、人遵守AI 时代(人机共治):人定义架构约束 → 编码为规则(Architecture-as-Code)→ Agent 生成代码时自动遵守↑ ↓└─── Architecture Understanding Agent 发现新问题 ←── 违规自动拦截 + 健康度报告
关键变化不是”Agent 替代人治理”,而是三个角色各司其职:
|
角色 |
职责 |
对应L级别 |
|
人(架构师) |
制定规则、做架构决策、确认 Agent 的理解 |
L3-L4:需要领域经验和战略判断 |
|
Architecture Understanding Agent |
监控架构健康、检测偏离、报告困惑、为编码 Agent 提供 Context |
L2-L3:需要系统全局理解 |
|
编码 Agent |
在规则约束下生成代码、自动遵守架构规范 |
L1-L2:执行层面的一致性保证 |
表2-2 人机协同中的三角色职责与 L 级别划分
具体来看,每个治理维度都有了人机协作的新模式:
|
治理维度 |
传统方式 |
AI 时代(人机共治) |
|
分层约束 |
“controller 不能直接调 dao”(靠人遵守) |
人定义规则 → ArchUnit/Lint 自动执行 → Agent 检测新增违规 |
|
API 规范 |
Swagger 文档(可能过期) |
人定义 Schema → Agent 自动生成实现 → Architecture Understanding Agent 检测 Schema 与实现的偏离 |
|
依赖管理 |
“别引入新依赖”(靠 Review) |
人维护白名单 → Agent 生成时受约束 → Agent 定期扫描发现未授权依赖 |
|
数据模型 |
ER 图(可能过期) |
人设计 Schema → 作为 SSoT → Agent 检测 Schema 漂移并报告 |
|
跨模块一致性 |
架构师人工审查(不可持续) |
人定义命名规范 → Architecture Understanding Agent 持续扫描一致性 → 推送治理建议 |
|
架构演进方向 |
架构评审会(低频、滞后) |
人写 ADR → Architecture Understanding Agent 实时监控代码是否偏离方向 → L3+告警 |
表2-3 架构治理维度的传统方式与人机共治模式对比
本质区别:传统架构治理的瓶颈在于“规则靠人执行、偏离靠人发现”。人机共治模式下,人只负责定义规则和做最终决策,Agent 负责执行和监控——人从“巡逻员”变成“立法者 + 法官”。
三、Architecture-as-Code:人机共治的落地形态
第二部分描述了“人定义规则、Agent 执行和监控”的协作模式。要让这个模式落地,架构约束必须机器可读、自动执行——这就是 Architecture-as-Code:
-
.architect 规则文件:定义模块边界、依赖方向、命名规范,编码 Agent 生成时自动遵守,Architecture Understanding Agent 定期扫描偏离;
-
Contract Testing:微服务间的契约自动验证——Architecture Understanding Agent 在模式 A(实时检测)中自动触发契约检查;
-
Fitness Functions:持续监控架构指标(耦合度、循环依赖、模块大小),偏离阈值时 Architecture Understanding Agent 按 L 分级报告。
与 L 分层的关系:Architecture-as-Code 本质上是把 L3-L4 级别的架构决策(人做的)转化为 L1-L2 级别的自动化规则(Agent 执行的)。人的智慧被编码后,Agent 无限复用——这就是人机共治的放大效应。
03
DevOps 的进化:从 CI/CD 到 AI-Ops
一、为什么 DevOps 不会消失?
有人说“Agent 能自动写代码、自动部署,还要 DevOps 干什么?”
这是对 DevOps 的误解。DevOps 的核心不是“自动化部署”,而是:
缩短从想法到生产环境的反馈循环,同时保证可靠性。
Agent 时代这个需求不但没消失,反而更强烈了——用数字员工的视角看,DevOps 正在经历和编码一样的分层演进:L1-L2 级别的部署和监控正在被 DevOps Agent 接管,人聚焦 L3-L4 的发布策略和故障决策:
|
传统 DevOps 挑战 |
AI 时代放大版 |
|
部署频率太低 |
Agent 产出速度 10x,部署频率需求暴增 |
|
线上问题定位慢 |
Agent 生成的代码可能有人类不熟悉的模式,排障更难 |
|
配置管理复杂 |
Agent 可能引入不一致的配置,需要更严格的 GitOps |
|
安全漏洞 |
Agent 可能生成有安全隐患的代码(训练数据中的坏模式),需要更强的安全扫描 |
表3-1 传统 DevOps 挑战及其在 AI 代码生成时代的放大效应
二、DevOps 的新能力要求
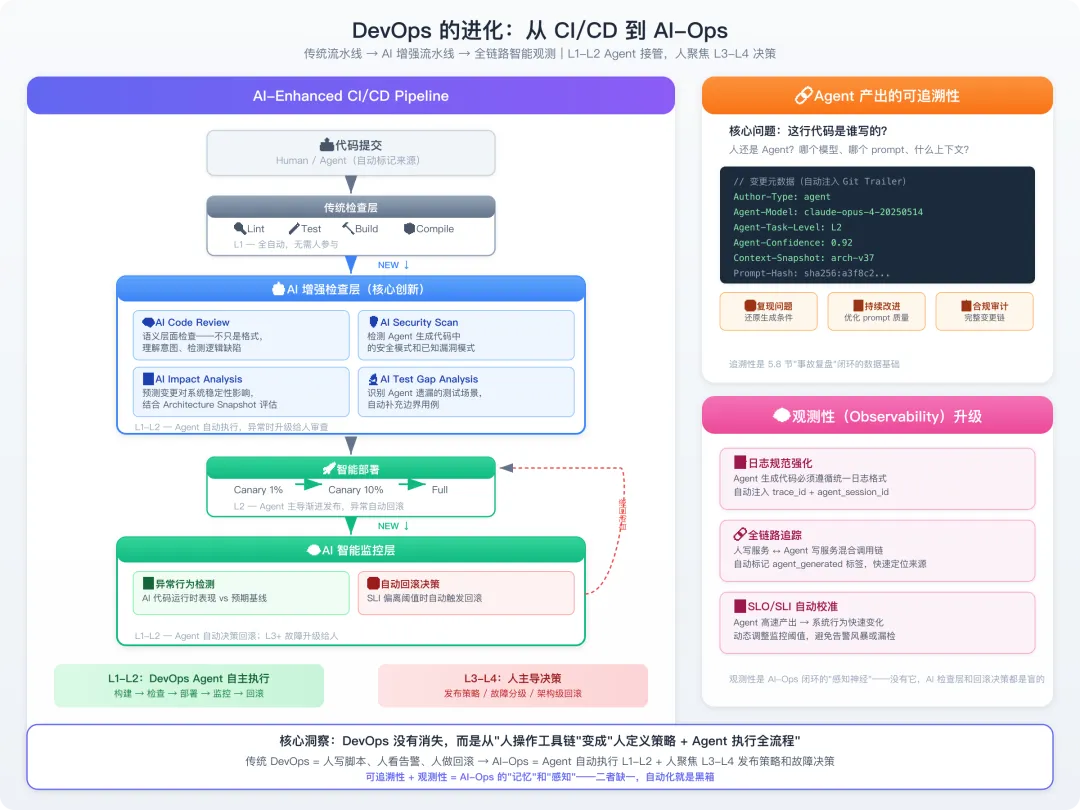
图3-1 DevOps 的进化:从 CI/CD 到 AI-Ops-1
(一)AI-Enhanced CI/CD Pipeline
代码提交 (Human/Agent)↓传统检查 (lint, test, build)↓AI 增强检查 ← 新增├── AI Code Review: 语义层面检查(不只是格式)├── AI Security Scan: 检测 Agent 生成代码中的安全模式├── AI Impact Analysis: 预测这次变更对系统稳定性的影响└── AI Test Gap Analysis: 识别 Agent 遗漏的测试场景↓部署 (canary → full)↓AI 监控 ← 新增├── 异常行为检测(AI 生成代码的运行时表现是否符合预期)└── 自动回滚决策
(二)Agent 产出的可追溯性
当 Agent 参与代码生产后,DevOps 需要回答一个新问题:
这行代码是谁写的?人还是 Agent?用的哪个模型、哪个 prompt、什么上下文?
这不是为了追责,而是为了:
-
复现问题:当 Agent 生成的代码出 bug,需要知道当时的生成条件;
-
持续改进:统计哪类 prompt 产出质量高,优化协作流程;
-
合规审计:某些行业要求代码变更的完整审计链。
三、观测性(Observability)的升级
Agent 生成的代码可能采用人类不熟悉的实现方式,这意味着:
-
日志规范更重要:Agent 需要遵循统一日志格式,否则出了问题没法查;
-
链路追踪更关键:微服务调用链中,Agent 生成的服务和人写的服务混合,需要全链路可观测;
-
SLO/SLI 自动校准:Agent 高速产出代码后,系统行为可能快速变化,需要动态调整监控阈值。
04
岗位重塑:产品经理与工程师的边界模糊
一、正在发生的融合
传统分工泾渭分明:
-
产品经理:定义 What(做什么);
-
工程师:实现 How(怎么做)。
但 Agent 时代,这条线正在被擦掉:
产品经理在变得更“技术”:
-
可以用 Agent 快速搭建原型,验证想法,不再需要等排期;
-
需要理解 AI 能力边界(“这个功能 LLM 做得到吗?幻觉率多高?”);
-
直接写 prompt/spec,Agent 生成可运行的产品。
工程师在变得更“产品”:
-
不再只是“接需求”,需要理解业务场景来给 Agent 写出好的上下文;
-
代码生成变快后,瓶颈转移到“做什么”而非“怎么做”;
-
需要从用户视角审查 Agent 产出,而非仅从技术视角。
二、岗位可能的演化方向
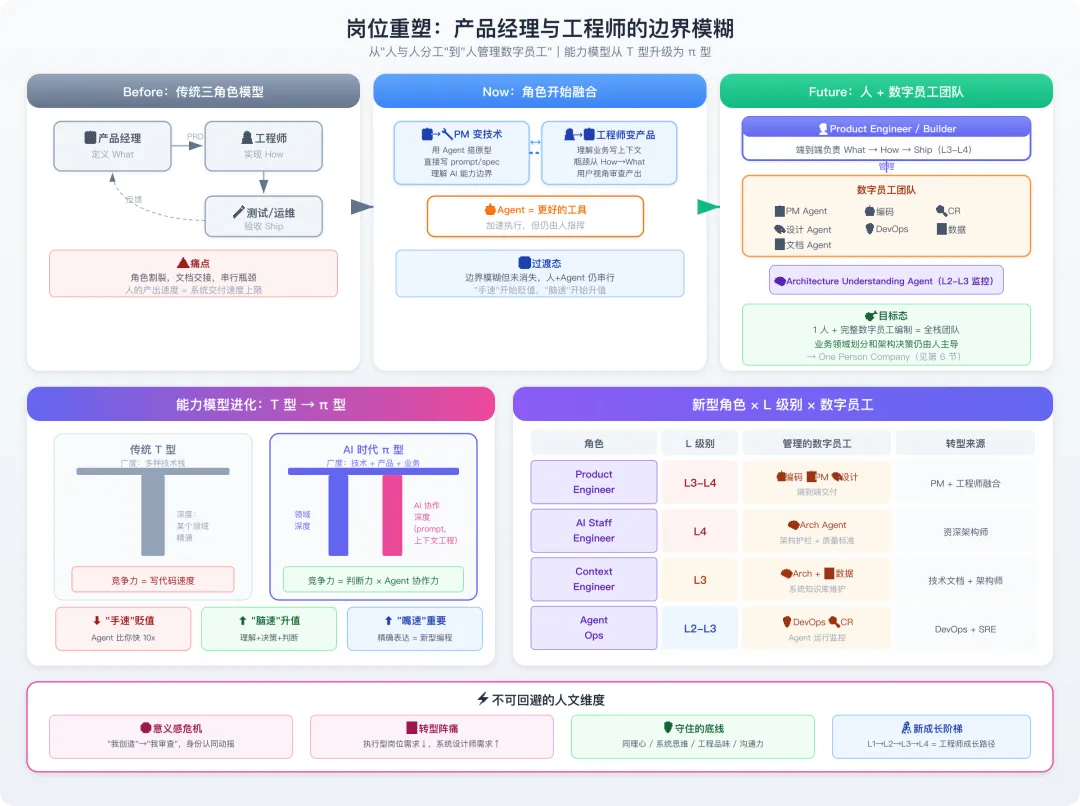
图4-1 岗位重塑:产品经理与工程师的边界模糊
(一)传统三角色模型
产品经理 ─── 需求文档 ───→ 工程师 ─── 代码 ───→ 测试/运维│ │└──── 验收/反馈 ────────────┘
每个角色各自独立,通过文档交接,瓶颈在人的产出速度和协调效率。
(二)新型角色模型:人 + 数字员工团队
传统的“人与人分工”正在变成“人与数字员工团队协作”。核心转变不是消灭岗位,而是每个人类角色都从“亲自执行”转向“管理一组数字员工”:
┌──────────────────────────────────────────────────────────────┐│ 产品工程师 / Builder ││ (端到端负责 What → How → Ship) ││ ││ ┌───────────┐ ┌───────────┐ ┌───────────┐ ││ │ 定义问题 │ │ 设计方案 │ │ 交付验证 │ ││ │ (What/L4) │ │ (How/L3) │ │ (Ship/L2) │ ││ └─────┬─────┘ └─────┬─────┘ └─────┬─────┘ ││ │ │ │ ││ ▼ ▼ ▼ ││ ┌─────────────── 数字员工团队 ──────────────────┐ ││ │ 📋 PM Agent 🤖 编码 Agent 🔍 CR Agent │ ││ │ 🎨 设计 Agent 🛡️ DevOps Agent 📊 数据 Agent│ ││ └────────────────────────────────────────────────┘ ││ ▲ ││ 🧠 Architecture Understanding Agent ││ (持续提供全局上下文,L2-L3 监控) │└──────────────────────────────────────────────────────────────┘
可能出现的新岗位/角色——不同于传统的“人做什么”,而是“人管理哪些数字员工、在哪个 L 级别工作”:
|
新角色 |
核心职责 |
工作的 L 级别 |
管理的数字员工 |
由谁转型而来 |
|
Product Engineer |
ineer 端到端负责从需求到交付,管理数字员工团队完成 L1-L2 执行 |
L3-L4:定义问题和方案 |
编码 Agent、PM Agent、设计 Agent |
PM + 工程师融合 |
|
AI Staff Engineer |
定义架构护栏和质量标准,设计 Agent 的工作规范(Architecture-as-Code) |
L4:架构决策 |
Architecture Understanding Agent |
资深架构师 |
|
Context Engineer |
构建和维护系统知识库,确保 Architecture Understanding Agent 有准确的架构理解 |
L3:系统全局理解 |
Architecture Understanding Agent、数据 Agent |
技术文档 + 架构师 |
|
Agent Ops |
管理数字员工的运行状态、监控产出质量、优化协作效率 |
L2-L3:运维和质量 |
DevOps Agent、CR Agent、全部 Agent 的运行监控 |
DevOps + SRE 转型 |
表2-2 两种Spec组织方案对比
与第 6 节 One Person Company 的关系:
在 Phase 2-3,这四个人类角色可能由 3-5 人分担;到 Phase 4(OPC),一个人可能同时承担 Product Engineer + AI Staff Engineer 的角色,Context Engineer 和 Agent Ops 的职能则大部分被成熟的 Agent 自动化。组织的演化路径是:多人各司其职 → 少数人 + 大量数字员工 → 一个人 + 完整数字员工编制。
三、能力模型的变化
(一)传统工程师的 T 型能力
广度:多种技术栈有了解─────────────────────────││ 深度:某个领域精通│
(二)AI 时代的 π 型能力
广度:技术 + 产品 + 业务都要懂─────────────────────────│ ││ 领域深度 │ AI 协作深度│ │ (prompt、上下文工程、│ │ Agent 行为理解)
关键变化:
-
“手速”贬值:写代码速度不再是竞争力,Agent 比你快 10x;
-
“脑速”升值:理解问题、做决策、判断质量的能力更稀缺;
-
“嘴速”重要:把需求精确表达给 Agent(本质上是一种新型编程)的能力。
四、不可回避的人文维度
赫拉利式追问:每次自动化革命都伴随认知去技能化(deskilling)和意义感危机。我们是否在无意中制造一代“审查员”而非“创造者”?
(一)工程师的意义感危机
从“我创造了这段代码”变成“我审查了 Agent 创造的代码”——这不仅是工作方式的变化,更是身份认同的动摇。
-
创造感 → 监督感:工程师的核心自豪感来自“我构建了这个系统”。当 70% 的代码是 Agent 写的,这种自豪感如何维系?
-
掌控感 → 焦虑感:“我真的理解这些代码吗?”——当 Agent 生成的代码规模超过人能理解的速度,技术主权感会丧失;
-
成长感 → 停滞感:初级工程师以前通过写 CRUD 建立代码直觉,现在这条路径被 Agent 截断了。
(二)应对方向
-
重新定义“创造”:创造不只是写代码,更是定义问题、设计系统、做出取舍。把“代码量”从成就指标中移除,替换为“系统影响力”;
-
刻意练习空间:为初级工程师保留“无 Agent 编程时间”——每周半天手写代码(类似医学生的手术实习),建立底层直觉;
-
新的成长阶梯:L1-L4 不仅是任务分类,也是工程师成长路径——从 L1(能指导 Agent)→ L2(能审查 Agent)→ L3(能设计 Agent 做不了的东西)→ L4(能做架构决策)。
(三)转型阵痛的诚实面对
角色融合的另一面是岗位削减。历史表明,每次“融合”都意味着一部分人被替代。应当诚实面对:
-
纯写代码的执行型工程师(只接需求 → 翻译成代码)的岗位需求会减少;
-
纯写 PRD 的产品经理(只产出需求文档但不理解技术实现)的岗位需求会减少;
-
但系统设计师、领域专家、Context Engineer 的需求会增长;
-
关键:组织应为转型提供安全网——培训资源、转型期缓冲、内部岗位调整机会。
五、哪些不会变?
尽管角色在融合,一些底层能力是永恒的:
-
用户同理心:理解用户的真实需求,Agent 不会替你做;
-
系统思维:一个改动对整体的影响,Agent 只看局部;
-
工程品味:什么是好的抽象、好的命名、好的接口设计,这是经验和审美;
-
沟通协作:跨团队协调、利益相关者管理,这是人的领域。
05
新的挑战与未解问题
一、代码所有权与知识产权
-
Agent 生成的代码,版权归谁?
-
如果 Agent 基于开源代码训练,生成了”类似”的代码片段,是否构成侵权?
-
企业的私有代码库喂给 Agent 后,如何防止知识泄露?
二、质量保障的范式转移
传统质量保障假设:人写的代码,人能理解。
Agent 时代:
-
Agent 可能生成“功能正确但风格诡异”的代码,人难以 Review;
-
测试覆盖率可能很高(Agent 擅长补测试),但测试的有效性谁来保证?
-
“所有测试都通过”不再等于“代码没问题”——需要新的质量指标。
三、技术债的新形态
传统技术债:人图省事留下的 TODO、硬编码、copy-pasteAI 技术债:Agent 生成的"看起来对但设计不优雅"的代码 × 10000 行
AI 技术债更隐蔽、更大规模。因为:
-
Agent 生成的代码通常能通过测试(功能正确);
-
但可能缺乏一致性、不符合团队约定、引入不必要的复杂度;
-
而且量太大,人来不及逐行审查。
用 L 分层的视角看:L1-L2 级别的技术债(命名不一致、格式不统一)可以靠 Architecture Understanding Agent 自动扫描;但 L3 级别的技术债(架构腐化、模块膨胀)需要人机协作才能治理。没有第 2 节描述的人机共治体系,AI 技术债就是一场慢性灾难。
四、团队文化的适应
-
初级工程师如何成长?以前通过写 CRUD 练手,现在 Agent 写了;
-
“10x 工程师”的定义变了——不是写代码快 10 倍,而是让 Agent 高效工作的能力;
-
如何避免“什么都让 Agent 写”导致的技能退化?
06
总结:未来产研模式全景图
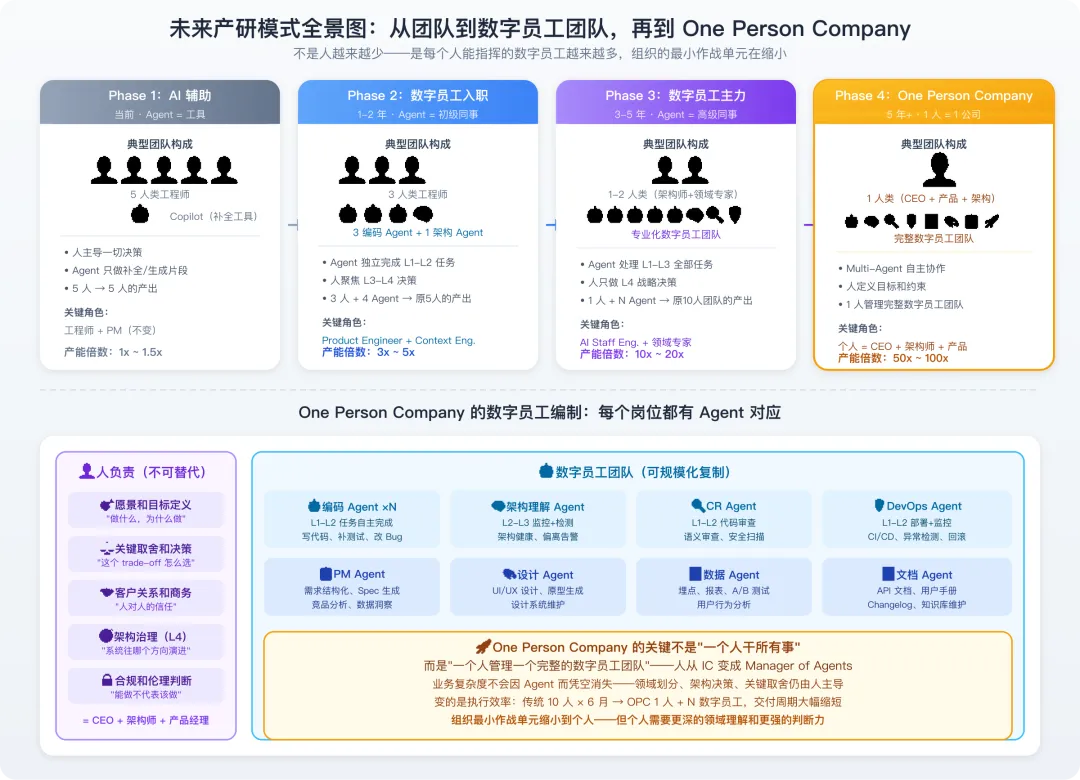
图6-1 未来产研模式全景图
一、产研模式演进路线图:四个阶段
核心趋势不是“Agent 越来越强”这么简单——而是组织的最小作战单元在持续缩小。
|
阶段 |
时间 |
Agent 定位 |
团队构成 |
产能倍数 |
|
Phase 1:AI 辅助 |
当前 |
工具(更好的 IDE 插件) |
5 人类 + Copilot |
1x ~ 1.5x |
|
Phase 2:数字员工入职 |
1-2 年 |
初级同事(L1-L2 自主) |
3 人类 + 3 编码 Agent + 1 架构 Agent |
3x ~ 5x |
|
Phase 3:数字员工主力 |
3-5 年 |
高级同事(L1-L3 自主) |
1-2 人类 + 专业化 Agent 团队 |
10x ~ 20x |
|
Phase 4:One Person Company |
5 年+ |
完整员工团队 |
1 人 + 完整数字员工编制 |
50x ~ 100x |
表6-1 产研模式 AI 演进四阶段
每个阶段的跳跃需要什么基础设施?
|
跳跃 |
关键前提 |
|
Phase 1 → 2 |
L 分层标准机器可判断 + 自动化验收能力(L1-L2 不依赖人验收) |
|
Phase 2 → 3 |
Architecture Understanding Agent 成熟 + Architecture-as-Code 全面覆盖 + Agent 能处理 L3 任务 |
|
Phase 3 → 4 |
Multi-Agent 协作协议标准化 + Agent 有持久记忆和长期学习能力 + 信任体系建立 |
表6-2 跨阶段跃迁的关键前提与技术基础设施要求
二、One Person Company:不是愿景,是正在发生的事
One Person Company 不是“一个人干所有事”,而是“一个人管理一个完整的数字员工团队”。
这个概念不是科幻——它正在从三个方向同时逼近现实:
① 技术维度:Agent 能力的快速进化
2024 年的 Agent 只能补全代码片段。2025 年的 Agent 已经能独立完成一个模块。按照当前速度,2027-2028 年的 Agent 完全有可能承担一个初级工程师的全部职责。
② 工具维度:数字员工的“岗位编制”正在形成
|
数字员工岗位 |
对应 L 级别 |
当前成熟度 |
预计独立可用 |
|
🤖 编码 Agent |
L1-L2 执行 |
⭐⭐⭐⭐ 已可用 |
2025 |
|
🔍 CR Agent |
L1-L2 审查 |
⭐⭐⭐ 基本可用 |
2025-2026 |
|
🧠 架构理解 Agent |
L2-L3 监控 |
⭐⭐ 概念验证 |
2026-2027 |
|
🛡️ DevOps Agent |
L1-L2 部署 |
⭐⭐⭐ 基本可用 |
2025-2026 |
|
📋 PM Agent |
L1-L2 需求 |
⭐⭐ 概念验证 |
2026-2027 |
|
🎨 设计 Agent |
L1-L2 UI |
⭐⭐⭐ 基本可用 |
2025-2026 |
|
📊 数据 Agent |
L1-L2 分析 |
⭐⭐⭐ 基本可用 |
2025-2026 |
|
📝 文档 Agent |
L1-L2 文档 |
⭐⭐⭐ 基本可用 |
2025-2026 |
表6-3 数字员工的“岗位编制”分级
当所有岗位都有 Agent 对应时,一个人就能“雇佣”一个完整团队。
③ 经济维度:组织边界的重新定义
传统创业:有想法 → 找 10 个人 → 融资 → 6 个月出 MVP → 验证市场瓶颈:招人的速度、团队磨合的时间、人力成本One Person Company:有想法 → 配置数字员工团队 → 6 周出 MVP → 验证市场 → 按需扩展瓶颈:人的判断力、领域知识、市场理解
这意味着:
-
创业门槛从“找到 10 个靠谱的人”降为“有一个靠谱的想法 + 知道怎么管理 Agent”;
-
边际成本从“每多一个功能需要多一个人月”降为“每多一个功能需要多一次 Agent 任务”;
-
组织形态从“公司是一群人的集合”变为“公司是一个人 + 一群数字员工的集合”。
类比:工业革命让一个人操控一台机器顶 100 个手工匠人。AI 革命让一个人管理一个数字团队顶一个 10 人产研团队。
区别在于:机器没有”理解力”,只能做重复劳动;数字员工有理解力,能做创造性工作。
三、One Person Company 模式下,什么变了,什么没变?
|
维度 |
变了 |
没变 |
|
谁写代码 |
数字员工(Agent)写 90%+ 的代码 |
代码仍然需要被理解、被审查、被维护 |
|
谁做决策 |
人做战略决策(L4),Agent 做战术决策(L1-L2) |
关键决策仍然需要人的判断力和领域知识 |
|
架构治理 |
Architecture Understanding Agent 持续监控 |
AI 越强,架构越重要——护栏不能少 |
|
质量保障 |
Agent 自动测试 + Agent 自动 Review |
质量标准仍然由人定义 |
|
团队规模 |
1 人 + N 数字员工 |
复杂系统仍然需要多个人类专家协作 |
|
用户同理心 |
Agent 可以分析数据 |
真正理解用户痛点仍然需要人 |
表6-4 不同维度下的变与不变
四、给不同角色的行动建议
如果你是工程师:
-
短期(1年):熟练使用 Agent 协作,理解 L1-L4 分级,成为“Agent 熟手”;
-
中期(3年):掌握 Architecture-as-Code,能设计 Agent 的工作规范和质量标准;
-
长期(5年):成为能管理数字员工团队的“AI Staff Engineer”,或探索 One Person Company 模式。
如果你是技术管理者:
-
短期:引入 L 分层标准,让团队开始区分“Agent 能做”和“人必须做”的任务;
-
中期:建设 Architecture Understanding Agent 基础设施,实现人机共治;
-
长期:重新设计组织结构——团队大小不再是产能的决定因素。
如果你是创业者:
-
关注 One Person Company 赛道——这是一个全新的创业范式;
-
核心竞争力不再是“能招到多少人”,而是“对领域的理解有多深”;
-
第一批 One Person Company 的成功案例会出现在垂直 SaaS 领域——因为领域知识壁垒最高。
五、三个不可逆的趋势
回到全文的核心:
-
从“人用工具”到“人管理数字员工”——Agent 不是更好的 IDE,是有职责、有权限、能成长的团队成员;
-
AI 越强,架构越重要——数字员工产出速度 10x-100x,没有护栏就是灾难级技术债;
-
组织的最小作战单元在缩小—— 从“部门”到“小组”到“个人 + 数字员工团队”,One Person Company 是终局形态之一。
六、三个需要守住的东西
无论到哪个阶段,人类不可让渡的核心:
-
架构思维和系统设计——数字员工擅长局部优化,全局设计仍然需要人;
-
领域知识和判断力——“做什么”永远比“怎么做”更难、更稀缺;
-
对人的理解——用户同理心、商业直觉、伦理判断,这些是 Agent 做不到的。
最后一个思考:One Person Company 的极致不是“一个人替代了一个团队”,而是释放了个人的创造力上限。以前一个有好想法的人,受限于“找不到团队”而放弃;未来,唯一的瓶颈是你自己的想象力和判断力。
软件工程没有消失——它从“一群人的纪律”变成了“一个人管理数字团队的方法论”。

推荐阅读
-
Software Engineering at Google — 传统 SE 的巅峰总结
-
The Pragmatic Programmer (20th Anniversary) — 永恒的工程智慧
-
An Introduction to Software Architecture — 架构治理的基础
-
Andrej Karpathy: “Software 2.0” — 用神经网络取代手写规则的愿景
-
Anthropic: Building effective agents — Agent 设计模式
-
Sam Altman: “The Intelligence Age” — AI 时代的经济和组织变革
-
[a]16z: “The One-Person Billion-Dollar Company” — 数字员工驱动的新型组织形态



「腾讯广告技术专题精选」
AI Native研发实践:Spec驱动+AI链路闭环实现智投广告前端
AAAI 2026|多智能体VLMs引导的低资源违规内容检测自训练框架
EMNLP2025|RAVEN++:通过主动强化推理精确定位广告视频中的细粒度违规内容
更多精彩可点击👉「广告硬核技术」👈查看合集