 夜雨聆风
夜雨聆风





AI 原生软件入门:从文字聊天,到看图、听音、读文件

很多人第一次用 AI,是从聊天框开始的。打开页面,输入一句问题,等它回一段文字。这当然有用,但也容易让人误会:好像 AI 只是一个更会聊天的搜索框。
真正的变化已经发生在输入框旁边那个小小的“+”号里。它能上传图片、录音、PDF、Word、Excel、PPT,有些产品还能处理视频。你不必把所有材料先打成文字,再交给 AI。很多时候,原始材料本身,就是更好的提问。
先说结论:
• 多模态这个词听着硬,其实就是让 AI 同时处理不同材料。
• 现在的 AI 原生软件,已经从“回文字”走向“读材料、看现场、听内容”。
• 普通人入门 AI,关键不在背多少提示词,而在学会把真实材料交给它。
• AI 能整理和解释,但重要结论仍要由人核对。
1. 旧入口太窄了
只用文字聊天,像是让一个同事隔着门缝工作。你告诉他“帮我看下这份报价有没有问题”,但报价单在你桌上;你说“这个会议重点是什么”,但录音还躺在手机里;你问“这张图能不能做成海报文案”,但图片没有发过去。
这时 AI 只能猜。猜得再像,也不如直接看材料。过去我们常把图片内容、录音内容、PDF 内容先转述一遍,再让 AI 处理。麻烦不说,信息也容易漏。
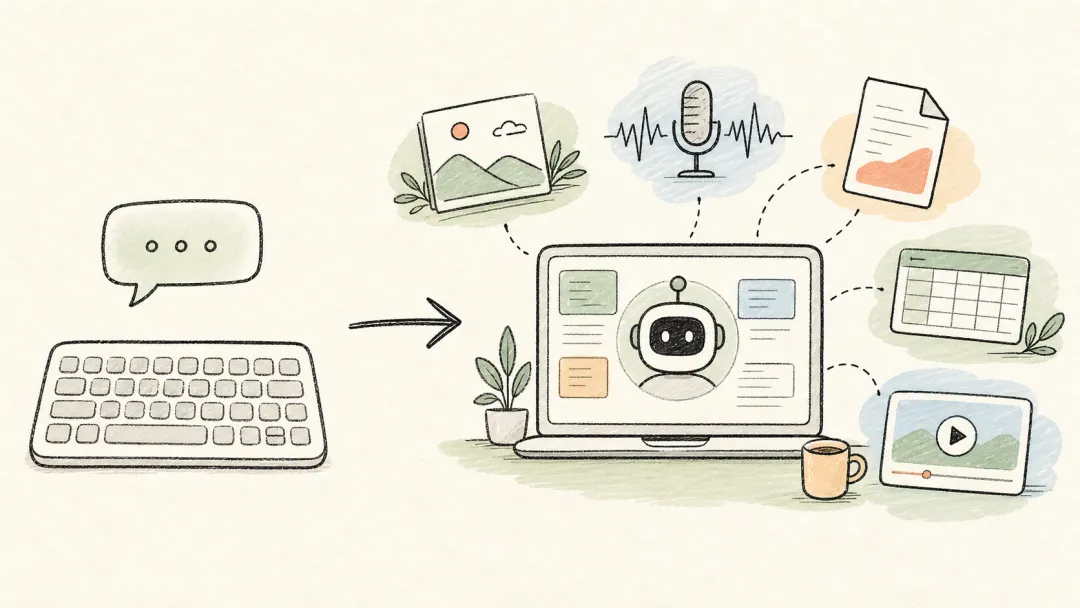
从单一聊天框,到把图片、声音、文件一起放进工作台。
一句话理解: 多模态的价值很实在:你少花时间转述材料,AI 多接触一点事实。
2. 多模态其实很日常
“模态”可以理解成材料的形态。文字是一种,图片是一种,声音、视频、PDF、表格、演示文稿也都是。多模态,就是 AI 不只读文字,还能把这些材料放在一起理解。
一个生活化的比喻:过去的 AI 像电话里的客服,只能听你描述;现在的 AI 更像坐在桌边的助手,可以看你递过去的照片、听一段录音、翻一份文件,再把它整理成你能读懂的答案。
截至 2026 年 5 月 28 日,从国内厂商公开资料看,这个方向已经落到产品入口里。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这些名字背后的技术路线不同,产品入口也不同。对普通使用者来说,先不用急着分清每个模型的参数和榜单。更实在的判断是:这个 AI 能不能直接吃下你手里的材料。
3. 普通人先从材料开始
多模态最容易理解的入口,是“我手上已经有什么”。把原本就要处理的材料,换一种方式交给它。
比如,一张电器说明书照片,可以让 AI 找到安装步骤和注意事项;一段会议录音,可以先整理成纪要,再让人补充遗漏;一份 PDF 研报,可以抽出核心观点和风险点;一个 Excel 表格,可以让 AI 先看异常数据,再由人确认口径。

小票、作业照片、录音、表格和演示文稿,都可以成为 AI 的输入材料。
这里有个很小的使用习惯:问 AI 之前,先停两秒,看桌面和手机里有没有更接近事实的材料。能上传原图,就别只描述“这张图大概是什么”;能上传文件,就别只复制一小段;能上传录音,就别凭记忆复述会议。
更稳的提问方式: “请根据这份文件/这张图/这段录音回答”,通常比“我给你描述一下情况”更接近真实。
4. 能看懂,不等于全可信
AI 能看图、听音、读文件之后,错误不会消失,只是换了形态。图片里字太小,它可能识别错;录音里多人同时说话,它可能漏掉发言人;PDF 排版复杂,它可能把图注和正文混在一起;表格口径不清,它可能算出一个看似漂亮但并不该用的数字。
所以,多模态 AI 更像一个资料整理员,不是终审。它可以先把一堆材料铺平、归类、提炼,再把人从第一轮重复劳动里解放出来。到了判断阶段,尤其是合同、财务、医疗、合规、公司决策,人还是要回到原始材料。
还有隐私。把家庭证件、客户合同、公司财务表直接上传到公共 AI 产品前,先看产品条款、企业规范和数据权限。很多问题的关键不在 AI 会不会,在材料能不能给它看。
5. 这节课建立一个习惯
从这一节开始,AI 入门不再只练“怎么写提示词”。更重要的是换一个问题:我现在给 AI 的,是不是最接近事实的材料?
手里有图片,就让它看图;有录音,就让它先听;有 PDF,就让它读原文;有表格,就让它看结构;有演示稿,就让它按页理解。AI 原生软件的入口,已经从“输入一句话”变成“交给它一组材料”。

AI 负责整理材料,人负责核对事实和作出判断。
这也是“多模态”真正重要的地方。它增加的不只是几个按钮:AI 从文字回复者,变成能接触真实材料的工作伙伴。学会这一点,后面再谈智能体、工作流、自动化,才不会漂在概念上。
资料来源与阅读入口
阿里云百炼《全模态》:https://help.aliyun.com/zh/model-studio/omni/
火山方舟《多模态理解》:https://www.volcengine.com/docs/82379/1958521
百度智能云《BML 全功能AI开发平台》:https://cloud.baidu.com/doc/BML/s/hkww6ksyw
Kimi 帮助中心《Kimi 概述》:https://www.kimi.com/zh-cn/help/new-user-guide/overview
智谱 AI 开放文档《GLM-4.5V》:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-4.5v
腾讯云《腾讯混元大模型产品概述》《大模型音视频理解接入》:https://cloud.tencent.com/document/product/1729/104753