 夜雨聆风
夜雨聆风





OpenClaw 这次修的不是小 bug,而是 Agent 系统的稳定性底座
一条普通消息发不出去,问题不一定在微信
今天这次 OpenClaw 更新,我最在意的不是版本号,而是一处很具体的小修复。
用户只是想发一条普通消息,但请求里如果带着 pollDurationHours、pollMulti 这类 schema padding 字段,旧逻辑可能会把它误判成投票消息,然后普通 send 被拦住。
这类问题很不起眼,真用起来却很烦。因为用户看到的是:我明明只是让它回我一句话,为什么发不出去?
我的判断是:这不是微信通道的小毛病,而是 Agent 多工具系统里非常典型的意图识别问题。
Agent 世界不是一个干净的 API 世界。插件、适配器、历史字段、不同渠道的 schema,经常会在同一条调用链里碰到一起。字段多一点、旧一点、宽一点,都可能让系统跑进错误分支。
老板真正担心的也不是字段名本身,而是:这个系统到底能不能稳定接活?出了问题,是不是只能靠人猜?
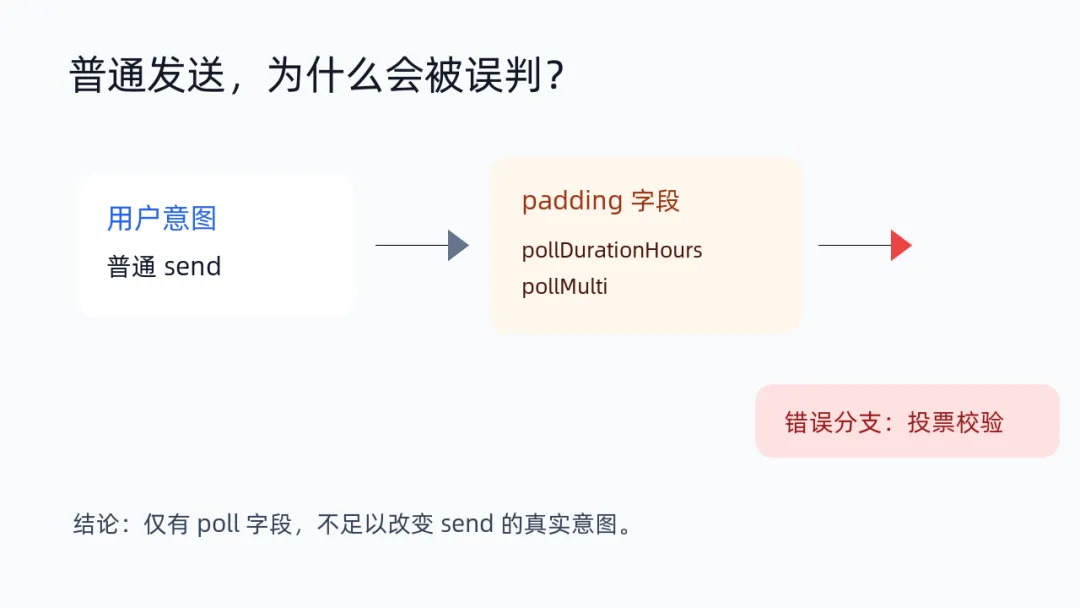
只看字段存在,不够
普通 send 里出现 poll 字段,不代表用户真的要发投票。
这个判断听起来简单,但在多渠道系统里很容易被写错。因为工程上最方便的写法经常是:看到某个字段,就走某个分支。
问题是,Agent 工具调用里会有很多 padding、兼容字段和上游残留字段。它们可能只是 schema 宽容的一部分,不一定表达真实意图。
所以我现在更倾向于把消息发送判断拆成两层:第一层看显式动作,第二层看结构是否完整。只有动作和结构都指向投票,才进入投票分支。
可以先用这个小规则:
message_type === "poll" 或明确投票 action 存在,才允许投票校验;仅有 pollDurationHours、pollMulti 这类字段,不足以改变普通发送意图
这就是 schema 宽容度。它不是为了纵容脏数据,而是为了避免兼容字段把用户意图带偏。
坏掉的 shell 状态,不应该继续被相信
同一批更新里,还有一个信号也值得看:exec 腐坏 shell snapshot 拒绝。
Agent 执行任务,经常依赖 shell 会话状态:当前目录、环境变量、上一次输出、进程是否还活着。如果 snapshot 已经坏了,但系统还继续把它当成可信上下文,后面所有判断都会被污染。
我踩过类似的坑:任务看起来还在继续,实际上目录不对、会话状态不对,Agent 还在一本正经地分析错误现场。
这比失败更危险。
失败至少明确;坏状态会让系统装作自己还有上下文。
所以拒绝腐坏 snapshot,本质是在给执行链路加一道硬边界:不可信,就不要继续。该重建会话就重建,该上报异常就上报异常,不要让错误状态继续扩散。

延迟要变成指标,而不是体感
gateway RPC RTT 探针,是另一类很实用的修复。
用户问“是不是断了”,背后可能有很多原因:模型还在跑,工具没返回,gateway 转发慢,节点连接抖动,消息投递失败,前端状态没刷新。
如果没有 RTT,排障只能靠体感。感觉慢、感觉卡、感觉没回。
有了 gateway RPC RTT,至少可以先判断:是网关往返慢,还是下游任务慢,还是投递链路慢。
对 OpenClaw 这种多 Agent、多节点、多渠道系统来说,这不是锦上添花。链路越长,越需要可观测性。
没有探针,系统只能解释结果;有了探针,系统才开始解释过程。
Workboard 收紧,说明操作边界也在变成熟
Workboard 卡片操作收紧,看上去是 UI 细节,其实是协作边界。
在 Agent 工作流里,一张卡片可能代表任务状态、上下文入口、继续执行、人工确认和结果回看。它不是普通按钮。
如果任何状态下都能随便点,系统看似更自由,实际更容易把正在执行的任务打乱。
所以卡片操作收紧,我反而认为是好事。控制台不应该追求所有按钮都能点,而应该让关键动作更明确:什么时候可以继续,什么时候必须确认,什么时候应该禁止操作。
这个地方我不会先追求自动化程度,而会先追求边界清楚。Agent 不是越放手越好,真正稳定的 Agent 必须知道哪些地方该停下来等人。
我会用这四项清单排障
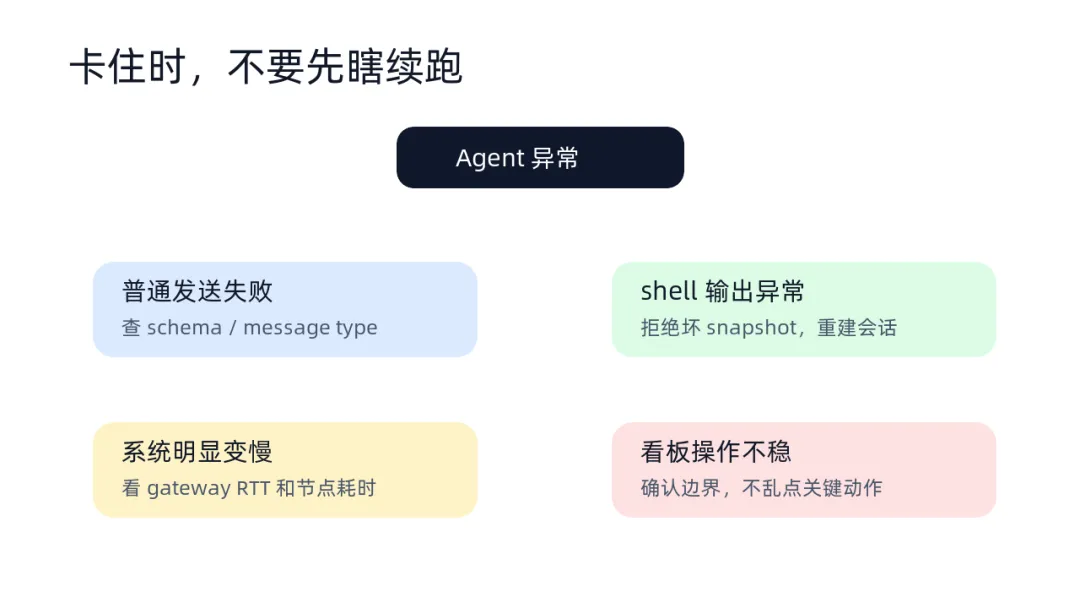
后面如果再遇到类似问题,我不会第一时间只问“模型是不是卡住了”。我会按四层排:
第一,看意图字段。普通发送失败时,先检查是否有 padding 字段把 send 误导成了 poll、file、button 或其他特殊消息。
第二,看执行状态。shell 输出对不上、目录不对、任务像是在旧上下文里跑时,优先怀疑 snapshot 或会话状态,而不是继续续跑。
第三,看链路延迟。系统没断但变慢时,先看 gateway RPC RTT,再看下游节点和模型运行时间。
第四,看操作边界。Workboard、预览、保存、发布这类动作不稳时,先判断是不是新规则正确拦住了模糊操作。
这套清单不复杂,但能减少很多无效猜测。

真正可靠的 Agent,先学会不乱继续
这批更新放在一起看,其实是在补三件底层能力:意图更宽容,状态更谨慎,链路更透明。
反直觉的是,Agent 系统成熟的标志,不一定是它能做更多事,而是它在不确定时能少做一点。
字段不够,不乱判。
状态坏了,不硬跑。
链路慢了,不瞎猜。
操作不明确,不乱点。
这听起来没有“全自动 Agent”那么刺激,但日常使用里,这些能力更值钱。
因为真正能长期工作的 Agent,不是每次都显得聪明,而是在出问题时,能准确知道自己哪里不该继续、哪里需要重试、哪里应该把真相告诉用户。
给团队的一张小模板
如果团队正在把 Agent 接进内部工具、消息系统或项目执行链路,可以把下面这张表贴到排障文档里:
1. 这次失败的用户意图是什么?有没有字段把它带进错误分支?
2. 当前执行状态可信么?shell、目录、进程、snapshot 有没有证据?
3. 慢在哪里?gateway RTT、节点耗时、模型耗时、投递耗时分别是多少?
4. 当前动作是否需要人工确认?保存、预览、发送、发布有没有真实回读证据?
5. 如果继续执行,最坏会造成什么错误?能不能先停下、截图、记录、再恢复?
这篇文章不想把一个版本更新包装成大新闻。我的判断更朴素:这些小修复,正是 Agent 系统从“能演示”走向“能日常用”的必经之路。