 夜雨聆风
夜雨聆风





文档解析也需要一个世界模型
系统看见了什么?系统认为世界现在是什么状态?系统下一步能做什么?


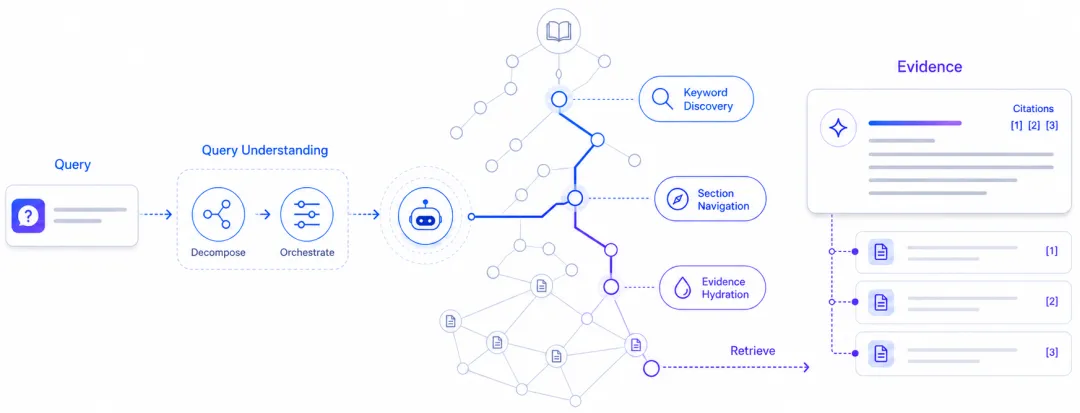
document -> chunk -> embedding/search -> top-k context -> answer这是一条清晰明确的链路。查 FAQ、问定义、找某段说明,它经常就是最简单、最便宜、最可靠的做法。我不想把传统 RAG 写成已经过时的东西。它的问题不是没用,而是它经常把“文档工作”简化成“文本召回”。 当 Agent 做的是一次问答,这个简化可以接受。当 Agent 做的是一个长任务,它就会出问题。 一个有点奇怪的现象是,Agent 读得越多,有时反而越不像一个真正的同事。它能引用正确的段落,却不知道该改哪一版文档。它能总结所有批注,却不知道哪些批注已经处理过。它能把一份报告里的数字搬进另一份 memo,却不知道这个数字来自哪张表、是否已经更新、会不会让后面的结论失效。它能生成一段很流畅的文字,却不知道这段文字破坏了哪个引用、哪个前提、哪个还没定下来的决定。 这不是模型不会读。很多时候,它读到了。问题在于它没有一个工作现场。 这些失败不是单纯的 recall 问题。召回可能已经成功了。失败发生在更深一层:Agent 拿到的是 observation,不是 state。Observation 是它眼前看到的几段材料。State 是这些材料在工作世界里的位置、关系、版本和可操作性。这两个东西不能混为一谈。 RAG 最初给人的感觉像是给模型装上了记忆。后来我们慢慢发现,它更像是给一个没有办公桌的人递资料。资料本身可能是对的,但桌上有哪些文件、哪份是最新版、哪些地方正在被别人修改、哪些批注还没处理、哪些结论依赖哪些来源,这些它仍然不知道。 过去一年,很多人默认 Agent 的问题是 context 不够。这个判断有一部分是对的。上下文太短,模型确实看不到足够材料。但在知识工作里,更大的问题已经不是“模型能不能多看几页”。真正的问题是:它有没有一个可以行动其上的外部世界? Context 是你临时塞给模型的东西。State 是任务、文档、证据、版本、引用和未完成决定本身的当前状态。Context 会被截断、压缩、遗忘。State 应该持续存在,并且能被多次行动共同读取和更新。 这就是我想用“文档世界状态”这个说法的原因。它不是要给 RAG 换个包装,也不是说 Knowhere 是物理世界模型。它只是想抓住一个具体问题:知识工作的 Agent 不只需要外部知识,它需要一个外部现实。对很多企业场景来说,这个现实就是文档、版本、引用、表格、图片、批注、来源、权限和它们之间的关系。文档不是附件。文档是 Agent 要进入的工作现场。 一个能工作的文档状态 应该包含什么 如果说文档是工作现场,系统至少要知道:桌上有哪些材料,哪份是最新版,哪些地方被批注过,哪些结论依赖哪些证据。把“文档状态”落到工程对象上,它并不神秘。一个可行动的文档世界,至少应该有这些对象:

Document-> Section-> Chunk-> Asset(table/image/page/slide)-> Metadata-> Source path-> Graph link-> Retrieval traceDocument 让系统知道证据属于哪份材料,而不是一段孤立文本。Section 保留章节层级和语义范围。Chunk 是最小可检索内容,但它不能只保存 content,还要保存位置、路径、类型和来源。Asset 让表格、图片、页面和 PPT 图示不从链路里消失。Metadata 保存页码、文件名、关键词、摘要和 chunk type。Graph link 表达跨章节、跨文档、跨资产的基础关系。Retrieval trace 让一次回答可以回看证据路径。 这些对象的意义不在于数据库设计更漂亮,而在于 Agent 的动作空间变了。如果系统只返回 top-k,Agent 能做的动作很少:读这些片段,然后回答。它想继续查,只能再发一个 query。新的 query 又会返回一批新的片段,和上一批片段之间未必有稳定关系。 如果系统维护了文档状态,Agent 可以做更细的动作: search(query)open_document(document_id)expand_section(section_path)inspect_asset(asset_id)compare_chunks(chunk_a, chunk_b)follow_edge(edge_id)cite(source_path)revise_query(reason)这些动作看起来普通,但它们改变了 Agent 的工作方式。它不再只是在 prompt 里读材料,而是在一个文档空间里移动。这也是 flat chunk 的根本问题。flat chunk 最大的损失不是切分边界不完美,而是它把文档从一个有结构的对象压成了一堆互相孤立的片段。你可以在这些片段上做更好的排序,但排序再好,Agent 拿到的仍然是一堆纸条,不是一个可以继续探索的文档空间。 Tree-like Chunking 的意义就在这里。它改的不是 chunk size,而是检索对象的形态。一个 chunk 不再只是 content,而是文档树里的节点。它知道自己属于哪份文档、哪一章、哪一节,是否关联表格或图片,来源页码在哪里,和其他节点有什么关系。这比“优化 RAG”听起来更基础。因为它不是在问怎么把片段排得更准,而是在问:Agent 消费的对象到底是什么? Knowhere 在 Noire 里补充了什么? 如果 Noire 要让 Agent 真正处理复杂文档,它不能只把 PDF、PPT、表格和截图解析成文本,再把文本塞给模型。它需要一个文档状态层,Knowhere 承担的就是这件事。 它当前的链路可以写成: dirty documents-> parse-> hierarchy / sections-> chunks / assets / metadata-> graph-> agentic retrieval-> cited evidence关键不在“把 PDF 转成文本”。Parser 到 Markdown 只是入口。真正定义 Knowhere 的,是 parser 之后的那套结构化产物:文档树、section path、chunk metadata、table/image link、轻量 graph、retrieval table,以及 Agent 可以调用的检索和导航接口。 落到工程上,这条链路是有结构的,但不需要把它理解成一个复杂产品流程。它其实是在做一件事:把一次性的文件处理,变成持久的文档状态发布。 API 创建任务,worker 解析文件,parser 把不同格式转成统一中间结果,chunk converter 把结果归一化,publication step 把 Document、DocumentSection、DocumentChunk 和 graph node / edge 写进系统。后面的 retrieval 才不是在一堆临时文本里找答案,而是在这些状态对象里找证据。这些持久化对象划出了 Knowhere 和 parser 的边界。Parser 输出的是原材料。Knowhere 发布的是 Agent 可以长期访问的文档状态。 也要把 Knowhere 和完整的 Agent 执行框架分开。模型、planner、sandbox、权限系统、任务队列和完整执行循环,属于 Noire 的其他层。Knowhere 补的是记忆、检索和上下文这一层:让复杂文档以可被执行框架管理的形态进入系统。 把不同层放在一起看会更清楚: Model: 负责语言推理和生成Harness: 负责工具、状态、约束、执行边界Knowhere: 把复杂文档建成可被 Harness 调用的记忆状态Retrieval infra: 负责索引、召回、排序、存储性能这几层可以同时存在。Milvus、BM25、GraphRAG、Knowhere 并不互相替代。向量库解决高性能相似搜索,BM25 解决词面匹配,GraphRAG 解决实体关系和图推理。Knowhere 更靠前,处理的是文档进入这些系统之前,有没有保留结构、路径、资产和来源。 真正的检索,是在文档里移动 普通 retrieval 是: query -> top-k snippets -> answer真正的 agentic retrieval 更接近: query-> find candidate documents-> inspect section paths-> expand relevant region-> inspect linked assets-> compare evidence across documents-> cite source-backed answer把流程铺开不是为了显得复杂。真实任务本来就不是一次 top-k 能解决。企业 Agent 查合同、财报、产品文档、研究报告时,定位、对齐、确认和复查,往往比“有没有一段文本看起来相关”更难。没有状态层,主动检索很容易变成多轮 top-k。看起来更主动,实际上只是多问了几次。 状态层存在之后,Agent 的每一步才有明确对象:展开哪个 section,打开哪个 asset,比较哪两个 chunk,沿哪条 graph link 走,引用哪个 source path。这也是 world model 视角对 Knowhere 有用的地方。它把问题从“怎么召回更多相关文本”往前推了一层:系统有没有维护一个 Agent 可以行动的外部状态? 评估 Agent,不能只看有没有召回 把 Knowhere 放在文档世界状态层,它的评估就不该只看传统 RAG 指标。Recall@k 仍然重要,但它只回答“相关证据有没有被召回”。如果 Agent 要在复杂材料空间里稳定工作,还要看别的东西: 答案能不能回到原始文档、章节、页码和资产;Agent 拿到一个结果后能不能继续展开上下文;返回证据有没有包含必要前提、例外和表格关系;多轮任务中同一文档对象、指标和实体是否保持一致;多份材料冲突时,系统是否暴露冲突,而不是把冲突抹平。 这些指标没有“答案是否好看”那么直观,却更接近生产系统。它们关心的不是模型一次回答得像不像,而是 Agent 能不能在一个复杂材料空间里稳定工作。 这也指向 Knowhere 后续要补的东西。当前 Knowhere 已经打好的部分,是文档树、chunk metadata、asset linkage 和轻量 graph。它们能支撑导航、引用和基础 expansion。下一步要往深走,是细粒度语义关系:相似、冲突、支持、同实体、同指标、同事件、同实验条件、同财务口径。 这些关系不是 keyword overlap 能稳定做好的。它需要实体抽取、指标归一、时间线对齐、证据类型识别和冲突判定。等这些关系稳定写进 graph 之后,Knowhere 才会从“文档可导航”继续走向“证据可比较、可验证、可追踪”。 要确定明确的文档边界 “文档世界模型”这个说法有用,但它也很容易被说大。一旦把它说成万能概念,它就会失去精度。Knowhere 不是 physical AI 里的 world model。它不学习空间、几何、力学、接触、材料,也不输出机器人动作。它处理的是文档域内的状态表示。这一点要说清楚,否则文章会变成概念借壳。 传统 RAG 也没有失效。FAQ、短问答、低风险资料检索里,flat retrieval 仍然够用。问题出现在更长、更杂、更需要证据复查的任务里。这里的判断不是“RAG 不行了”,而是“只有 top-k observation 不够支撑复杂工作”。上下文窗口仍然重要,但它不是状态管理。更大的窗口让模型一次看见更多材料,却没法自动恢复文档层级、资产关系、版本差异和引用路径。 GraphRAG 也不是单独解法。Graph 很重要,但图的质量取决于前面的文档解析、资产保留、实体归一、证据关系抽取和版本管理。没有好的 ingestion,图只是把损坏的信息换一种结构保存。Knowhere 也不保证推理正确。它改善的是 Agent 可访问的文档状态。最终判断仍然取决于检索策略、任务目标、模型能力、验证步骤和上层 Harness 怎么处理证据。边界保住之后,“文档世界状态”这个说法才有意义。它把 Knowhere 放回一个具体问题:Agent 在复杂文档里行动时,系统给了它什么状态对象和什么可执行动作。 最后,回到 Agent Agent = Model + Harness 这个框架仍然有用。模型负责推理和生成,Harness 负责工具、上下文策略、执行边界和反馈循环。但当 Agent 进入更长的任务和更复杂的材料环境时,Harness 里必须明确分出一层:World State。 Physical AI 需要物理 world state:场景、对象、动作后果的可计算表征。Knowledge-work AI 需要文档 world state:文档、章节、chunk、资产、来源、关系的可导航表征。两边的具体形态不同,但缺了这一层,Agent 就只能在 observation 上做反应式工作,很难做长周期推理、回溯、比较和复查。 Knowhere 在 Noire 里的位置就在这里。它不替代模型,不替代 Harness 的其他部分,也不替代检索基础设施。它补的是知识工作场景里的文档世界状态层:让文档不再只是 prompt 里的一段附件,而是 Agent 可以反复回到、反复导航、反复引用的可操作状态。模型会继续变强,材料会继续变杂。但真正能进入知识工作的 Agent,缺的不是更多上下文,而是一个可以行动的知识状态。 Reference:
-
Fei-Fei Li / World Labs, A Functional Taxonomy of World Models -
NVIDIA Technical Blog, Develop Physical AI Reasoning, World, and Action Models with NVIDIA Cosmos 3 -
Google DeepMind, Genie 3: A new frontier for world models -
World Labs, RTFM: A Real-Time Frame Model
Meta Structure 团队是专注知识治理和 AI 智能体赛道的创新者,依托自身长期积累的技术实力,致力于打造真正可落地的企业及个人 AI 解决方案,帮助各类组织及个人实现知识智能化管理与高效决策支持。
核心研发团队由人工智能、自然语言处理、语义挖掘等领域资深专家组成,成员主要来自中国科学院、清华大学、北京大学等顶尖科研机构与海内外重点高校,同时汇聚了出身于腾讯、华为等一线科技公司的算法专家与工程师实践者。
我们的核心能力是深度融合自研 RAG 技术与大模型推理能力,实现多模态数据治理、自动化建库、知识结构化解析关联、专业个性化多模态内容检索生成等功能,算法效率行业领先。
我们相信,大模型的未来,不只是“通用智能”,而是真正懂你知识、守你数据、助你解决问题的私有智能体。无论是企业应用,还是个人助手,这都是我们正在全力奔赴的方向。
