 夜雨聆风
夜雨聆风





AI CAE 工具实践 02|Abaqus-MCP 项目拆解:AI 如何进入 CAE ?
AI CAE 工具实践/第 02 期
Abaqus-MCP 的价值不在于“AI 自动会做仿真”,而在于它把 Abaqus/CAE 会话变成了一个可观察、可调用、也必须被约束的工程接口。
上一期讲 MCP 时落到一个判断:AI 真正缺的,是一条能接触工程工具的受控通路。
放到 Abaqus/CAE 上,这条通路缺在哪里就很具体了——AI 写得出脚本草稿,却看不到当前的模型树、材料、Step、Job 和 ODB 状态。本期想拆解的,就是 Abaqus-MCP 如何补上这一段。
需要先说清楚的是本文的边界:这不是安装实录,也不把项目能力包装成已经完整验证过的结论,重点是基于公开 README、release 信息和相关项目资料,梳理它把 AI 接入 Abaqus/CAE 的设计思路与调用链路。
●1. Abaqus-MCP 解决的不是自动化,而是上下文断点
Abaqus 并不缺自动化能力。Abaqus Python 可以创建模型、定义材料、设置 Step、提交 Job、读取 ODB。真正的问题是:这些能力默认不在 AI 客户端的上下文里。
过去的流程是“AI 写脚本,人复制运行,再把日志贴回来”。上下文、执行过程和结果证据都在人工搬运中断开。更理想的流程是:AI 先读当前模型信息,生成脚本草稿,工程师确认后再执行,并把日志、截图、结果摘要回传给人复核。
Cai-aa/abaqus-mcp 切入的正是这个断点,它通过 file-based IPC,让外部 MCP 客户端可以与正在运行的 Abaqus/CAE 会话交换信息。可以这样理解:
●它不是 Abaqus 的替代品。 真正建模、求解和后处理的后端仍然是 Abaqus/CAE。
●它不是完整仿真平台。 它不负责替工程师定义工况、判断安全系数或签核结果。
●它是桥接层。 一边连接 MCP 客户端,一边连接 Abaqus/CAE 会话。
●它暴露有限动作。 外部 AI 客户端可以触发查询、脚本执行、Job 管理、ODB 检查和截图回传等能力。
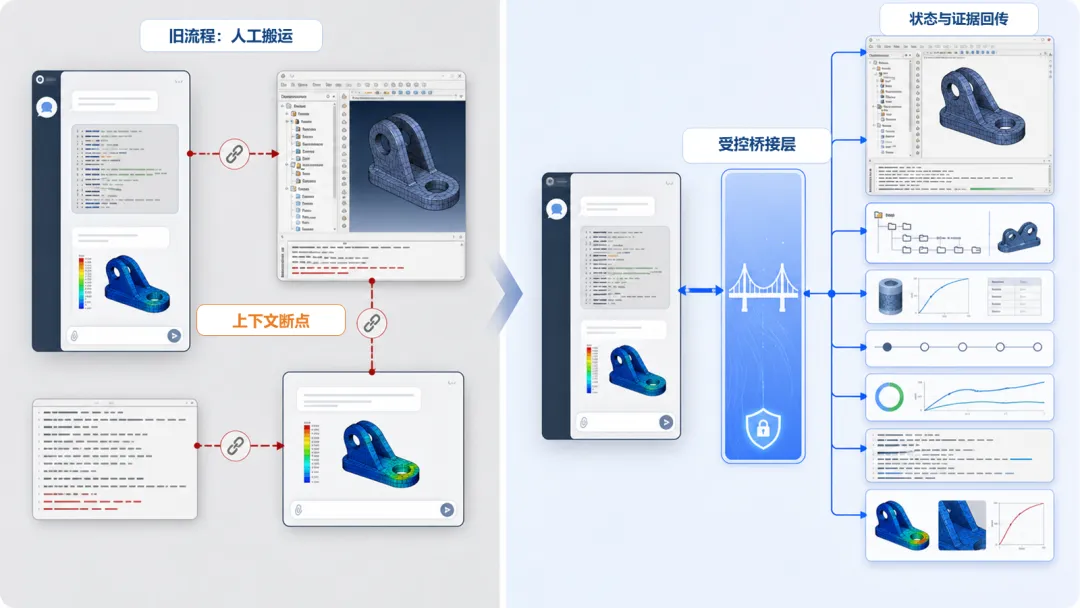
图 1|从上下文断点到受控桥接层。 Abaqus-MCP 的价值不是替代工程师做判断,而是让模型状态、日志、截图和结果证据可以从 Abaqus/CAE 会话回到 AI 客户端与人工复核流程中。
对工程师来说,关键不是“AI 接管 Abaqus”,而是“工程软件会话可以把状态和证据回传给 AI”。
●2. 从调用链路到工具能力
把这条链路拆开来看,大致是:
MCP Client -> mcp_server.py -> file-based IPC -> Abaqus/CAE plugin -> Abaqus 会话
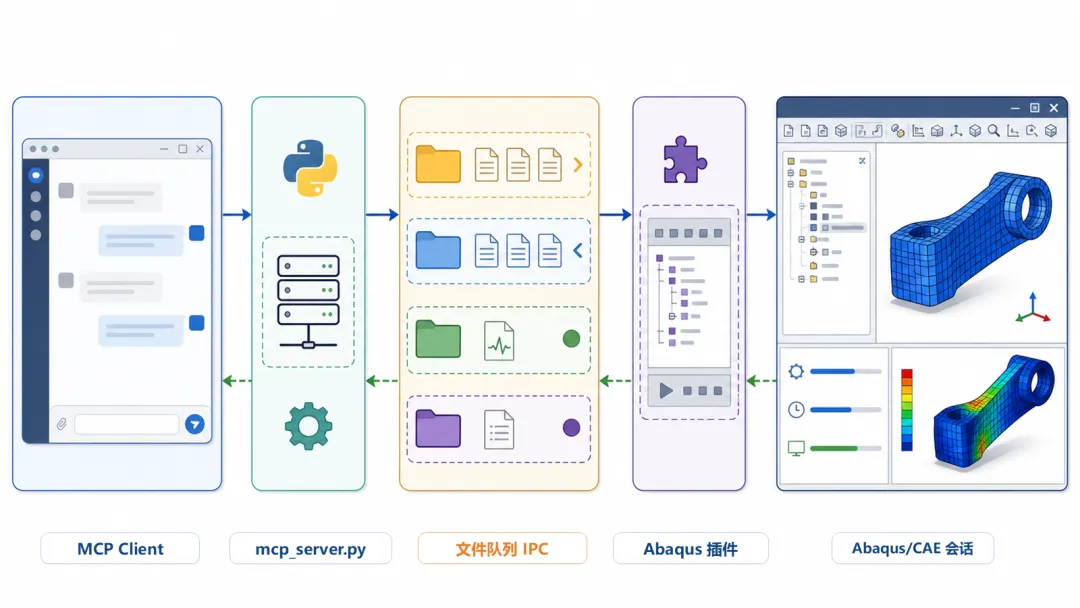
图 2|Abaqus-MCP 的本地调用链路。 外部 MCP Client 并不直接操作 Abaqus/CAE,而是通过本地 server、文件队列和插件层完成命令传递与结果回传。
外部 server 和 Abaqus 插件之间通过本地文件队列传递命令和结果。commands/ 放待执行命令,results/ 放返回结果,status.json 用于心跳状态,mcp.log 记录操作日志。这个设计便于观察,也便于追踪。
但可观察不等于天然安全。只要涉及脚本执行、文件写入、Job 提交和结果读取,就必须限制工作目录、保留日志、使用副本模型,并让高风险动作停在人类确认点之前。
链路打通之后,外部 MCP 客户端能调用的 Abaqus 能力,大致已经形成“模型信息 -> Job -> ODB -> 截图”的闭环基础。
| 能力 | 对应工具 | 工程意义 | 风险边界 |
|---|---|---|---|
| 检查连接 | check_abaqus_connection / ping | 确认插件是否响应 | 只能说明接口连通 |
| 执行脚本 | execute_script | 辅助运行 Abaqus Python | 高风险,必须人工确认 |
| 查询模型 | get_model_info | 读取模型、材料、Step、载荷等 | 适合先做只读观察 |
| 管理 Job | list_jobs / submit_job | 列出并提交分析任务 | 防止覆盖和误提交 |
| 检查 ODB | get_odb_info | 只读查询 ODB 元数据 | 元数据不等于结果可信 |
| 截图回传 | get_viewport_image | 返回 Abaqus 视口图像 | 截图只是可视证据 |
| 状态资源 | abaqus://status | 查询插件运行状态 | 只表示接口状态 |
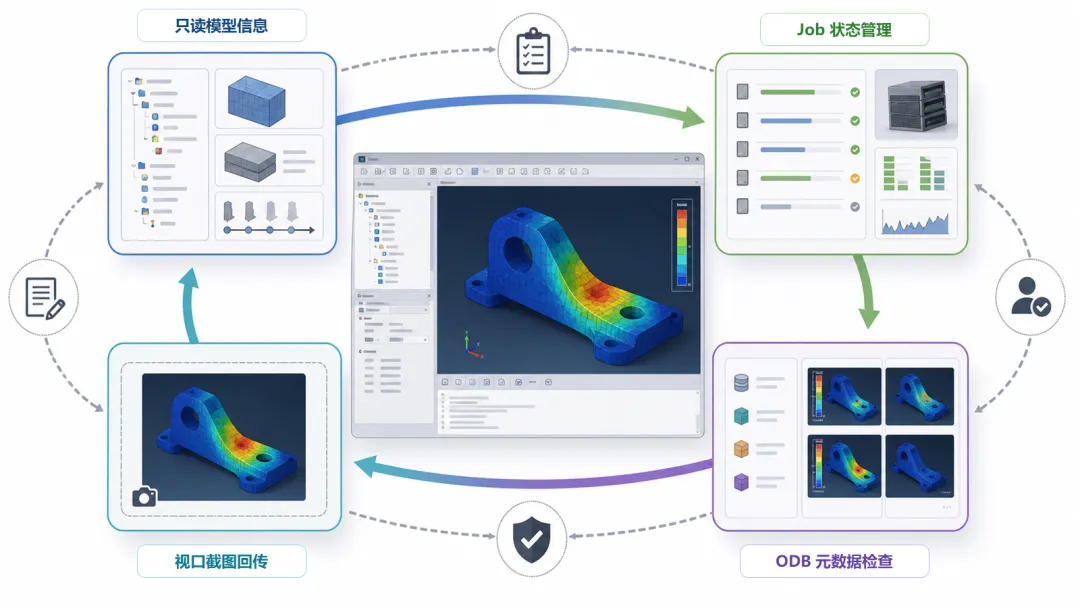
图 3|模型信息、Job、ODB、截图的闭环能力。 这些工具不是零散按钮,而是围绕同一个工程会话形成“先读状态、再看任务、再查结果、再回传证据”的基础闭环。
其中最需要单独拎出来看的是 execute_script:Abaqus 自动化绕不开脚本,但脚本一旦执行,就可能修改模型、覆盖对象,甚至提交 Job。这也引出一个更实际的问题:这些能力应该按什么顺序开放?
●3. 它适合从低风险动作开始,而不是接管仿真判断
答案不是一上来就让 AI 写脚本、改模型或提交 Job,而是先从低风险、可回溯的任务开始:Abaqus Python 学习、只读模型检查、脚本草稿执行前检查、小型 demo 模型、Job 状态查询、ODB 元数据检查、视口截图回传。
起步顺序可以按权限逐级放开:
连接检查 -> 只读查询 -> 截图回传 -> 执行无副作用脚本 -> 创建副本模型 -> 提交小 Job -> 读取 ODB 元数据
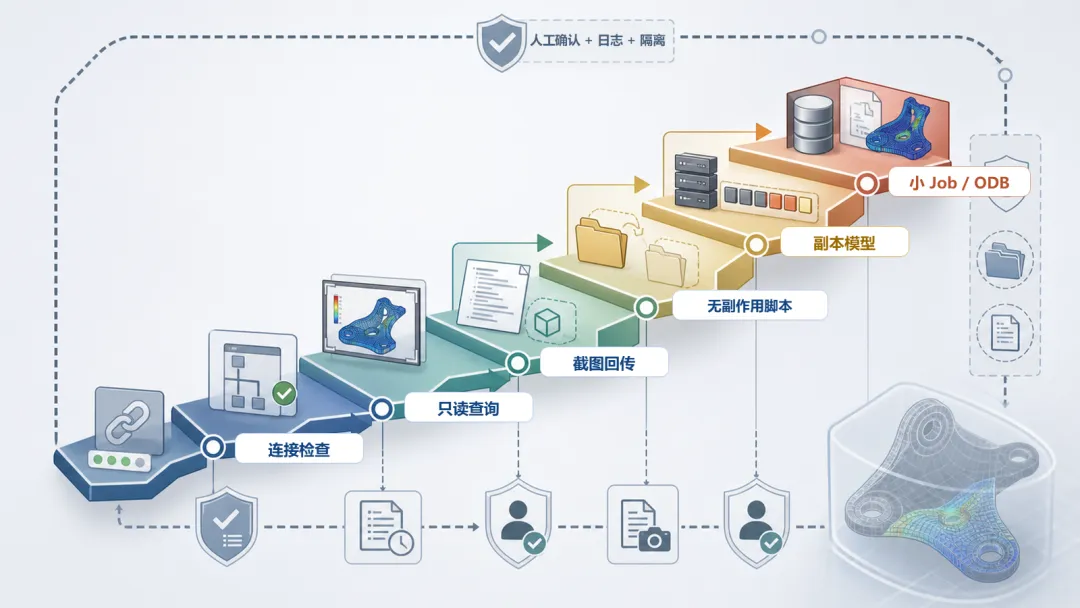
图 4|权限逐级开放与工程风险边界。 越靠后的动作权限越高,越需要副本模型、日志记录、人工确认和结果复核,避免把工具调用误写成“自动仿真工程师”。
这个顺序不是为了展示功能,而是为了控制风险:越靠后的动作权限越高,越需要日志、副本和人工确认。
换句话说,Abaqus-MCP 可以进入流程,但不应该被写成“自动仿真工程师”。每类高风险动作都应该有清晰边界:
| 高风险动作 | 建议边界 |
|---|---|
| 任意 execute_script | 先只读,后执行;执行前展示完整脚本 |
| 修改已有模型 | 使用副本或新 demo 模型 |
| 提交 Job | 确认作业名、目录、许可证和计算资源 |
| 读取 / 解释 ODB | AI 只给元数据和初步摘要,工程结论由人复核 |
| 视口截图 | 作为可视证据,不替代模型数据和结果校核 |
未经确认修改生产模型、覆盖 Job 或 ODB、开放任意脚本执行,或者让 AI 独立判断复杂材料非线性、接触收敛等工程问题,都不适合作为起步用法。底层逻辑仍然是:欢迎 AI 进入流程,但工程责任不能转移给 AI。
●4. 本期最小案例:先让 AI 查询当前模型
连接跑通以后,第一条有价值的命令不应该是“帮我建模并提交 Job”,而应该是只读查询。
建议 prompt:
请通过 Abaqus-MCP 查询当前 Abaqus/CAE 会话中的模型信息。只读取,不修改,不执行建模脚本。请返回模型名、部件、材料、Step、载荷、边界条件和 Job 列表;如果为空,请明确说明当前会话可能没有加载模型。
理想返回可能类似:
当前模型:Model-1Parts: Beam-1, Support-1Materials: SteelSteps: Initial, StaticLoadLoads: Load-1BCs: Fixed-EndJobs: cantilever_demo
如果当前会话是空模型,返回空列表并不一定代表失败。它只说明当前没有可读对象。真正的连接测试要结合插件状态、心跳、日志和客户端工具调用结果一起判断。
这个最小案例的价值在于“先读上下文”。在工程软件里,先读清楚当前状态,比一上来执行脚本更重要。
●5. 从看懂架构,到真正连上
Abaqus-MCP 真正值得关注的地方,在于它把原本封闭在 Abaqus/CAE 里的会话状态和操作入口,整理成一组可以被 MCP 客户端调用的工具。
这让 AI 从“脚本建议者”往前走了一步,变成“受控工具调用者”。它可以查询模型、执行脚本、管理 Job、检查 ODB、拿回视口截图。但也正因为它开始触碰真实工程软件,权限、日志、副本、确认点和回滚策略就不能停留在口号上。
下一期,我们进入配置实战:在 Windows 环境中,如何把 Abaqus/CAE、Abaqus-MCP 插件和 MCP 客户端连起来,并完成第一条连接检查命令。
能让 AI 调用工具,只是第一步;能让每一次调用都可确认、可追溯、可复核,才是工程工作流真正需要的能力。
|
公众号  |
知识星球  |
扫码关注 科趣范,让科研更简单 |
|
小红书  |
抖音  |