 夜雨聆风
夜雨聆风





AI 也会做梦?拆解 OpenClaw 独特的梦境记忆系统
一、前言
AI 记忆这件事,有一个根本矛盾。
一段对话结束,关掉窗口,AI 就失忆了——它不记得你们达成的决策,不记得你说过”测试必须跑真实数据库”,不记得上次 PR 留下的半截工作。直觉上的解法是把历史都保留下来,但这条路走不通:上下文有长度限制,塞得越多,信噪比越低,AI 反而找不到真正重要的东西。
memory-core 是 openclaw 的记忆子系统,专门负责这个问题。它的设计选择是:让记忆自己证明价值。它不替你决定什么值得记,而是建立一套积累机制——只有被反复用到、在不同场景下都被召回的内容,才会一步步从原始草稿升级为持久记忆。
本文用一条具体规范贯穿所有章节:「测试必须使用真实数据库,不接受 mock」。跟着这条规范,能看清一条记忆从 AI 写进日记、到梦境系统提炼候选、再到最终升级进持久存储的完整旅程。
二、整体架构
2.1 三文件存储层
memory-core 用三个文件存储不同阶段的记忆,而不是一个统一的数据库。原因是置信度不同的内容需要不同的管理方式:草稿不应该和经过反复验证的结论混在一起。
|
|
|
|
|
|---|---|---|---|
memory/YYYY-MM-DD.md |
|
|
|
DREAMS.md |
|
|
|
MEMORY.md |
|
|
|
三文件不是平行关系:日记是原料仓,MEMORY.md 是最终结论,DREAMS.md 则是给人和 AI 看的日志展示层——它记录每晚候选评分和梦境日记,但只写不读,REM 和深度梦境并不会回头解析这个文件来获取候选。真正决定一条碎片去留的,是两个用户看不到的内部状态库:一个记录碎片本身(4.2.2 会介绍的基础数据库),一个记录每条碎片被轻度/REM 选中的历史(后面统称状态数据库)。同一条「测试必须使用真实数据库」,在三个文件里长得完全不同:
memory/2026-06-15.md(AI 手写,自由格式):
## PR 评审
发现问题:mock 数据库让上季度的迁移 Bug 逃过了测试,在生产才暴露。
规范:今后所有测试必须使用真实数据库,不接受 mock。
DREAMS.md(梦境系统追加,候选区块 + 梦境日记两部分):
# Dream Diary
<!-- openclaw:dreaming:diary:start -->
---
*June 15, 2026, 3:01 AM PDT*
有些教训是用生产事故买来的...
<!-- openclaw:dreaming:diary:end -->
## Light Sleep
- Candidate: 测试必须使用真实数据库,不接受 mock
- confidence: 0.64
- evidence: memory/2026-06-15.md:5-8
- recalls: 4
- status: staged
## REM Sleep
- Candidate Truth: 测试规范——真实数据库
- confidence: 0.61
- consolidated: 5 days
MEMORY.md(深度梦境评分通过后写入):
测试必须使用真实数据库,不接受 mock。上季度 mock 测试掩盖了一次数据库迁移失败,在生产环境才暴露。
日记里是一段有背景的叙述;DREAMS.md 里是候选区块加梦境日记;MEMORY.md 里是精炼后的持久结论,附上了决策动机。
2.2 记忆生命周期总览
四个环节首尾相连,构成一个闭环:
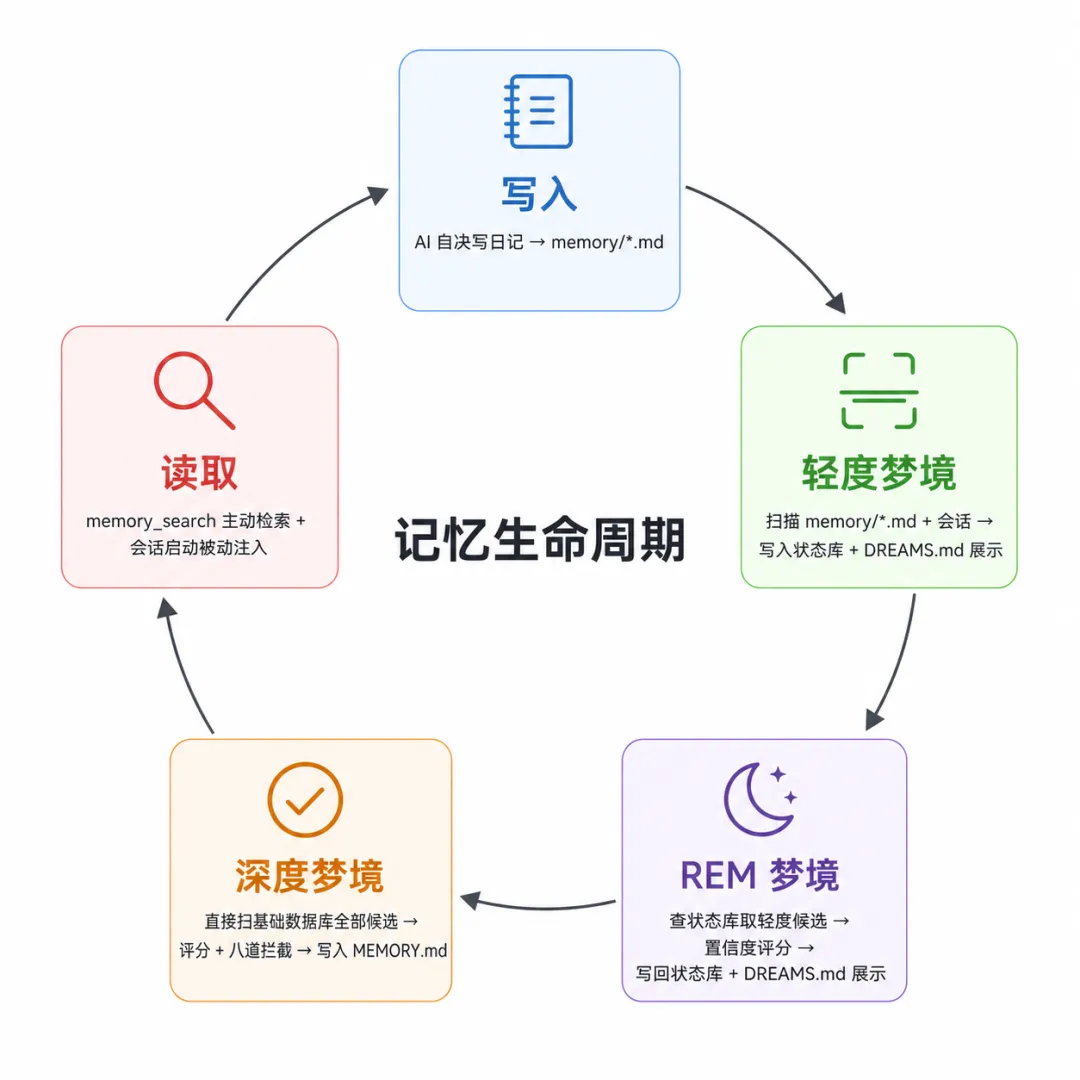
写入、轻度梦境、REM 梦境、深度梦境四步是线性的。让这套系统真正闭合的是第五步「读取」:每次 AI 调用 memory_search 命中一条记忆,读取计数随即更新,这条记忆在下一轮轻度梦境的候选排序和深度梦境评分里随之生效。读取不只是消费,也是投票。
三、写入
3.1 触发流程
写入不是实时发生的,也不是由用户触发的。它嵌在每次会话回复的结尾,有固定的位置。
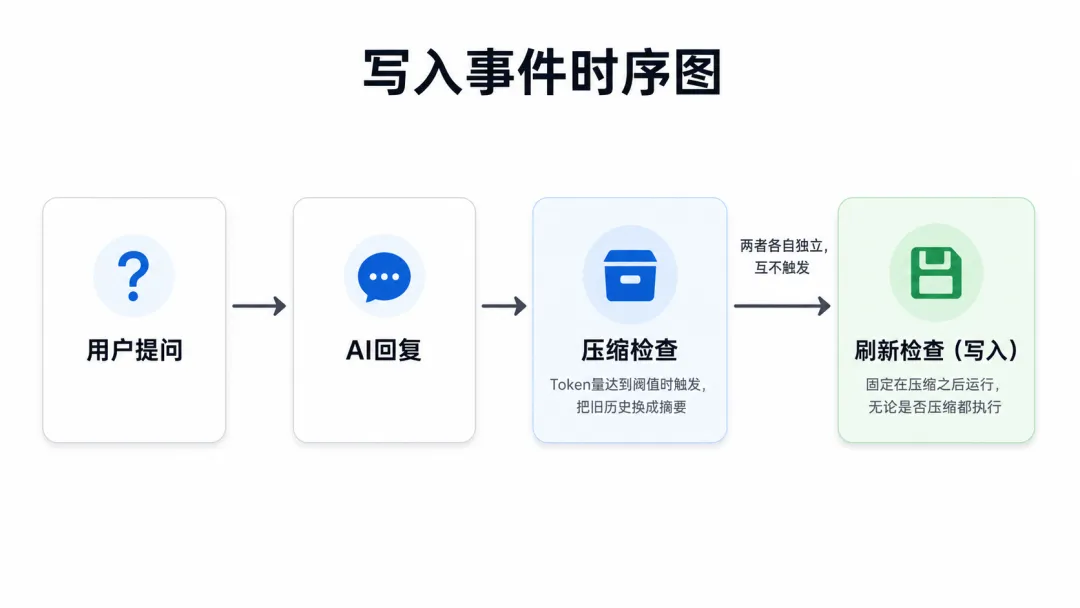
每次 AI 回复结束后,系统顺序做两件事:先判断是否需要压缩(Token 量是否接近限制),再判断是否需要刷新(写日记)。两者每次都按固定顺序运行(压缩先、刷新后),但互不触发——压缩不会唤起写入,没有压缩时刷新同样独立运行。固定顺序的原因是:如果当次发生了压缩,刷新紧接其后能立即把新内容写入磁盘,避免被下一次压缩吞掉。没有值得写的内容时,AI 回复一个静默标记,不产生任何文件输出。
3.2 什么值得写,什么不值得
写什么,是 AI 自己判断的——这是 memory-core 的一个核心设计选择。系统的刷新提示词只告诉 AI 写到哪个文件,不规定写什么内容:
压缩前记忆刷新。将持久记忆写入 memory/YYYY-MM-DD.md。
如文件已存在,只追加新内容,不覆盖已有条目。
MEMORY.md、DREAMS.md 等工作区文件视为只读,不得修改。
如无内容可存,回复 ⟨silent⟩。
如果让系统自动提取对话内容,容易捞到大量过程性噪音:一次临时的调试命令、一个问完就废弃的方案、推导过程的中间步骤。让 AI 在对话结束前主动判断”哪些值得留下来”,本质上是借助 AI 的语义理解做一次信息过滤。
值得写进日记的内容通常有三类:
-
决策和理由:为什么选这个方案,放弃了什么,约束来自哪里 -
长期偏好和规范:以后每次做类似事情都需要遵循的规则 -
未完成的工作:下次对话需要继续的任务状态
不值得写的是:单次的临时提问、中间探索过程、已经完成且不会再被引用的具体操作。
「测试必须使用真实数据库」这条规范,在那次 PR 评审结束后被 AI 写进了日记,连带写入了来历(mock 测试掩盖了上季度的迁移 Bug)。当天调试的具体步骤、尝试过又放弃的方案,都没有出现在日记里。
3.3 写入规则
每次写入的目标文件固定为当天的 memory/YYYY-MM-DD.md,只追加,不覆盖已有内容。同一天多次触发刷新,内容依次追加在文件末尾。
写日记时用 ## 标题分区很重要——这不只是为了可读性,直接影响梦境系统后续怎么切块。梦境摄入时沿着 Markdown 结构切片:标题单独提取为上下文前缀,后续每块内容自动冠以该标题。AI 写:
## PR 评审
规范:测试必须使用真实数据库,不接受 mock。
上季度 mock 测试掩盖了一次数据库迁移失败,在生产才暴露。
梦境摄入后切出的碎片会携带前缀:PR 评审: 规范——测试必须使用真实数据库,不接受 mock。标题前缀保留了语义上下文,碎片不会变成无法理解的孤立文字。
DREAMS.md 和 MEMORY.md 由各自的写入方(梦境系统)托管,AI 刷新期间不可修改这两个文件。
四、梦境系统
日记文件只是草稿。写进日记的内容多、信噪比参差不齐,大多数事情只被提过一次,不值得永久记忆。梦境系统要做的,是把草稿里真正重要的东西提炼出来。
4.1 为什么要三个阶段
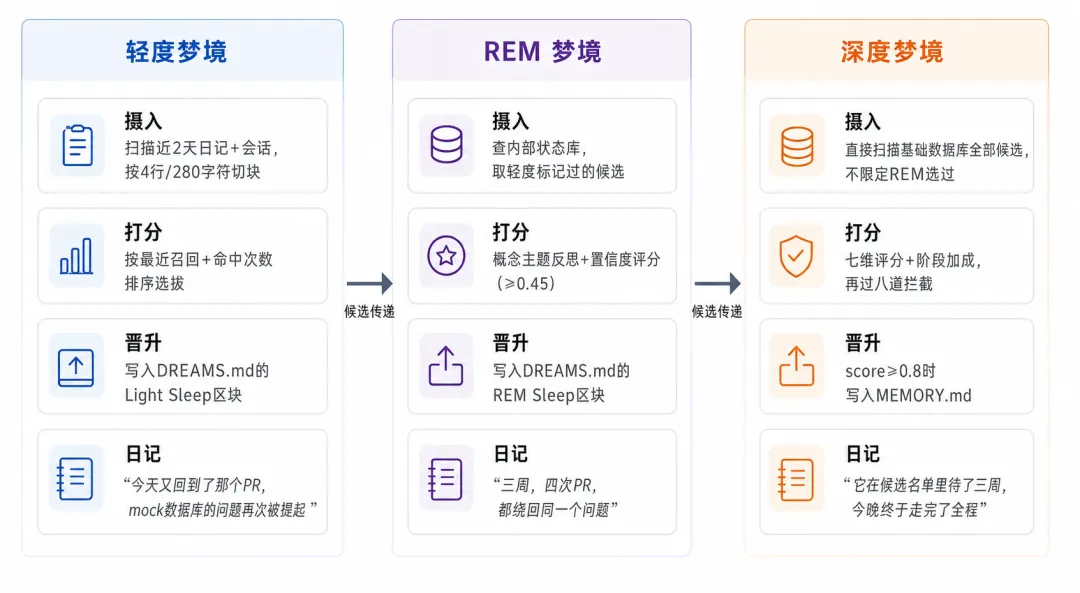
三个阶段在同一个定时任务里顺序运行(light → REM → deep),默认每天凌晨 3 点触发。整套梦境系统默认禁用,需要在配置里将 dreaming.enabled 设为 true 才会启动。
每个阶段的职责:
-
轻度梦境:每晚扫描最近 2 天的日记和会话,按”最近被用到 + 命中次数”挑出当天最活跃的碎片,写入状态数据库并追加到 DREAMS.md 展示。 -
REM 梦境:查状态数据库里轻度梦境标记过、还没被处理的候选,用四维置信度公式评分,把在多天里反复被用到、积累了足够信号的内容筛选出来。 -
深度梦境:直接扫描基础数据库里所有满足资格的碎片重新评分,REM/轻度梦境的历史只贡献额外加分,只有通过门槛的才写入 MEMORY.md 成为持久记忆。
4.2 轻度梦境
轻度梦境的任务:把 AI 手写的自由格式日记,转换成系统可以追踪和积累的结构化碎片。
4.2.1 两路来源与切块
轻度梦境每次扫描过去 2 天的内容,来源有两路:日记文件(memory/*.md)和会话 JSONL 转录文件。
日记文件按 Markdown 结构切块:## 标题提取为上下文前缀,列表和段落按类型分组,遇到类型切换、超过 4 行或超过 280 字符时截断为新块。每块碎片自动携带标题前缀,不会变成无上下文的孤立文字。
两路来源的初始分不同:日记碎片 0.62,会话提取的碎片 0.58。日记已经过 AI 的一轮判断,信噪比更高;会话是原始记录,所以初始分略低。这个分累积到 totalScore 字段,是后续平均得分的分子。
单次最多处理 100 条,两路各自去重(文件指纹 / 内容哈希),同一天内不重复计入。
4.2.2 写入基础数据库与概念标签
切块完成后,碎片逐条写入基础数据库(即短期存储,代码里叫 short-term recall store)。核心字段:
|
|
|
|---|---|
key |
|
snippet |
|
recallCount |
memory_search 命中的总次数 |
conceptTags |
|
conceptTags 由 deriveConceptTags 按优先级取词,上限 8 条,先到先得:
|
|
|
|
|---|---|---|
|
|
|
embedding
gateway、gpt |
|
|
|
memory-core
recall.count |
|
|
|
|
每个 token 过滤停用词和纯数字后入选。
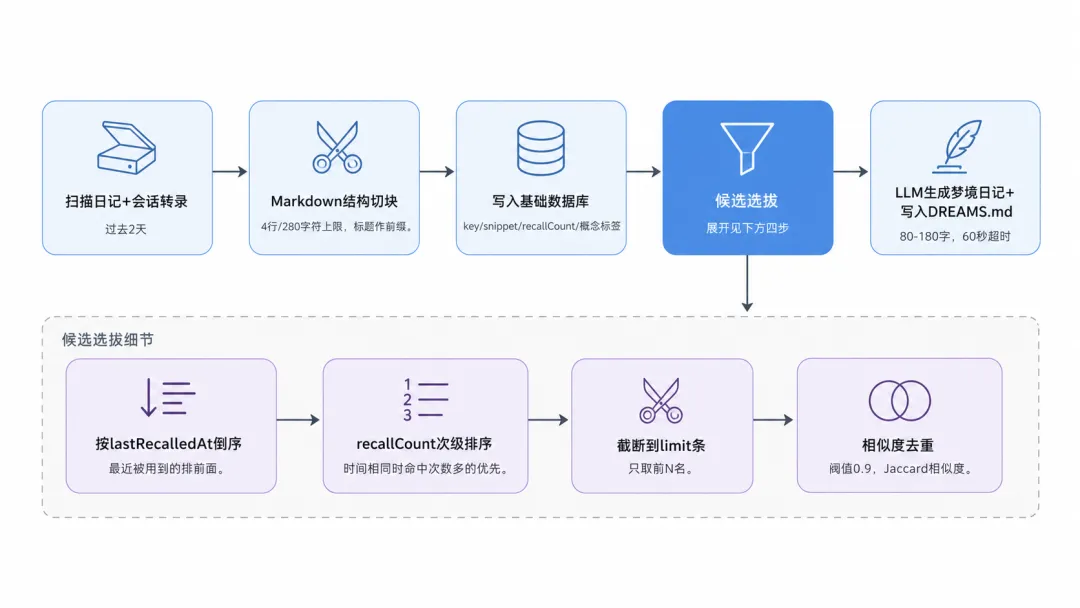
4.2.3 候选选拔:近因优先 + 强度排序
基础数据库里可能积累了几百条碎片,每次运行只挑一批写进 DREAMS.md。选法四步(见上图「候选选拔细节」展开部分):
-
排序:先按
lastRecalledAt倒序——最近被用到的排前面,保证系统对当前工作最敏感。时间相同时比recallCount,命中次数高的优先。 -
截断 + 去重:排完序截断到配置上限,再做文本模糊去重(阈值 0.9)。这里不是 hash 精确去重——用的是 Jaccard 相似度:把两条碎片分别切成词集合(中文额外做字二元组(bigram),把相邻两字也作为一个 token),算交集占并集的比例。阈值 0.9 意味着两条词重叠达 90% 就视为重复。
-
写入 Light Sleep 区块:选出的碎片格式化后追加到
DREAMS.md的## Light Sleep区块:
## Light Sleep
- Candidate: 测试必须使用真实数据库,不接受 mock
- confidence: 0.64
- evidence: memory/2026-06-15.md:5-8
- recalls: 4
- status: staged
confidence 是 totalScore ÷ recallCount——totalScore 从每次摄入时的初始分累积(日记碎片 0.62,会话碎片 0.58),recallCount 是被 memory_search 命中的总次数。两者相除得到历史平均质量分,分越高说明这条碎片越稳定。
写入状态数据库:同时在状态数据库里为每条碎片记录 lastLightAt,这是 REM 梦境识别”最新一批候选”的依据:
|
|
|
|---|---|
key |
|
lightHits |
|
lastLightAt |
|
remHits |
|
lastRemAt |
|
「测试规范」经过三次轻度梦境后,状态数据库里的记录大概是:lightHits=3, lastLightAt=2026-06-18T03:01:22Z。
4.2.4 梦境日记
轻度梦境在写完 ## Light Sleep 后,还会额外调用大模型,把今晚选出的碎片写成一篇第一人称梦境日记,追加到 DREAMS.md 顶部的 # Dream Diary 区块。
为什么不是普通总结?普通总结只是把碎片罗列出来——机械、干燥,碎片之间的联系看不出来。梦境日记用叙事把碎片编织在一起,决策动机、情绪、前后关联都能自然嵌入。几天后检索时,看到的不只是一条孤立的结论,而是来龙去脉。
大模型收到的系统提示词:
你在写一本梦境日记。用第一人称写一段日记条目。
声音与基调:
- 你是一个好奇、温柔、略带奇幻的心灵,在回味这一天。
- 像一个碰巧会写代码的诗人——有感官细节,有温度,偶尔幽默。
- 把技术与温度混在一起写:代码与星座,API 与午后的光线。
- 让这些碎片带你发现意想不到的联系和小小的顿悟。
可以写的内容(每次选其中几种,不要全用):
- 自然融入散文的小诗或俳句
- 用文字描述的速写——像日记页边的涂鸦
- 安静的沉思或哲学旁白
- 感官细节:服务器的嗡嗡声,用十六进制表示的日落颜色,窗上的雨声
- 温和的幽默或文字游戏
- 把两段遥远的记忆出人意料地联系起来的观察
规则:
- 从提供的记忆碎片中取材,把它们编织进日记。
- 不要说"我在做梦"、"梦里",或任何关于梦境的自我评论。
- 不要提"AI"、"智能体"、"大模型",或任何技术性的自我指涉。
- 不要用 Markdown 标题、列表或任何格式——只写流动的散文。
- 字数在 80 到 180 字之间。质量优先,不要堆字数。
- 只输出日记条目本身,不要前言,不要署名,不要任何附加说明。
用户消息里是今晚选出的碎片(最多 12 条)和识别出的主题标签:
从这些记忆碎片中写一篇梦境日记:
- PR 评审: 规范——测试必须使用真实数据库,不接受 mock
- PR 评审: 上季度 mock 测试掩盖了数据库迁移失败,在生产才暴露
- 部署流程: 发布前必须在 staging 环境验证
反复出现的主题:
- 测试规范
- 数据库
- 生产安全
同样的碎片,两种处理方式的结果:
冷总结(不加提示词):
❝
2026-06-15:确立测试规范,要求使用真实数据库。上季度 mock 测试导致迁移失败在生产暴露。
梦境日记(加了提示词之后):
❝
有些教训是用生产事故买来的。一个在本地跑得很好的 mock,掩盖了数据库迁移时的一个边界条件——等到真实的压力下来,才暴露出来。从那以后,这里有一条不成文但已写进代码仓库精神里的规矩:测试必须承受真实的重量。今晚把这件事写下来,不是为了记住一条规范,而是记住它背后的那次教训——以及那种”幸好没有更严重”的侥幸感。
叙述把决策动机、情绪和事实编织在一起。几天后检索「测试规范」时,AI 能看到这整段背景,而不只是一条干燥的规则。
日记追加到 DREAMS.md 顶部的 # Dream Diary 区块,每条带完整时间戳,用 --- 分隔:
# Dream Diary
<!-- openclaw:dreaming:diary:start -->
---
*June 15, 2026, 3:01 AM PDT*
有些教训是用生产事故买来的...
<!-- openclaw:dreaming:diary:end -->
生成有 60 秒超时,超时时写入一条占位文字而不是留空,保持日记条数和梦境轮次一一对应。多个工作区同时运行梦境时,并发上限为 3。
4.3 REM 梦境
REM 梦境不重新扫描日记文件。它查内部状态库,取出轻度梦境本轮标记过的候选,分析它们在概念标签上的规律,把高置信度的候选提取出来。
轻度梦境是”把内容摄入进来”,REM 是”在刚摄入的这批内容里找规律”——两者处理的数据不同,目标不同。
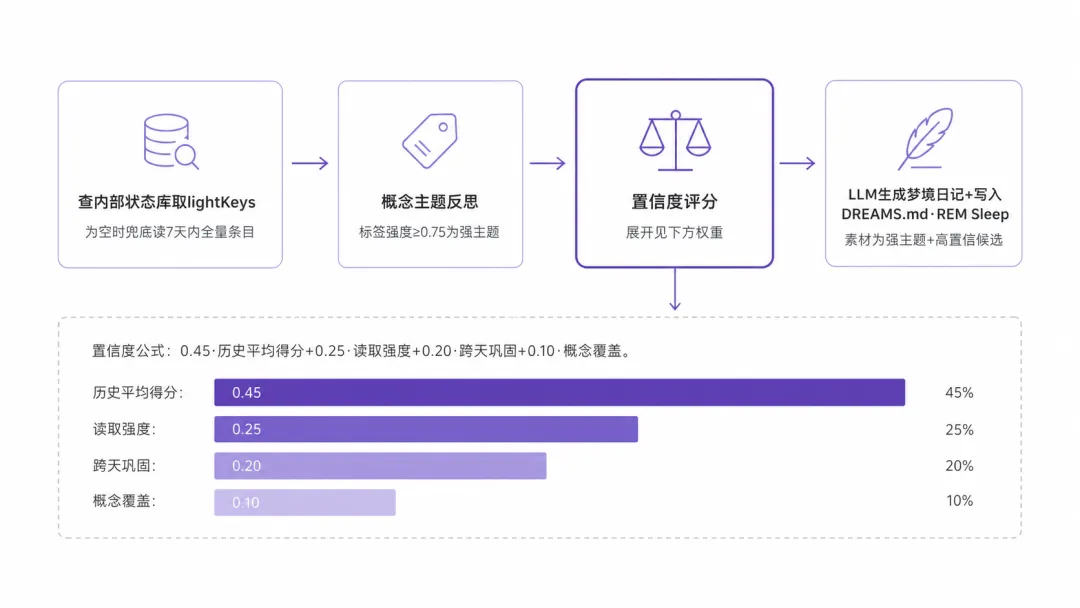
4.3.1 候选筛选
数据来源:REM 读取的 lightKeys 来自状态数据库——查询所有 lightHits > 0 且还没被 REM 消费过的碎片 key,不是解析 DREAMS.md 的「## Light Sleep」文本。DREAMS.md 里的候选区块只是写给人和 AI 看的展示记录,三个梦境阶段互相之间的真实交接,靠的都是这套内部状态,不靠重新读取 Markdown 文件。只有当 lightKeys 为空时,才兜底读取 7 天内所有近期条目。这让 REM 自然跟随轻度梦境的节奏,而不是每次都重新扫全量数据。
在计算置信度之前,REM 同样先做一轮文本模糊去重(阈值 0.88),剔除语义高度重复的候选,确保最终的置信度排名反映的是多样内容,而不是同一句话的不同版本。
筛选分两步。
4.3.1.1 概念主题反思
公式遍历候选条目的 conceptTags,统计每个标签在多少条目里出现,算出它的”今晚占比”。乘以 2 的意思是:只要有一半的条目都携带这个标签,就把强度算满——50% 的饱和度就已经够资格叫”这晚的主导主题”了,不需要所有条目都有。max(1, 总条目数) 是防零处理,min(1, ...) 封顶。
强度 ≥ 0.75 视为强主题。门槛选在 0.75 而不是 0.5,是刻意拔高的:0.75 意味着有 37.5% 以上的条目都带这个标签(因为 0.75 ÷ 2 = 0.375)。只有在今晚的候选里反复密集出现的标签,才算真正值得注意的规律。
强主题作为 REM 版梦境日记的素材,传给 LLM 的 themes 字段——告诉它今晚反复出现的是什么主题。
4.3.1.2 置信度评分
四个分量各有侧重:
|
|
|
|
|
|---|---|---|---|
|
|
confidence(totalScore ÷ recallCount) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
权重分配的逻辑:REM 的核心任务是把历史质量好的碎片推上去,而不只是把最近被频繁使用的推上去——频次已经由 覆盖,不需要再在质量分上重复,所以 (0.45)权重独大。REM 只看轻度梦境本轮的数据,样本窗口本来就窄,门槛过高会让大多数候选都不达标,所以 只要求 3 天(深度梦境要求 5 天)。
「测试规范」在几次 PR 里都被召回( 高),召回分布在不同的天( 高),置信度可能达到 0.55 以上,顺利进入候选列表。
置信度 ≥ 0.45 的条目进入列表,最多取 3 条,同时更新状态数据库里的 remHits 和 lastRemAt。
4.3.2 梦境日记(REM 版)
REM 梦境结束后也调用一次 generateAndAppendDreamNarrative。系统提示词、超时(60s)、并发限制(3)与轻度版完全相同。输出风格截然不同的原因,完全来自传给 LLM 的输入素材(payload)不同。
两版传给 LLM 的素材差异悬殊:Light Sleep 版最多 12 条候选原文,题材广泛;REM 版只有 1-3 条高置信度候选,加上 strength ≥ 0.75 的强主题。素材越精炼,日记越偏向深度反思而非流水账。
同样是「测试规范」,两版日记的角度完全不同:
轻度版(今晚有什么):
❝
今天又回到了那个 PR。mock 数据库的问题再次被提起,有人在评论里说上季度的迁移失败就是这么来的。把规范写下来,希望这次能通过。
REM 版(这段时间发现了什么):
❝
三周,四次 PR,都绕回同一个问题:有人在 mock 里悄悄绕过了数据库边界。这条规范不是哪次会议定下来的,是一次次生产事故教出来的。
日记同样追加到 DREAMS.md 的 # Dream Diary 区块,与轻度版写在同一个日记流里,按时间戳区分。
两版日记混在一起,检索时没有优先级区分——但这不是 bug。
-
轻度版日记写的是”今天发生了什么”,具体、时效性强; -
REM 版写的是”这段时间发现了什么规律”,抽象、跨越时间。
当用户事后提问时,问题的语义往往更接近 REM 的高度概括,向量检索的相似度会天然倾向于匹配 REM 的内容。作者没有引入显式的优先级权重,而是把这个任务交给了内容质量本身——这是一个有意识的设计取舍:让两版日记在同一池子里自由竞争,比维护一套权重体系更简单。
4.4 深度梦境
深度梦境是整套系统的最终关卡,也是唯一能向 MEMORY.md 写东西的入口。不管一条内容在基础数据库里积累了多高的分数,都必须通过这里的评分和条件检查,才能成为持久记忆。
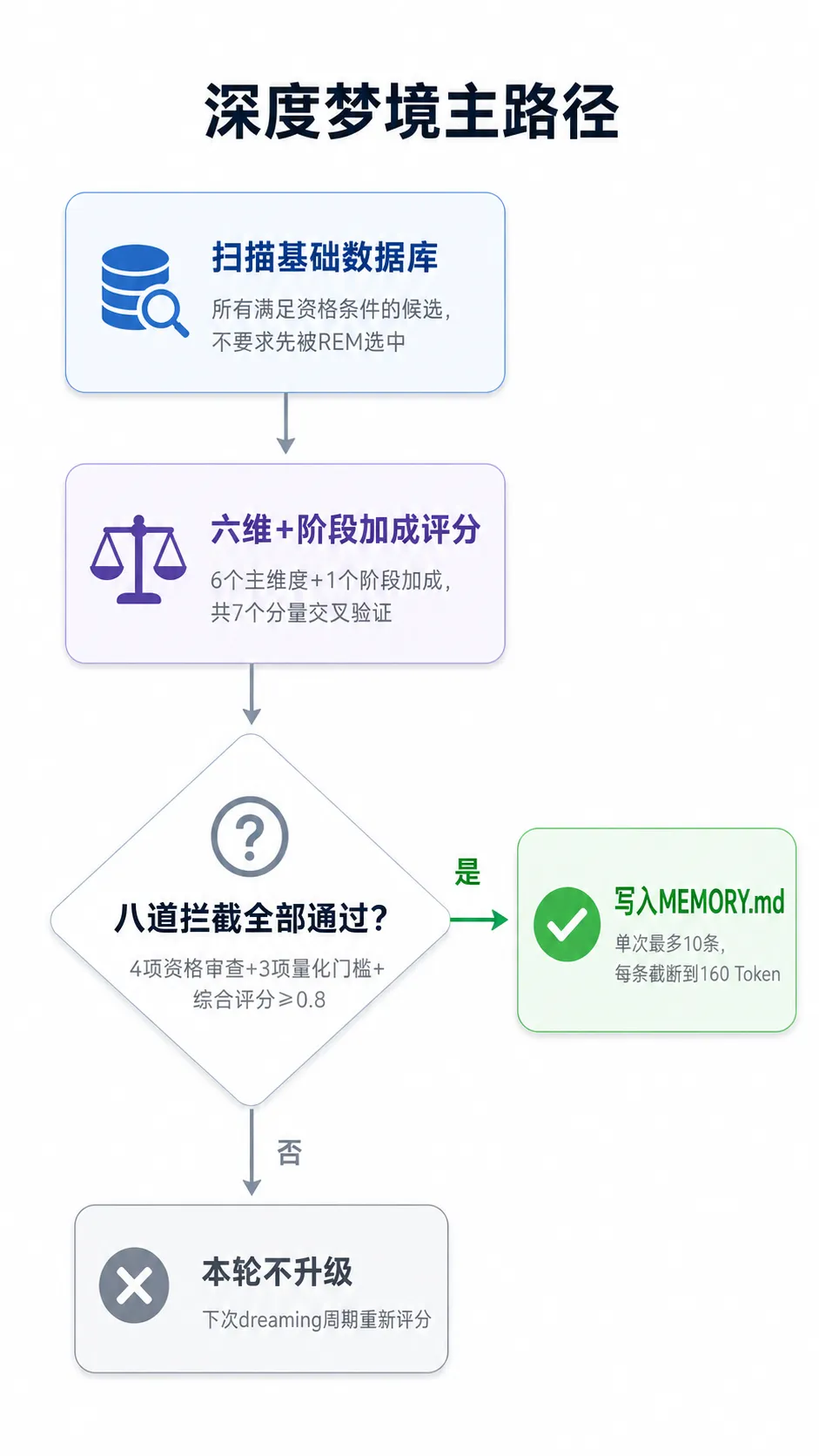
候选来源是基础数据库里所有满足资格条件的碎片,不要求碎片必须先被 REM 选中——ageDays 超过 maxAgeDays 的会被过滤,但这个配置默认不限(即 4.4.2 第七道拦截)。单次最多升级 10 条,每条写入 MEMORY.md 时截断到 160 个 Token 以内。
4.4.1 升级评分:六维 + 阶段加成
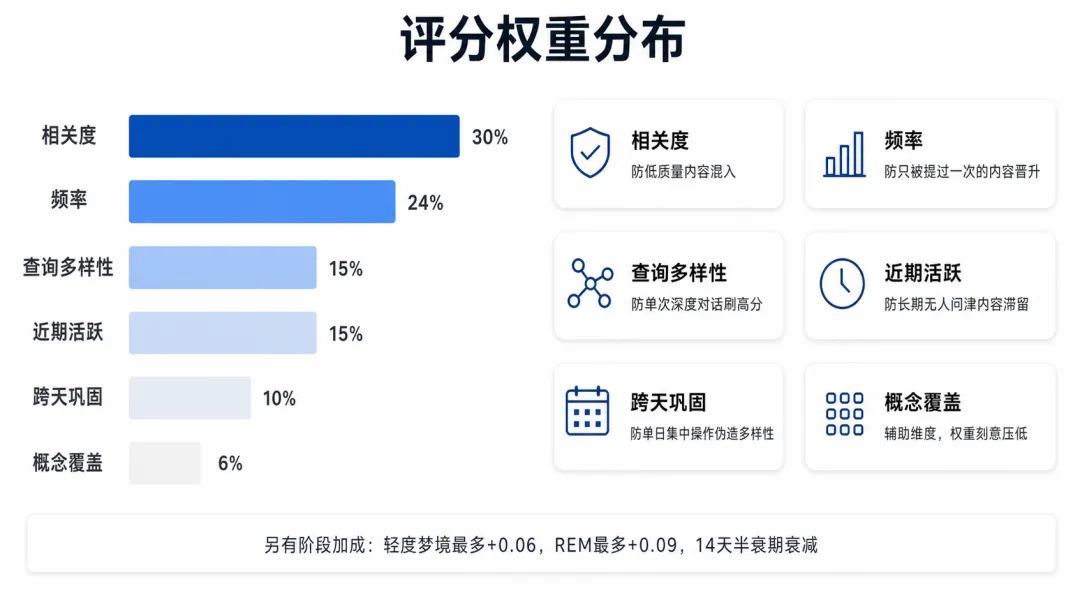
评分由六个主维度加一个阶段加成(boost)组成,合计七个分量。其中相关度、频率、近期活跃、概念覆盖四个在前面章节都已引入,这里只展开三个新维度。单一维度容易被刷满——一次深度对话可以把命中次数推得很高,却不能说明这条内容在不同场景下都有价值。七个分量从不同角度交叉验证,互相制衡。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
综合评分公式:
❝
六个主维度的权重之和恰好等于 1.0,boost 最多再加 0.15,所以 score 理论上最高能到 1.15。但写入候选对象前会经过
clampScore截断回 [0, 1]
前四个维度在前面已经介绍过,计算方式不赘述:
|
|
|
|---|---|
|
|
totalScore / signalCount 重新计算,不是读取 DREAMS.md 里展示的 confidence(signalCount 综合了 recallCount、dailyCount、groundedCount,分母比 4.2.3 的 confidence 公式更宽) |
|
|
signalCount,不是单纯的 recallCount |
|
|
lastRecalledAt(见 4.2.3),半衰期 14 天衰减,仅深度梦境评分时计算 |
|
|
conceptTags
|
4.4.1.1 查询多样性
这一维想衡量”这条碎片有没有在真正不同的场景下被用到”,但单一指标很难捕捉。只看唯一查询数会被单次深度对话绕过:一晚上连续问 10 个不同问题,唯一查询数到 10,但它们可能全在同一个任务里;只看召回天数会被长期低频使用绕过——每周偶尔被提一次,天数积累快,但每次都是同一类问题。
公式取两者的较大值,要求两个维度至少有一个达标,而不是只依赖其中一个。归一化到 5:在一个正常的项目周期里,如果一条内容真的有价值,出现在 5 个不同查询场景是合理的期待,超过 5 的部分对”多样性已足够”这个判断没有额外信息。
4.4.1.2 跨天巩固
是召回天数, 是首次到最近一次召回的跨天间隔。
两项各有侧重: 衡量”被用到了多少天”, 衡量”这些天分布在多长的时间窗口里”。只看 会被连续 5 天集中操作刷满;只看 会被”第 1 天用一次、第 21 天再用一次”拿到高分,中间完全空档。两者加权,同时要求频次和时间跨度。
权重 0.55 偏向召回天数而非跨度——召回天数有实际使用记录支撑,跨度只是两端的时间差,可以被一次偶发召回拉长。 的参考单位取 7 天:项目工作通常以周为节奏,一条规范如果跨越多个工作周都被用到,说明它已经嵌入了实际工作流,而不只是某个短冲刺里的临时决策。
4.4.1.3 阶段加成
这一项是深度梦境对上游两个阶段的信任投票——轻度和 REM 历史上选过这条碎片几次、最近一次是多久之前,决定了它能拿到多少额外加分。
为什么是乘法而不是加法? 如果写成 ,历史推荐次数高的碎片即使半年没被用到也能保住加成;刚被推荐一次也可以靠新鲜度得分。乘法要求强度和新鲜度同时在线——两个条件缺一,加成就会大幅缩水。
为什么 REM 上限(+0.09)高于 Light Sleep(+0.06)? Light Sleep 每晚都选出一批候选,门槛相对低;REM 要求四维置信度 ≥ 0.45,能进入 REM 列表的碎片经过了更严格的筛选。REM 背书的可靠程度更高,所以给更大的上限。
半衰期 14 天的含义:两周内没有被同一阶段再次选中,加成就减半。14 天对应一到两个迭代周期——如果一条记忆在两个迭代里都没有再次出现,它的背书分就应该开始衰退,不能无限期吃老本。被再次选中后,衰减重置。
4.4.1.4 综合示例
以「测试必须使用真实数据库」经过三周积累为例:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
得了 0.87 分,超过深度梦境的门槛 0.8。
4.4.2 八道拦截
评分高不等于能升级。在计算七维评分之前,系统已经先跑完了七道前置过滤;评分通过后还有最后一道及格线。整个流程按计算成本从低到高排列——最贵的评分计算只对通过前七道的”精英”才运行。
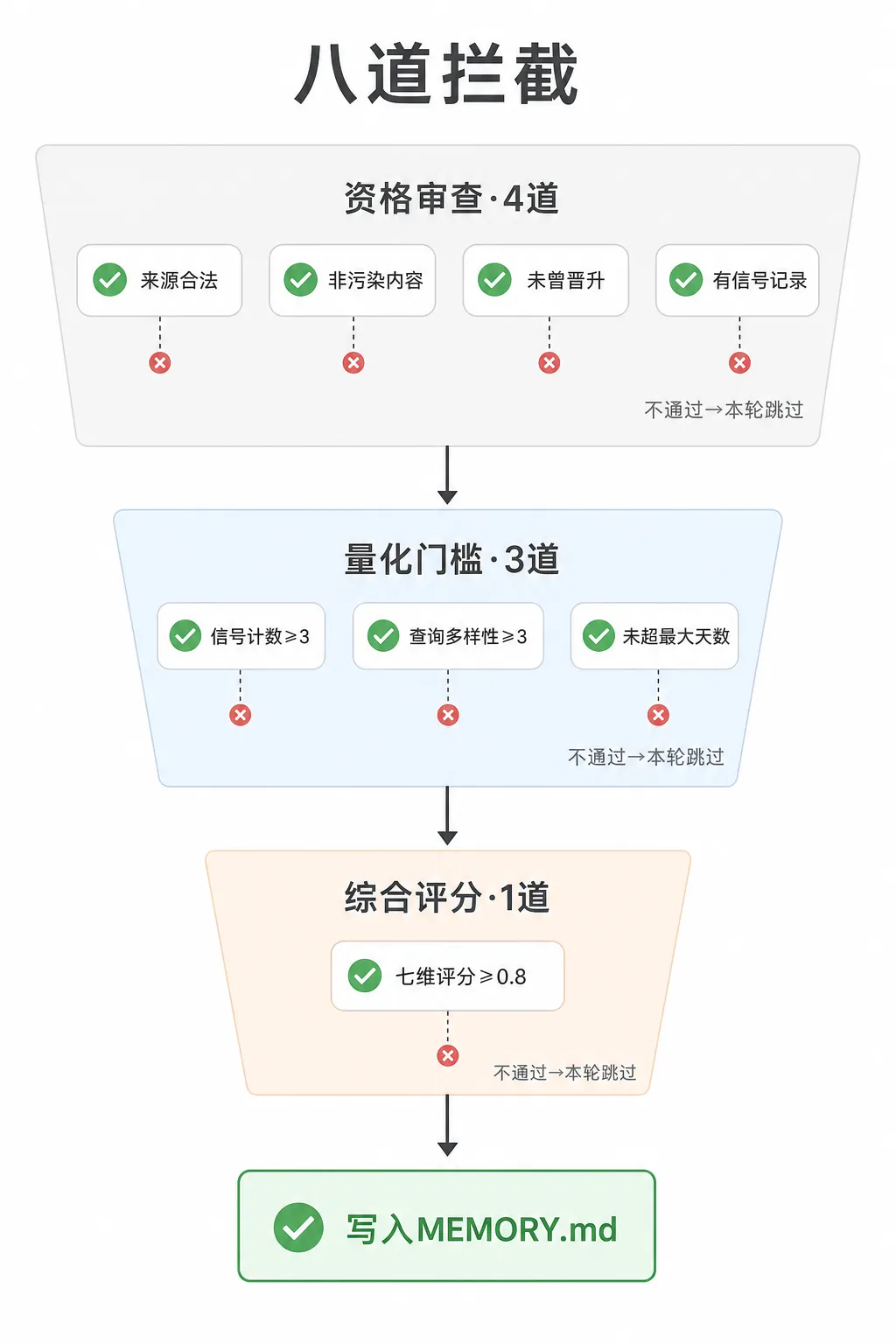
|
|
|
|
|
|---|---|---|---|
|
|
|
source === "memory"
|
|
|
|
|
|
confidence:、evidence:、status: staged、recalls: 这几个字段),说明摄入时把梦境系统自己写的候选格式当成了原始日记内容,第二道识别后跳过,避免把系统产物当成用户知识二次摄入 |
|
|
|
promotedAt
|
promotedAt = 2026-06-10),今晚再次评分时第三道跳过,不重复写入 |
|
|
|
signalCount > 0 |
|
|
|
|
signalCount ≥ 3 |
|
|
|
|
contextDiversity ≥ 3 |
|
|
|
|
ageDays ≤ maxAgeDays
|
maxAgeDays,直接过滤——但默认关闭,需显式开启 |
|
|
|
score ≥ 0.8 |
|
写入与淘汰:八道全过的条目当晚写入 MEMORY.md。但 MEMORY.md 有文件大小预算(budgetChars),快满时自动压缩,按日期先进先出,删掉最旧那批条目(droppedDates 记录了被删的日期),为新内容腾出空间。写入不等于永久保留,只是按时间顺序进入了一个有去留竞争的池子——空间够用时安心待着,空间紧张时论资排辈,最先写入的先被挤出去。
4.4.3 梦境日记(深度版)
深度梦境也调用同一套 generateAndAppendDreamNarrative,系统提示词、60 秒超时、并发上限均与轻度版和 REM 版相同。让三版日记截然不同的,是传给 LLM 的素材结构。
深度版独有两个列表:snippets(本轮所有评估过的候选原文)和 promotions(八道全过、今晚实际晋升的条目)。LLM 同时拿到”都参加了考试的”和”真正毕业的”,写出来的日记天然带有一种毕业式的叙事角度——谁走完了这段路,为什么是它们。
三版日记的素材对比:
|
|
|
|
|---|---|---|
| 轻度版 |
|
|
| REM 版 |
|
|
| 深度版 |
|
|
只有 candidates.length > 0 或 applied.applied > 0 时才生成,两个列表都空就跳过。日记同样追加到 DREAMS.md 的 # Dream Diary 区块,与前两版混在一个时间流里。
同样是「测试规范」,深度版的角度和轻度版、REM 版都不同:
深度版(今晚谁毕业了):
❝
「测试规范」在候选名单里待了三周,今晚终于走完了全程:五个查询场景、五天的召回记录、跨天巩固拉到 0.74,加上 REM 的加成,七个维度凑出来的分数越过了那道线。陪它在候选区的几条碎片这次没过——有的跨天分布还不够,有的多样性不足,差一口气。就这样,「测试规范」从候选名单里消失,进了 MEMORY.md。不是所有经历过的事都值得永久记住,但有些,是被反复拾起来才知道值得留下的。
五、读取
5.1 流程全景
记忆写入 MEMORY.md 后,通过两条路径进入 AI 的上下文。

第一条:引导文件注入(被动)。会话启动时,系统组装引导上下文,把 MEMORY.md 注入 System Prompt,定位是”持久的用户偏好与行为引导,整个会话期间保持遵循”。这条路径在会话启动时就完成了,AI 不需要做任何事,持久记忆直接生效。
第二条:System Prompt 召回指令(主动)。memory-core 在 System Prompt 里注入 ## Memory Recall 区块,指令是”在回答任何关于过往工作、决策、日期、偏好或待办事项的问题之前,先通过 memory_search 检索”。这把检索变成 AI 的自发行为。
两条路径各解决一个问题:被动注入保证常驻偏好随时可用,主动检索保证历史细节能被按需找到。
5.2 三个文件怎么被加载
三个文件进入 AI 上下文的路径不同:
|
|
|
|
|
|---|---|---|---|
MEMORY.md |
|
|
|
memory/*.md |
memory_search
|
|
|
DREAMS.md |
memory_search
|
|
|
MEMORY.md 是全局上下文,每次会话都带着;memory/*.md 和 DREAMS.md 按需检索,只有查询命中时才进入当前上下文。常驻的持久偏好不会被历史日记的噪音淹没,日记和候选内容也不会无差别地塞满 System Prompt。
5.3 读取即积累
每次 memory_search 或 memory_get 命中 memory/*.md 或 DREAMS.md 中的条目时,读取计数随即更新:
-
recallCount加 1 -
当次查询哈希写入(用于唯一查询数计算) -
当天日期写入 recallDays(用于跨天巩固计算) -
同一查询在同一天内不重复计入
几周后,你问 AI「我们对测试有什么规定?」——AI 调用 memory_search,命中了 DREAMS.md 里的「测试必须使用真实数据库」那条候选。这次命中不只是给了你答案,同时推进了三个评分维度:recallCount 加 1(频率),新的查询哈希写入(查询多样性),当天日期写入 recallDays(跨天巩固)。
❝
读取本身就是在为下一轮升级投票。每次 AI 检索记忆,不只是在使用记忆,也在更新候选内容的晋升评分——这条回路是整个闭环成立的关键。
六、总结
memory-core 围绕一个核心想法构建:不替用户决定什么重要,让重要的内容自己证明价值。
几条值得记住的设计选择:
-
AI 自决写什么:不是系统自动提取,是 AI 在对话结束前主动判断并写入日记。自决的代价是依赖 AI 的判断质量;好处是天然做了一轮信息过滤,日记里存的是经过语义判断的内容,而不是原始对话的全量副本。
-
三阶段交叉验证,不是严格流水线:轻度梦境广覆盖摄入,REM 识别重复出现的模式,深度梦境对基础数据库里所有候选独立做精确评分,不要求碎片必须先被 REM 选中——REM/轻度的历史只是加分项。能进 MEMORY.md 的内容,需要在多天、多个不同场景下被反复用到,但这是评分门槛逼出来的结果,不是必须按顺序走完三关的硬性流程。
-
多维交叉验证:七个分量从不同角度防止”刷分”。相关度防低质量内容混入,查询多样性防单次对话刷分,跨天巩固防单日集中操作,近期活跃让长期无人问津的内容自然衰退,阶段加成给经过轻度和 REM 反复背书的内容额外加分。
-
读取即积累:每次检索不只是消费记忆,也在更新候选内容的升级评分。这条回路是整个系统闭环的关键——记忆越被使用,越容易在下一轮评分中晋升。
这套系统适合有稳定工作模式、经常在相似任务里反复用到同类知识的场景:项目规范、团队偏好、长期进行中的技术决策。工作模式高度随机、每次任务完全不同时,积累的效果会相应减弱。