 夜雨聆风
夜雨聆风





5-零基础学-OpenClaw-MCP一键完成文章精读与结构化总结
要知道在默认状态下的OpenClaw是无法直接读取微信公众号文章的。
内置的网页抓取工具会被微信的反爬机制拦截,每次都得手动复制全文粘贴进去,效率非常低。
试过几种方案都不够理想,直到找到一款开源的微信文章阅读器 MCP,配合 OpenClaw 的自动安装能力,全程用自然语言就能完成配置,不需要手动敲命令、不需要折腾环境。今天把完整的实操过程整理出来,对做内容创作、行业调研的朋友应该会很实用。
前置说明:需要先完成 OpenClaw 的基础部署与 IM 通道配置,还没搭建的可以回看前面的系列教程。
一、先搞清楚:为什么默认读不了公众号文章
很多人第一次尝试都会遇到同样的问题:直接把公众号文章链接发给 AI,得到的回复都是无法获取有效内容,建议截图或手动粘贴文本。
本质原因是微信公众平台有严格的反爬防护机制,普通的 HTTP 请求只能拿到页面框架,提取不到正文内容。内置的 web_fetch 工具没有针对微信做专项适配,自然无法正常解析。
想要解决这个问题,就需要专门的抓取组件来绕过反爬、结构化提取正文。而 MCP 就是把这套抓取能力封装成标准协议接口,让 AI 可以像调用内置工具一样直接使用。
二、选型:开源微信文章阅读器 MCP
在社区里对比了几个方案,目前完成度和稳定性都比较好的是 wexin-read-mcp 这个开源项目,地址:
https://github.com/Bwkyd/wexin-read-mcp
这是一个极简的 MCP 服务,核心能力就是让大模型能够正常读取微信公众号文章。它的技术实现非常扎实:
底层基于 url-md(Rust 开发的单二进制工具)处理反爬与正文提取,不需要依赖完整浏览器环境
自动提取标题、作者、发布时间、正文、封面图等完整元信息
返回内容为标准 Markdown 格式,完整保留标题层级、图片引用、列表结构
v0.3.0 版本进一步优化了抓取链路,单文件仅 7MB,启动速度快、资源占用极低
放在以前,要用上这类工具得自己拉代码、装依赖、改配置文件,对新手很不友好。但在 OpenClaw 的体系里,整个安装过程一句话就能完成。
三、一键安装:全程自然语言操作
这是最省心的地方。不需要 SSH 登录服务器,不需要敲任何命令行,直接在对话窗口把项目链接发给 OpenClaw 就行。
操作只有一步:把 GitHub 仓库链接发送给机器人,同时说明需求:
帮我安装这个微信文章阅读器的 MCP 服务
接下来 OpenClaw 会自动识别项目类型、下载源码、安装依赖、完成接入配置,整个过程不需要人工干预。安装完成后,机器人会主动告知使用方式:
💡 安装完成。后续你只需要发给我一篇微信文章链接,我会自动调用工具读取完整内容并按需分析。

四、实测效果:结构化输出文章总结
拿一篇机器之心的行业文章做测试,直接把链接丢进去,指令很简单:
帮我读取这篇文章,整理成结构化总结
大概十几秒就能返回结果,输出的是完整的 Markdown 格式总结,结构非常清晰:
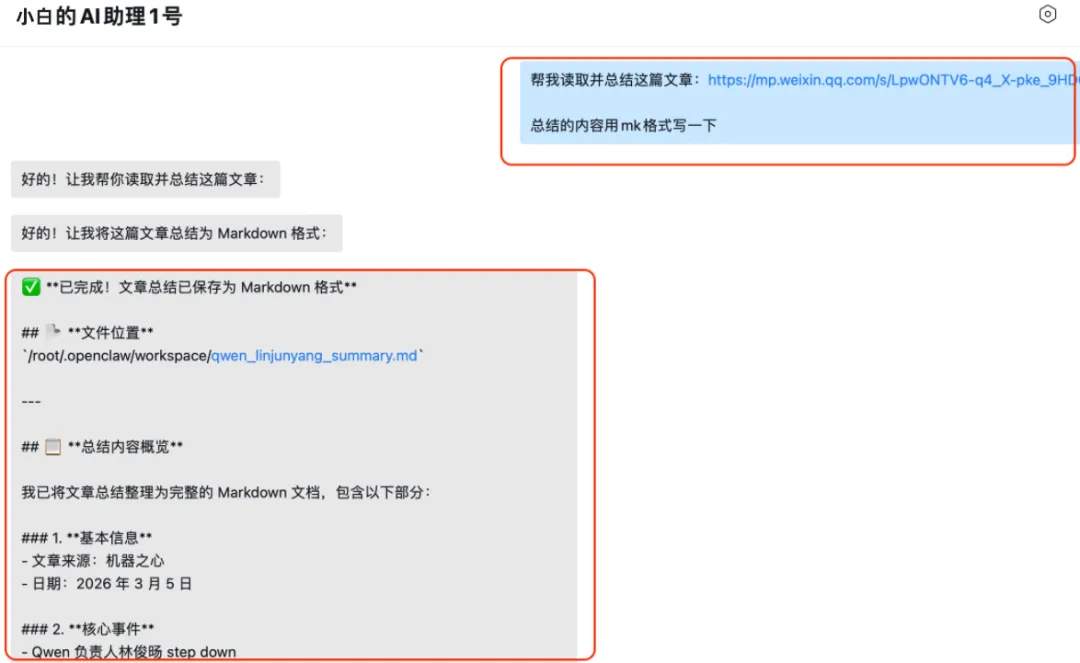
## 📋 **总结内容概览**我已将文章总结整理为完整的 Markdown 文档,包含以下部分:### 1. **基本信息**- 文章来源:机器之心- 日期:2026 年 3 月 5 日### 2. **核心事件**- Qwen 负责人林俊旸 step down### 3. **事件时间线**- 昨天:消息引发关注 + 林俊旸朋友圈回应- 今天:阿里 CEO 吴泳铭内部邮件回应### 4. **阿里官方回应**- 人事变动详情- 组织调整(成立基础模型支持小组)- 未来战略(坚持开源+加大投入)### 5. **关键要点**- Qwen 团队领导层变更- 阿里 AI 战略不变- 林俊旸个人表态### 6. **后续展望**- 林俊旸的未来去向- Qwen 的发展方向### 7. **影响分析**- 对 Qwen 团队- 对 AI 社区- 对行业### 8. **总结**- 一句话概括整个事件
写在最后
微信公众号可以说是中文互联网最重要的内容阵地之一,打通这个入口之后,OpenClaw 的信息处理能力才算真正落地到日常工作流里。
整个安装和使用过程几乎零门槛,不需要懂开发,不需要敲命令,跟着步骤走五分钟就能搞定。做内容、做研究、做行业分析的朋友都可以试试,能省下大量重复劳动的时间。