 夜雨聆风
夜雨聆风





AI 时代下软件保护对抗的现状与趋势
一、核心结论
AI 正在改变软件保护的攻防结构,但还没有让代码混淆、App Shielding、运行时保护失效。Promon 的 Q1 2026 报告给出的关键判断是:领先 LLM 已经具备一定反混淆能力,可以读取反汇编代码、分析程序逻辑并尝试恢复原始代码;但在真实移动 App 场景中,尤其是 ARM 架构和多层混淆叠加后,AI 的成功率仍会显著下降。
这意味着软件保护进入了一个新阶段:过去主要对抗人类逆向工程师的理解成本,现在还必须对抗 AI Agent 的自动化分析、批量试错和工具编排能力。保护目标不再只是“让人看不懂”,而是让 AI 的自动化破解链路变慢、变错、变贵,并迫使攻击者回到人工验证。
二、Promon 报告揭示的现状
1. AI 已经能攻击混淆代码,但能力高度受场景限制
Promon 测试了 10 个领先 AI 模型,对 OLLVM 混淆代码进行反混淆评估,覆盖 x86 与 ARM 两种架构,以及 raw assembly 和 Ghidra pseudocode 两种输入形态。结果显示,AI 对混淆代码确实构成现实威胁,但不是无条件成功。
在最强的三层混淆 SUB(指令替代) + FLA(控制流平坦化) + BCF(虚假控制流) 下,最强模型在 x86 架构上仍能以约 20%–36% 的成功率恢复可工作代码;但在 ARM 场景下,平均成功率降到 8.5%,多数模型只有个位数成功率。Promon 因此认为,ARM 移动 App 当前对 AI 反混淆有更强抵抗力。
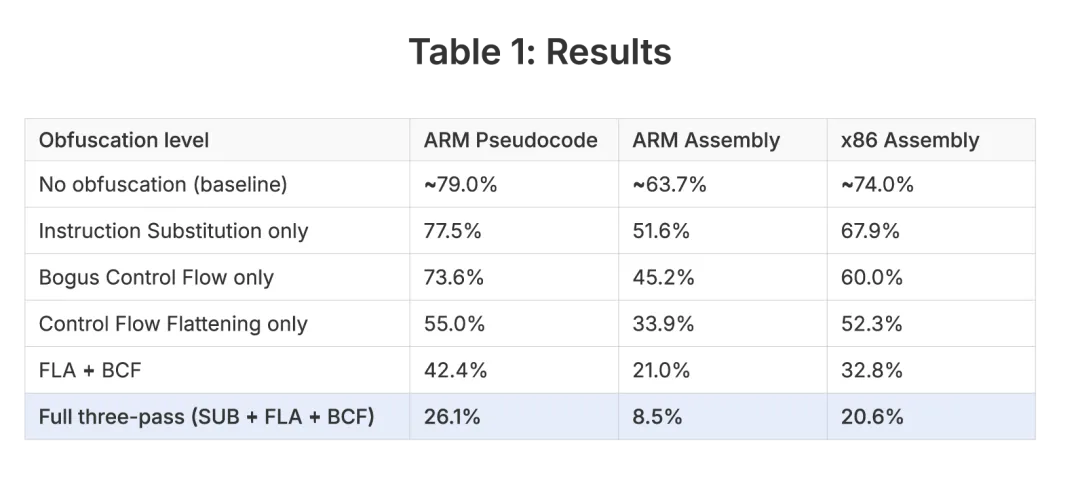
这对移动 App 保护是一个重要信号:AI 对软件保护的威胁已经真实存在,但现阶段仍强烈依赖架构、输入质量、混淆层数和模型能力。
2. 分层混淆仍然有效,而且效果不是简单相加
报告最重要的工程结论之一是:多种混淆技术组合后会产生乘法效应,而不是线性叠加。
Promon 特别指出,Control Flow Flattening 与 Bogus Control Flow 组合时,会显著放大代码结构复杂度。FLA 会生成中心调度器,BCF 再在这些调度点插入虚假分支,使控制流复杂度被放大。报告给出的数据是:相较单独 BCF,组合后复杂度在 x86 上放大 4.18x,在 ARM 上放大 5.50x。
这说明混淆并没有因为 AI 出现而失效。恰恰相反,面对 AI 自动化逆向,单点混淆会显得薄弱,而组合式、分层式混淆成为基本要求。
3. AI 工具有内生错误率,防守方可以利用这个弱点
Promon 一个很有启发性的发现是:AI 即使处理未混淆代码,也不是 100% 准确。报告称,没有模型在 clean code 上超过 86% 成功率;GPT-4o 在 clean x86 assembly 上只有 48% 成功率;clean ARM assembly 的平均成功率也只有 63.7%。
这改变了防守方对“AI 破解能力”的理解。攻击者并不是从 100% 准确率开始,再被混淆削弱;攻击者一开始就会产生大量错误输出。混淆的作用是把这种错误率进一步放大。
在真实攻击中,AI Agent 会批量处理一个 App 中成百上千个函数。只要输出中混入大量错误函数,攻击者就很难自动判断哪些恢复结果可信、哪些会导致逻辑错误。于是,攻击流程会被迫进入人工验证,自动化优势被削弱。
4. 反编译器质量会直接决定 AI 攻击效果
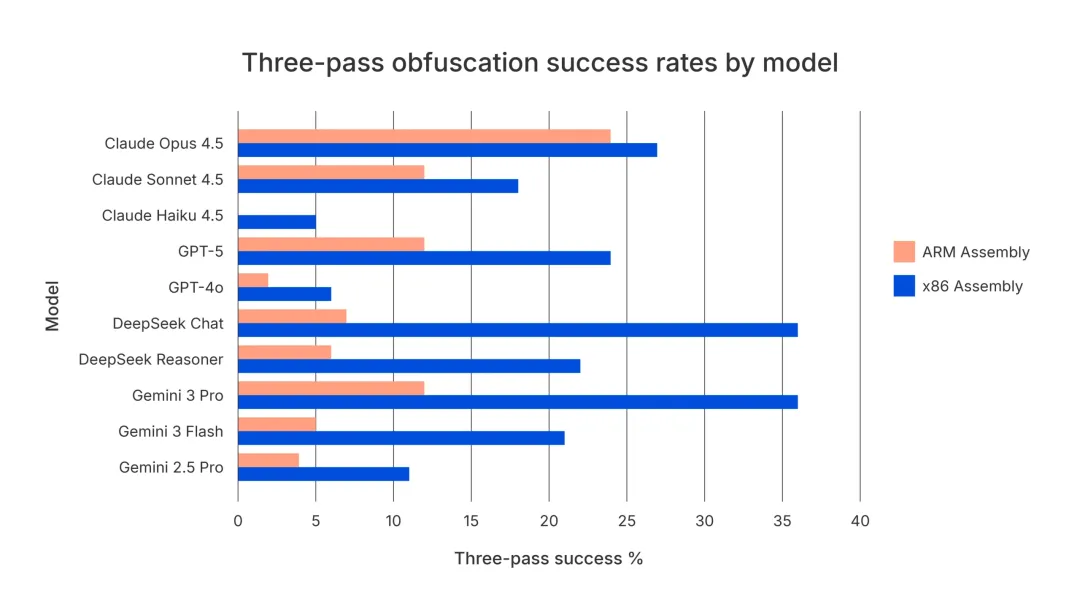
Promon 报告指出,AI 拿到 raw assembly 和拿到 Ghidra 生成的 pseudocode,成功率差异很大。以三层 ARM 混淆为例,Claude Opus 4.5 从 pseudocode 输入可达到 50% 成功率,但从 raw ARM assembly 只有 24%;GPT-4o 则是 10% 对 2%。
这说明 AI 不是独立完成逆向。它高度依赖上游工具提供的输入质量。反编译器越能生成清晰、结构化、接近 C 语言的伪代码,AI 越容易理解逻辑;反编译器输出越破碎、误导、类型错误、函数边界错误,AI 越容易产生错误推理。
这也是未来软件保护的重要方向:防守不只要混淆二进制本身,还要主动降低反编译器输出质量,也就是 anti-decompilation。
5. 不同 AI 模型的威胁等级差异很大
Promon 测试发现,模型能力差距明显。顶级模型在高强度混淆下仍保持一定成功率,而部分模型在三层 ARM assembly 场景下几乎失败。
因此,软件保护不能只看平均模型能力。对普通自动化攻击,可以参考平均成功率;但对金融、支付、游戏、流媒体、SDK、版权保护、企业软件和高价值算法,应该按顶级模型能力建模。攻击者一旦有足够收益,通常会选择更强模型、更好的反编译器和更完整的自动化流水线。
三、AI 时代软件保护的本质变化
1. 对手从“人类逆向者”变成“AI Agent 破解流水线”
传统软件保护假设攻击者是人类:打开 IDA、Ghidra、x64dbg、Frida,逐步理解关键函数,定位授权校验、反调试、Hook 检测、协议签名和业务限制点。防守方的策略是提高人的阅读成本、定位成本和修改成本。
AI 时代的对手模型不同。更现实的攻击者会构建一条流水线:
-
用反编译器批量生成 pseudocode。
-
用 LLM 总结函数语义、识别可疑路径。
-
用脚本和调试器验证 Hook 点。
-
用 Agent 记录失败原因并规划下一轮尝试。
-
用自动化测试环境验证补丁是否生效。
-
最后由人类确认关键路径和可变现方式。
人类不再逐行看代码,而是管理 AI Agent 的任务、结果和验证。这会显著降低攻击成本。
2. 保护目标从“隐藏逻辑”转向“破坏自动化闭环”
过去软件保护常追求“隐藏关键逻辑”。但 AI Agent 攻击更依赖闭环:观察输入、生成假设、修改或 Hook、运行验证、根据反馈调整策略。
因此,未来软件保护的目标应包括:
-
降低 AI 可读输入质量。
-
增加错误恢复结果的比例。
-
减少高信号反馈。
-
延迟关键校验结果。
-
让单点补丁无法证明成功。
-
把关键判断移到服务端和业务风控侧。
-
让攻击者必须跨模块、跨会话、跨设备、跨账号验证。
换句话说,保护不是追求绝对不可逆,而是让 AI Agent 无法低成本自动完成“理解-修改-验证-规模化”的闭环。
3. 客户端保护必须和服务端可信结合
AI 会让客户端逆向更高效,所以高价值逻辑不能只依赖客户端隐藏。授权、权益、支付、风控、内容访问、游戏经济、版权下载、SDK 调用资格等关键判断,应尽可能与服务端状态绑定。
更稳健的模式是:
客户端做混淆、完整性校验、反调试、反 Hook、反重打包、Root/Jailbreak 检测。
服务端做 App attestation、设备可信、账号风险、行为序列、授权状态和异常收益检测。
客户端保护负责提高攻击成本,服务端保护负责判断请求是否可信。
AI 时代的软件保护不应只看“二进制有没有被破解”,还要看“破解后的客户端能否持续获得业务收益”。
四、未来趋势判断
趋势 1:AI 反混淆能力会持续提升,ARM 当前优势不会永久存在
Promon 认为 ARM 当前比 x86 更抗 AI,一个重要原因是训练数据差异。公开互联网中 x86 反汇编、逆向文章、恶意软件分析资料更多,而 ARM 高质量逆向语料相对少。
但这个差距可能缩小。随着移动逆向、IoT、车载、边缘设备、ARM 服务器资料增多,模型对 ARM 的理解能力会提升。防守方不能把当前 ARM 优势当作长期护城河。
趋势 2:Anti-decompilation 会成为软件保护关键方向
Promon 报告显示,pseudocode 输入能显著提升 AI 成功率。因此,未来保护不会只做传统控制流混淆,还会更多针对反编译器:
-
破坏函数边界识别。
-
制造误导性类型信息。
-
让伪代码结构不稳定。
-
增加不可达但看似关键的路径。
-
让反编译输出语义与真实执行语义偏离。
这类保护的价值在于,它攻击的是 AI Agent 的上游输入质量。
趋势 3:软件保护会从静态保护转向动态、分层和服务端协同
单一混淆很难长期对抗 AI。未来更有效的是组合防护:
-
静态层:控制流混淆、指令替换、字符串加密、虚拟化保护。
-
反分析层:反调试、反 Hook、反模拟器、反 Frida、反重打包。
-
完整性层:运行时校验、代码段校验、资源校验、签名校验。
-
可信层:App attestation、设备绑定、密钥保护、远程证明。
-
业务层:账号风控、行为异常、权益校验、收益异常检测。
AI 迫使软件保护从“代码工程”升级为“代码 + 运行时 + 设备 + 服务端 + 业务”的体系工程。
趋势 4:保护评估会从人工渗透测试转向 AI 对抗基准测试
Promon 的方法本身也代表一个趋势:未来安全团队会定期用不同模型、不同反编译器、不同混淆配置测试保护效果。
评估指标也会变化:
-
AI 能否恢复可执行逻辑。
-
错误恢复比例是多少。
-
AI 能否定位关键授权路径。
-
AI 是否能生成有效 Hook 假设。
-
AI Agent 是否能完成自动验证闭环。
-
保护是否能让攻击者必须人工介入。
软件保护不再只问“能不能被人逆向”,而是问“顶级 AI Agent 在多少成本内能否规模化破解”。
趋势 5:防护设计会主动利用 AI 的弱点
未来有效的软件保护会更有意识地针对 AI Agent 的弱点设计:
-
针对上下文窗口有限:增加跨函数、跨模块、跨会话依赖。
-
针对模型依赖高质量输入:降低反编译器输出质量。
-
针对模型容易错误归因:设计诱饵路径和低信号失败。
-
针对 Agent 需要验证反馈:延迟、模糊或分散关键反馈。
-
针对批量自动化:让错误输出难以被自动筛除。
-
针对工具链依赖:检测调试器、Hook 框架、模拟器和重打包环境。
这不是“骗 AI”本身,而是系统性提高 AI 自动化攻击的成本。
五、对企业和产品团队的启示

第一,把 AI 反混淆纳入威胁模型。只按传统人工逆向能力设计保护,已经低估风险。
第二,把三层或多层混淆作为敏感逻辑保护基线。单点混淆在 AI Agent 面前容易被批量试探。
第三,移动 App 当前相对更有优势,但不要依赖 ARM 架构红利。模型训练数据会补齐,工具链也会进步。
第四,投入 anti-decompilation。AI 越依赖反编译器,破坏 pseudocode 质量越有战略价值。
第五,把客户端保护和服务端可信绑定。客户端负责抬高破解成本,服务端负责判断请求可信度和业务结果合理性。
第六,建立持续评估机制。每次模型能力、反编译器版本、保护配置变化,都可能改变攻防平衡。
六、结语
Promon Q1 2026 报告的真正价值,不是证明“AI 已经破解混淆”,也不是证明“混淆仍然安全”,而是把软件保护带入了可量化的 AI 对抗阶段。
AI 的出现改变了攻击成本结构。攻击者可以更快理解代码、更快生成假设、更快批量验证。防守方也必须改变目标:不再只对抗人类阅读,而是对抗 AI Agent 的自动化逆向流水线。
未来软件保护的竞争点,将不只是混淆强度,而是能否持续破坏 AI 的输入质量、推理稳定性、验证闭环和规模化能力。能做到这一点的软件保护,才是真正面向 AI 时代的保护。
参考来源
-
Promon, 2026, App Threat Report 2026 Q1: The State of Code Obfuscation Against AI -
Promon, 2025, AI powered mobile app attacks: What app shielding can and can’t stop