 夜雨聆风
夜雨聆风





AI 写代码 10* 更快,为什么软件只提升 1.6*?
——编码不再是瓶颈,工程系统正在成为新的上限
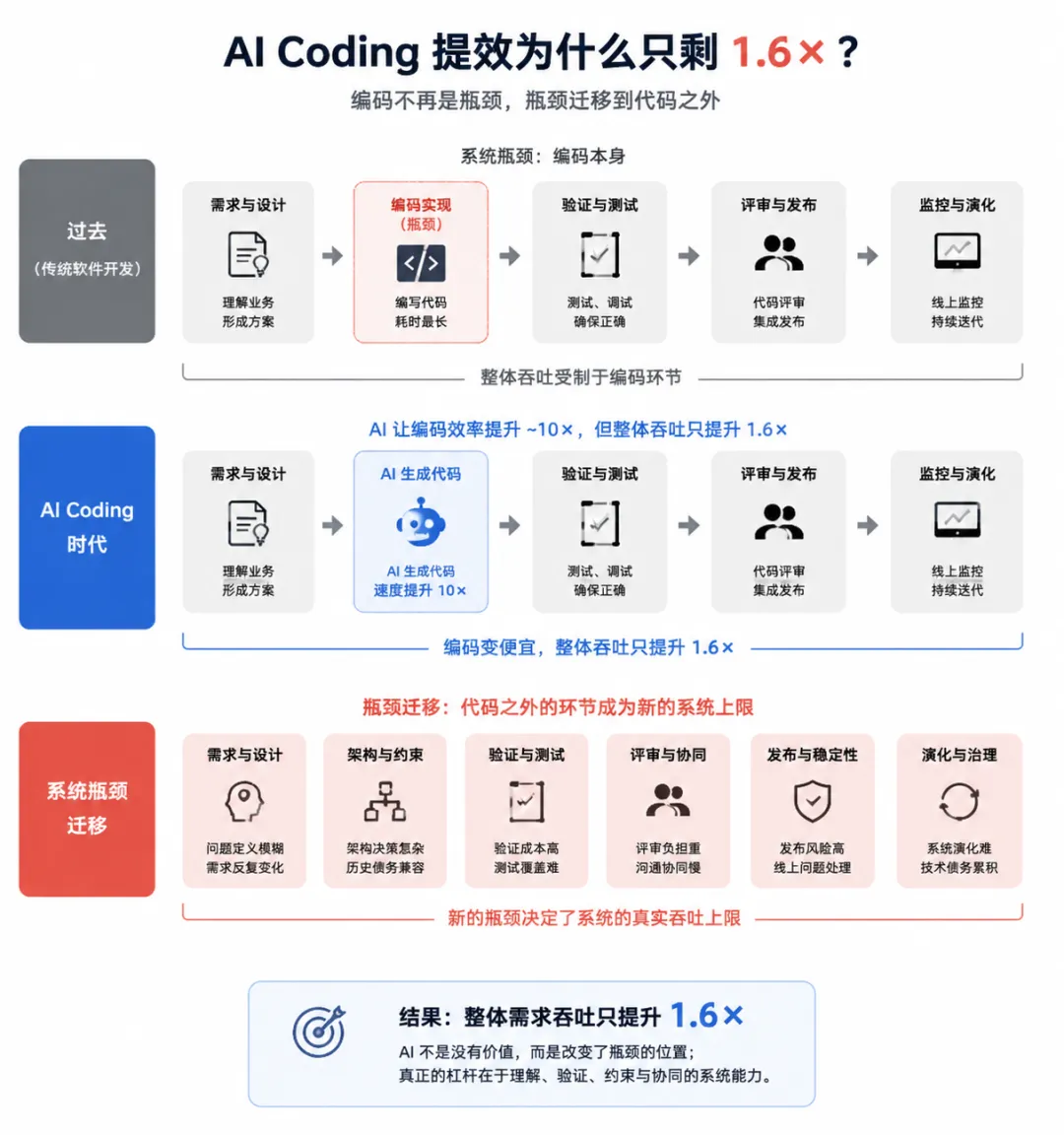
6 月 23 日,火山引擎 Force 大会上,字节跳动技术副总裁洪定坤分享了一组数据:TRAE 团队过去半年里,超过 90% 的代码由 AI 生成,但人均需求吞吐只提升了 1.6 倍。这个数字本身不算差,但问题在于——AI 写代码的速度至少是人的 10 倍,如果 90% 的代码都由 AI 产出,按直觉效率提升应该是几倍甚至一个数量级,而 10 倍和 1.6 倍之间有一个巨大的缺口。第一次看到这个结果时,我想到的是另一个时代的问题。
在《人月神话》中,Brooks 提出过一个后来被反复引用的判断:向已经延期的软件项目增加人手,只会让项目更晚完成。这个结论之所以重要,不是因为它反直觉,而是因为它揭示了一件事情——软件生产从来不是一个线性过程。今天,AI Coding 正在迫使整个行业重新认识这一点。
一、代码并不是软件生产的核心约束
过去一年,关于 AI 编码最常见的叙事方式是代码生成速度:模型一天生成多少代码,团队多少比例代码来自 AI,工程师平均消耗多少 Token。这些指标都有一个共同前提:默认认为代码编写是软件研发最昂贵的部分。但 TRAE 的数据恰恰反驳了这个前提——如果编码是瓶颈,那么编码速度提升 10 倍、AI 贡献 90% 代码之后,整体吞吐应该接近数量级增长,而实际只有 1.6 倍,这说明瓶颈根本不在编码。
洪定坤自己也坦诚地说,这些增长数字”不代表我们的 AI Coding 实践已经做得非常好”,反而”正因为用得越来越多,对挑战有了更真实的体感”。软件研发从来不是单纯的信息录入过程,真正复杂的部分往往发生在编码之前和编码之后。在编码之前,需要形成问题定义,需要理解业务约束,需要完成架构决策,需要判断哪些既有能力应该复用、哪些历史债务必须兼容;在编码之后,需要完成验证、测试、评审、发布、监控以及后续演化。代码只是这些约束最终显现出来的一种表达形式。
因此,当 AI 把编码成本降低到接近零时,整个系统不会自动获得数量级增长,而是会暴露出原本被编码成本掩盖的问题。瓶颈开始迁移:过去人们等待代码产生,现在人们等待代码被确认;过去人们优化生产能力,现在开始发现验证能力正在成为新的上限。从 1.6 倍这个数字来看,这个迁移已经在发生。
二、功能正确性不是工程能力,而只是进入工程的门槛
如果说第一节是宏观判断,那么接下来这组实验,是这个判断最直接的证据。洪定坤在分享中提到了一个实验:针对豆包一个中等复杂度的新功能——用户在创作页面创作视频并预览调整——他们选取 3 个主流 Coding 模型和 3 个主流 Agent 框架,两两组合,用相同的 Prompt 各跑 100 次,总计 900 次。

结果很值得玩味。只看功能正确性——代码能不能跑、功能基本对不对——所有组合的正确率都超过了 80%,单看这个数字,Vibe Coding 似乎已经可以交付了。但当他们进一步考察 UI 易用性、交互可行性、可靠性、可维护性、性能、兼容性这些真实上线必须过的关卡时,所有组合的得分相比正确率都出现了大幅下降,落在 40 到 60 分的不及格区间,而且随机性极强:有的异常处理不规范,有的不复用仓库已有组件,有的改动影响了历史功能,有的实现方式不符合团队工程规范。按真实业务上线的标准,这些结果距离交付都还有相当距离。
这个实验说明的事情,和过去一年 Vibe Coding 的主流叙事形成了鲜明对照。Vibe Coding 的叙事构造了一种理想状态:需求表达接近自然语言,实现由模型自动完成。这种设想对于边界明确、生命周期短的小规模软件,确实已经显示出惊人的效率。但大型软件系统之所以复杂,并不在于功能实现,而在于约束——系统为什么难维护,不是因为代码写不出来,而是因为任何一个局部变化都会影响既有结构,权限模型、服务边界、历史兼容、性能预算、数据一致性、安全要求、发布节奏,这些共同组成了工程现实。
当模型能够稳定生成功能时,一个新的问题开始出现:功能正确已经不再构成竞争力,决定质量的变成了约束表达能力——谁能把组织知识、架构规则、历史经验、工程规范编码进系统,谁就更容易获得稳定结果。这一点,洪定坤在分享中也给出了对照实验:当他们把被称为 Harness 的工程基建——上下文工程、架构约束、团队知识沉淀、技术债梳理——加进去之后,同样的 9 种模型框架组合,正确率从 80% 提升到接近 90%,但更显著的是可交付性,普遍从 40 到 60 分的不及格水平提升到了 80 分。

这个对照比任何观点都直接:决定交付质量的不是模型的生成能力,而是工程基础设施。上下文如何组织、知识如何沉淀、约束如何自动注入、验证如何自动执行、反馈如何重新进入系统——这些事情不显眼,但它们决定最终结果。如果没有这些基础设施,AI 带来的可能不是生产力,而是债务生产速度。
三、代码门槛降低以后,组织不会消失,只会重新形成
还有一个容易被忽视的变化。洪定坤讲了一个真实的场景:一个产品同学找到他,说自己最近有个需求,用 Vibe Coding 已经做出来了,页面能看,流程也能跑,但拿给研发看,研发说还得排期,可能还要几天。她不太理解:为什么不能直接给我代码仓库权限,我自己提交不就上线了?后来认真看了这段代码,发现虽然能跑,但性能不够好,扩展性没考虑,也有权限安全问题。
这个故事很能说明今天的新问题。AI 让产品、设计、运营各种角色都有机会把想法直接变成代码,这个变化有价值——沟通更直接,验证更快,不能简单地说”非工程师写的代码都不能用”。但另一方面,代码生成门槛下降,不代表系统复杂度下降,真实业务系统里,代码要放进既有架构,要和已有模块配合,要考虑性能、安全、兼容,所以也不能”谁写出来谁就直接上线”。
这背后是一个更深的变化。过去,代码能力天然形成组织边界——产品负责提出问题,研发负责实现,测试负责验证——这种边界不完全合理,但它稳定。而当 AI 让每个人都获得生成能力以后,这种边界开始瓦解,于是问题发生变化:不再是谁能写代码,而是谁能够承担系统责任。因为真正昂贵的部分仍然存在——需求之间会冲突,模块之间会耦合,性能会退化,安全问题会积累,架构会失控。
代码生成能力可以民主化,但系统责任不会。因此,未来的软件组织结构未必会因为 AI 而消失,反而可能重新集中——不是围绕编码能力集中,而是围绕约束制定能力集中。未来的挑战不在于让更多人能写代码,而在于让更多人的产出能够合理地进入统一的架构、规范和交付流程,这才是整体效率提升的真正杠杆。
四、AI Coding 真正改变的,不是程序员,而是软件工程的测量方式
最后回到那个 1.6 倍。洪定坤在分享中明确说,如果把 AI 代码贡献率、采纳率、生成量这些指标当成 KPI 去单纯优化,会”没有找到更好的全局优化方法”,他提出要关注三件事:指标、治理、协作。这个判断指向的,其实是一个更底层的问题:我们一直在用输入衡量输出。
过去衡量研发效率:代码量、工时、资源投入;今天开始增加:AI 占比、Token 使用量、生成速度。但这些指标的问题是一致的——它们量的都是”投入了多少”,不是”产出了什么”。真正值得观察的,也许仍然是那些老指标:交付周期是否缩短,线上质量是否提升,系统复杂度是否下降,团队协作是否更顺畅,维护成本是否降低。如果这些没有变化,那么无论生成多少代码,本质上都没有改变生产函数。
1.6 倍不是 AI 的失败,而是一面镜子——它照出的是,代码之外的那些环节,才是软件工程真正的重心。代码正在变便宜,理解、验证、约束、协同正在变贵,这不是 AI 编码时代的暂时现象,而是软件工程进入下一阶段之后的长期规律。