 夜雨聆风
夜雨聆风





发布60天评分 95 下载 9000+——这个 Obsidian AI插件自动把你的笔记变成知识库
今年 4 月 27 日,一个叫 Greener-Dalii 的开发者在 GitHub 上创建了 Karpathy LLM Wiki。
两个月后,这个插件拿到了 Obsidian 官方评分 95/100,社区插件市场下载量突破 9000,GitHub 163 颗星。对一个发布才 60 天的插件来说,这个增速有点吓人。
我装了 12 个 Obsidian AI 插件,最后只留了 3 个。LLM Wiki 是唯一一个让我觉得”这东西在帮我思考”的。
上个月我在写一篇关于本地大模型的文章,翻了自己过去三个月的笔记找素材。搜了 8 次关键词,开了 15 个标签页,最后发现漏了一条三个月前写的重要结论——它躺在某个叫”随手记”的文件里,文件名和内容毫无关系。
这就是笔记的悖论:你写得越多,找到东西越难。
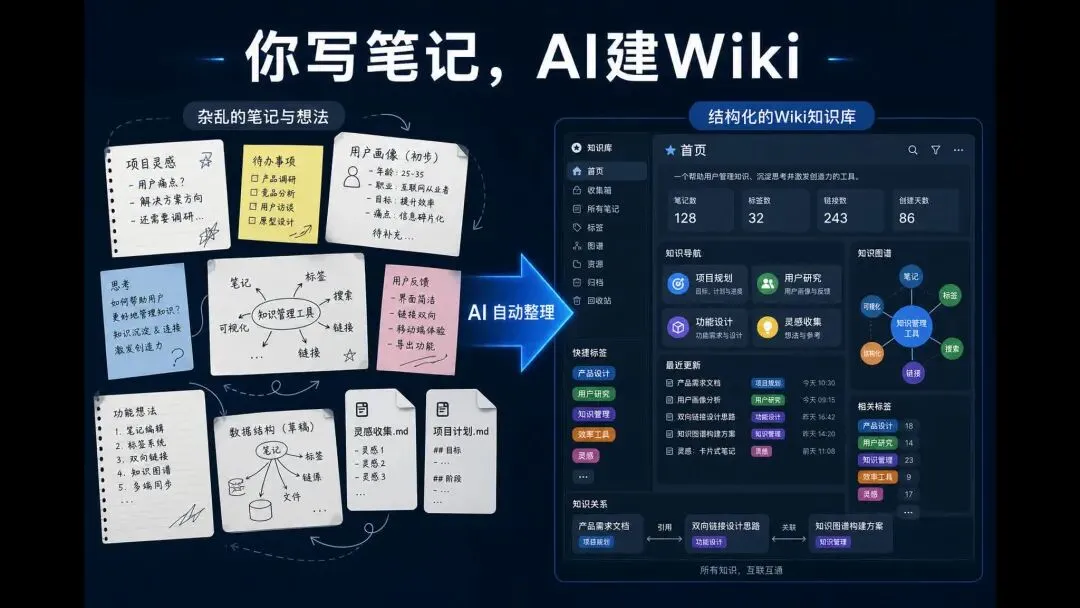
Karpathy LLM Wiki 做的事很简单:你写笔记,AI 帮你整理成 Wiki。你提问,它从你自己的知识库里找答案。12+ 种 LLM 提供商,10 种语言,完全可以在本地跑。
它跟其他 AI 插件有什么不一样?
Obsidian 的 AI 插件我基本都试过。大多数做的是同一件事:选中文字 → 调 API → 返回结果。本质上是个聊天框嵌在 Obsidian 里。
LLM Wiki 的思路完全不同。它不跟你聊天——它帮你建结构。
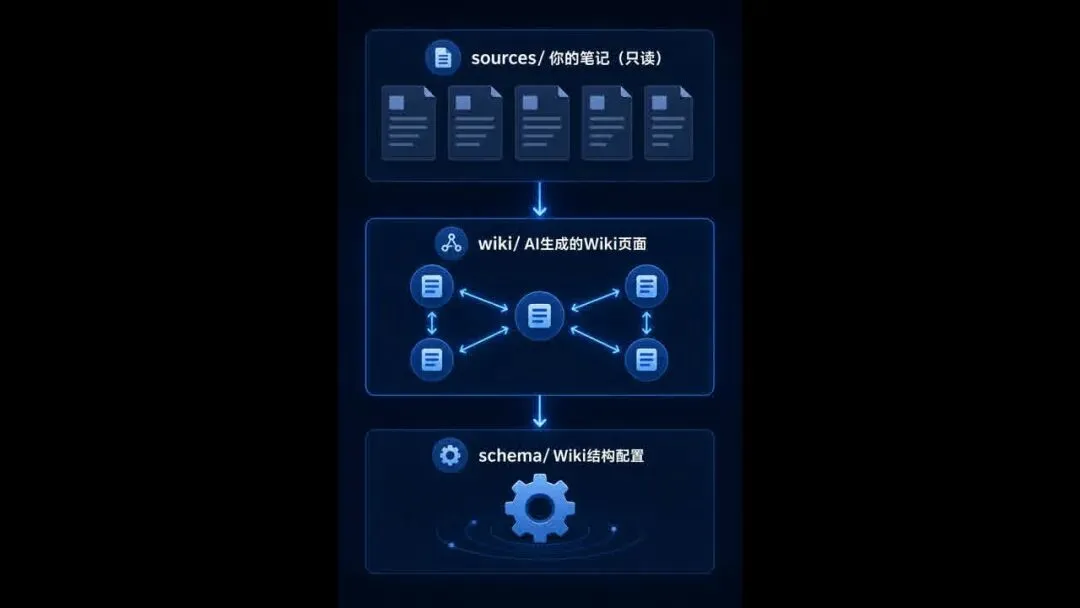
它的三层架构很清晰:
你把笔记丢进 sources/,剩下的不用管。AI 读你的内容,提取人物、概念、理论,生成独立页面,自动建立 [[双向链接]]。同一个笔记被多次摄入时,新信息合并进去,不重复;发现矛盾时标注来源,不覆盖。
我拿自己那篇本地大模型的文章试了一下。Fine 粒度提取了 47 个实体和概念,包括我写的时候根本没意识到的几个关联——比如”向量数据库”和”嵌入模型”被我分散在三篇不同笔记里,LLM Wiki 把它们连起来了。
实际用起来什么感觉?
摄入:拖进去就行
安装后在社区插件市场搜 “Karpathy LLM Wiki”,装好配好 API Key,就可以用了。
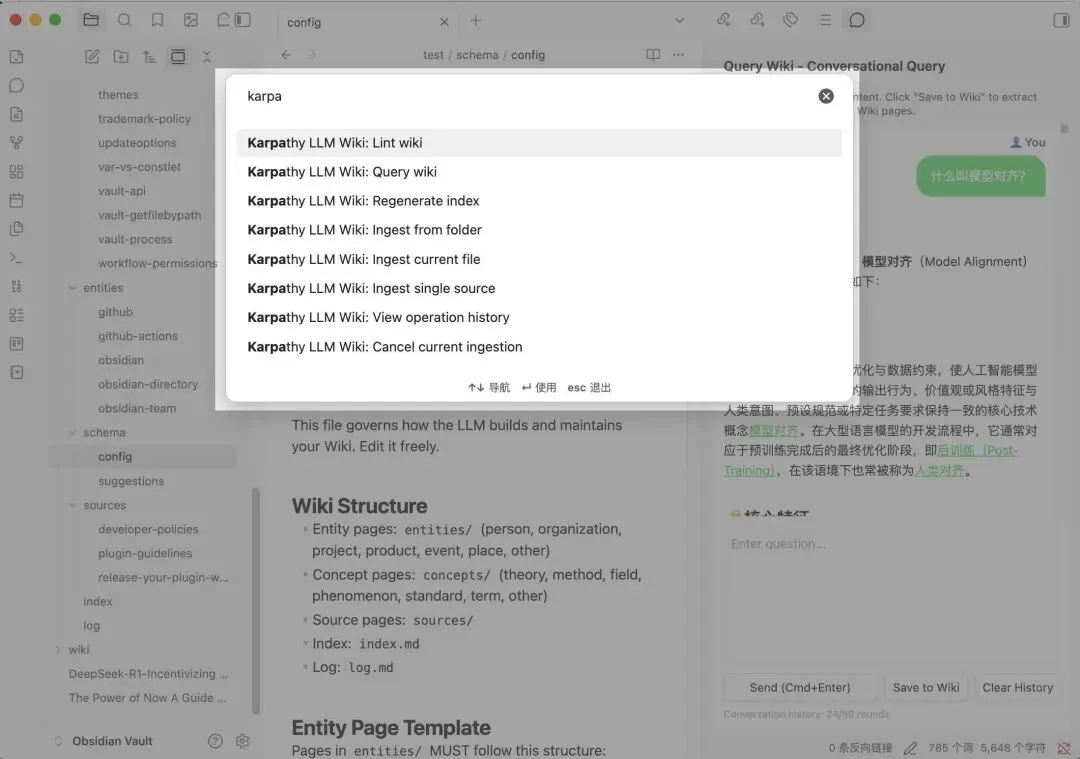
操作方式很直接:
Cmd+P → “Ingest single source”:摄入单篇笔记Cmd+P → “Ingest from folder”:批量摄入整个文件夹五档提取粒度从 Minimal(~5 条)到 Fine(~100 条),日常用 Standard(~50 条)就够了。大文件夹用 Coarse 省 token,重点文档用 Fine 深挖。
摄入同一篇笔记多次是增量更新,不会重复生成。Smart Batch Skip 自动跳过已处理的文件——这点很实用,不用手动记哪些已经摄入过了。
查询:问自己的知识库
Cmd+P → “Query wiki”,弹出一个对话窗口。跟 ChatGPT 的区别是:它只从你的 Wiki 里找答案。
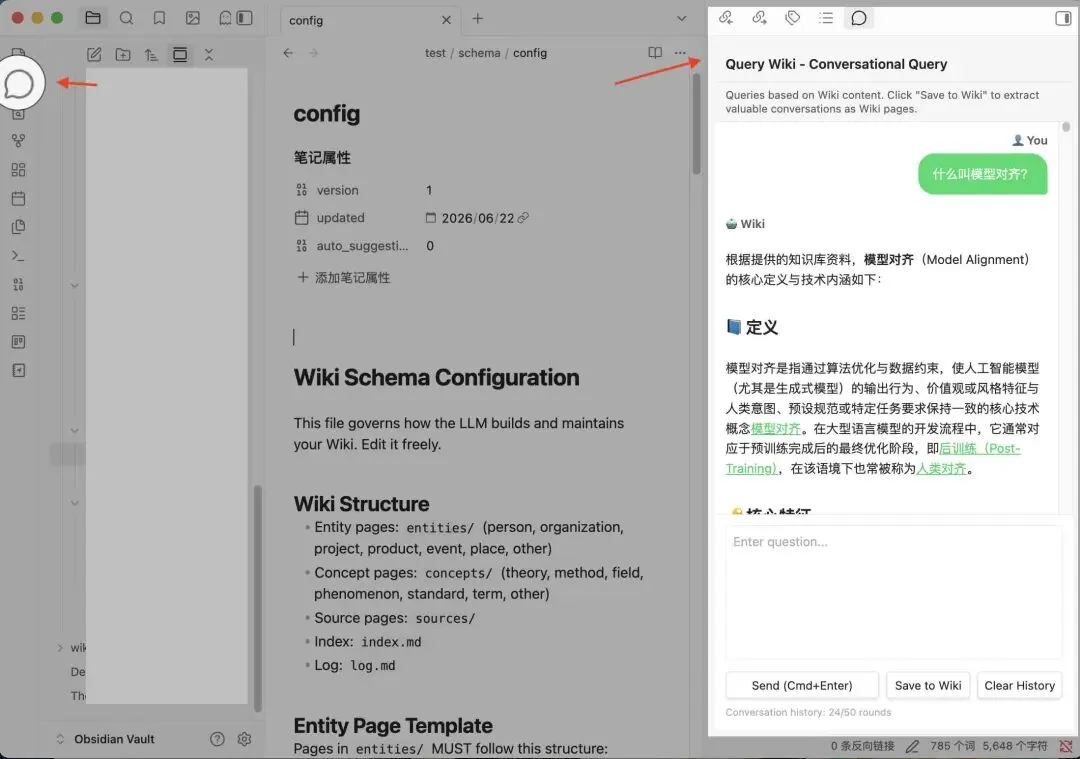
我问它”我写过哪些关于本地部署大模型的内容”,它列出了 6 篇相关笔记,每条带 [[wiki-links]] 可以直接跳过去。v1.22.1 之后查询窗口改成了右侧停靠面板,笔记和对话可以同时看,不用来回切换。
维护:一键体检
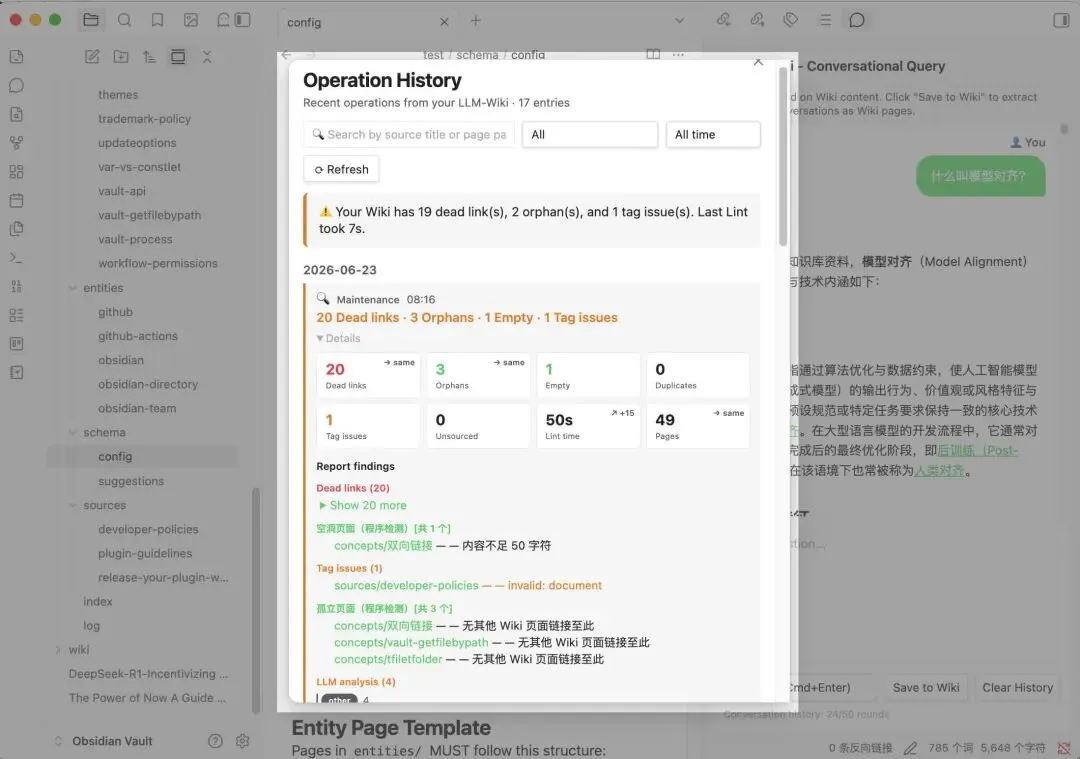
Cmd+P → “Lint wiki” 做全库健康检查:重复页面、死链、空页、孤立页、缺别名。Smart Fix All 一键按因果顺序修复——补别名 → 合并重复 → 修死链 → 链接孤立页 → 扩展空页。
操作历史面板(v1.21.0)记录了每次摄入和 Lint 的结果,可搜索可筛选。
模型怎么选?
插件遵循 Karpathy 的原始理念:喂完整 Wiki 上下文,不分块 RAG 检索。所以长上下文模型是刚需。
实际用下来,不需要旗舰模型。几个性价比方案:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
想完全本地?装 Ollama,拉一个 qwen3.5:27b,数据全程不出你的机器。
谁适合用?
不适合的场景:笔记少于 100 条(手动整理更快),或者只需要一个聊天框嵌在 Obsidian 里(Copilot 插件更轻量)。
几个实际提醒
API 成本。Standard 粒度摄入一篇 3000 字笔记大约消耗 15K-25K token。用 DeepSeek V4-Flash 的话,一篇不到一分钱。批量摄入 100 篇大概几毛钱。但用 Fine 粒度或 Claude Opus 成本会明显上去。
摄入需要时间。单篇 Standard 粒度大约 30-60 秒。并行生成可以开到 3-5 并发,2-3 倍提速。文件夹批量摄入建议开 Coarse 粒度先跑一遍,重点文档再 Fine。
本地模型有坑。小模型(7B 以下)容易对空白输入产生幻觉——v1.21.0 加了摄入前校验门,空文件和纯 frontmatter 笔记会被拦截。建议本地模型至少 14B 以上。
保持更新。这个插件更新非常频繁,v1.22.x 系列一周发了 4 个 PATCH。建议开启自动更新。
我和这个插件的两个月
5 月 7 日,我发了第一篇🦞 用 AI 维护你的 Obsidian 知识库:LLM Wiki 新手操作指南,那时候插件刚上线 10 天,功能还很基础。完读率 28.2%,说明很多人对这个概念感兴趣,但真正用起来的人不多——配置门槛摆在那。
6 月 13 日,我写了一篇最好的Obsidian移动端体验,不在手机App里——在微信里,打开率 23.86%,215 次分享。那次我意识到一件事:读者要的不是”怎么装这个插件”,而是”装完之后能干什么”。
今天这篇是第三篇。两个月过去,插件从 v1.0 迭代到了 v1.22.4,多了并行生成、Smart Fix All、摄入前校验门、右侧查询面板——每一样都是用户提了 issue 之后加上的。一个开发者,60 天,几十个版本。这种迭代密度在 Obsidian 插件圈里不多见。
LLM Wiki 不是那种”装了就完了”的插件。它需要你喂笔记、配模型、偶尔跑一下 Lint。但一旦 Wiki 长起来,搜索变成对话,笔记之间开始自动关联——那种”这东西在帮我思考”的感觉,是其他插件给不了的。
两个月,95 分,9000+ 下载。这个增速说明了一件事:用 Obsidian 的人,真的需要 AI 帮忙整理知识。
把这篇文章转给用 Obsidian 做知识管理的朋友 🤫

我是黑曜石,陪你打造第二大脑。一个发布 60 天的插件拿到 95 分,说明好工具不需要熬资历。
如果今天的内容对你有用:🔴 点亮「推荐❤️」 — 让更多 Obsidian 用户看到这个 95 分的插件📌 收藏 — 下次装插件时翻出来对照
评论区聊聊:你现在的 Obsidian 笔记有多少条?搜索还能找到想要的东西吗?
如果你无法访问 GitHub 或不会配置,后台回复「Wiki插件」,我把插件文件和配置指南发给你。