 夜雨聆风
夜雨聆风





从扫描件到可搜索文档
这篇教程围绕 OCRmyPDF 搭建了一套完整的 OCR 工作流,目标不是简单把图片识别成文字,而是把没有文本层的扫描 PDF 转换成可搜索、可提取、可长期保存的文档。它展示的重点包括:生成可测试的模拟扫描件、执行 OCR、输出 PDF/A、提取 sidecar text、验证识别结果,以及处理批量文件。
先搭环境,再造测试样本
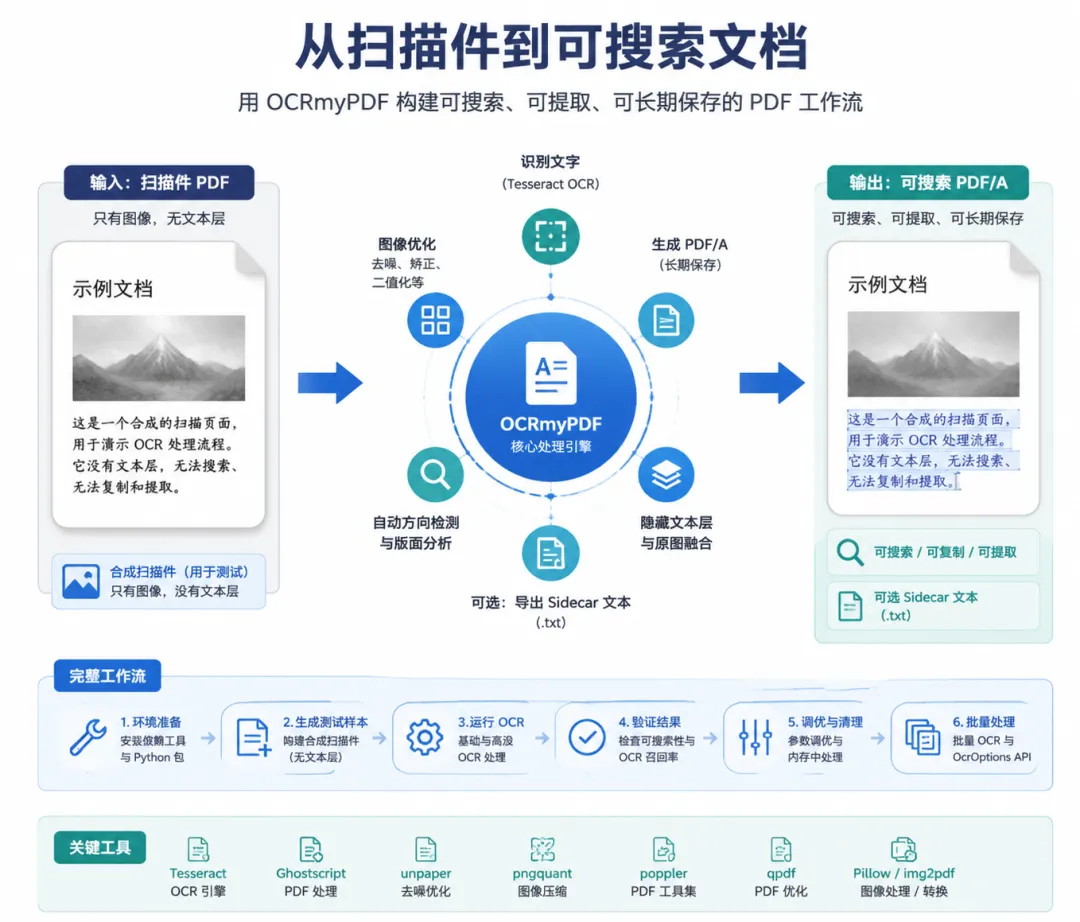
教程一开始先在 Google Colab 中准备运行环境,安装了 Tesseract、Ghostscript、unpaper、pngquant、poppler、qpdf 等系统工具,同时安装 OCRmyPDF、img2pdf、Pillow 等 Python 包。为了让演示不依赖外部素材,作者还生成了一个“只有图像、没有文本层”的合成扫描 PDF,用来模拟真实扫描件。
这种做法的好处很明显:既能验证 OCRmyPDF 的实际行为,也能在不同功能之间做对照测试,比如比较 OCR 前后的文件大小、文本恢复效果和输出格式。
OCRmyPDF 的核心流程

教程使用 OCRmyPDF 的公开 API 处理扫描 PDF,并分别演示了基础 OCR 和高级 OCR 流程。高级流程中加入了 PDF/A 输出、图像优化、sidecar text 生成和文档元数据写入等能力。
这里的重点不只是“识别文字”,而是把一份扫描文档整理成更适合归档和检索的标准化文件。PDF/A 的加入,意味着输出更接近长期保存场景的要求;sidecar text 则便于后续做搜索、索引或进一步的数据处理。
如何验证识别结果
为了确认 OCR 真的把文本“找回来了”,教程会从 sidecar text 中读取识别结果,也会用 pdftotext 从输出 PDF 中提取嵌入文本,再与原始样本文本进行对比。文章还用一个简单的 word-recall 指标,粗略衡量 OCR 恢复了多少原文内容。
此外,教程还检查了 PDF 结构、PDF/A 标记和文件大小,帮助读者判断输出是否符合预期。这一步很重要,因为 OCR 流程的目标不仅是“看起来能打开”,还要能在后续系统里稳定使用。
处理不同质量的扫描件

教程还展示了几类常见的生产环境问题。比如:
- 通过设置 Tesseract 的
ocr_engine_mode和page_segmentation_mode,微调识别策略; - 使用
unpaper清理噪声较多的扫描页; - 开启自动旋转和方向校正;
- 给单张图片显式指定 DPI,再转换成可搜索 PDF;
- 用
BytesIO在内存中完成 OCR,避免依赖磁盘中间文件。
这些功能说明,OCRmyPDF 不只是一个“批量转文字”的工具,更像是一个可嵌入自动化管线的文档处理组件,能够适配不同质量、不同来源的输入。
已有 OCR 文件与批处理
教程也考虑了现实中的重复处理场景。对于已经包含文本层的 PDF,它演示了 skip-text、redo-OCR 和 force-OCR 等模式,分别对应跳过、重新识别和强制重做三种策略。这样就能根据文件状态,避免重复劳动或覆盖错误结果。
在此基础上,作者进一步把流程扩展到文件夹级批处理:先生成多个输入 PDF,再逐个输出到指定目录。最后还尝试了较新的 OcrOptions 类型化 API,用结构化配置对象来传递 OCR 参数,让调用方式更清晰,也更适合工程化集成。
总结
整体来看,这篇教程展示的不是单点 OCR 功能,而是一条完整的文档数字化路径:从模拟扫描输入、OCR 识别、PDF/A 归档、文本提取,到质量验证、图像清理、内存处理和批量执行,OCRmyPDF 都提供了相对成熟的支持。对需要处理扫描件归档、全文检索或自动化文档管线的场景来说,它是一个实用度很高的工具。
更多相关文章,可查看合集:AI 科技前沿