 夜雨聆风
夜雨聆风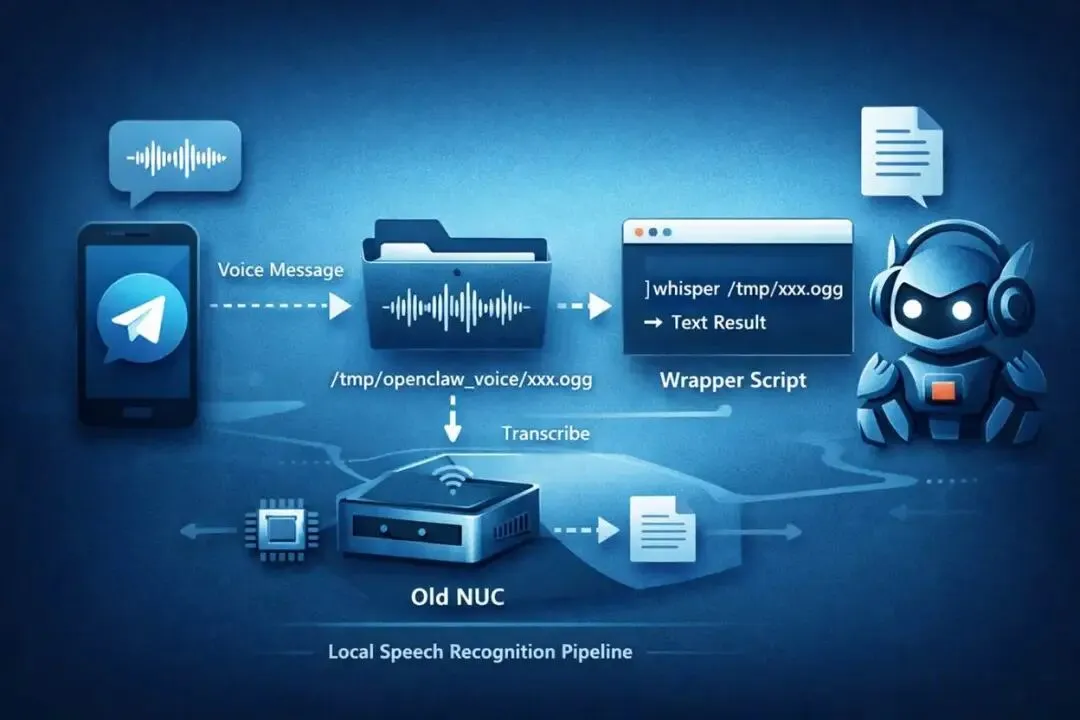
一、安装背景
装完小龙虾之后,的确感觉很方便,像是有了一个24小时的小助理,有点什么事情,吩咐它一声就好,尤其是生活中一些琐碎的小事,比如一些待办事项啊,等等,再也不会忘记了。
不过用了一阵子之后,感觉还是不够方便,主要是有时候不方便在手机上打字。于是,我就想,要不给小龙虾装个语音识别工具吧,这样以后只要对它说话就可以了,尤其是在忙前忙后的时候,掏出手机打字总不如说句话方便。
鉴于这个小龙虾已经能干不少事情了,于是我就给它下了一条指令:你自己装一个语音转文字的Skill。小龙虾回复我:好的,不过需要你先装一个homebrew。这个我没权限装,需要你来装。
啥是Homebrew?我上网一搜,这玩意原来是Mac OS需要的,而我的小龙虾是跑在NUC + Windows + WSL2上,不需要Homebrew。看来,网上相关教程都是Mac环境,以至于小龙虾默认自己是生活在Mac中。哈哈,不好意思,没那么高大上,你的主人很抠门,给你的屋子是一台13年前的NUC。
算了算了,小龙虾还是不靠谱,自己装吧。我搜了一下,发现几点:
1.在NUC上装语音识别,如果需要Telegram自动识别,需要写一个Wrapper。
2.针对NUC这个环境,不建议安装Openai-whisper,因为我的NUC的CPU是13年前的型号,实在太慢了。应该选择faster-whisper,用CTranslate2做CPU加速推理,在我的NUC上跑起来会快很多。
3.Faster-whisper还有个好处,就是不像openai-whisper那样要求系统里安装FFMpeg,因为它用 PyAV 来解码音频并随包带上了 FFmpeg 库。对一台 CPU NUC 来说,这会省很多麻烦。
二、安装过程
2.1安装环境
先装需要的环境
python3 -m venv .venv
source .venv/bin/activate
pip install -U pip wheel setuptools
pip install faster-whisper
2.2测试一下
在写wrapper之前,先测试一下能否跑通。新建一个test_whisper.py:
from faster_whisper import WhisperModel
model = WhisperModel("small", device="cpu", compute_type="int8")
segments, info = model.transcribe("test.mp3", beam_size=5)
print("language =", info.language, "prob =", info.language_probability)
for seg in segments:
print(f"[{seg.start:.2f} -> {seg.end:.2f}] {seg.text}")
尝试运行一下:python test_whisper.py,搞定,下一步就是写wrapper。
2.3写一个wrapper
一个 wrapper 可以长这样,输出纯文本,方便OpenClaw 调:
#!/usr/bin/env python3
import sys
from faster_whisper import WhisperModel
def main():
if len(sys.argv) < 2:
print("Usage: transcribe.py <audio_file>", file=sys.stderr)
sys.exit(1)
audio_file = sys.argv[1]
model = WhisperModel(
"small",
device="cpu",
compute_type="int8",
)
segments, info = model.transcribe(
audio_file,
beam_size=5,
vad_filter=True,
)
text = " ".join(seg.text.strip() for seg in segments).strip()
print(text)
if __name__ == "__main__":
main()
保存成 transcribe.py,给执行权限:chmod +x transcribe.py。
调用方式:./transcribe.py your_audio_file.mp3
2.4:语音处理架构
wrapper脚本写好之后,我发语音后,小龙虾接受音频文件,然后把文件路径发给 agent;agent调已经写好的 wrapper,返回转写文本。
当然,这里还有个后续问题:这个语音文件需要每次都存储么?答案是:不需要长期存储。对语音转写这种用途,临时文件 → 转写→ 删除是更合理的模式。首先是存储问题,Telegram 语音通常是 OGG/Opus,每条几十 KB 到几百 KB。如果长期运行bot,时间长了会堆出很多无用文件。没有保留价值。其次隐私。语音消息往往包含个人内容,自动删除可以减少不必要的保留。最后是实现简单。faster-whisper只需要在转写时读取文件,不需要持续访问。
流程是这样的
Telegram 下载语音到临时目录,例如
/tmp/openclaw_voice/xxx.ogg
- wrapper 转写:
transcribe.py /tmp/openclaw_voice/xxx.ogg
- 转写完成后删除:
rm /tmp/openclaw_voice/xxx.ogg
在 Python wrapper 里添加自动删除:
import os
from faster_whisper import WhisperModel
def transcribe(audio_file):
model = WhisperModel("small", device="cpu", compute_type="int8")
segments, _ = model.transcribe(audio_file)
text = " ".join(seg.text for seg in segments)
os.remove(audio_file)# 转写后删除
return text
2.5一个我踩过的坑
当我第一次运行:pip install faster-whisper的时候,系统报错: error: externally-managed-environment。
我搜素了一下发现因为较新的Ubuntu启用了PEP 668 机制。系统自带的 Python 被标记为“受管理环境”,不允许直接用pip 往里面装第三方包,以免破坏系统依赖。怎么办呢?解决办法是用 virtual environment(venv)。venv 的本质是:在系统 Python 之外,创建一套“隔离的 Python 环境”,所有依赖只装在这里,不影响系统。这样就可以避免触发PEP 668 限制,而且不污染系统环境,不同项目之间互不干扰。
安装步骤如下:
先确保系统支持 venv:
sudo apt update
sudo apt install -y python3-venv python3-full
然后创建一个独立环境(例如放在当前目录):
python3 -m venv .venv
source .venv/bin/activate
激活后,终端前面会出现:
(.venv)
接下来再安装依赖:
pip install -U pip wheel setuptools
pip install faster-whisper
这时候就不会再出现externally-managed-environment 错误了。
而且以后运行 wrapper 或任何相关Python 脚本,都必须先激活 venv:
source .venv/bin/activate
python transcribe.py xxx.ogg
三、实际使用体验
运行了几周后,这个方案的稳定性远超预期。原本担心 13 年前的CPU 会让响应变得迟钝,但在 int8 量化加速下,短语音的转写几乎是秒回。
这种“动口不动手”的交互,极大地填补了我日程中的碎片时间。最典型的场景是,当我步履匆匆地穿梭于各个会议室之间,脑子里突然蹦出一个灵感或一项急需跟进的待办,我不再需要停下脚步、掏出手机、顶着屏幕打字,而是直接对着 Telegram 留下一句语音。小龙虾会默默地在后台完成转写、提取关键点,并把它们分门别类地归档。
更重要的是,这一切都在我自己的本地环境下运行。看着这台被时代淘汰的老 NUC 重新焕发活力,真让我有一种物尽其用的成就感。
