 夜雨聆风
夜雨聆风一句话摘要:RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大模型在回答问题前先「查资料」的技术——如果说 LLM 是一个满腹经纶但与世隔绝的学者,RAG 就是帮他接通了整个图书馆的光纤网络。
1. 概述
1.1 什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大模型在回答问题前先「查资料」的技术。别看名字唬人,原理很朴素:与其让 AI 凭记忆硬编答案,不如让它先翻翻书再开口——毕竟,开卷考试的成绩总比闭卷好。
2020 年,Meta AI(当时还叫 Facebook AI)的研究团队在论文 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" 中正式提出了 RAG 框架。他们发现一个尴尬的事实:大模型虽然博学,但它的「记忆」冻结在训练截止日。你问它今天的新闻,它只能给你一个充满自信但完全过时的回答。于是他们想:能不能让模型在回答前先「Google 一下」?
你可以把 RAG 想象成一个学霸参加知识竞赛——不是死记硬背所有答案,而是随身带着一个超级搜索引擎。主持人问问题,学霸先搜一下相关资料,再组织语言回答。又快又准,还不容易胡说八道。
💡 人话翻译:RAG 就是让 AI 回答问题前先查资料,查完再答,这样答案更靠谱。
1.2 解决了什么问题?
在 RAG 出现之前,世界是这样的:
• 知识过时:大模型的知识冻结在训练截止日,无法获取最新信息。你问它 2024 年的诺贝尔奖得主,它可能给你编一个不存在的名字——还特别自信 • 幻觉泛滥:没有外部知识兜底时,LLM 会"一本正经地胡说八道"(Hallucination),生成看似合理但完全虚构的内容 • 领域盲区:企业内部知识(产品手册、内部 Wiki、客户数据)从未出现在训练集中,模型对此完全空白
然后,RAG 带着它的「检索+生成」双引擎出现了——
它让 LLM 在生成回答前,先从知识库中检索最相关的文档片段作为上下文,再基于这些「有据可查」的材料生成答案。知识实时更新、回答有引用来源、幻觉率大幅降低,还不需要重新训练模型。
1.3 核心优势
| 知识实时更新 | ||
| 减少幻觉 | ||
| 成本效率高 | ||
| 可溯源可审计 |
2. 核心概念
🗺️ 进入正题之前,先装备好这些概念——否则后面的内容会像没有字幕的外语电影。
2.1 Embedding(向量嵌入)
定义:Embedding 是将文本(词、句子、段落)映射为高维实数向量的过程,使得语义相近的文本在向量空间中距离更近。
直觉:你可以把它想象成给每段文字分配一个「GPS 坐标」——内容意思越接近的文本,坐标越靠近。"今天天气不错"和"今日阳光明媚"的坐标几乎重合,而"量子力学入门"则在地图的另一端。
示例:使用 OpenAI 的 text-embedding-3-large 模型,一段 500 字的产品说明会被编码为一个 3072 维的浮点数向量。这个向量不可读,但包含了该文本的完整语义信息。
2.2 向量数据库(Vector Database)
定义:向量数据库是一种专门为高维向量数据设计的存储和检索系统,支持基于近似最近邻(ANN, Approximate Nearest Neighbor)算法的高效相似度搜索。
直觉:传统数据库用 SQL 精确匹配("找 ID=42 的记录"),向量数据库用"距离"做模糊匹配("找和这段话意思最像的 10 条记录")。
示例:Pinecone、Milvus、Qdrant、Weaviate 是目前主流的向量数据库。以 Milvus 为例,它可以在 10 亿条向量中 50ms 内返回 Top-10 最相似结果,使用 HNSW 索引时召回率达 95%+。
2.3 Chunking(文本分块)
定义:Chunking 是将长文档拆分为适合 Embedding 和检索的短文本片段的过程,分块策略直接影响检索质量。
直觉:如果整本《三体》是一个文档,你不可能把它整本扔进向量数据库——搜索精度会极差。你需要按章节、段落甚至语义单元拆开,让每个片段足够聚焦、语义自洽。
示例:一份 50 页的技术文档,按 500 tokens 一块进行递归字符分块(Recursive Character Splitting),最终生成约 200 个 chunk,每个 chunk 独立编码为向量。
2.4 Reranker(重排序器)
定义:Reranker 是在初步检索(粗召回)之后,使用更精细的模型对候选文档进行二次排序的组件,通常采用 Cross-Encoder 架构。
直觉:向量检索是「初选」(速度快但不够精准),Reranker 是「复审」(速度慢但排序精准)。先海选 100 个候选,再精挑细选出最好的 5 个。
示例:Cohere Rerank v3、BGE-Reranker-v2 等模型可以将 Top-100 的初步检索结果重新排序,使最相关的文档排到前面,通常能将 NDCG@10 提升 15%~30%。
2.5 术语表
📖 以下术语将在全文反复出现,建议先混个眼熟。
3. 架构设计
🏗️ 本节拆开引擎盖,看看 RAG 系统内部长什么样。
3.0 技术栈一览
3.1 整体架构
RAG 系统的设计哲学可以用一句话概括:用「检索」弥补「记忆」的不足。LLM 的参数存储了海量通用知识(静态记忆),但缺乏领域专有知识和最新信息。RAG 通过在推理时动态注入检索到的外部知识,实现了「开卷考试」模式——模型的能力不变,但信息来源从「大脑记忆」扩展到了「整个知识库」。
这种设计带来了一个精妙的工程 trade-off:用推理时间换知识覆盖度。每次推理多花几百毫秒做检索,换来的是对数十万文档的实时访问能力——这比重新训练模型的成本低了好几个数量级。
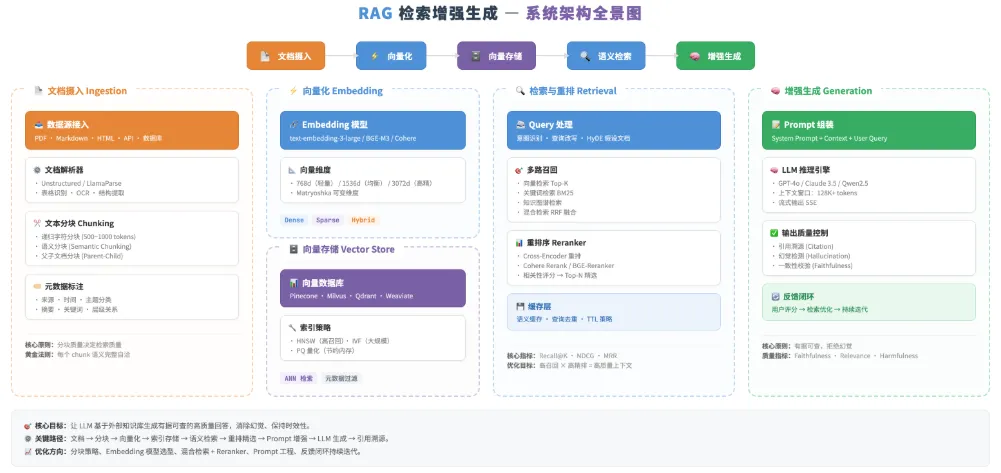
图 1:RAG 检索增强生成系统架构全景图——从文档摄入到增强生成的端到端数据流
图中关键路径解读:
1. 文档摄入管道(左侧橙色区):原始文档经过解析、分块、元数据标注后,进入向量化阶段。分块质量是整个系统的地基 2. 向量化与存储(中左区):文本 chunk 通过 Embedding 模型编码为高维向量,写入向量数据库并建立 ANN 索引 3. 检索与重排(中右蓝色区):用户查询经过意图识别和查询改写后,通过多路召回(向量 + BM25 + 知识图谱)获取候选文档,Reranker 精排后输出最终上下文 4. 增强生成(右侧绿色区):检索结果与用户问题组装成 Prompt,送入 LLM 生成带引用的回答,并通过质量控制模块检测幻觉和一致性
🔍 架构设计的精妙之处:RAG 系统将「知识存储」和「知识运用」解耦为两个独立可优化的子系统。存储侧可以无限扩展(加文档不需要改模型),运用侧可以灵活升级(换 LLM 不需要重建索引)。这种解耦是支撑 RAG 在企业场景大规模落地的关键。
3.2 核心模块详解
模块 1:文档摄入管道(Ingestion Pipeline)
角色定位:整个系统的「粮仓入口」——进什么粮,出什么面
• 职责:接收多格式原始文档(PDF、Markdown、HTML、数据库记录),解析为纯文本,按策略分块,标注元数据后输出结构化的 chunk 序列 • 输入/输出:原始文档 → [{text, metadata, chunk_id}, ...]• 核心机制:递归字符分块为基础策略,辅以语义分块(Semantic Chunking)和父子文档分块(Parent-Child)处理复杂文档
模块 2:向量化引擎(Embedding Engine)
角色定位:语义世界的「翻译官」——把人类语言翻译成数学语言
• 职责:将文本 chunk 和用户查询统一编码为相同维度的稠密向量 • 输入/输出:文本字符串 → 浮点数向量(如 1536 维) • 核心机制:基于预训练的双编码器(Bi-Encoder)模型,Query 和 Document 独立编码,通过余弦相似度衡量语义距离
模块 3:检索与重排(Retrieval & Reranking)
角色定位:知识图书馆的「首席检索员」——快速找到最相关的那几页
• 职责:接收用户查询向量,从向量数据库中召回 Top-K 候选文档,通过 Reranker 精排后输出 Top-N 最相关片段 • 输入/输出:用户查询 → Top-N 个 {text, score, source}文档片段• 核心机制:混合检索(Dense + Sparse)→ RRF 融合 → Cross-Encoder 重排
模块 4:增强生成引擎(Augmented Generation)
角色定位:最终的「答题手」——基于检索证据生成有据可查的回答
• 职责:将检索到的上下文与用户问题组装为 Prompt,调用 LLM 生成结构化回答,并附带引用来源 • 输入/输出: {query, contexts[]}→{answer, citations[], confidence}• 核心机制:System Prompt 约束 + In-context Learning + 引用格式化
3.3 模块交互
一个典型请求的旅程:
用户输入 "RAG 系统如何处理 PDF 文档?"——查询首先被送到 Embedding 引擎编码为 1536 维向量,然后同时触发两路检索:向量数据库的 ANN 检索返回语义最近的 Top-50 候选,BM25 引擎返回关键词匹配的 Top-50 候选。两路结果经 RRF(Reciprocal Rank Fusion)融合为统一排序列表后,送入 Cross-Encoder Reranker 做精细排序,最终取 Top-5 最相关片段。这 5 个片段连同原始查询一起组装成 Prompt 模板,送入 LLM 生成回答。生成后的输出还会经过幻觉检测模块校验——如果回答中有任何内容无法在检索上下文中找到依据,系统会标记为低置信度。
4. 工作原理
⚙️ 架构告诉我们「长什么样」,原理告诉我们「怎么转起来的」。
4.1 离线索引流程
RAG 系统的数据准备分为离线索引和在线检索两个阶段。离线索引是一次性(或定期增量)的预处理过程,将知识库中的文档转化为可检索的向量索引。

图 2:离线索引流程——从原始文档到可检索的向量索引
各步骤详解:
1. 文档解析:使用 Unstructured 或 LlamaParse 将 PDF、DOCX、HTML 等多格式文档统一转为纯文本。表格、图片说明、代码块需要特殊处理 2. 文本分块:按照预设策略(递归字符 / 语义 / 父子文档)将长文本拆分为 500~1000 tokens 的 chunk,确保每个 chunk 语义完整 3. Embedding 编码:每个 chunk 通过 Embedding 模型(如 text-embedding-3-large)编码为高维向量4. 写入向量数据库:向量与对应的原始文本、元数据一起写入向量数据库,建立 HNSW 或 IVF 索引
4.2 在线检索-生成流程
在线阶段是用户每次提问时的实时处理流程。
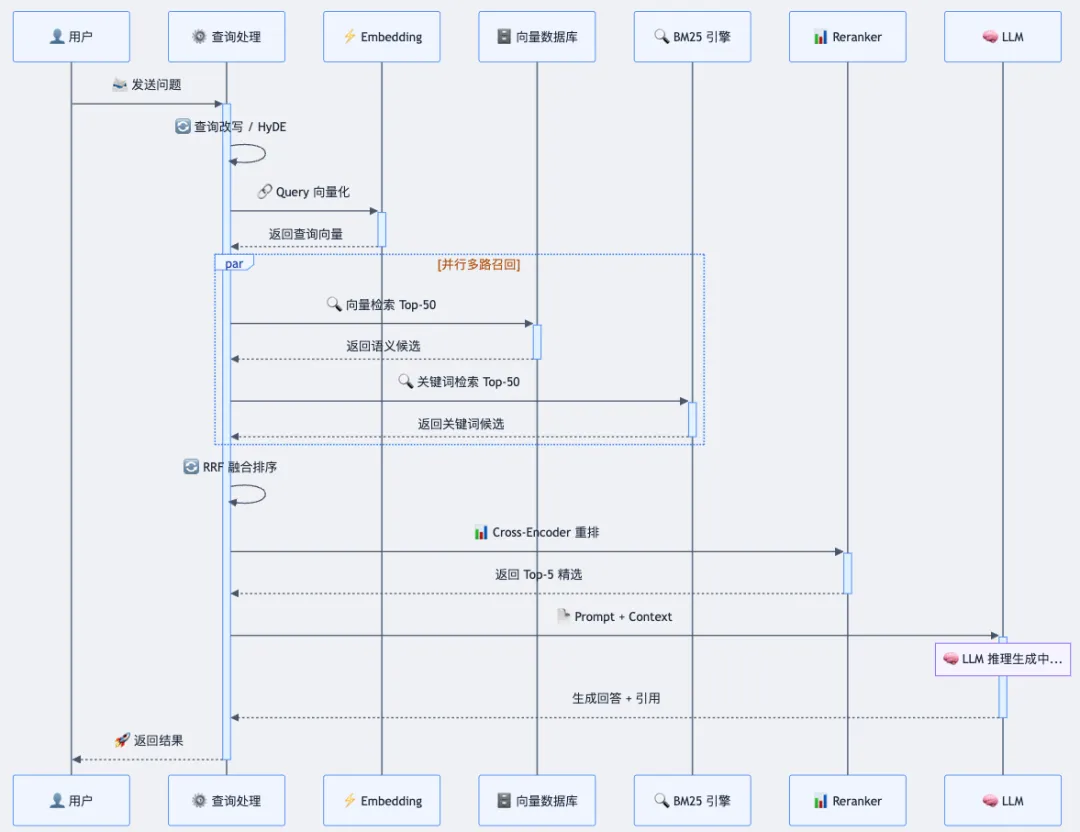
图 3:在线检索-生成时序图——从用户提问到增强回答的完整调用链
4.3 关键算法:余弦相似度检索
直觉:向量检索的核心就是「比距离」——查询向量和每个文档向量比一比谁更近(更像),最近的就是最相关的。
数学表达:
sim(q, d) = (q · d) / (|q| × |d|)
即:两个向量的点积 ÷ 两个向量模长的乘积
其中:
• q:查询文本的 Embedding 向量 • d:文档 chunk 的 Embedding 向量 • n:向量维度(如 1536)
🎯 公式的灵魂:余弦相似度只看「方向」不看「大小」——两段文本的向量朝同一个方向指,语义就相近,值域 [-1, 1]。
4.4 关键算法:RRF 融合排序
直觉:多路召回的结果需要统一排序。RRF(Reciprocal Rank Fusion)用一个简单而优雅的方式合并多个排序列表——每个文档的分数 = 各列表中排名倒数之和。
数学表达:
RRF(d) = Σ 1 / (k + r(d))
即:文档 d 的 RRF 分数 = 在每个排序列表中「排名 + k」的倒数之和
其中:
• R:多个排序列表(如向量检索列表、BM25 检索列表) • r(d):文档 d 在第 r 个列表中的排名(从 1 开始) • k:平滑常数(通常取 60)
🎯 公式的灵魂:不管各路检索用什么算法打分,RRF 只看排名,天然免疫分数量级不同的问题。在向量列表排第 1 的文档和在 BM25 列表排第 1 的文档,贡献完全相同。
5. 实战应用
🛠️ 理论看完了,现在撸起袖子搬砖。
5.1 场景一:企业智能客服
痛点:客服团队每天处理上千条重复咨询,人工回复效率低、质量不稳定,而 ChatGPT 不了解公司产品细节。
RAG 方案:
1. 将产品手册、FAQ、工单历史导入知识库 2. 用户提问时实时检索最相关的产品说明 3. LLM 基于检索到的官方文档生成回答
# 🚀 企业客服 RAG 最小示例 —— 使用 LangChain + OpenAI# 环境要求:Python 3.10+, pip install langchain langchain-openai chromadbfrom langchain_openai import OpenAIEmbeddings, ChatOpenAIfrom langchain_community.vectorstores import Chromafrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.chains import RetrievalQA# 1. 准备知识库文档docs = [ "我们的 Pro 套餐每月 99 元,包含 10GB 存储和无限 API 调用。", "退款政策:购买后 7 天内可全额退款,需通过客服邮箱申请。", "API 限流规则:免费用户 100 次/分钟,Pro 用户 1000 次/分钟。", "产品支持 Python、JavaScript、Go 三种语言的 SDK。",]# 2. 分块 + 向量化 + 存入向量数据库splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)chunks = splitter.create_documents(docs)vectorstore = Chroma.from_documents( documents=chunks, embedding=OpenAIEmbeddings(model="text-embedding-3-small"),)# 3. 构建 RAG 链rag_chain = RetrievalQA.from_chain_type( llm=ChatOpenAI(model="gpt-4o-mini", temperature=0), retriever=vectorstore.as_retriever(search_kwargs={"k": 3}), return_source_documents=True, # 返回引用来源)# 4. 提问result = rag_chain.invoke({"query": "Pro 套餐多少钱?包含什么?"})print(result["result"])# 输出:Pro 套餐每月 99 元,包含 10GB 存储和无限 API 调用。运行结果:
Pro 套餐每月 99 元,包含 10GB 存储和无限 API 调用。💡 实战要点:
search_kwargs={"k": 3}控制检索返回的文档数量。k 太小可能遗漏相关信息,k 太大会引入噪音——通常 3~5 是企业客服场景的甜点值。
5.2 场景二:代码知识库问答
痛点:大型项目代码库动辄数十万行,新人上手困难,「这个功能在哪实现的?」「这个接口的调用约定是什么?」这类问题只有老员工能答。
RAG 方案:
# 🔧 代码库 RAG 进阶示例 —— 支持代码文件的智能问答# 环境要求:pip install langchain langchain-openai faiss-cpuimport osfrom langchain_openai import OpenAIEmbeddings, ChatOpenAIfrom langchain_community.vectorstores import FAISSfrom langchain.text_splitter import Language, RecursiveCharacterTextSplitterfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParser# 1. 使用语言感知分块器处理代码文件code_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=1000, # 代码块建议 800~1500 tokens chunk_overlap=100, # 保留函数签名上下文)# 2. 加载代码文件并分块code_files = ["main.py", "api/routes.py", "models/user.py"] # 示例code_chunks = []for filepath in code_files: if os.path.exists(filepath): with open(filepath, "r") as f: content = f.read() chunks = code_splitter.create_documents( [content], metadatas=[{"source": filepath}], # 标注来源文件 ) code_chunks.extend(chunks)# 3. 构建 FAISS 向量索引vectorstore = FAISS.from_documents( code_chunks, OpenAIEmbeddings(model="text-embedding-3-small"),)retriever = vectorstore.as_retriever(search_kwargs={"k": 5})# 4. 自定义 Prompt 模板(针对代码问答优化)prompt = ChatPromptTemplate.from_template("""你是一个代码知识库助手。基于以下检索到的代码片段回答问题。如果代码片段中没有相关信息,请明确说"我在代码库中没有找到相关实现"。检索到的代码片段:{context}问题:{question}请用中文回答,并引用具体的文件路径和代码行。""")# 5. 构建 LCEL 链chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | ChatOpenAI(model="gpt-4o-mini", temperature=0) | StrOutputParser())# 6. 使用answer = chain.invoke("用户认证的逻辑在哪里实现的?")print(answer)5.3 场景三:多文档研究助手
痛点:研究人员需要跨数十篇论文、报告做综合分析,手动检索和交叉引用极其耗时。
RAG 方案核心差异:
6. 检索优化技巧
🎯 检索质量是 RAG 系统的天花板——LLM 再聪明,垃圾上下文也只能生成垃圾答案。
6.1 查询改写(Query Rewriting)
原始用户查询往往模糊、口语化、信息不完整。查询改写通过 LLM 将用户问题转化为更适合检索的形式,通常能提升 10%~25% 的检索召回率。
1. Multi-Query 扩展 # Multi-Query 改写示例original = "RAG 怎么处理 PDF?"rewritten = [ "RAG 系统如何解析和处理 PDF 文档?", "检索增强生成中 PDF 文件的预处理流程是什么?", "如何将 PDF 文档导入 RAG 知识库?",]• ✅ 推荐做法:用 LLM 将一个问题改写为 3~5 个不同角度的查询,分别检索后合并结果 • ❌ 反面教材:只用原始查询做单次检索,遗漏大量相关文档 • 💡 原因:同一个意图可以有多种表达方式,多查询覆盖更多语义空间 2. HyDE(假设文档嵌入) • ✅ 推荐做法:先让 LLM 生成一个「假设答案」,用这个假设答案的向量去检索,而不是用问题本身 • ❌ 反面教材:直接用短问题的向量检索,语义信息太少导致召回不精准 • 💡 原因:假设答案的向量更接近真实文档的向量空间(因为它们都是「陈述性文本」),而问题是「疑问性文本」,向量分布可能偏差
6.2 混合检索(Hybrid Search)
向量检索擅长语义匹配但弱于精确匹配,BM25 擅长关键词匹配但不懂语义。混合检索两手抓,综合优势。
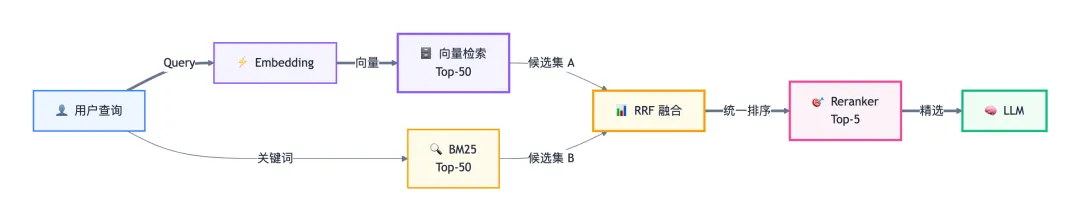
图 4:混合检索流水线——向量检索 + BM25 双路召回经 RRF 融合后由 Reranker 精排
性能对比数据:
| 混合检索 + RRF | 85.1% | 0.79 | |
| 混合检索 + Reranker | 89.7% | 0.86 |
🎯 选型建议:如果你的场景对延迟不敏感(>200ms 可接受),混合检索 + Reranker 是无脑最优解。如果延迟敏感(<50ms),纯向量检索 + 语义缓存是更好的选择。
6.3 Reranker 精排
Reranker 使用 Cross-Encoder 模型将 Query 和每个候选文档拼接后联合编码,比 Bi-Encoder(独立编码再比距离)的排序精度高 15%~30%。
• ✅ 推荐做法:初步检索取 Top-50100,Reranker 精排取 Top-35 • ❌ 反面教材:直接用 Reranker 在全量文档上排序(太慢,单次推理需要 O(N) 次模型调用) • 💡 原因:Cross-Encoder 精度极高但速度慢(每对 Query-Doc 需一次前向传播),必须先用快速的 Bi-Encoder 做粗筛
2. 推荐模型 Reranker 适用场景 延迟 Cohere Rerank v3 通用场景、多语言 ~100ms/batch BGE-Reranker-v2-m3 中文场景、自部署 ~50ms/batch FlashRank 低延迟场景、本地部署 ~10ms/batch
6.4 常见陷阱
⚠️ 前人栽树,后人乘凉。以下是社区用血泪换来的经验教训:
| 分块太大 | |||
| 分块太小 | |||
| Embedding 模型错配 | |||
| 不用 Reranker | |||
| 忽略元数据过滤 | |||
| Prompt 塞太多上下文 |
7. 知识库构建指南
📚 知识库的质量决定了 RAG 系统的上限——垃圾进,垃圾出,这是不可违背的物理定律。
7.1 文档预处理最佳实践
格式统一 • ✅ 推荐做法:统一使用 Unstructured 或 LlamaParse 解析所有格式,输出标准化的 JSON 结构 • ❌ 反面教材:不同格式用不同工具处理,PDF 用 A 库、HTML 用 B 库,输出格式不一致 • 💡 原因:统一的解析管道确保后续分块和 Embedding 的一致性,减少数据质量波动 去噪清洗 • ✅ 推荐做法:去掉页眉页脚、水印文字、导航栏、广告文本,只保留正文内容 • ❌ 反面教材:原始 HTML 直接灌入,包含大量 <nav>、<footer>、CSS 类名等噪音• 💡 原因:噪音文本会被 Embedding 编码为无意义的向量,占据存储空间并干扰检索
7.2 分块策略选型指南
| 递归字符分块 | |||||
| 语义分块 | |||||
| 父子文档 | |||||
| Markdown 标题分块 |
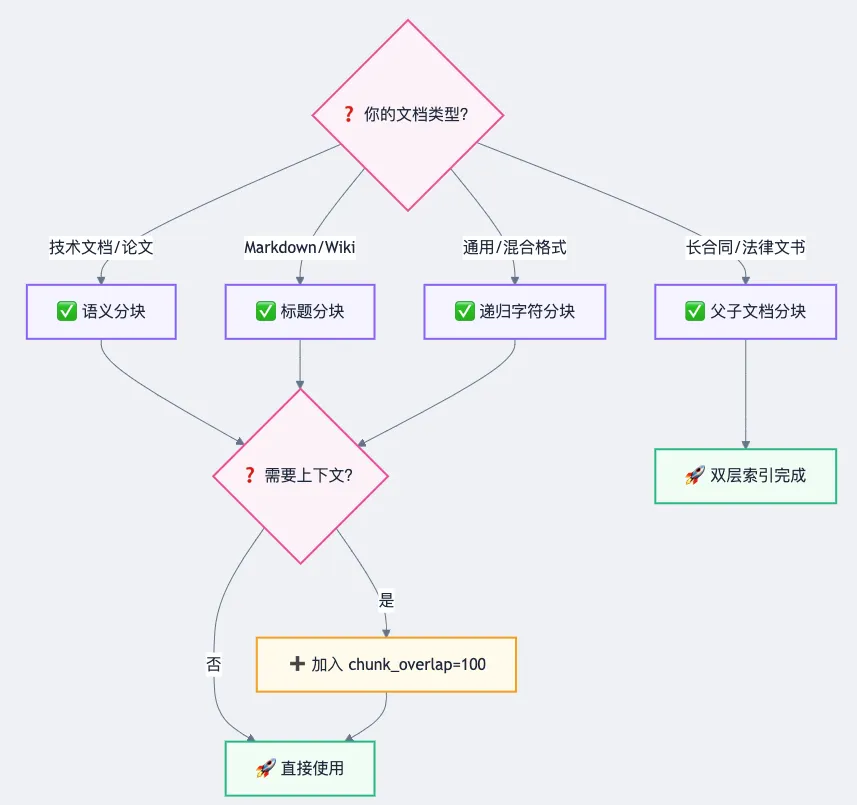
图 5:分块策略选型决策树——根据文档类型选择最佳分块方案
7.3 Embedding 模型选型
🎯 选型建议:如果你的知识库以中文为主,BGE-M3 是自部署首选。如果不想自部署且预算充裕,OpenAI
text-embedding-3-large是综合最优。如果追求极致性价比,text-embedding-3-small+ Matryoshka 降维到 512d 能省 70% 存储。
7.4 向量数据库选型
| Pinecone | |||||
| Milvus | |||||
| Qdrant | |||||
| Weaviate | |||||
| pgvector | |||||
| Chroma |
7.5 知识库维护
知识库不是「建一次就完事」的静态资产,需要持续维护:
• 增量更新:新文档进入时,只对新增 chunk 做 Embedding 和索引,不重建整库 • 版本管理:文档更新后,旧版本 chunk 标记为过期而不是直接删除,支持回溯 • 质量监控:定期抽样检查检索质量,用 Recall@K 和 NDCG 指标跟踪退化趋势 • 去重清洗:定期检测近似重复的 chunk(余弦相似度 > 0.95),合并或删除冗余
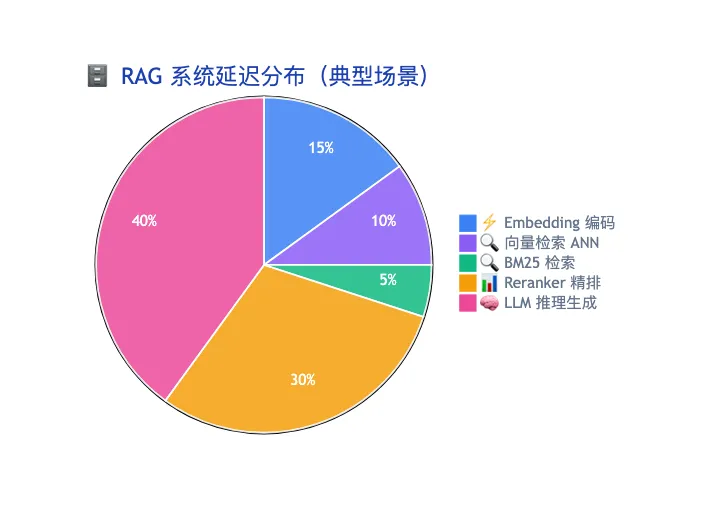
图 6:RAG 系统各环节延迟占比——LLM 推理和 Reranker 是主要瓶颈
8. 哲学反思与展望
🔭 技术解决问题,但真正有趣的问题往往在技术之外。
8.1 RAG 背后的思想
RAG 本质上做了一件很深刻的事:它将 AI 系统的「知识」和「能力」分离了。
传统的 LLM 把知识硬编码在数十亿参数中,就像人类把知识记在大脑里。这种方式有一个根本性限制——大脑的容量是有限的,记忆会衰退、会过时、会出错。RAG 的解决方案与其说是技术创新,不如说是对人类认知方式的一种回归:我们从来不是靠死记硬背来解决知识密集型问题的,我们靠的是「检索」——翻书、查文献、问专家、搜索引擎。
这让人想起认知科学中的「分布式认知」(Distributed Cognition)理论:智能不仅仅存在于大脑中,而是分布在个体、工具和环境的整个系统中。你的手机备忘录是你记忆的延伸,搜索引擎是你知识的延伸,而 RAG 则是 AI 系统迈向分布式智能的第一步。
8.2 未解之题
「好的技术回答旧问题,伟大的技术提出新问题。」
• 检索的边界在哪里? 当知识库规模达到数十亿文档时,「找到最相关的」变成了一个定义模糊的问题——什么是「最相关」?相关性是客观的还是因查询者的知识背景而异的? • 上下文窗口扩大会淘汰 RAG 吗? 当 LLM 的上下文窗口从 128K 扩展到 1M 甚至 10M tokens 时,直接把整个知识库塞进去是否比检索更有效?这引出一个更本质的问题:「精确的少量信息」和「粗略的大量信息」,哪个对推理更有利?
8.3 未来展望
RAG 的演进方向已经从单纯的「检索+生成」扩展到更复杂的范式:
Agentic RAG 正在成为主流趋势——RAG 不再是一个被动的检索管道,而是一个有「自主判断力」的 Agent。它能决定何时需要检索(不是每个问题都需要)、检索什么来源(知识库 vs 网页 vs API)、检索结果是否足够好(不够好就换个策略再搜),甚至能多轮迭代直到找到满意的答案。
Graph RAG 将知识图谱与向量检索融合,不仅检索「与问题语义相近的文档」,还能沿着实体关系做多跳推理。这对于需要综合推理的复杂问题(如"公司 A 的竞品公司 B 的 CEO 是谁?")具有颠覆性优势。
Self-RAG 让模型学会自我反思——生成每段回答后自动评估是否需要更多证据,如果需要就触发新一轮检索。这种「边写边查」的模式比传统的「先查后写」更灵活、更精准。
💭 结语:我们教会了 AI 在回答前先查资料——但也许,真正值得深思的是:当机器都学会了「不确定就去查」,我们人类是否也该对自己的「记忆」多一份谦逊?
引用链接
[1] 1. 概述——这玩意儿到底是啥: #1-概述[2] 2. 核心概念——先把黑话学会: #2-核心概念[3] 3. 架构设计——拆开引擎盖看看: #3-架构设计[4] 4. 工作原理——魔法背后的齿轮: #4-工作原理[5] 5. 实战应用——从理论到搬砖: #5-实战应用[6] 6. 检索优化技巧——让搜索更聪明: #6-检索优化技巧[7] 7. 知识库构建指南——好地基才有好房子: #7-知识库构建指南[8] 8. 哲学反思与展望——站远一点看: #8-哲学反思与展望[9] 9. 参考资料——致敬巨人的肩膀: #9-参考资料
