 夜雨聆风
夜雨聆风当大模型走进软件系统,我们突然发现,这个世界的不确定性来源变得比以前更复杂了。
在传统软件工程中,我们习惯了"人设计软件,软件确定性执行"的模型——人可能会犯错,但软件一旦写好,就是确定的。我们的工作就是通过代码把人的经验固化下来,降低世界的不确定性。
大模型来了之后,情况变了。大模型本身就是概率性的,同一句话问两次,可能得到两个不同答案。它会产生幻觉,会一本正经地胡说八道。但它又能理解语言,能感知图像音频,能做很多传统软件做不了的灵活事情。
于是我们有了三种不确定性来源:
• 人带着生理和心理的不确定性 • 大模型带着概率和统计的不确定性 • 软件——虽然本身是确定的,但它也会因为需求理解不全、边界条件没考虑到而"犯错"
这三者各有各的特点,各有各的位置。怎么把它们组合在一起,构建一个整体不确定性更低、更可靠的系统?这就是我们要讨论的问题。
📊 三种不确定性的对比分析
1️⃣ 人的不确定性
特征:😴 疲劳:工作时间长会疲劳,凌晨更严重😔 情绪波动:心情好坏影响工作质量🧠 注意力分散:容易被其他事情打断💭 记忆偏差:容易遗忘细节😰 压力影响:压力大时容易出错🎲 主观性强:同一情况不同判断同济事件中的表现:凌晨2点 → 医生疲劳 → 提前标记"完成" → 交接班未确认 → 患者被遗忘
传统解决方式:✅ 流程规范(SOP)✅ 检查清单✅ 双人确认✅ 培训教育❌ 但人还是会犯错
2️⃣ 大模型的不确定性
特征:🎲 概率性输出:同样输入可能产生不同输出🌊 幻觉问题:可能编造不存在的事实📏 精度波动:输出质量不稳定🎯 上下文敏感:不同上下文不同表现🔮 不可解释:难以追溯决策过程📊 数据依赖:依赖训练数据质量示例:
同一个问题,不同次调用可能不同
response1 = llm.generate("分析这个医疗图像")response2 = llm.generate("分析这个医疗图像")
response1 和 response2 可能不完全一致
解决方式:✅ 温度调低(降低随机性)✅ Few-shot提示✅ RAG(检索增强生成)✅ 输出验证❌ 但无法完全消除不确定性
3️⃣ 软件的不确定性
特征:✅ 确定性执行:同样输入必然同样输出✅ 逻辑严密:严格按照代码逻辑执行✅ 不会疲劳:7×24小时保持相同性能✅ 可复现:问题可重现、可调试❌ 但逻辑固化:不够灵活❌ 无法适应:新场景需要重新编程示例:
def check_patient_status(patient_id):# 固化逻辑:每次执行结果完全一致if patient_in_room(patient_id):if exam_completed(patient_id):return "异常:患者未离场"else:return "正常"else:return "患者已离开"
🔍 三种不确定性的相同点
1️⃣ 都会犯错
2️⃣ 都需要监督
3️⃣ 都能通过"固化"降低不确定性
核心洞察:
软件的本质是"固化确定性逻辑",降低人和系统的不确定性。
🎯 三种不确定性的不同点
1️⃣ 不确定性来源不同
2️⃣ 可控性不同
3️⃣ 灵活性不同
4️⃣ 成本不同
💡 固化不确定性的三种模式
1️⃣ 传统模式:软件固化人的流程
核心思想:
用确定性软件降低人的不确定性。
实施方式:人的流程(不确定) ↓ 分析、抽象软件逻辑(确定) ↓ 编程代码固化(确定)
同济事件可以应用:
传统软件固化流程
def exam_workflow(patient_id):# 1. 患者进入check_in_patient(patient_id)# 2. 固定患者fix_patient_on_device(patient_id)# 3. 开始检查start_exam(patient_id)# 4. 检查完成complete_exam(patient_id)# 5. ⚠️ 关键:解除固定release_patient(patient_id) # 必须执行# 6. ⚠️ 关键:确认离场confirm_patient_leave(patient_id) # 必须确认# 7. ⚠️ 关键:更新状态update_status(patient_id, "completed") # 最后一步
效果:✅ 强制执行流程,避免遗忘✅ 每步必须确认,不能跳过❌ 但需要人来触发执行❌ 人如果不用软件,软件也帮不上局限性:🚫 人是主动的,软件是被动的🚫 人可以选择不用软件🚫 软件无法感知真实世界
2️⃣ AI原生模式:大模型感知 + 软件固化
核心思想:
用大模型感知世界,用软件固化确定部分,形成闭环。
架构演进:
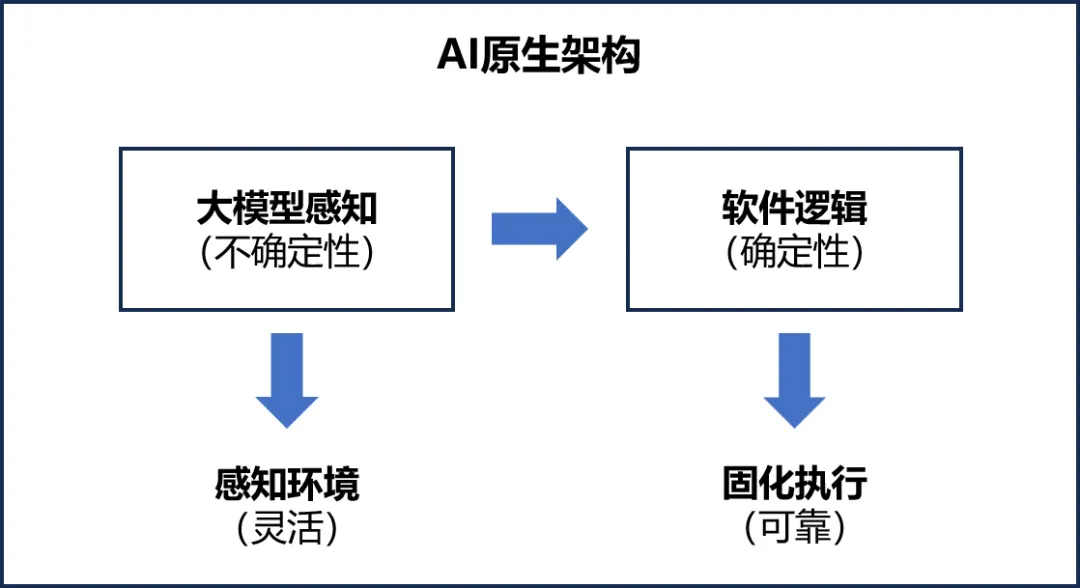
同济事件中的应用:
AI原生:大模型感知 + 软件固化
1. 大模型感知(处理不确定性)
def perceive_situation():# 多模态感知image = camera_tool.get_frame()# 视觉audio = mic_tool.get_audio()# 听觉device_status = device_tool.get_status() # 设备# 大模型分析(带不确定性)analysis = llm.analyze({"image": image,"audio": audio,"device": device_status})# 输出:置信度 + 判断return {"situation": "患者在设备上,系统显示完成","confidence": 0.95, # 不确定性度量"risk_level": "high"}
2. 软件固化确定性逻辑(处理确定部分)
def emergency_protocol(situation_analysis):# 固化逻辑:一旦判定高风险,强制执行if situation_analysis["risk_level"] == "high":# 确定性执行,不允许偏差execute_emergency_steps() # 固化流程# 记录(不可更改)log_event(situation_analysis)
3. 闭环反馈
def feedback_loop():while True:# 感知(大模型)situation = perceive_situation()# 判断(大模型 + 规则)risk = assess_risk(situation)# 执行(软件固化)if risk > threshold:emergency_protocol(risk)# 学习(优化模型)learn_from_feedback(situation)
效果:✅ 大模型主动感知,不依赖人✅ 软件固化确定性逻辑,可靠执行✅ 形成闭环,自动运行✅ 持续学习,不断优化
3️⃣ 规则工厂模式:AI生产软件
核心思想:
用AI生产软件,动态固化规则,适应变化。
架构设计:
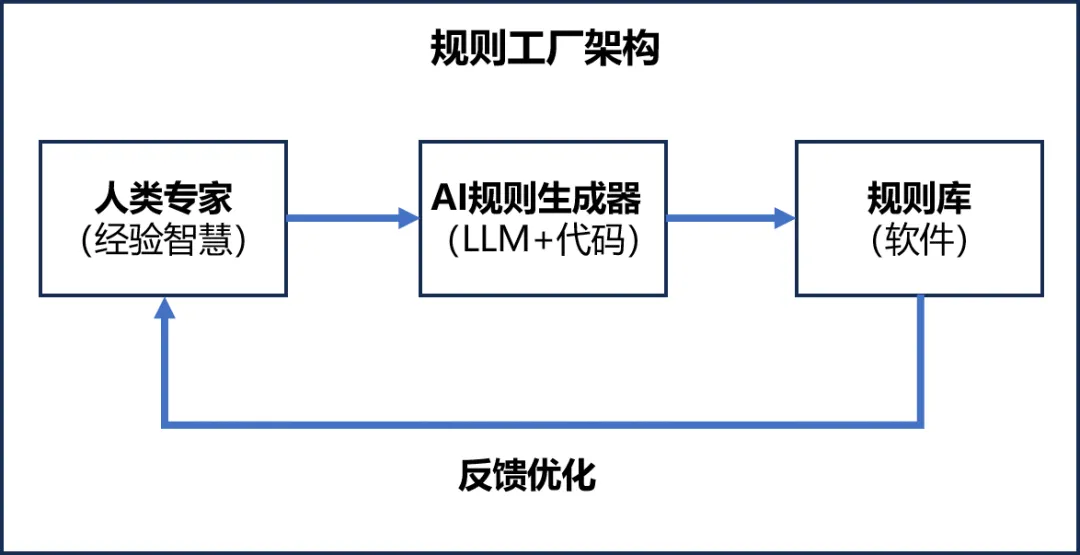
实现方式:
1. 规则提取
从事件中提取规则
def extract_rules_from_incident(incident_report):"""从同济事件中提取规则输入:事件描述输出:可执行规则"""prompt = f"""分析以下医疗事件,提取需要固化的规则:事件描述:{incident_report}请输出:1. 关键控制点2. 必须执行的动作3. 禁止的操作4. 预警条件以JSON格式输出。"""rules = llm.generate(prompt)return parse_rules(rules)
2. 规则生成
AI生成软件代码
def generate_rule_code(rule_spec):"""从规则规范生成可执行代码"""prompt = f"""将以下医疗规则转换为Python代码:规则描述:{rule_spec}要求:1. 使用确定性逻辑2. 包含完整的错误处理3. 添加详细的日志4. 符合医疗合规要求"""code = llm.generate(prompt)# 代码审查reviewed_code = review_code(code)return reviewed_code
3. 规则部署
动态部署规则
class RuleFactory:"""规则工厂:动态生成和管理规则"""def deploy_rule(self, rule_name, rule_spec):""" 部署新规则 """# 1. 生成代码code = generate_rule_code(rule_spec)# 2. 测试test_result = self.test_rule(code)if not test_result.passed:return test_result.errors# 3. 部署self.rule_engine.register(rule_name, code)# 4. 监控self.monitor_rule(rule_name)return {"status": "deployed", "rule_id": rule_name}def update_rule(self, rule_name, feedback):""" 根据反馈更新规则 """# 分析反馈improvement = llm.analyze_feedback(feedback)# 生成新版本new_code = generate_rule_code(improvement)# 灰度发布self.canary_deploy(rule_name, new_code)
⚖️ 谁来监督监督者?
一个自然的问题:如果大模型感知错了怎么办?如果AI生成的代码有bug怎么办?
我们的答案是:保留人工审核关口,分级控制风险。
规则生成 → 自动测试 → 风险分级 ↓高风险规则 → 人工审核 → 灰度发布 ↓低风险规则 → 自动发布 → 快速迭代 ↓全量规则 → 持续监控 → 反馈优化具体实践:
• 大模型感知错误:软件层做校验,交叉验证多个来源的数据,如果置信度低于阈值,自动转人工处理 • AI生成代码bug:自动测试用例先行,核心路径必须覆盖;高危操作需要人工审核;生产环境开启灰度,流量逐步放量 • 规则冲突:建立规则优先级机制,新规则不覆盖旧规则,并行运行一段时间对比效果后再切换
核心原则:速度和安全可以兼得——低风险场景追求速度,高风险场景守住安全。速度快不代表不审核,只是分级审核。
🎯 三种模式对比
💎 核心洞察
1️⃣ 软件是"固化确定性的艺术"
不确定性世界 ↓ 识别、抽象确定性逻辑 ↓ 编程、固化软件系统(确定性) ↓ 降低系统整体不确定性
2️⃣ 人 + 大模型 + 软件的黄金三角
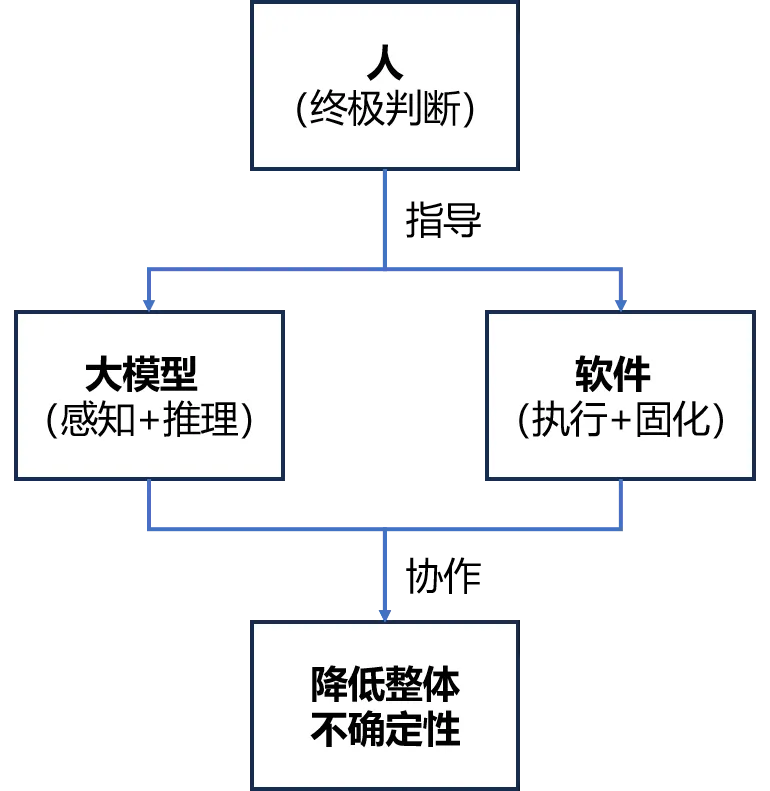
分工:人:负责价值判断、最终决策、复杂情况处理大模型:负责感知世界、理解语义、灵活推理软件:负责固化逻辑、可靠执行、精确控制
3️⃣ 规则工厂:从事件到规则的快速闭环
事件发生 ↓ AI分析规则提取 ↓ AI生成软件代码 ↓ 自动部署执行固化 ↓ 反馈学习规则优化 ↓持续改进
时间对比:传统模式:事件 → 讨论 → 需求 → 开发 → 测试 → 部署(月级)AI原生模式:事件 → 分析 → 调参 → 部署(周级)规则工厂模式:事件 → AI生成 → 自动部署(小时级 ⚡️)
往期热文:
