 夜雨聆风
夜雨聆风
> 本文来自社区投稿
> 编辑:机智流
导读:上周我们发了篇名为 FactReview 的文章,讨论 AI 审稿人如何通过代码执行验证论文主张。与之不同的是,文本所讲的 AiScientist 的野心更大——它不满足于“检验结论”,而是要真正接过一篇论文,在数十小时里自主完成环境搭建、代码实现、实验迭代与误差修复,把研究工程一路做到可累积的结果改进。

过去一年,AI for Research 的进展非常快。无论是 idea generation、文献整理、paper-to-code,还是围绕明确目标进行实验优化,越来越多系统已经证明:大模型不只是能“讨论研究”,而是在开始真正参与研究。
但如果把问题再往前推一步,一个更硬核的设定就会出现:如果直接把一篇论文、一个基础环境和有限的时间预算交给 AI,它能不能把后面的研究工程一路做下去?
这里的“做下去”,不是只生成一段代码,也不是只跑一次实验,而是要从论文理解出发,逐步完成环境配置、资源获取、实现搭建、实验运行、误差诊断与迭代修复,并在数十小时的跨度里持续推进结果。
近日,中国人民大学高瓴人工智能学院提出了一个面向这一任务设定的系统 AiScientist。论文将这一问题明确表述为 autonomous long-horizon engineering for ML research(机器学习研究中的长程自动化工程)。
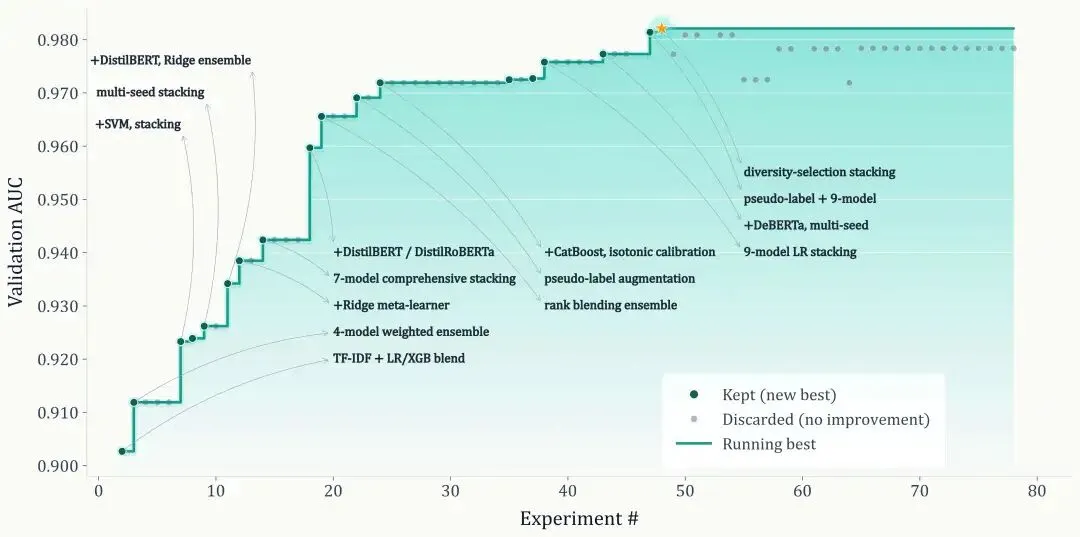
实验显示,AiScientist 在 MLE-Bench Lite 的 Detecting Insults 任务上,可在 23 小时内自主完成 74 轮实验循环,将 validation AUC 从 0.903 提升到 0.982;在 PaperBench 上相对最佳匹配基线平均提升 10.54 分,并在 MLE-Bench Lite 上达到 81.82% Any Medal。
更值得注意的是,这篇工作的价值不只在于分数。论文的机制分析进一步表明:长程研究工程的突破,并不是单靠某一个局部阶段做得更好就会自然出现。系统既要在论文理解、实现、实验、诊断这些高难度环节上持续做对,也要让这些环节之间的项目状态被稳定保留、继承和重用,前一轮工作才能真正变成下一轮改进的起点。
论文标题:Toward Autonomous Long-Horizon Engineering for ML Research
论文链接:https://arxiv.org/pdf/2604.13018
代码链接:https://github.com/AweAI-Team/AiScientist
这项工作在解决什么问题?
AiScientist 并不是在否定现有 AI for Research 的进展。恰恰相反,论文把它放在一个很清晰的脉络里:前面的工作已经在自动化科学发现、目标驱动的实验优化、从论文到代码生成等方向上打下了很多基础,而 AiScientist 关注的是一个更“落地”的场景:machine learning research engineering。
在这个场景中,真正困难的地方并不只是某一步难,而是整条链条都难。
论文把这种困难总结得很准确。
第一,研究规格本身往往不完整。很多关键实现细节不会在论文里写全,系统必须自己补足。
第二,system setup 负担很重。环境、依赖、数据、模型资源的准备,常常和算法实现一样麻烦。
第三,反馈是延迟而且混杂的。很多问题要等实验跑出来才暴露,而且很难立刻判断到底是配置、实现、数据还是训练策略出了问题。
第四,项目状态必须跨轮次延续。日志、计划、实验记录、中间结论都不是附属品,而是后续决策的依据。
也正因为如此,机器学习研究工程并不只是很多 hard local problem 的简单相加。更难的地方在于:这些局部难题必须被组织成一条连续推进的项目轨迹,系统要在很长的时间跨度里,让前一阶段的解释、实现和实验结果,继续对后一阶段产生作用。
AiScientist 怎么把这件事组织起来?
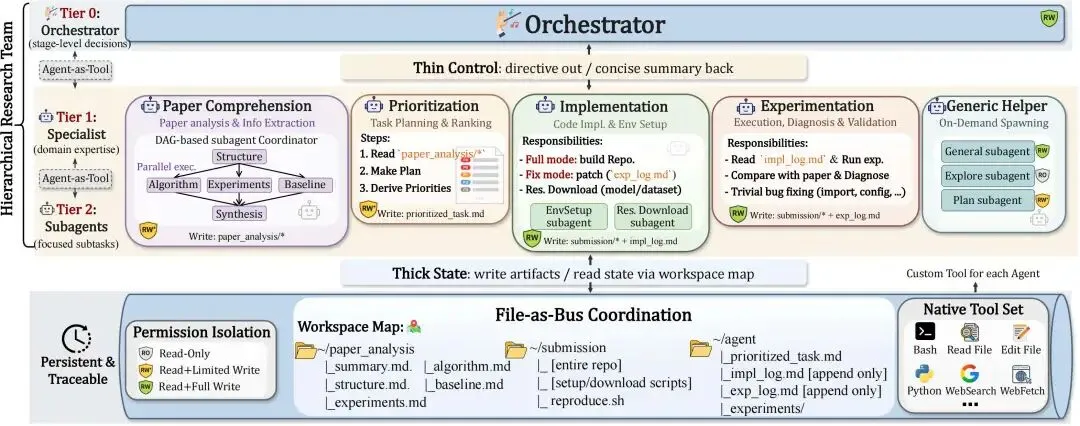
AiScientist 的核心思路,可以概括为论文中的一句话:thin control over thick state。
它的意思不是让控制更弱,而是把控制和状态分开设计。顶层控制保持轻量,负责阶段判断、任务推进和委派;真正厚重、真正需要跨阶段保存的内容,则沉淀在工作区里。
围绕这一思路,AiScientist 有两层核心设计。
第一层是 hierarchical orchestration。顶层 Orchestrator 不直接卷入每一个细节,而是通过阶段级规划、简洁摘要和 workspace map 管理全局,再把论文理解、任务规划、代码实现、实验执行和诊断修复交给更专门的角色处理。
第二层是 File-as-Bus。AiScientist 不把长期状态主要寄托在聊天上下文里,而是把论文分析、实现计划、代码、实验日志、错误记录和中间结论持续写回共享工作区,让后续 agent 能够重新读取这些 artifact,并在其基础上继续工作。
这使得整个系统形成了一个真正的 evidence-driven loop:不是“再试一次”,而是围绕已有证据继续 implement、run、diagnose、patch、re-validate。换句话说,AiScientist 想解决的,并不是让 agent 多说几轮,而是让它在多轮之后还能接着做对。
先看结果:它不只是跑通了,而是在持续逼近目标
在 Detecting Insults 任务上,AiScientist 在 23 小时里自主跑了 74 轮实验循环,期间完成 18 次 best-so-far update,最终把 validation AUC 从 0.903 提升到 0.982。这说明系统不是停在“能启动”“能提交”,而是在不断吸收实验反馈,持续把结果往前推。
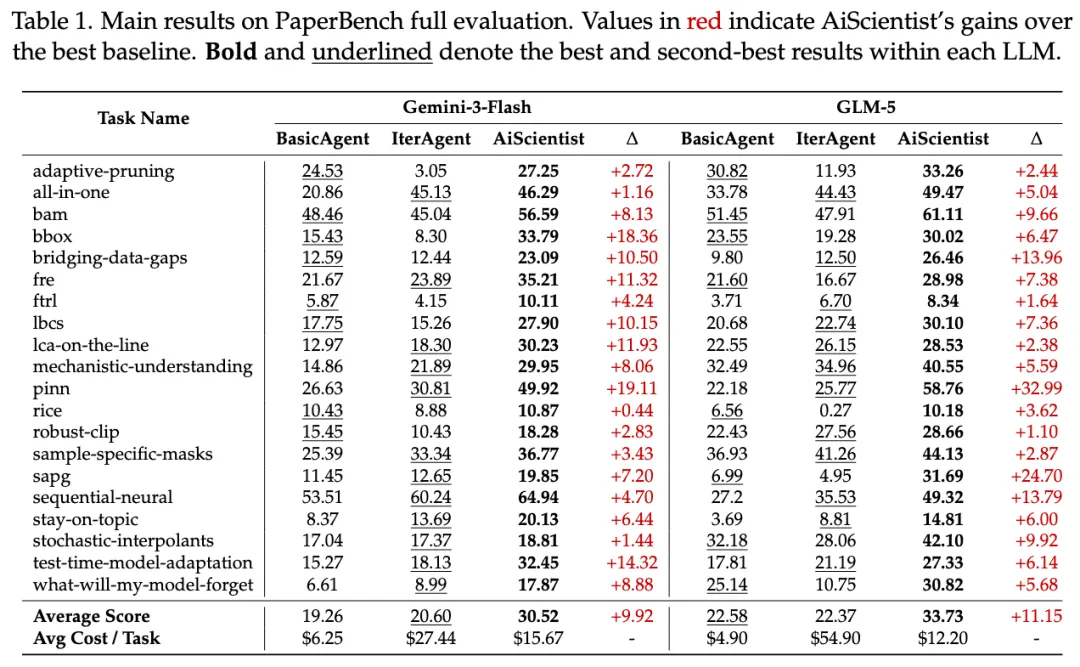
在更强调从论文出发完成复现与工程实现的 PaperBench 上,AiScientist 相对最佳匹配基线平均提升 10.54 分。
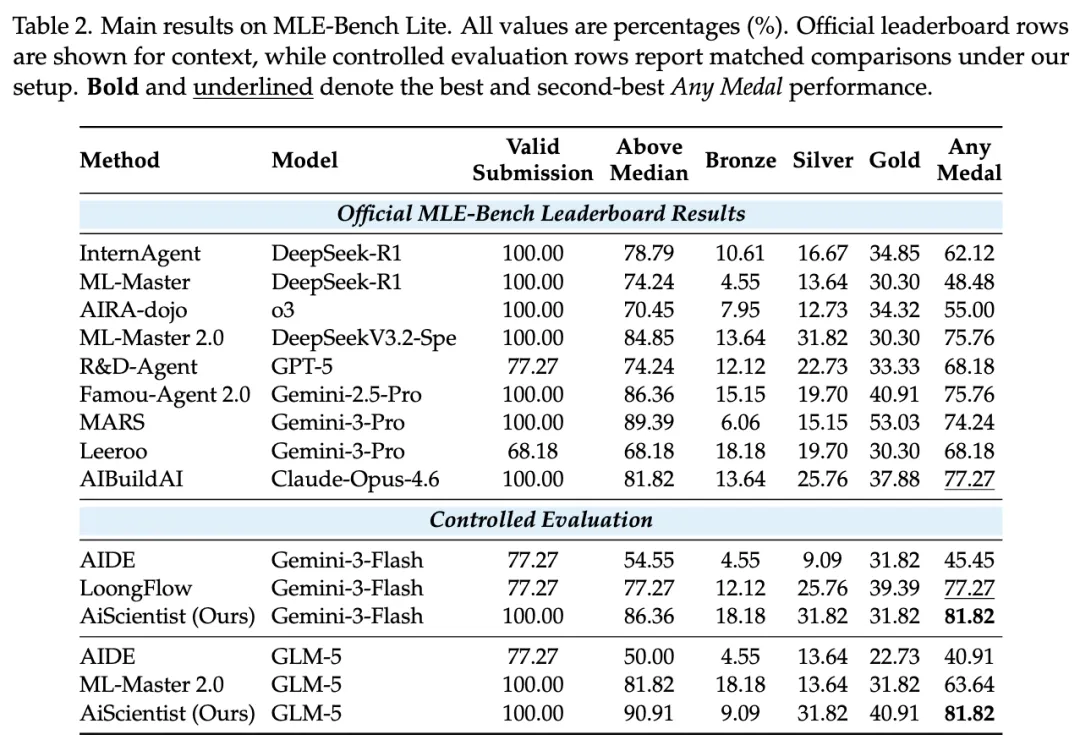
在要求系统自行完成实现与有效提交、并进一步持续实验改进的 MLE-Bench Lite 上,AiScientist 达到 81.82% Any Medal,论文中对应的平均提升为 11.37 个百分点。
这两个 benchmark 的侧重点不同,一个更看重前沿论文的复现,另一个更看重在竞赛式机器学习任务中,从实现、提交到后续实验改进的完整闭环。AiScientist 能在两者上同时建立优势,意味着它解决的并不是一个单点技巧,而是一类更普遍的长程研究工程问题。
三个值得单独拎出来的 takeaway
Takeaway 1:研究工程的难,不只是“每一步都难”,更在于这些难题必须在同一条项目轨迹上连续接力
这其实是从主实验结果里直接长出来的判断。
如果 AiScientist 只是某个局部环节更强,比如更会写代码或更会调参,那么它未必能同时在 PaperBench 和 MLE-Bench Lite 两类 benchmark 上都保持明显优势。前者考察的是从论文理解到可执行实现的完整链条,后者则要求系统先把可运行、可提交的方案自己搭出来,再在此基础上持续迭代、逐步逼近更好结果。AiScientist 在这两类任务上都能拉开差距,说明它处理的不是某个单点模块,而是怎样把多个本来就很难的阶段,组织成一条可持续推进的长链条。
Detecting Insults 的 23 小时、74 轮实验循环,则把这种能力展示得更具体。它表明系统面对的不是“一次决策”,而是一串彼此耦合的决策:前面的理解和实现会影响后面的实验,后面的实验结果又反过来修正前面的判断。也正因如此,长程研究工程既包含很多高难度 local problem,也包含一个更难的系统层问题:如何让这些局部能力在连续迭代中真正累积成进展。
Takeaway 2:长程能力的关键,不只是“多做几轮”,而是新增轮次能不能建立在前面留下的有效状态之上
这部分的证据,来自论文对不同系统组织方式的比较。
论文明确写到一句很值得注意的话:More interaction alone is not enough. 也就是说,多轮交互本身并不会自动变成长程能力。与 IterativeAgent 的比较显示,即便系统已经加入了更多迭代互动,如果这些互动没有建立在前面阶段的有效积累之上,性能依然可能明显落后,而且成本更高。
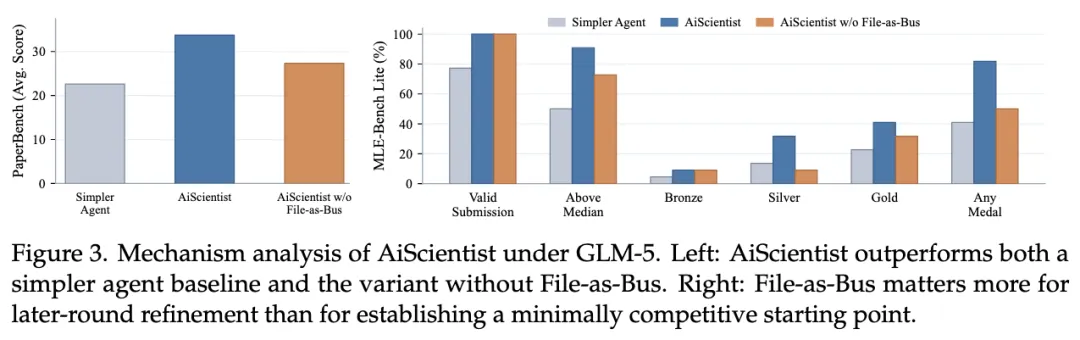
与此同时,论文还比较了去掉 File-as-Bus 的版本。结果显示,移除这一机制后,AiScientist 在 PaperBench 上下降 6.41 分,在 MLE-Bench Lite 上 Any Medal 下降 31.82 个百分点。这说明系统真正缺的,不只是更多 agent、更多轮数或更长上下文,而是能不能把分析、代码、日志、实验结论这些项目状态,以足够高的保真度留到后面继续利用。
更重要的是,这个结论并不是在说局部阶段不重要。相反,论文理解、实现、实验、诊断每一步都很难。实验真正提示我们的是:即便每个局部环节都不弱,如果这些环节之间缺乏稳定的状态衔接,局部能力也很难转化为持续、可累积的长程进展。
Takeaway 3:File-as-Bus 更大的价值,在于把系统推进到真正有含金量的后半程 refinement
这个判断同样不是凭直觉得出的,而是消融实验中非常鲜明的模式。
论文指出,去掉 File-as-Bus 之后,系统在 MLE-Bench Lite 上的 Valid Submission 和 Bronze 并没有完全崩掉,但在 Above Median、Silver、Gold 和 Any Medal 这些更强结果指标上,退化明显更大。论文据此给出的结论也很直接:File-as-Bus matters more for later-round refinement than for establishing a minimally competitive starting point.
这句话很重要。它意味着 File-as-Bus 的作用,不只是帮助系统先把项目“搭起来”,更重要的是帮助它在后续的误差归因、超参数修正、结果对齐和多轮试错中,把中间证据稳稳留住,并反复用于下一轮改进。
换句话说,真正高价值的研究工程从来不止于“先做出一个能运行的版本”。更关键的部分,往往发生在后面一轮轮细节修补和结果逼近里。AiScientist 的实验说明,项目状态一旦不能被稳定保存和继承,系统就很难进入这个真正决定上限的后半段。
为什么这件事值得关注?
AiScientist 值得关注,并不只是因为它又把某个 benchmark 做高了一些,而是因为它把一个越来越清晰的问题,落到了可验证的系统设计上:AI 真要进入科研流程,难点不只在某一步会不会做,而在它能否把不断演化的项目状态保存成后续还能继续使用的依据。
这也是这篇工作最有启发性的地方。它没有把“研究 agent”理解为一个更会说话、更会规划的单体模型,而是把长程研究工程视为一个需要组织局部能力、维护项目状态、持续吸收实验反馈的系统问题。
对于未来的 AI for Research 来说,这个判断可能非常重要。因为越接近真实科研,任务就越不可能靠一次生成结束;真正拉开差距的,往往是系统能不能把前面做过的事留下来,并让这些积累在后面继续发挥作用。
