 夜雨聆风
夜雨聆风
导读 本文根据 Datastrato 创始人兼 CEO 堵俊平在 Data for AI Meetup(深圳站)的技术演讲整理而成。
1. 从 AI 模型到 AI Agents 的演进
2. 软件架构的范式转变
3. 被隐藏的瓶颈:数据基础设施
4. 数据基础设施的五大转变
5. 新兴架构:统一的数据控制平面
6. 真实场景:数据准备的工作流
7. 元数据:数据系统的大脑
8. 开放生态系统的关键作用
9. 核心洞察
分享嘉宾|堵俊平 Datastrato 创始人兼 CEO
出品社区|DataFun
01
从 AI 模型到 AI Agents 的演进
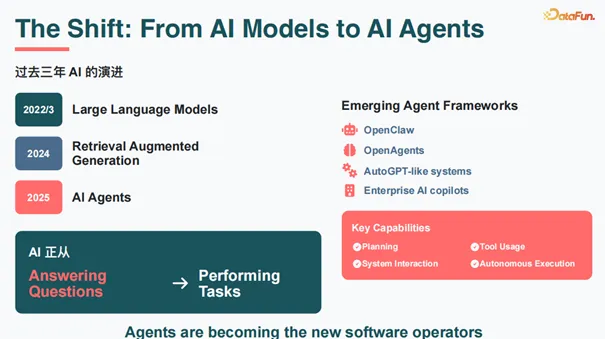
过去三年,AI 技术经历了清晰的演进轨迹。2022 年底 ChatGPT 引爆了大语言模型革命,业界关注模型能力竞赛。2024 年,RAG(检索增强生成)成为热点,核心是如何将大模型与企业数据结合。2025 年,AI Agents 成为主流,从 Menus 到 OpenClaw,标志着 AI 从"回答问题"(Answering Questions)进化到"执行任务"(Performing Tasks)。
这一演进的本质是能力的根本转变。AI Agents 具备了规划(Planning)、工具使用(Tool Usage)、系统交互(System Interaction)和自主执行(Autonomous Execution)能力。它们不仅告诉你答案,而且亲自上手解决问题。Agents are becoming the new software operators(Agents 正在成为新的软件操作者)。
02
软件架构的范式转变

这种能力转变正在重构软件架构的底层逻辑。在传统软件架构中,人类通过精心设计的 UI 界面操作应用,应用再访问底层数据。在 AI Copilot 阶段,Copilot 替代了 UI 成为中介层,但仍然依赖后端应用。
而在 Agentic AI 阶段,架构逻辑发生了根本改变。Agent 通过推理和规划,直接调用标准化工具套件,直接访问数据层,完全绕过了传统的应用中间层。这意味着应用层、基础设施层,尤其是数据平台,整个逻辑都需要基于全新范式重构。Agents become the primary interface to software systems(Agents 成为软件系统的主要接口)。
03
被隐藏的瓶颈:数据基础设施

目前 AI 领域的讨论主要集中在三个方向:模型能力(OpenAI 的 O 系列、Claude 的新版本)、提示工程(如何与 Agent 沟通的各种实践)、以及端到端的 Agent 框架。这些讨论都没错,但远远不够(It's not enough)。
观察 Agent 工作流程会发现:它需要发现数据、理解 Schema、检索上下文、执行查询、更新数据、触发数据管道。Agents 将大部分时间花在与数据交互上(Agents spend most of their time interacting with data)。然而真正的瓶颈在于:今天的数据平台是为人类编写 SQL 设计的,而不是为 Agents 操作系统设计的。如果数据系统没有做好准备,Agent 的操作将是错误的、危险的、不安全的。
04
数据基础设施的五大转变
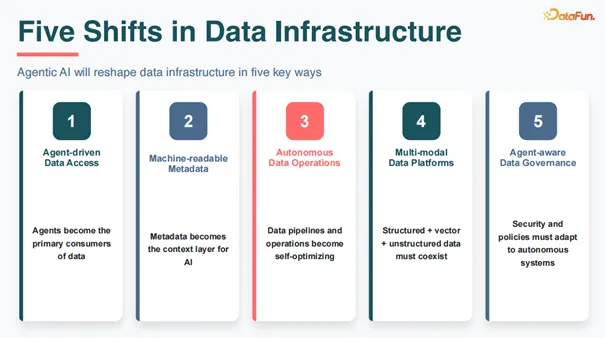
Agentic AI 将从五个关键维度重塑数据基础设施。
第一是 Agent 驱动的数据访问。未来数据的主要消费者不再是通过 BI 工具访问的人类,而是 AI Agents。Agents 成为数据的首要消费者(Agents become the primary consumers of data),数据接口、访问模式都需要针对 Agent 优化。
第二是机器可读的元数据。Agent 无法像人类一样"猜测"数据含义,必须依赖明确的、结构化的元数据来理解数据。元数据成为 AI 的上下文层(Metadata becomes the context layer for AI)。
第三是自主数据运维。未来的 DataOps 运维将是智能化、自主化的,不需要太多人工干预。即使专业运维团队也无法 7×24 小时在线,但 AI 可以。数据管道和运维将变得自优化(Data pipelines and operations become self-optimizing)。
第四是多模态数据平台。除了传统的表结构数据,向量数据、图片、音视频等多模态数据将成为一等公民。结构化、向量、非结构化数据必须共存(Structured + vector + unstructured data must coexist)。
第五是 Agent 感知的数据治理。相比人类,Agent 的数据访问方式可能更加"狂野"和不规范,安全策略必须适应自主系统(Security and policies must adapt to autonomous systems)。
05
新兴架构:统一的数据控制平面
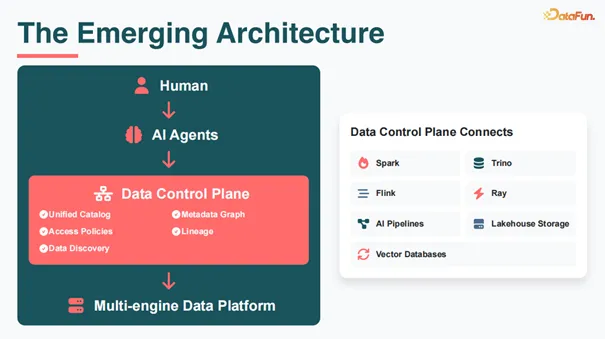
下一代数据基础设施的核心是数据控制平面(Data Control Plane)。它包含几个核心组件:统一的元数据目录(Unified Catalog)提供全局数据资产视图,访问控制策略(Access Policies)集中化管理权限,数据发现(Data Discovery)通过 API 与 Agent 交互,元数据图谱(Metadata Graph)展现数据血缘关系。
多引擎支持(Multi-engine)至关重要。传统系统往往是一个引擎配一个元数据,现在是一个统一的元数据支持多个引擎——Spark(批处理)、Trino(查询)、Flink(流处理)、Ray(AI 计算)等。引擎处理的结果可被下一次任务复用。所有数据最终存储在 Lakehouse Storage 和 Vector Databases 中。数据控制平面连接一切(The Data Control Plane Connects everything)。
06
真实场景:数据准备的工作流

让我们看一个真实场景。当你要求 Agent"为训练推荐模型准备数据集",Agent 会执行以下工作流:发现相关的表(Discover relevant tables)、检查数据质量(Check data quality)、合并数据集(Join multiple datasets)、生成 Embedding 向量(Generate embeddings)、存储到湖仓(Store results in lakehouse)、注册元数据(Register metadata)。
没有统一元数据,这会变得极其复杂(Without Unified Metadata, this becomes extremely complex)。Agent 需要与数据库、数据仓库、AI系统等多个异构系统分别交互。但有了统一控制平面,所有操作通过统一接口完成。统一元数据层是 Agent 数据操作的关键使能器(Unified metadata layer is the key enabler for agentic data operations)。
07
元数据:数据系统的大脑

元数据正在成为数据系统的大脑(Metadata is becoming the brain of data systems)。一个完整的元数据包含数据集名称(Dataset: customer_orders)、所有者(Owner: growth_team)、PII 敏感字段(PII columns: email, phone)、血缘关系(Lineage: clickstream → orders →analytics)。
如果没有这样一层把信息聚合在一起,Agent就无法理解数据的含义和用法。Agent 依赖元数据理解:什么数据存在(What data exists)、数据如何连接(How data is connected)、谁拥有数据(Who owns the data)、哪些策略适用(Which policies apply)。基于元数据,Agent 能够推理数据(Reason about data)、生成查询(Generate queries)、安全操作(Operate safely)。
08
开放生态系统的关键作用

为支持 Agent 时代,我们需要开放和统一的数据基础设施(To support the Agentic era, we need open and unified data infrastructure)。这包括开放湖仓格式(Iceberg、Delta Lake、Hudi 等已成为标准)、多引擎支持(Spark、Trino、Flink、Ray 协同工作)、统一元数据平台(Apache Gravitino 作为单一真实来源)、可扩展治理(策略即代码方式)、多云原生支持(AWS、Azure、GCP、混合云环境)。这些开放组件构成完整的生态系统,支持企业级环境中 AI Agent 的持续创新。
09
核心洞察

Agentic AI 将从根本上改变数据系统的使用方式和设计原则(Agentic AI will fundamentally reshape how data systems are used)。下一代数据技术栈具有四大特征:Agent 原生(Agent-native,数据系统面向 Agent 设计)、元数据驱动(Metadata-driven,元数据如数据地图指导 Agent 操作)、多引擎(Multi-engine,批处理、流处理、AI 计算协同)、多模态(Multi-modal,结构化、向量、非结构化数据共存)。
下一代数据平台不仅服务人类,更服务 Agents(The next generation data platform will not just serve humans — it will serve agents)。关键挑战在于构建能让 AI Agents 安全、高效地大规模操作数据的基础设施(The key challenge ahead is building infrastructure that allows AI agents to safely and efficiently operate on data at scale)。
欢迎来到元数据的世界(Welcome to the world of metadata)。Apache Gravitino 等开源项目正在搭建 Agent 与数据之间的桥梁,构建开放、统一、智能的数据基础设施,真正释放 Agentic AI 的潜力,让 AI 从实验室走向生产环境的每一个角落。



关于 Data for AI 社区
Data for AI 是一个聚焦数据与人工智能基础设施生态的技术交流社区。
社区的分享嘉宾来自全球数据与人工智能领域众多头部厂商与新锐创业团队,包括 Alibaba、Anyscale、AWS、Bilibili、ByteDance、Databricks、Datastrato、eBay、IBM、Intel、LanceDB、Lilith、Meta、Microsoft、NVIDIA、OpenAI、Pinterest、Roku、Tencent、Uber、Xiaomi、Zilliz 等企业。如此多方参与,让社区能持续输出高质量、贴近行业一线的技术内容。我们的组织者来自 Linux 和 Apache 等知名开源基金会和社区。这让 Data for AI 在保持开放友好氛围的同时,也具备中立、可信、专业的技术讨论基础。
Data for AI 的目标,是为数据工程、AI & Data Infra 等领域的开发者打造一个轻松而专业的交流平台。通过线上线下的活动,大家可以一起探索前沿趋势、分享实践经验、拆解真实业务案例,打破行业信息壁垒,连接优质同行伙伴,共同构建一个持续成长、价值共生的技术社群网络。
如您希望加入 Data for AI 社区,请联系社区主理人 Richard(微信:OPQRichard)沟通交流。



分享嘉宾
INTRODUCTION

堵俊平

Datastrato

创始人兼 CEO

Datastrato 创始人兼 CEO,LF AI & DATA 基金会董事,Apache 软件基金会成员,大数据技术与开源领域专家,开放原子开源基金会 TOC(技术监督委员会)主席,Apache 开源基金会 Member, Apache Hadoop 以及 Submarine 等项目 Committer 和 PMC,Apache YuniKorn, TubeMQ 等项目导师。曾任腾讯开源联盟主席兼大数据平台研发总监,Hortonworks Hadoop YARN 团队负责人等。

往期推荐

点个在看你最好看
SPRING HAS ARRIVED

