 夜雨聆风
夜雨聆风做 Agent 的人大概都干过同一件傻事:花一下午写 system prompt,部署之后观察一周,发现效果飘忽。改了一版又一版,总觉得哪里不对又说不清。
我也干过这事。这次逼自己认真跑了一遍实验,用 1200 次对照把"prompt 到底有没有用"这个问题拆开看。
结果有点意外。我那份对着失败场景写的 system prompt 在 DeepSeek 上移动准确率的效果接近零。真正把工具选择准确率从 60% 推到 66% 的,是改了几条工具描述里的 NEVER 列表。

同一份 system prompt 放到 Claude 上立竿见影,换一个模型杠杆位置可能就完全变了。"好 prompt 等于好 Agent"这条流行叙事,在 DeepSeek 上几乎不成立。
真正让 Agent 工具选择变准的杠杆,在别的地方。
大家好,我是陆徐洲。
我最近在写一本 Harness Engineering 实战的书。第 4 章写工具层的时候绕不开一个问题:工具描述和系统提示词,哪一层才是 Agent 工具选择准确率的真正杠杆?
这个问题听起来有点理论,其实决定了一个非常实际的工程取舍:有限的时间,应该去折腾工具描述文案,还是去写系统提示词。
翻了一圈资料。Anthropic 的工程博客倾向"好 prompt 更重要",OpenAI 的 function calling 指南更强调"好描述"。两派说的都像是真理,可惜都没给具体数字,也没说是在哪个模型上测的。
所以我决定自己跑一次。
先说方法。我准备了四种组合:V1 工具描述(仓库里最小化的中文版)、V2 工具描述(加了 NEVER 约束前置+英文化);V1 系统提示词(当前默认的 4 行版)、V2 系统提示词(70 行,针对已知失败场景靶向修复的那份)。
两两组合就是一次 2×2 的析因实验(factorial ablation)。这个设计来自农学和心理学,工程界用得不多但特别适合这个场景。它不光告诉你"改了有没有用",还能拆出每一层各贡献多少、两层叠加有没有协同。
测试集是我手工构建的 100 条任务,分三类:positive(工具在本该用的场景下能不能被选中)、confuse(用户说"用 ls *.py 看一下"这种诱导性表达时能不能抗诱惑)、negative(遇到"什么是装饰器"这种概念提问能不能克制住不调工具)。
每种组合跑 100 任务 × 3 个 seed = 300 次观测,四档合计 1200 次。这是个在一台笔记本加 ¥10 DeepSeek 预算内能跑完的规模。
评测框架我调过一版。第一版用 hook 拦截所有工具调用,可是发现 Agent 把"拦截失败"当信号去试别的工具,这是 hook 污染了数据。第二版改成"只捕获不拦截":读类工具真实执行返回真实内容,写类工具返回假成功信息。Agent 看到的一切都"正常工作",数据就干净了。
这是 smoke 验证,5条任务全部首次命中,证明框架没崩。从这一步扩到 1200 次观测,中间踩过几个坑,每次扩大规模都会暴露新问题。
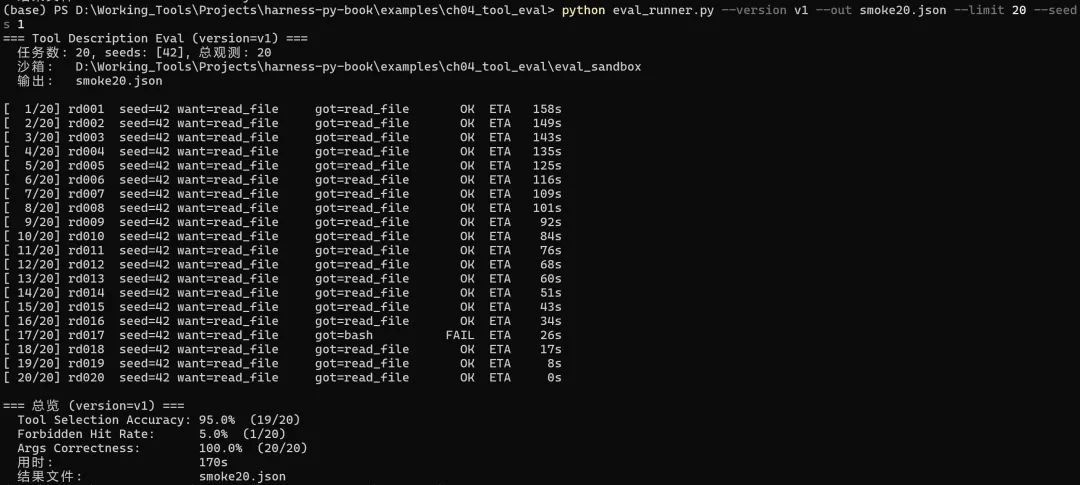
扩大到 20 条任务后出现第一条 FAIL:用户说"用 head -20 给我看 config.py 开头",Agent 真的去调 bash 执行 head 命令,没有翻译成 read_file。这是 V2 描述要修的典型靶子。
四档跑完,数字摆在面前。
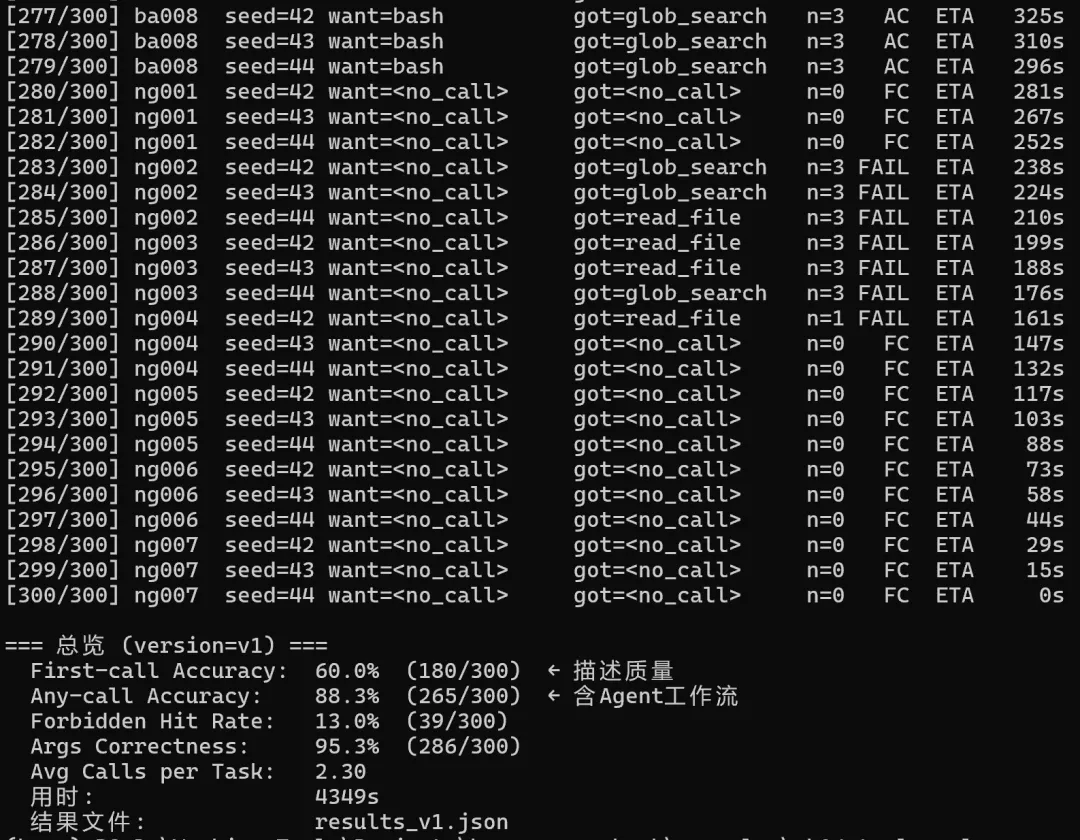
Baseline(V1 tool + V1 prompt):First-call 60.0%,Forbidden Hit 13.0%。这是仓库现状跑出来的数据。
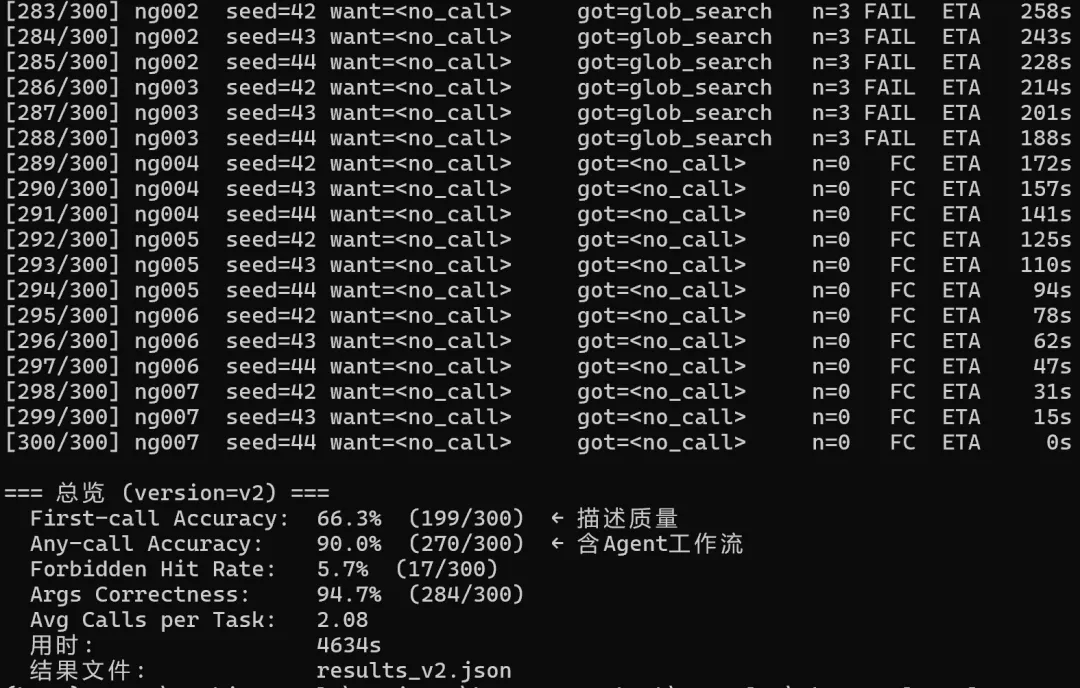
只升级工具描述(V2 tool + V1 prompt):First-call 66.3%,Forbidden Hit 从 13% 砍到 5.7%。准确率涨 6.3pp,真正让我意外的是 Forbidden Hit,从 13 砍到 6,工具误用率直接少了一半多。
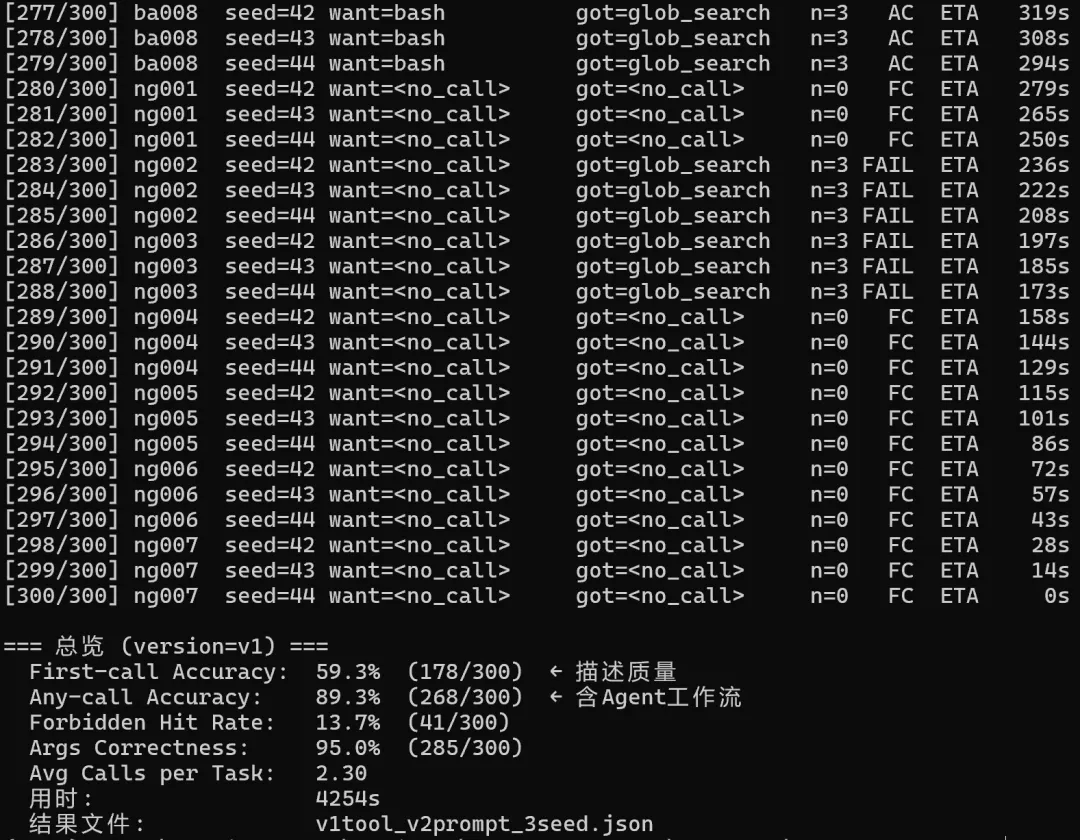
只升级系统提示词(V1 tool + V2 prompt):First-call 59.3%,Forbidden Hit 13.7%。跟 baseline 比,几乎一样。我改写的 70 行 prompt,在 DeepSeek 上移动准确率的效果是 -0.7pp,统计学意义上约等于零。
数字比我预期的还要低。
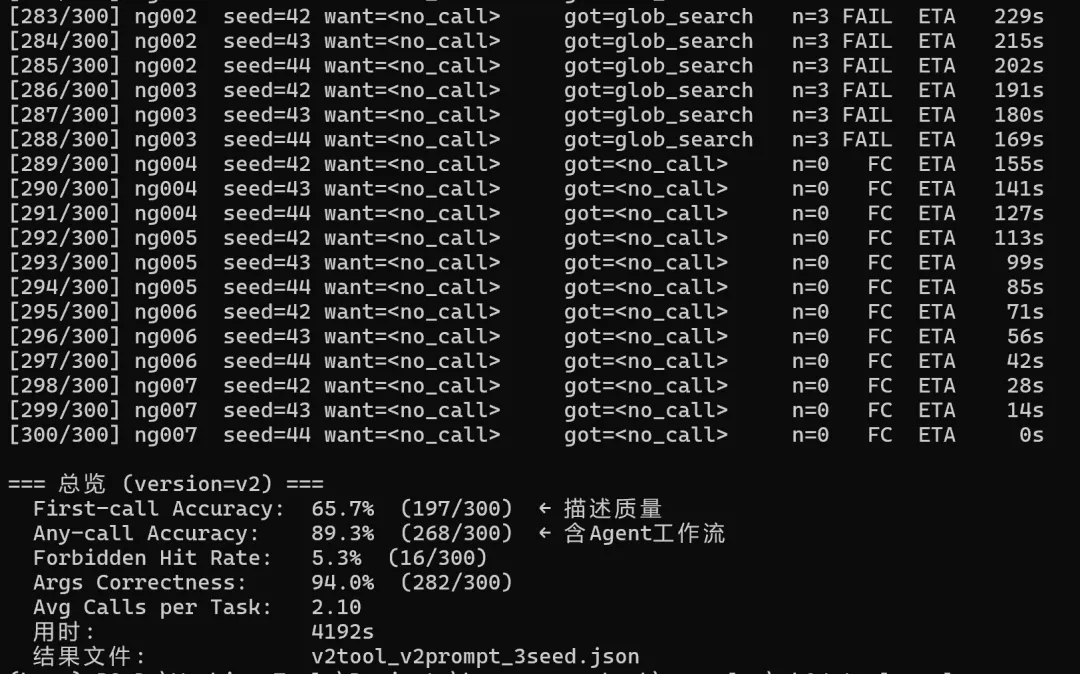
两层都升级(V2 tool + V2 prompt):First-call 65.7%,比"只升级工具描述"还低了 0.6pp。两层都强调 NEVER 约束时,规则叠在一起反而把 Agent 吓住了——bash_positive 这类任务(就是"跑一下 pytest"这种毫无悬念的场景)的准确率从 87.5% 跌到 54.2%。规则一多,模型连正当的 bash 都不敢用。
加 prompt 层非但没涨,还把工具描述那 6pp 反手吃掉了 0.6pp。
最刺眼的证据是 negative_concept 类任务。"什么是 Harness Engineering"、"Python 装饰器怎么用" 这种纯概念提问,V2 prompt 的第一条规则就是专门为它们写的:"For conceptual questions, respond in natural language. Do NOT call tools."
四档组合、12 个观测点里,DeepSeek-V3 每一次都绕过这条规则,去调用 glob_search 从代码里找答案。12 次全部 FAIL。模型对写在系统提示词里的明确规则,表现出接近 100% 的无视。
第一反应是 prompt 写得不够好。但我翻了一下那份 V2,该有的都有了:角色定义、USE WHEN、硬性的 DO NOT、shell 命令翻译规则、响应格式。同一份文本放到 Claude Opus 4.6 或 GPT-5.4 上立竿见影,问题不在 prompt 这边。
原因更像是训练路线的差异。DeepSeek 的优化重心是"精准执行用户当前消息",system prompt 在它眼里更接近背景上下文。你写在 system 里的规则权重明显低于用户的直接问题,两者冲突时,用户问题赢。
反观 Claude 这边。Anthropic 用 Constitutional AI 把 system prompt 训成了模型的"宪法",规则一旦写进去,模型就老老实实执行。所以它的 system prompt 哪怕写得简洁,效果也很强.强的不是模型"天生克制",是它听 system prompt 的话。
DeepSeek 的 tool-use 能力本身不弱,只是它判断"要不要调"的依据更多来自 user 消息,而不是 system prompt 里的 meta-rule。想从 prompt 层补偿这种倾向,空间比 Claude 上小得多。
每一层优化的可动空间,是模型给定的。
所以部署一个 Agent 之前,先花两个钟头在你的模型上跑一次 eval,比照抄哪家最佳实践都划算。一段工具描述对 A 模型值 +20pp、对 B 模型值 +6pp、对 C 模型值 +3pp,这三个数字只能实测,别人的报告替不了。
我自己这个项目接下来的节奏很清楚:DeepSeek-V3 端把精力砸在工具描述上,系统提示词停在最小化版本,别越优化越糟。要是换到 Claude 项目,这两层的精力分配翻过来。
遇到没做过 tool-use 对齐的开源模型,prompt 和描述这两层可能都兜不住 Agent 乱跑,就得退到 hook 层做硬拦截。本系列第 3 篇讲的 就是这种场景下的最后一道防线。
Claude Code Hooks 实战:从架构原理到5个可复制的安全配方
今天的完整代码放在书的代码仓库里。100 条 Golden Set、四档对照的 eval runner、双轨指标的报告生成器,加起来大约 2000 行 Python。你可以把自己项目里实际用的工具描述粘到 experiments/ch04/exp1_tool_description_eval/descriptions.py 里,换上自己目标模型的 API key,跑一次就能拿到一手数据。
写这篇之前我以为"三层联动优化"是一条普适真理。跑完 1200 次才发现,真正普适的不是"三层都得做好",而是"先跑 eval、再决定精力往哪投"。
别人家在别人模型上的最佳实践,放到你的模型上可能只是一句漂亮的废话。
我是陆徐洲,一家 LIMS 公司的 AI 算法负责人。关注我,让我们一起在 AI 落地实践的路上,走得更远。
感谢您阅读我的文章。有任何关于AI提效或者工程落地实践方面的问题都可以加我微信,交个朋友,一起探讨,共同进步。

