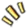夜雨聆风
夜雨聆风点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
我研究 Hermes Agent 的时候有个习惯:只看文档没用,必须自己亲手跑一遍。
光看 README 你永远不会发现,原来"自学习"这件事,是真的会在你电脑上写文件的;原来 Skill 不是抽象概念,跑完一轮任务就能看到一个 markdown 文件躺在那。
所以这一篇,我把第一次上手 Hermes Agent 的全过程,从 0 跑通讲一遍。包括环境怎么配、模型怎么挂、第一轮任务该跑什么、跑完后看哪些产出。
读完这一篇,你应该能在自己电脑上跑出第一份 MEMORY.md 和 SKILL.md,对"自进化 Agent"有第一感性认知。
上手前先想清楚一件事
很多人上来就装环境、配模型、跑命令,跑完之后还是说不清"我刚刚到底干了啥"。
所以在你下命令之前,我建议先想清楚:你这一轮上手,是为了验证哪件事?
我的答案很明确:我要让 Hermes 完成一件真实任务,并产出第一个 Skill。
不是为了听它打招呼,不是为了让它写一段 hello world,是要让它做一件你平时会做的事,然后看它能不能把这件事的"做法"沉淀成一个 markdown 文件。
带着这个目标,整个上手过程就有了主线。每一步你都能问自己:这一步是不是在朝"产出第一个 Skill"靠近?
如果不是,跳过它没问题。
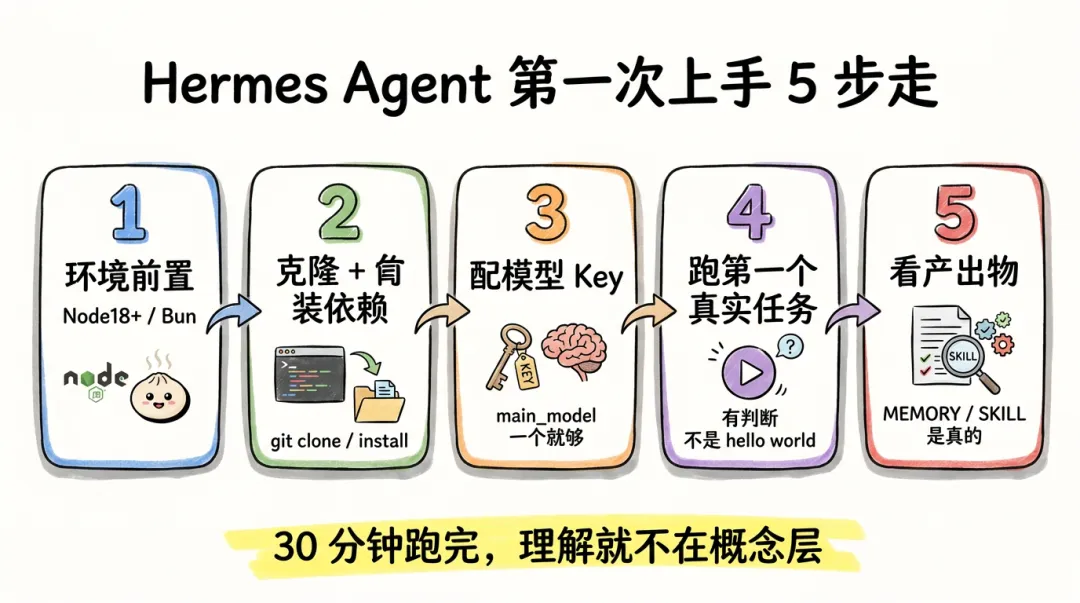
环境前置:3 件事先准备好
我装的过程中踩过几个坑,先把要点列前面。
第 1 件:Node / Bun 二选一
Hermes Agent 的核心是 TypeScript / JavaScript 项目。它对 Bun 友好度更高(启动快、原生 TS)。如果你机器上已经装过 Node 18+,先用 Node 也行。
# 或
bun -v
我自己用 Bun,主要是因为它启动 Agent 这种"长期跑"的进程时延迟更友好。你怎么舒服怎么来。
第 2 件:模型 Key
至少要一个能跑的 LLM 接口。常见三选一:
我建议第一次上手选 Anthropic 或 OpenAI 的官方接口,因为:
调通了之后再换自家服务,少绕弯路。
第 3 件:一个工作目录
Hermes 跑起来后会往磁盘写东西:MEMORY.md、USER.md、SKILL.md、session 数据库。
强烈建议你单独开一个目录,比如 ~/projects/hermes-playground/。不要直接在你正经的项目目录里跑,免得日后要清理。
安装:别怕第一次报错
把仓库 clone 下来:
cd Hermes-Agent
装依赖:
bun install
# 或用 pnpm / npm
pnpm install
第一次装大概率会有几个 warning,先不管。如果有 error 阻塞了,常见的就两类:
类型 1:Node 版本太低
报 Unsupported engine 或者 ?? 这种语法报错,多半是 Node < 18。升一下版本就行:
nvm use 20
类型 2:原生模块编译失败
某些依赖在 macOS 上要 Xcode CLI Tools,Linux 上要 build-essential。报 node-gyp 之类的,先把工具链补齐:
xcode-select --install
# Ubuntu / Debian
sudo apt install build-essential python3
我第一次装的时候卡在 better-sqlite3 编译失败,就是少了 Xcode CLI。补完一次性通过。
配置模型:别一开始就配 5 个
Hermes 配置文件里通常会有一堆模型槽位,比如 main_model、review_model、memory_model 之类。
很多人一上来就想"我要给每个槽位配一个最强的模型",结果配出来一堆 key 没一个跑得通。
我的建议:第一次上手只配一个 main_model 就行。
参考配置(.env 或 config.json,具体看你 fork 的版本):
HERMES_MAIN_MODEL=claude-3-5-sonnet-20241022
或者:
HERMES_MAIN_MODEL=gpt-4o
记住一句话:你只是在验证"这个 Agent 能不能动",不是在选最优配方。
跑通之后再去调第二个 review 模型,到时候你会更清楚每个槽位是干嘛的。
第一次跑:让它干一件你今天本来就要干的事
很多教程的"hello world"是让 Agent 写个 fizzbuzz。我觉得太假。
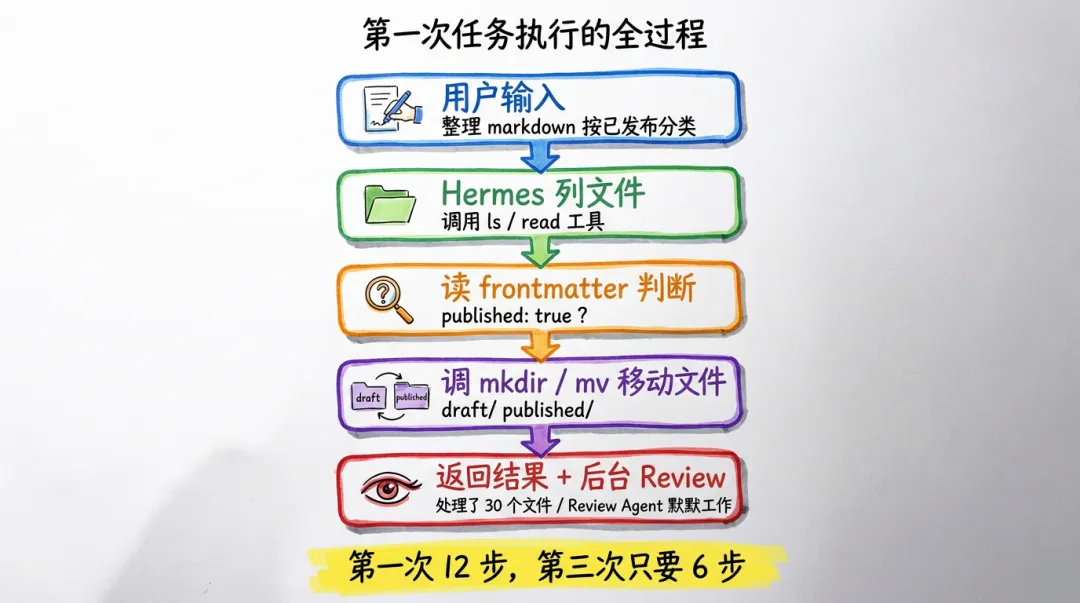
我第一次让 Hermes 干的事是:帮我整理一下当前文件夹里的 markdown 文件,按"未发布"和"已发布"分两个子目录。
为啥选这个?
- 它是真实的整理任务,我反正每周都要做一次
- 涉及到"读文件 → 判断 → 移动文件"几个工具调用
- 整理规则是有"判断标准"的,正好可以让 Hermes 提取成 Skill
- 跑完之后我能立刻验证:它有没有把这件事记下来
启动 Agent:
# 或者你 fork 里定义的入口命令
然后在 prompt 里输入:
draft/ 和 published/ 两个子目录。判断标准是文件 frontmatter 里
有没有 published: true。
第一次跑你会看到几件事按顺序发生:
- Hermes 打招呼,说它要先列文件
- 调 ls / read 工具看文件列表
- 一个个读 frontmatter
- 调 mkdir / mv 工具把文件挪到对应目录
- 跑完,告诉你处理了几个文件
这一切看起来跟普通 Agent 没区别。但真正的差异,从这里才开始。
任务跑完之后才是重头戏
普通 Agent 跑完任务就结束了。
Hermes 跑完之后,会安静地在后台再做一件事:让 Review Agent 评估你刚才这次任务,决定要不要把它沉淀进 Memory 或 Skill。
这件事可能不会立刻展示在你 UI 上,但它会改你的工作目录里的几个文件。
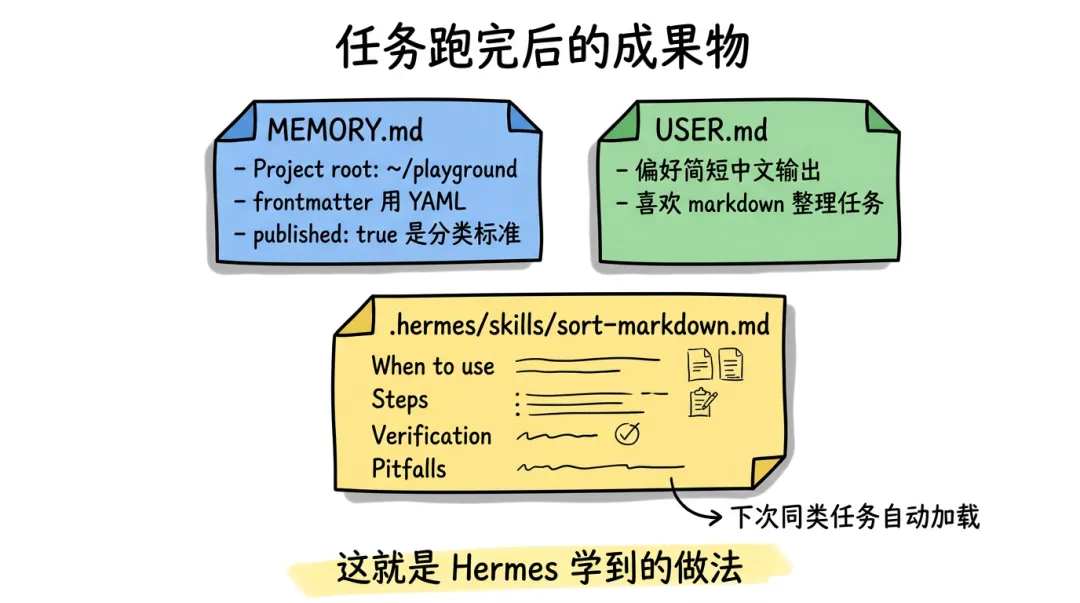
所以任务跑完,我会立刻去看 3 个文件:
cat MEMORY.md
cat USER.md
ls .hermes/skills/
如果一切顺利,你会看到:
MEMORY.md 里多了一两行环境/项目事实:
- Markdown files use YAML frontmatter with `published` boolean.
- Default sort: published files go to `published/`, drafts to `draft/`.
SKILL 目录下出现了一个新的 markdown:
打开这个 Skill,里面会有:
这个文件,就是 Hermes 从这次任务里学到的"做法"。
下次你再让它做类似任务,它会在拼 system prompt 的时候自动把这个 Skill 拽进上下文,相当于"自带攻略"。
这才是 Hermes 区别于普通 Agent 的真正意义。
第一次跑 vs 第三次跑
我第一次跑的时候,整理 30 个 markdown 文件用了大概 12 步工具调用。
第三次跑的时候,因为 Skill 已经在那里了,Hermes 拼 prompt 的时候会优先读 Skill,整个流程压到 6 步左右。
这是我第一次直观感受到"它越用越快"。
不是因为模型变快了,也不是因为我换了机器,是因为它把这次的"做法"沉到了 Skill 里,下次直接抄答案。
我踩过的几个坑
坑 1:MEMORY.md 没生成
任务太简单(比如只问它"你好吗"),Review Agent 会判断"不值得保存",所以什么都不写。
解决:让它干一件有判断标准的活,让它真的"用工具"而不是"聊天"。
坑 2:Skill 写得很糟糕
第一次跑出来的 Skill 经常很糙,可能就两三行 step。
这是正常的。Hermes 设计上 Skill 是允许"持续 patch"的,第一版只要有骨架就行,下次复用时不顺利的地方它会自动改。
不要追求一次 Skill 写得完美,那不是 Hermes 的工作方式。
坑 3:Review Agent 把无关信息塞 Memory
有时候你随口说一句"我电脑挺慢的",它真的会把这条写进 MEMORY.md。
解决:直接打开 MEMORY.md 删掉那一行就好。Hermes 把 Memory 文件设计成可读可写的纯文本,就是为了让你能直接干预。
坑 4:模型 token 涨太快
每次任务都会带 Memory + 当前激活的 Skill 进系统 prompt。如果你 Memory 写得太啰嗦、Skill 攒得太多,token 涨得很猛。
解决:定期清理 Memory(删过期事实),按场景给 Skill 打 tag,只在相关任务时激活。后面专门有一篇会聊 Memory 治理。
上手 vs 稳定使用的心智差别
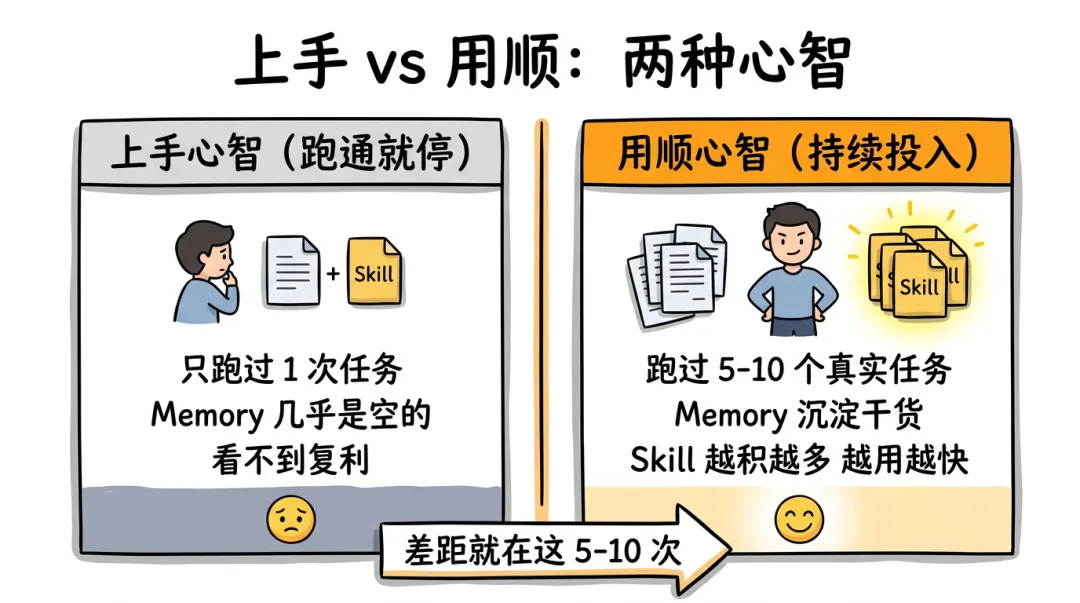
第一次跑通和真正"用顺",不是一回事。
我观察到一个规律:很多人停留在"我跑通了第一次",没继续往下走,所以始终没体验到 Hermes 真正的好处。
第一次跑通只是"看到自学习这件事是真的"。
真正用顺,是要跑过 5-10 个真实任务,让 Memory 里有几条干货事实、Skill 目录里有 3-5 个能复用的能力,你才能感觉到"这玩意确实在帮我"。
我的上手 checklist
如果你今天就要从 0 跑通,给你一个我自己用过的 checklist:
□ 一个 LLM Key(Anthropic / OpenAI 任选)
□ 单独建一个 playground 目录
□ 只配 main_model,不要贪心
□ 选一个真实有判断的任务(不是 hello world)
□ 跑完后立刻 cat MEMORY.md / ls .hermes/skills/
□ 同样的任务再跑 1-2 次,体感越用越快
□ 翻一下生成的 Skill,必要时手动 patch
跑完上面 8 步,你对"自进化 Agent"的理解就不会再停留在概念层面了。
聊聊我的理解
第一次跑 Hermes,我最大的感受不是"它有多智能",而是"它把 Agent 的工作流程从一次性变成了持续性"。
普通 Agent 给我的感觉像零工。这次活干完了,下次再来,它对你一无所知。
Hermes 给我的感觉更像是雇了一个新员工。第一天上班磕磕绊绊,但他每天都在写日志、记规范、攒经验。一个月后他做同样的事会快得多,也更不容易出错。
这种"沉淀感",是我之前用各种 Agent 没体验过的。
所以如果你也想真正理解自进化 Agent 是什么,别只看 README,别只看视频。今天花 30 分钟,把它跑起来,让它替你干一件你今天本来就要干的活。
跑完之后,去看那个生成的 Skill 文件。
那一刻你会理解,为什么这个系列后面值得继续看下去。

往期推荐