 夜雨聆风
夜雨聆风说实话,2025年最让我兴奋的AI趋势,不是GPT-5又多了多少参数,而是——大模型终于能跑在你的手机上了。
没错,不是云端API调用,不是租GPU服务器,是真的在你手里那台设备上,离线运行一个能对话、能推理的AI大模型。树莓派5能跑到18 tokens/s,iPhone 16 Pro能流畅跑7B模型,就连几百块钱的物联网开发板都能部署端侧AI了。
这背后,是一整套从云端到端侧的模型迁移技术栈。今天这篇文章,我把模型压缩、量化、蒸馏这三大核心技术掰开揉碎了讲,再配合llama.cpp等工具的实操指南,让你看完就能动手部署。
一、为什么要搞端侧部署?云不好吗?
先说一个数据:一个7B参数的模型,FP16精度加载需要14GB显存。这意味着什么?你得有一张RTX 4090才能勉强跑起来。而消费级设备的内存通常只有4-8GB,手机上可能就2-3GB可用。
但端侧部署的需求是真实存在的:
隐私场景——医疗数据、金融数据、个人隐私对话,你敢全传到云端吗?端侧部署让数据不出设备,天然满足合规要求。
离线场景——无人机在山区巡检、机器人在工厂作业、智能手表做实时翻译,这些场景网络不稳定甚至完全断网,云端API根本靠不住。
延迟场景——自动驾驶的决策延迟要求毫秒级,云端的网络往返就要50-200ms,端侧推理能做到5ms以内。
成本场景——每次API调用都要钱,一个月下来成本惊人。端侧部署一次投入,零边际成本无限次调用。
说白了,端侧AI解决的是"最后一公里"问题。模型再强大,跑不到用户设备上,永远是实验室里的玩具。
二、三大压缩技术:量化、剪枝、蒸馏
要把一个动辄几十GB的大模型塞进手机或树莓派,必须大幅压缩。业界主流的压缩手段有三个,我逐个讲清楚。
1. 量化(Quantization):精度换空间
量化是性价比最高的压缩手段,也是目前端侧部署的标配操作。
原理说起来很简单:把模型权重从高精度(FP32/FP16)转成低精度(INT8/INT4)。FP16每个参数占2字节,INT4只需要0.5字节,模型体积直接缩小4倍。
实际效果有多猛?看这组数据:
· FP16:7B模型需要14GB显存
· INT8量化:降到约7GB,精度损失极小
· INT4量化:降到约4GB,精度损失可控
· INT2量化:降到约2GB,但精度开始明显下降
目前主流量化方法有三种:
GPTQ——基于Hessian矩阵的二阶信息量化,逐层最小化量化误差。适合GPU推理,精度保持最好,但量化过程本身需要GPU。
AWQ——激活感知权重量化,核心思路是保护重要的权重通道不被过度量化。不需要反向传播,速度快,精度也不错。
GGUF——llama.cpp原生支持的量化格式,提供Q2_K到Q8_0多个级别。其中Q4_K_M是最推荐的"甜点"级别,在精度和体积之间取得最佳平衡。
实操建议:先试Q4_K_M量化,如果精度不够就升到Q5_K_M或Q8_0,如果还嫌大就降到Q3_K_M。大多数场景下Q4_K_M就够了。
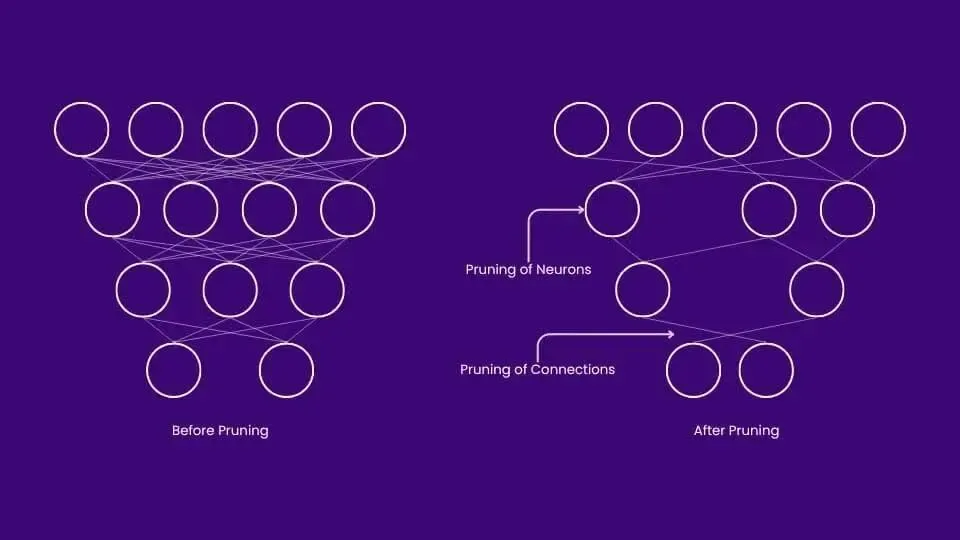
2. 剪枝(Pruning):砍掉冗余参数
剪枝的思路更直接——直接把不重要的参数砍掉。
一个训练好的大模型里,有大量权重接近于零,对推理结果几乎没有影响。剪枝就是把这些"废物"参数移除,让模型变得更小更快。
剪枝分几种粒度:
非结构化剪枝——逐个权重剪,可以剪得很细,但硬件加速器不好优化。
结构化剪枝——按通道、按层剪,虽然压缩率略低,但GPU/TPU能高效执行。这是目前主流方案。
稀疏化——NVIDIA的2:4结构化稀疏,每4个权重保留2个,压缩50%的同时硬件原生支持加速。
实际应用中,剪枝通常和量化配合使用:先剪枝去掉冗余结构,再量化降低剩余权重的精度,效果叠加。
3. 知识蒸馏(Knowledge Distillation):大老师教小学生
蒸馏是最优雅的压缩方式——让大模型(教师模型)的"知识"迁移到小模型(学生模型)。
具体做法是:用教师模型的输出概率分布(软标签)来训练学生模型,而不是只用硬标签。学生模型不仅学到了"这是什么",还学到了"为什么是这个",保留了很多教师模型的"暗知识"。
经典的例子:DistilBERT把BERT压缩了40%,速度快了60%,还保留了97%的语言理解能力。最近的趋势是多级蒸馏——从70B模型蒸馏到13B,再从13B蒸馏到3B,每一级都保留大部分能力。
三、实战:用llama.cpp在消费级设备上跑大模型
理论讲完了,直接上手。这里给一个完整的端侧部署实战流程。
Step 1:选模型
端侧部署推荐选择3B以下的小模型:
· Qwen2.5-1.5B-Instruct:中文能力优秀,1.5B参数量适合手机
· Llama-3.2-3B-Instruct:Meta出品,英文能力强劲
· Phi-3-mini-4K:微软出品,推理能力超出参数量级别
· Gemma-2-2B:Google出品,多语言支持好
Step 2:下载量化模型
直接从HuggingFace下载已经量化好的GGUF格式模型:
# 安装huggingface-cli
pip install huggingface-hub
# 下载Qwen2.5-1.5B的Q4_K_M量化版
huggingface-cli download \
Qwen/Qwen2.5-1.5B-Instruct-GGUF \
qwen2.5-1.5b-instruct-q4_k_m.gguf \
--local-dir ./models
一个1.5B模型的Q4_K_M量化版大约1GB左右,手机存储完全放得下。
Step 3:编译llama.cpp
# 克隆llama.cpp
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# PC上编译(带CUDA加速)
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j$(nproc)
# Android交叉编译
cmake -B build-android \
-DCMAKE_TOOLCHAIN_FILE=$NDK_ROOT/build/cmake/android.toolchain.cmake \
-DANDROID_ABI=arm64-v8a \
-DANDROID_PLATFORM=android-28
cmake --build build-android --config Release -j$(nproc)
Step 4:运行推理
# 在PC/Mac上运行
./llama-cli -m ./models/qwen2.5-1.5b-instruct-q4_k_m.gguf \
-p "用一句话解释什么是量子计算" \
-n 256 --temp 0.7
# 在树莓派5上运行(8GB内存)
./llama-cli -m ./models/qwen2.5-1.5b-instruct-q4_k_m.gguf \
-p "你好,请做个自我介绍" \
-n 128 -ngl 0 --threads 4
-ngl 0表示不用GPU层(树莓派没有),纯CPU推理。实测树莓派5能跑到10-15 tokens/s,对话体验完全可用。
Step 5:手机端部署
对于Android手机,有两种方案:
方案A:Termux + llama.cpp——在手机上安装Termux终端,编译llama.cpp,直接命令行运行。适合开发者调试。
方案B:MLC LLM——MLC LLM提供了更友好的移动端部署方案,利用手机NPU加速,在旗舰手机上推理速度比纯CPU快3-5倍。

四、端侧AI的硬件生态
不是所有设备都适合跑大模型,选对硬件很关键。
手机阵营:
· iPhone 16 Pro(A18 Pro):8GB统一内存,跑3B模型流畅,约15 tok/s
· 骁龙8 Gen 3/8 Elite:支持INT4 NPU加速,7B模型可用
· 联发科天玑9400:APU 790加速器,端侧AI能力强
开发板阵营:
· 树莓派5(8GB):ARM Cortex-A76,纯CPU跑1-3B模型
· NVIDIA Jetson Orin Nano:GPU加速,能跑7B量化模型
· ESP32-S3:超低功耗,只能跑几十MB的TinyML模型
PC/NPU阵营:
· Apple M4 MacBook:统一内存架构,跑13B模型毫无压力
· Intel Core Ultra(Meteor Lake):内置NPU,支持INT8加速
· AMD Ryzen AI 300系列:XDNA NPU,50 TOPS算力
选硬件的黄金法则:内存 > 算力 > 功耗。大模型推理首先是内存墙问题,其次才是算力。4GB内存以下基本只能跑1B模型,8GB可以跑3B,16GB以上才能跑7B。
五、未来趋势与实用建议
端侧AI的发展速度远超预期。几个值得关注的趋势:
混合推理架构——简单问题端侧处理,复杂问题云端处理,动态切换。Google的Gemini Nano就是这个思路。
模型持续小型化——2025年,3B模型的性能已经超过2023年的70B模型。模型架构的改进让小模型越来越强。
专用AI芯片普及——从手机到PC到IoT,NPU正在成为标配。未来每台设备都有AI加速能力。
如果你现在就想开始端侧AI部署,我的建议是:
第一步:买一台树莓派5(8GB版,约400元),这是最低成本的入门硬件。
第二步:用llama.cpp跑一个Qwen2.5-1.5B的Q4_K_M量化模型,体验纯CPU推理。
第三步:尝试自己量化模型——下载FP16权重,用llama.cpp的quantize工具转换不同量化级别,对比精度和速度。
第四步:把模型部署到手机上,用MLC LLM或Termux方案。
端侧AI不是未来,是现在。当你第一次在离线状态下跟一个跑在自己设备上的AI流畅对话时,你会理解这种技术带来的震撼——AI不再是云端的神,而是口袋里的助手。
🔥 觉得有用?转发给同样关注AI落地的朋友
关注【老马AI观察录】,获取更多AI技术实战干货
你有什么端侧AI部署的经验或问题?欢迎留言交流 👇
