 夜雨聆风
夜雨聆风AI 热潮之下,LLM、MCP、Prompt、Agent 等新名词层出不穷。但你真的分得清它们各自的概念,以及彼此之间如何关联吗?
一、LLM(Large Language Model,大语言模型)
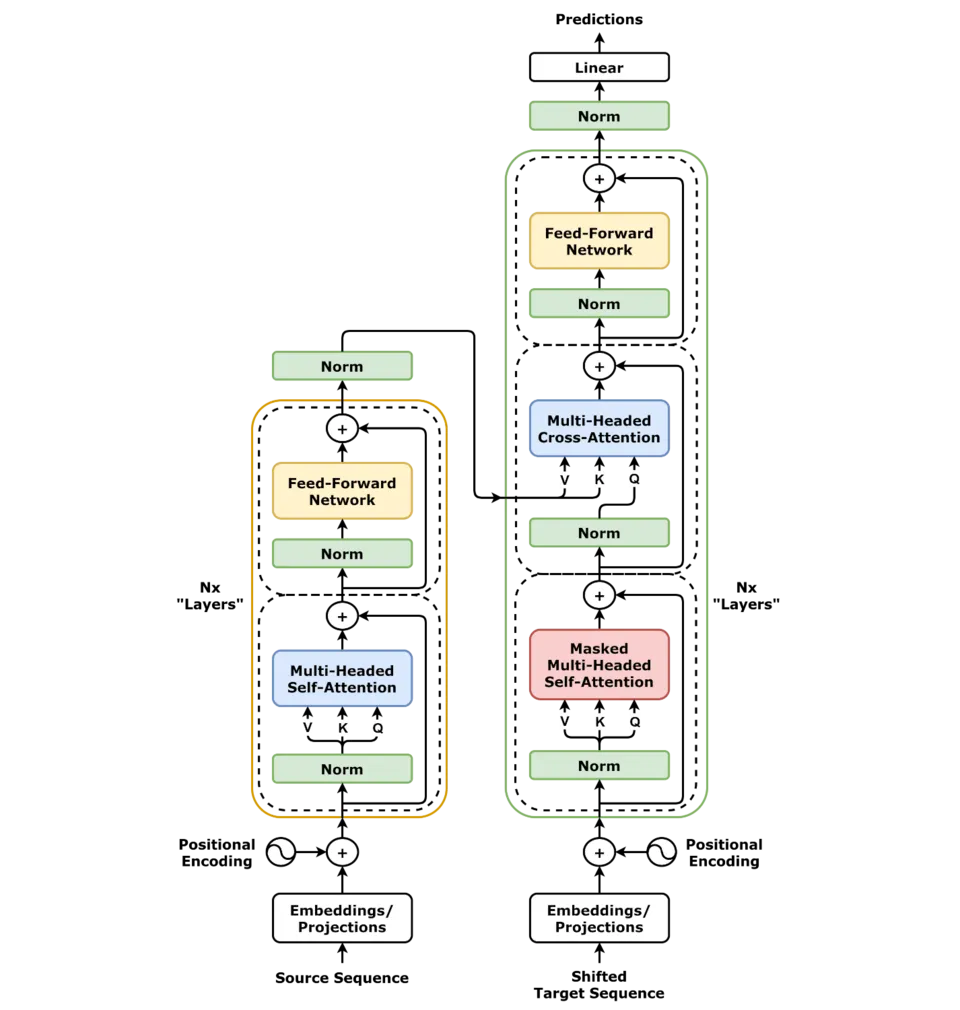
LLM即“大语言模型”,是当前各类AI应用的底层引擎。无论是聊天机器人、代码生成工具,还是智能写作助手,背后都运行着一个或多个大语言模型。目前,绝大多数LLM都基于Transformer架构构建(如下图所示)。
Transformer通过一种自注意力机制,让模型能够同时关注输入文本中的所有位置,从而更好地理解上下文关系,并且相对于RNN或LSTM架构,Transformer可以并行处理数据,大幅提升训练效率,从而能够处理更长的文本序列。
目前常见的LLM代表有:GPT、LLaMA、kimi、通义千问等等。
二、Token(词元)—大语言模型的基本处理单元
Token 是大语言模型理解和生成文本的最小原子单位。
由于计算机无法直接处理人类语言中的字符或单词,且神经网络只能处理数字,因此需要将原始文本转换成一系列数字,这个过程就是Tokenization(分词)。
但如何分词,是一个重大难点。如果按“单词”切分,词典会非常大(数百万词),且无法处理生词;如果按“字符”切分,虽然词典很小,但每个字符携带的信息太少,模型需要处理很长的序列才能理解一个单词,效率低。目前最主流的方案是子词切分(Subword Tokenization),即把常见单词保留为完整 Token,把罕见或未见过的单词拆成更小但仍有意义的子词组合。
例如:"unhappiness"可能被拆成"un"+"happiness"或"un"+"happi"+"ness"。
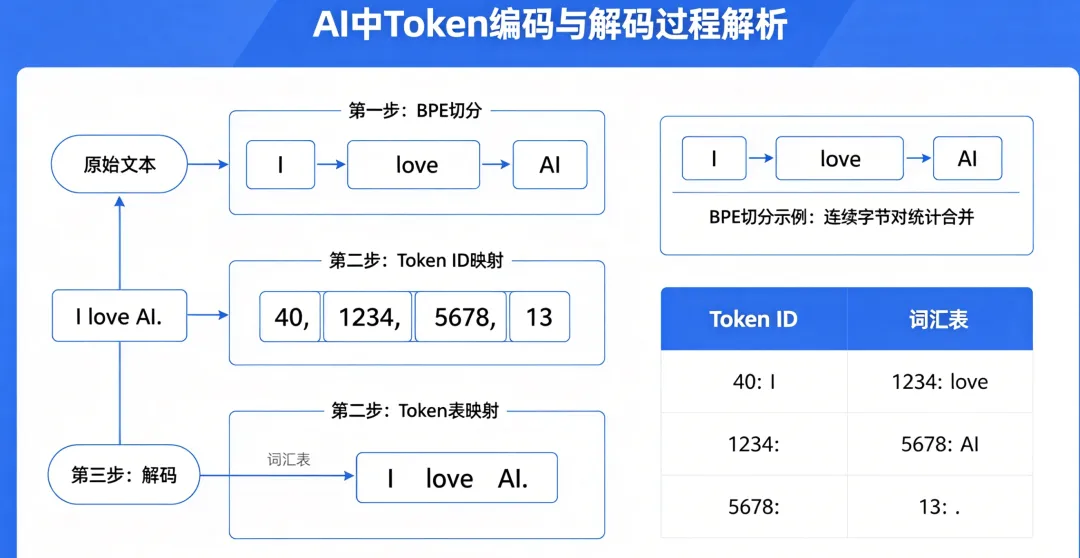
因此,大语言模型在语义转化过程中,是编码(文本 → Token ID)和解码(Token ID → 文本)过程。
以下面例子为例:
(1)原始文本:
"I love AI."
(2)编码步骤:
①预处理:统一空格处理。文本变为:IĠloveĠAI.
②切分:
该文本被切分为:["I", "Ġlove", "ĠAI", "."]
"I"(ID: 40)
"Ġlove"(ID: 1234) (注意开头的Ġ表示这是一个词的开头,而不是内部子词)
"ĠAI"(ID: 5678)
"."(ID: 13)
③映射为 Token ID 序列:[40, 1234, 5678, 13]
③解码步骤:
模型输出一个概率分布,选择最高概率的 Token ID 序列[40, 1234, 5678, 13],然后通过词汇表反查:
40→"I"
1234→"Ġlove"(Ġ在解码时通常会被还原为普通空格,得到" love")
5678→"ĠAI"(解码为" AI")
13→"."
最终解码回原始文本:"I love AI."
注意:解码时 Ġ 符号被转换为空格,所以 "I" 后直接跟空格 + "love"。这是许多 BPE 编码器的约定。
目前,绝大部分厂商出售的API也就是Token的使用统计,平均来讲,一个Token大概相当于0.75个英文单词或者1.5个汉字,因此,在处理大的文本时,半天内能使用几百万Token就不足为奇了。
三、Context(上下文)
在理解了Context和Token后,你在使用AI时肯定会好奇,它为什么能够记得住你前文内容,仿佛有记忆一样,这就引入了一个概念Context(上下文)。Context 是模型在处理当前 Token 时所能“看到”的所有先前 Token 的总和,它相当于模型的短期工作记忆,决定了模型理解当前输入所依赖的信息范围。
LLM 本身是无状态的——每次推理时,模型只根据当前输入的 Token 序列计算输出,并不会自动“记住”之前的对话。要让模型产生连贯的多轮对话或长文档理解,就需要把之前的交互历史或文档内容不断拼接到新的输入中。这个拼接起来的完整 Token 序列,就是模型在该次推理中的 Context。
例如,在元宝中,你发送“我叫小明”,模型回复“你好,小明”。然后你问“我的名字是什么?”,客户端并不会只发送“我的名字是什么?”,而是会把上一轮的用户输入和模型回复也一起打包成新的 Context:
text
用户:我叫小明助手:你好,小明用户:我的名字是什么?
模型看到整个 Context 后,才知道“我的名字”指的是“小明”。如果没有之前的对话历史,模型就无法正确回答。
Context 长度以 Token 数为单位:Context 越长,包含的 Token 数量越多。每次推理时,模型需要处理所有这些 Token。在一次 API 调用中,你发送的所有内容(包括系统提示、历史对话、用户当前输入等)的 Token 数之和,就是本次使用的 Context 长度。为了让模型知道 Token 的顺序,每个 Token 在 Context 中都带有位置信息。Transformer 通过位置编码(或相对位置偏置)来区分“第一个词”和“最后一个词”。
所有 LLM 都有一个硬性上限,称为上下文窗口(Context Window)。例如:
| 模型 | 上下文窗口(Token 数) |
|---|---|
| GPT-3.5 (早期) | 4,096 |
| GPT-4 (8K) | 8,192 |
| GPT-4 Turbo | 128,000 |
| Claude 3 | 200,000 |
| Gemini 1.5 Pro | 2,000,000 |
模型无法处理超过窗口长度的输入,超出后会截断最早的部分(如对话开头的几轮),或者对长文档进行切片、分块处理。
因此,长context也伴随着以下问题:
①显存与计算成本:Transformer 的自注意力机制计算复杂度与 Context 长度的平方成正比(O(n²))。Context 越长,推理越慢、越贵,这也是为什么长上下文模型需要采用稀疏注意力等技术。
②“中间丢失”现象:研究表明,LLM 对长 Context 中间部分的信息 recall 能力较弱,而更擅长记住开头和结尾。
目前解决以上问题的方法主要有:
①检索增强生成(RAG):当文档总长度远超上下文窗口时(如 100 万字的书籍),不可能全部塞进 Context。RAG 的做法是先检索与当前问题最相关的几个片段,只把这些片段放入 Context,而不是放全文。
②主动压缩:一些高级用法会对对话历史进行摘要,用摘要 Token 替代原始的多轮对话,从而压缩 Context 长度。
四、Prompt(提示词)
Prompt 就是你输入给 LLM 的那段指令或问题,用来告诉模型你想要什么。例如:“请解释什么是区块链”。
为了提升大模型工作效率,好的prompt是必须的,换句话说,给别人讲述一件事情要想得到更高效的反馈,就得自己先把话讲的清晰明了。
五、Tool(工具)
大语言模型本质上还是基于数据库来训练的,因此要想获得实时信息,需要引入Tool,也就是外部工具。比如我想要获取今天的天气信息,但是模型的数据集只到25年,因此我需要给LLM接入天气预报查询工具才能获取最新的天气信息。
Tool 本质上是一个封装了特定功能的可调用函数,接收输入参数,执行操作(如查天气、算数学、发邮件),返回结果,LLM 本身不具备实时数据获取或外部动作能力,但通过调用 Tool 就能突破训练数据的局限。
六、MCP(统一的工具接入标准)
由于不同 LLM 接入 Tool 的协议标准各不相同——比如 GPT 有一套自己的标准,DeepSeek 也有另一套标准,工具开发者如果为每个模型单独适配,工作量会很大。为了解决这一问题,业界引入了 MCP(模型上下文协议),作为统一的工具接入标准。
在实际落地中,遵循 MCP 标准的工具通常会集中部署在某个 MCP 服务器(平台)上。只要某个 LLM 支持 MCP 协议,它就能直接调用该服务器上所有已集成的工具,无需为每个工具单独写适配代码。
七、Agent(智能体)
在 LLM 调用 Tool 的过程中,会遇到一个实际问题:完成一个复杂任务往往需要多次、按顺序或根据中间结果动态地调用多个工具。例如,“查天气 → 如果下雨就推荐室内活动 → 把结果发到邮箱”就需要依次调用天气查询工具、活动推荐工具、邮件发送工具。如果每次都靠人工手动触发,显然不现实。为此,引入了 Agent 概念。
Agent 是一个能够自主规划任务步骤、决策何时调用哪个工具、并根据工具返回结果继续行动的程序。它把 LLM 作为“大脑”,让 LLM 输出下一步该做什么(例如“调用天气API”、“调用邮件API”),然后 Agent 执行这些动作,并把执行结果再次喂给 LLM,循环往复,直到完成用户目标。
八、Agent Skill
每个人都有自己的习惯,比如我早上可能习惯起来看下当天热点新闻。如果使用一个通用 Agent,每次都需要说“帮我查一下今天的头条新闻”,重复多次就会很繁琐。Agent Skill 就是为了让 Agent 学习并记住用户的个性化行为模式而设计的功能模块。
简单来说,Agent Skill 是预定义好的一系列提示词、工具调用流程和默认参数的组合文档,允许用户将“一个常用的多步骤操作”封装成一个“技能”,之后只需说一个简单的指令(如“早安”)就能触发整个流程。
相比于普通 Prompt 每次都要写完整指令,Agent Skill 可以复用,且能包含多个步骤(先查天气、再读新闻、最后播报)。
Agent 内部会维护一个 Skill 注册表,用户需要在自己使用的Agent上加载进去,然后在用户说出触发词时,Agent 直接加载该 Skill并输出想要的信息。
