 夜雨聆风
夜雨聆风你拿手机扫了一下客厅,屏幕上那张普通照片,可能正在变成一张三维地图。
这件事听起来像装修 App 的小功能,但它后面牵着更大的问题:机器人要避开桌角,AR 眼镜要把虚拟物体放在真实地板上,自动驾驶要判断路边障碍物离自己多远,AI 不能只“看见”世界,它还得知道世界的深度、相机站在哪里、物体在空间里怎么排列。
标题:VGGT: Visual Geometry Grounded Transformer
作者:Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, David Novotný
机构:Visual Geometry Group, University of Oxford;Meta AI
发布时间:2025-06-10
原文链接:https://doi.org/10.1109/cvpr52734.2025.00499
老办法像一队测绘员
让电脑从照片里还原三维世界,过去从来不是一键生成的事,更像一队测绘员进了现场。先在多张照片里找同一个角点——这张图里的桌脚,是不是那张图里的桌脚;再反推出每张照片拍摄时相机的位置和角度;接着把这些对应点拉回三维空间,搭出一片稀疏点云;最后还要反复校正,像把一张歪了的地图一点点揉平。
这套传统方法叫 Structure from Motion,中文常译作“运动恢复结构”。它经典,也可靠,但麻烦在步骤多、调参多、后处理重。一旦场景里出现反光玻璃、重复纹理、模糊运动,整条链路就有可能卡住。
VGGT 问的是一个挺大胆的问题:能不能让一个大模型把这队测绘员的活直接接过去?输入可以是一张、几张,也可以是上百张同一场景的图片,模型一口气给出相机参数、深度图、点图和三维点追踪。换成白话,它不只说“这里有沙发”,还试着告诉你沙发离镜头多远、地板往哪儿延伸、每张照片分别是从什么角度拍的。
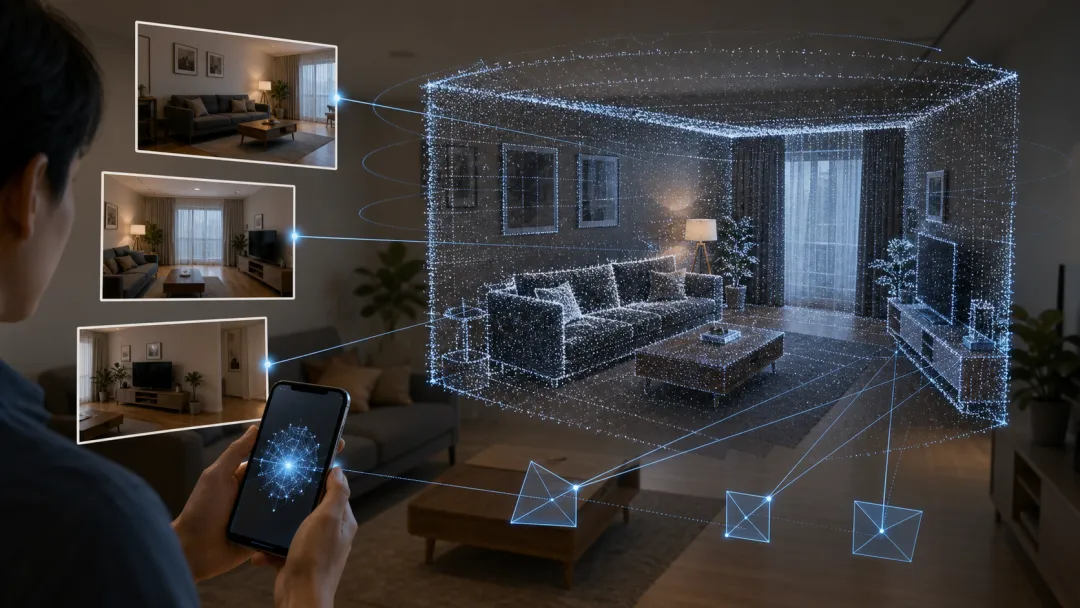
它不是“凭空想象”,而是在学几何
最容易被误会的一点是:既然挂着 Transformer 的名字,它是不是也和语言模型一样,靠"猜下一个词"的同款逻辑在脑补三维世界?没那么简单。VGGT 是一个前馈神经网络,所谓前馈,可以先粗略理解成"看一遍、直接给答案",不用像传统几何优化那样反复迭代。它确实仍在使用 Transformer 这种擅长处理关系的结构,但训练目标全部落在视觉几何上:相机位置、深度、点云、点轨迹,这些不是朋友圈滤镜,而是三维重建里实打实要用的量。
打个不太精确的比方:过去的三维视觉像教学生按公式解题,先找特征点、再列方程、再回头检查误差;VGGT 更像那种刷过无数带答案空间题的学生,看到新房间的几张照片,把解题草稿和答案一起写了出来。
快只是它的一面。论文报告里,VGGT 在多个三维任务上拿下了当时的领先成绩,相机参数估计、多视角深度估计、稠密点云重建、三维点追踪都在其中;项目页写得更直白:通常一秒之内就能把一个场景重建出来。热榜标题真正值得拎出来看的部分也在这里——不是 Transformer 被推翻,而是 Transformer 被逼着长出了一种"几何感",它得弄清照片之间的相互关系,弄清哪些像素背后是同一个真实点,弄清二维画面下面藏着的三维秩序。
如果它变可靠,很多设备会被革命
这类模型最先改变的,多半不是你手机相册里那些炫酷的 3D 动效,而是那些真正要"理解空间"的系统。机器人在房间里走动,不能只识别"那是椅子",还得知道椅背伸出来多少、腿在哪儿、自己能不能从旁边绕过去;AR 眼镜要把一块虚拟屏幕钉在墙上,光靠平面识别也不够,得有稳定的深度和相机姿态;影视、游戏、数字孪生、室内扫描,则统统被卡在同一个地方——从一堆照片到一份能用的三维结构,中间这段路太重了。
一次前向推理就能给出足够好的三维属性,意味着开发者可以砍掉一段沉重的后处理流水线,不用每次都等传统优化慢慢收敛,也不必把特征匹配、点云融合、相机校正拆成一堆脆弱步骤。更妙的是,它还能往下当别的任务的底座——论文里提到,把预训练的 VGGT 当作特征骨干,可以增强非刚性点追踪、新视角合成这些下游任务。它不只是一个"照片转点云"的工具,更像一个带着空间常识的视觉底盘。
快,不等于永远对
三维重建有一个天然的麻烦:照片里看不见的地方,模型只能靠经验脑补。桌子背面、玻璃反光、纯白墙面、天空、水面、快速运动的人,都会让问题立刻变难——模型可以给出一个看上去顺滑的结果,可顺滑不等于真实。
放在普通的娱乐场景里,这种"差不多"无伤大雅,扫个房间做预览,错一点也就是墙角歪了。可一旦走进机器人避障、工业测量、自动驾驶、建筑施工或安全巡检,三维结果就不能只看"像不像",还要追问"误差有多大、哪里不确定、能不能复核"。

还有一个绕不开的话题是商用边界。项目页显示,VGGT 原始模型权重并不是无条件可商用;团队后来给出了面向商业用途的新 checkpoint,附带许可限制。对开发者来说,这不是小字脚注,而是产品上线前必须先过的一道门槛。
所以 VGGT 最适合被当成一条方向的强信号——三维视觉正在从"手工几何流水线"走向"神经网络直接估计几何"。经典几何不会因为它就立刻退场,关键场景仍然得靠校正、优化和验证;但它确实把一个长期笨重的问题,推进到了一个更像大模型时代的形态。下次你拿手机扫一圈房间,AI 看到的也许不只是画面,它可能已经在心里悄悄量过尺了。
