 夜雨聆风
夜雨聆风
5 月 28 日,Anthropic 悄然发布了 Claude Opus 4.8。距离上一个大版本 Opus 4.7 才过去六个星期,快迭代,已经成了 Anthropic 的新常态。
对天天跟 AI 打交道的人来说,这次更新最打动人的地方,不是又刷高了几个基准分数,而是 AI 第一次真正学会了诚实。它愿意主动告诉你,「这里我不太确定,你最好再检查一下。」


为什么「会说我不确定」这么重要?
以前的 AI 有一个通病:越不懂越敢说,说错了就给你道歉一下,然后下次还敢。
哪怕是代码里藏着一个隐蔽的 Bug,它也可能自信满满地给你一段完美解决方案,导致你后面花更多时间 debug。
Opus 4.8 在编程任务中,把「漏掉代码缺陷」的概率降低了大约四倍。它不再一味追求显得聪明,而是更倾向于把自己的不确定区域标记出来,让人类可以介入把关。
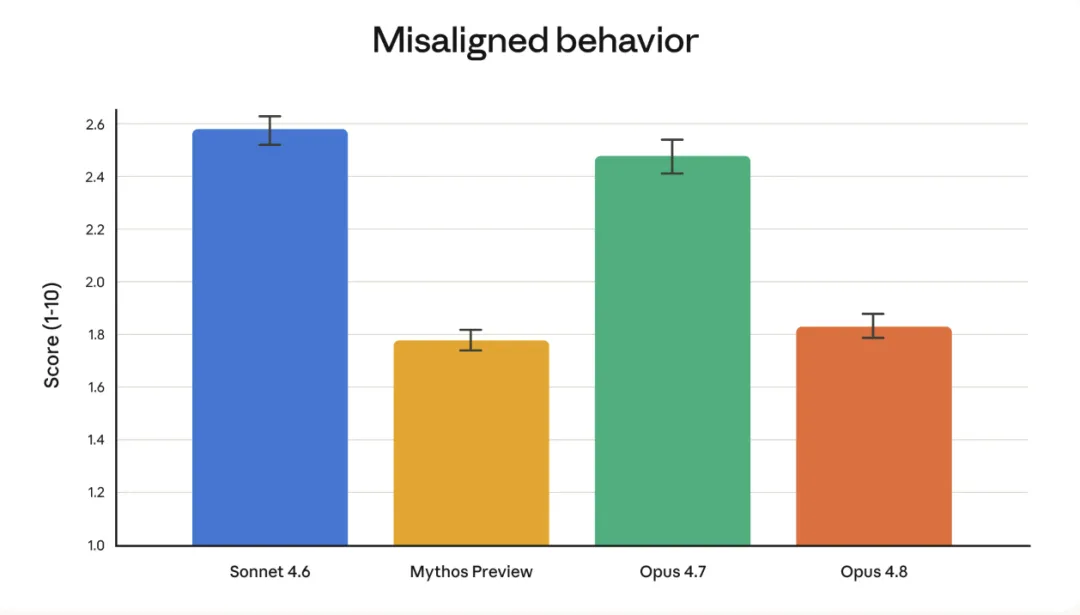
这听起来像是一件小事,但对真正用 AI 做复杂工程、研究、法律分析的人来说,简直是降维打击式的信任升级。在高风险场景里,一个「知道自己不知道」的 AI,比一个永远自信的 AI 要有价值得多。

性能上有哪些实打实的提升?
1、编码能力
SWE-bench Pro 从 64.3% 提升到 69.2%,SWE-bench Verified 也小幅前进到 88.6%。在真实世界的 GitHub 问题修复上,它的表现更加稳健。
2、代理任务与长时程工作
引入了 Dynamic Workflows(动态工作流),在 Claude Code 里一次可以拉起上千个并行子代理。它们可以分工、辩论、迭代,最后收敛出一个经过多轮验证的结果。这对大规模代码迁移、重构、自动化测试这类“长跑”任务特别友好。
3、努力程度控制
用户可以在 claude.ai 或 API 里手动选择“低、中、高、最大”思考强度,平衡速度、成本和深度。默认在编码任务里用 High,努力和性能的权衡更精细了。
4、速度优化
新增 Fast Mode,响应速度提升约 2.5 倍,成本也大幅下降。
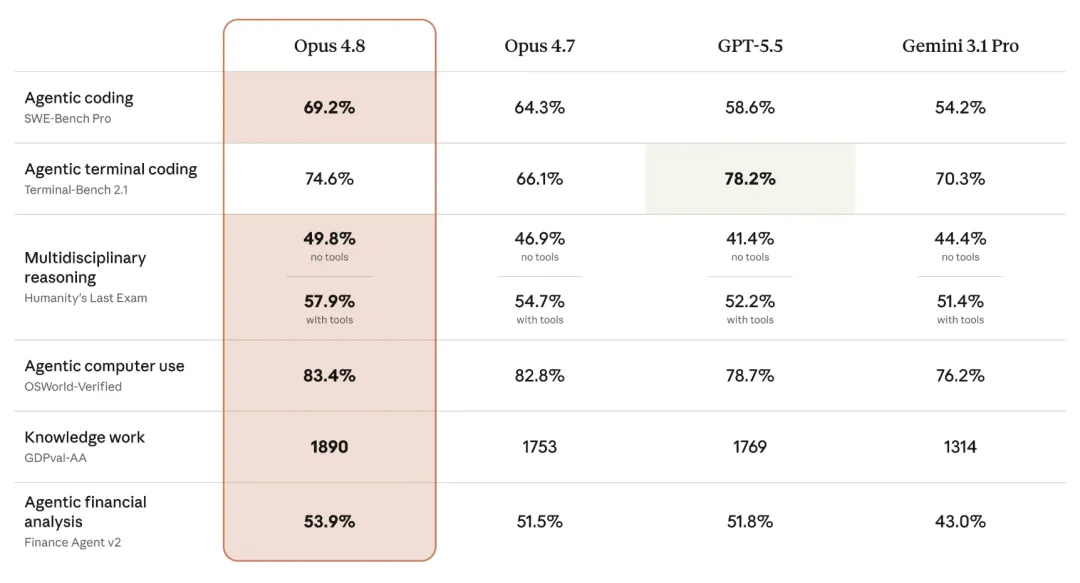
整体来看,这不是一次「参数炸裂」的革命性升级,而是一次针对实际使用痛点的精准打磨。Anthropic 明显把精力放在了“让模型在真实 workflow 里更可靠、更可控”上,而不是单纯追逐 leaderboard。

价格不变,直接能用
好消息是,价格完全没动。输入 500 万 token 还是 5 美元,输出 100 万 token 25 美元。通过 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 都能直接调用,标识符是 claude-opus-4-8。

这意味着什么?
Anthropic 这次还做了一件值得关注的事,公开讨论了 RLHF 训练中常见的「考试心态」问题,也就是模型会去猜测评分者的偏好,而不是追求最优解。愿意把这种行业共性问题摊开来说,本身就值得肯定。
更重要的是,Opus 4.8 被很多人视为 Claude Mythos 正式版发布前的热身。Mythos 据说会带来更大幅度的能力跃迁,而 4.8 正在把诚实、对齐、长期自主性这些软实力先练扎实。
对 AI 开发者和日常使用者来说,可以确定的是几件事。复杂任务交给 AI 的时候,不用时刻提防它胡说八道了。
团队协作场景下,AI 不再是黑箱输出机,更像一个会主动求证、愿意承认局限的靠谱同事。
等 AI Agent 真正走向生产力工具的时候,可靠性会比单纯的聪明更值钱。

总结
Opus 4.8 不是那种让人尖叫的“哇哦”式发布,但它可能是最近最务实、最值得关注的一次迭代。
它在提醒一件事,AI 的进化方向不只是变得更聪明,更重要的是变得更值得信任。
感兴趣的话现在就可以去 claude.ai 或者 API 里试试新模型。尤其做代码、做研究、做复杂分析的,强烈建议上手感受一下「AI 主动告诉你哪里有风险」这种新体验。

