 夜雨聆风
夜雨聆风推荐系统是 AI 项目实战里非常适合写成完整案例的方向。相比目标检测项目需要准备图片、标注、训练权重,推荐系统更适合用结构化数据快速完成一个可运行系统;相比大模型 RAG 项目需要本地模型或 API,协同过滤推荐系统不依赖模型权重,也不需要 GPU,只要有用户评分数据,就能构建出“用户喜欢什么、相似用户喜欢什么、相似电影有哪些、下一部电影应该推荐什么”的完整闭环。
本文围绕一个真实可运行的 Flask Web 项目展开:基于协同过滤的电影推荐系统。系统使用内置电影评分数据,构建用户-电影评分矩阵,实现用户协同过滤 User-CF、物品协同过滤 Item-CF 和混合推荐 Hybrid,并提供 Flask 页面、API 接口、电影详情页、用户画像页、数据看板、评分提交和离线验证脚本。项目解压后安装依赖即可运行,适合用于 CSDN 技术博客、课程设计、项目展示、推荐算法入门实践和二次开发。
一、为什么选择“电影推荐系统”作为今天的 AI 项目实战选题
推荐系统是很多互联网产品的核心能力。电商要推荐商品,短视频要推荐内容,音乐平台要推荐歌曲,电影网站要推荐影片。对入门项目而言,电影推荐系统的好处在于业务容易理解,数据结构清晰,结果也容易展示。用户看过哪些电影、给过多少分、和哪些用户偏好相近、下一步适合推荐哪些电影,这些都可以直接转化成可视化页面和表格结果。
从项目交付角度看,电影推荐系统还有三个优势。
第一,项目不依赖深度学习权重。协同过滤主要依赖评分矩阵和相似度计算,不需要训练神经网络,也不需要下载 YOLO、BERT 或大语言模型权重。只要 Python 环境能安装 Flask、pandas、numpy、matplotlib,就能运行完整系统。
第二,代码逻辑适合讲解。协同过滤不是单纯调一个黑盒接口,而是可以清楚拆成数据读取、评分矩阵构建、相似度计算、评分预测、Top-N 排序、Web 展示等步骤。每个步骤都能对应到一个源码模块,适合写成 CSDN 干货文章。
第三,展示效果完整。项目可以展示首页、推荐结果页、电影详情页、相似电影列表、用户画像页、评估指标图和相似度热力图。读者不只是看到一段算法代码,而是能看到一个 Web 系统真正跑起来。
电影推荐系统的业务背景来自真实观影场景:用户进入影院或线上平台后,会根据类型偏好、历史评分、相似影片和热门趋势选择下一部电影。下面这张影院座位实景图适合作为项目场景引入,说明推荐算法最终服务的是具体的观影选择。

本文项目没有直接把 MovieLens 数据集打包到源码中,而是内置了一份小型演示数据,保证离线也能运行。如果后续要做大规模实验,可以参考 GroupLens 官方提供的 MovieLens 100K 或 MovieLens Latest Small 数据集,把字段映射到本项目的 movies.csv、ratings.csv 和 users.csv。
二、项目最终效果展示
先看系统运行后的主要页面和结果。运行命令如下:
python run_demo.py --user-id 1 --method hybrid --top-n 10python app.py
启动 Flask 后,浏览器访问:
浏览器访问运行日志中显示的本地地址下面三张页面图来自 Flask 服务启动后的浏览器真实访问结果,后面的得分、评估和相似度图由离线验证脚本基于同一份评分数据生成。
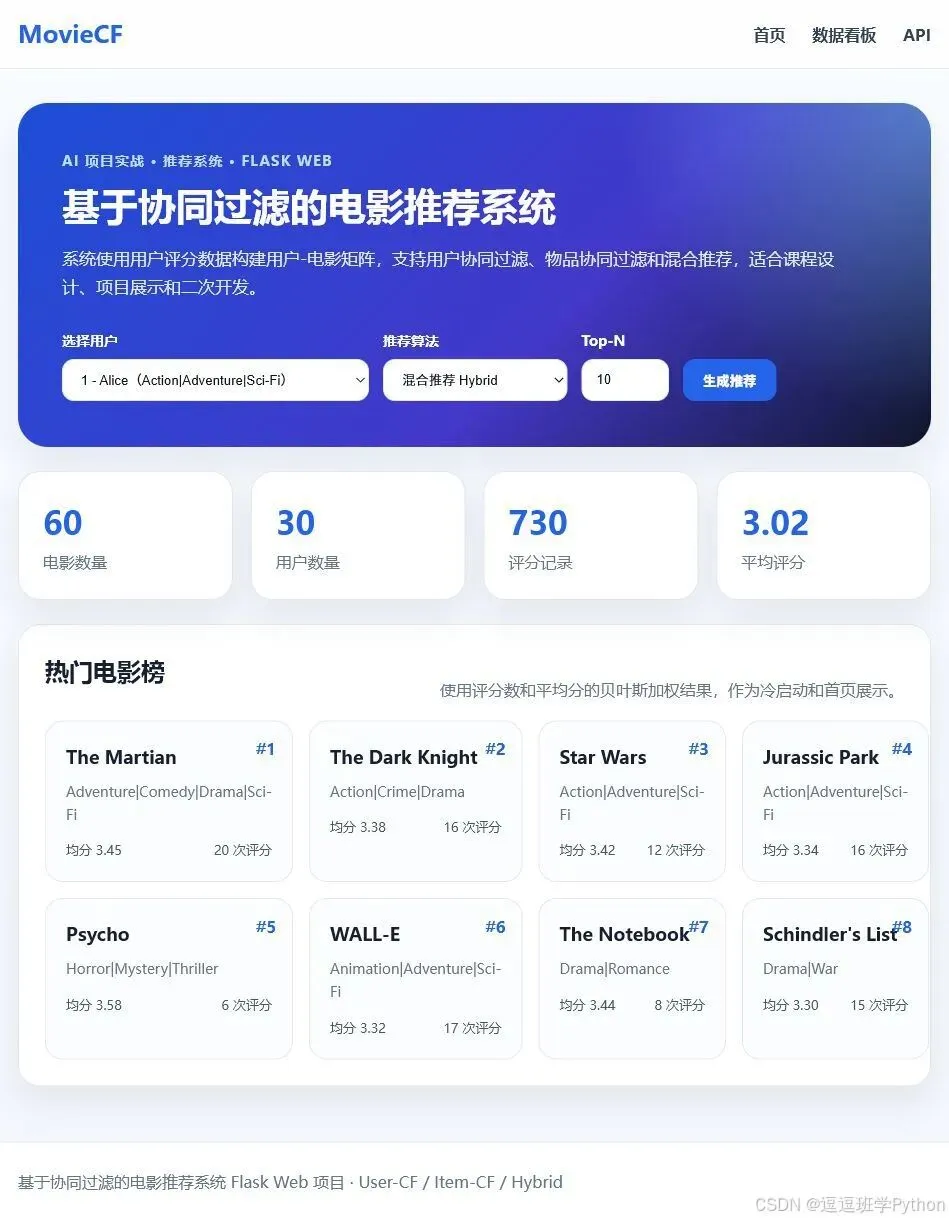
首页主要展示项目介绍、电影数量、用户数量、评分数量、平均评分、热门电影和推荐入口。用户可以选择一个用户 ID,再选择推荐方法:hybrid、user 或 item。
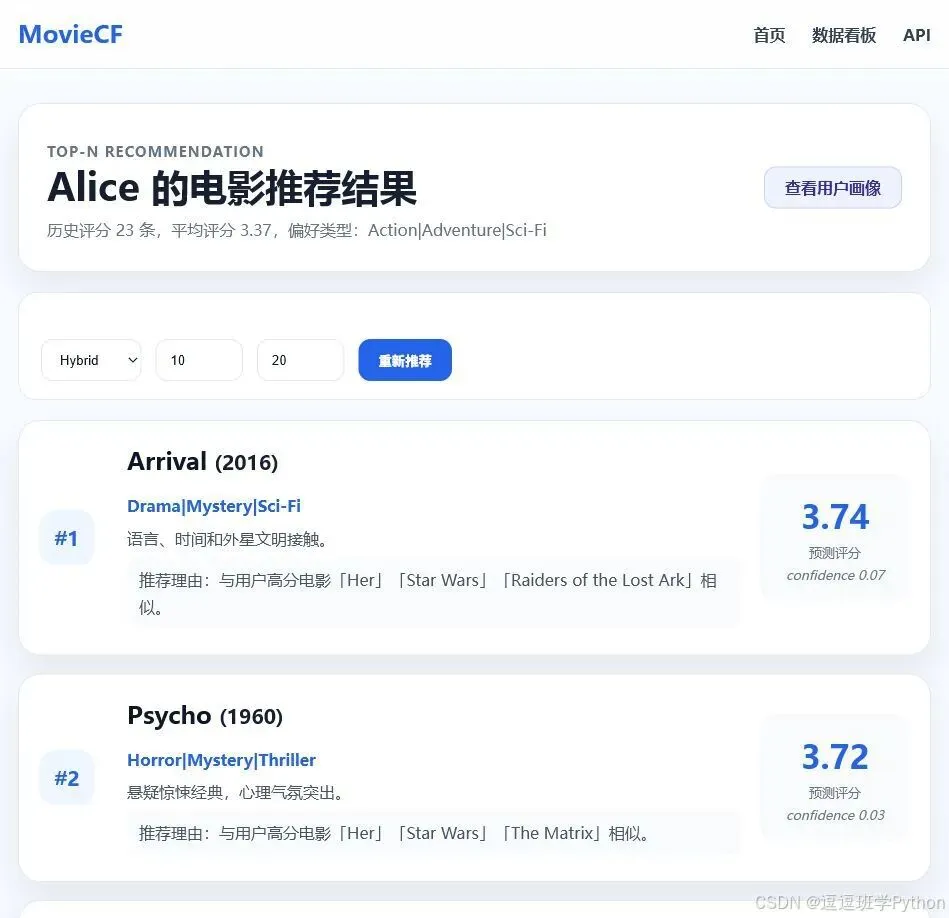
推荐结果页展示当前用户的 Top-N 推荐电影。每条推荐结果都包含电影标题、年份、类型、预测评分、置信度和推荐理由。这里的推荐理由不是随便写的,而是根据用户已经给过高分的相似电影生成,例如“与用户高分电影《Star Wars》《Her》相似”。
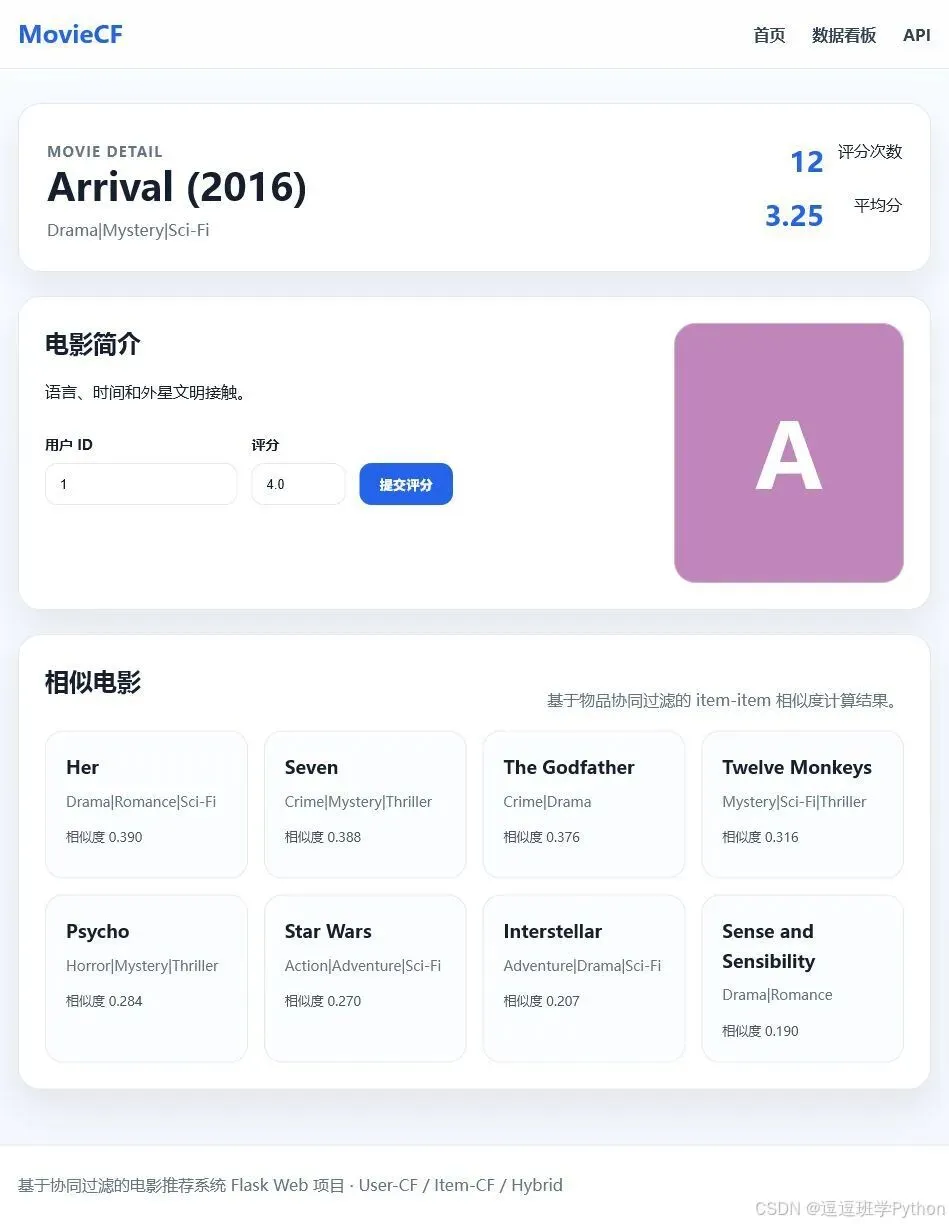
电影详情页展示电影简介、评分统计、用户评分表单和相似电影列表。相似电影来自 Item-CF 的电影相似度矩阵,适合解释“看过这部电影的人还可能喜欢什么”。
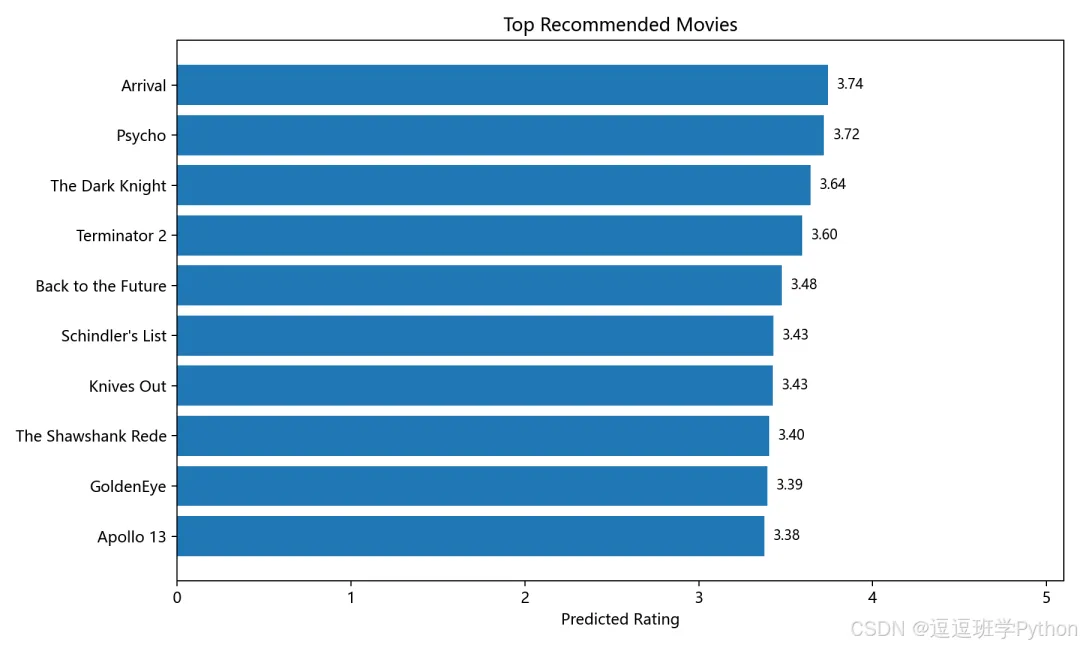
推荐得分图直观展示 Top-N 电影的预测评分排序。这个图适合放在项目报告或博客运行效果部分,说明系统不是只返回标题列表,而是有算法得分依据。
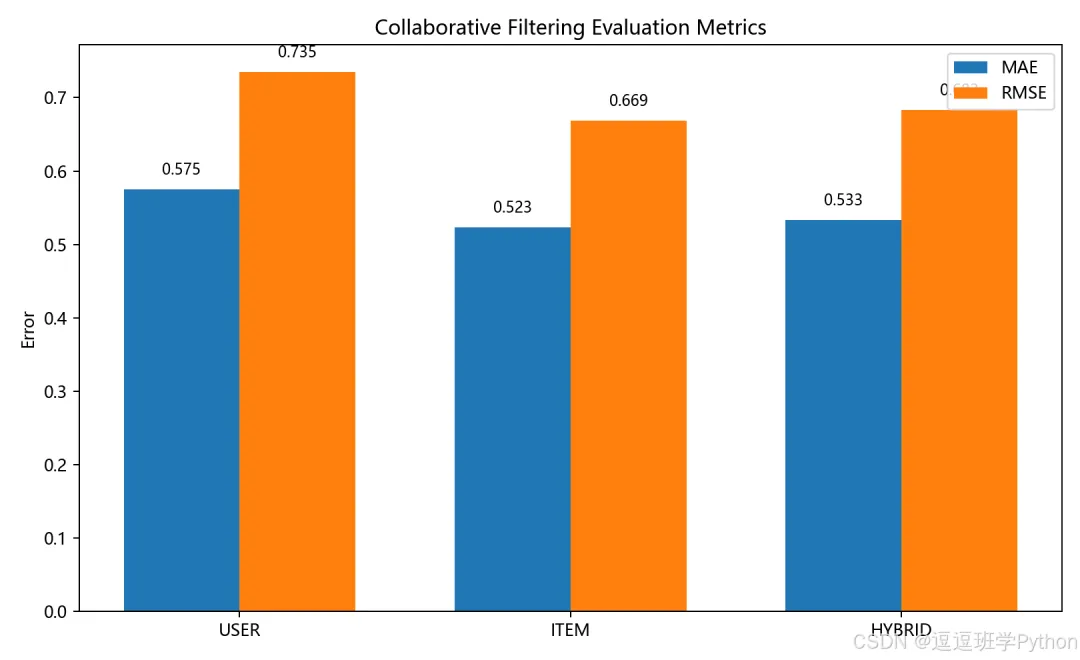
评估图展示 User-CF、Item-CF 和 Hybrid 三种方法的 MAE、RMSE 对比。当前内置数据的验证结果如下:
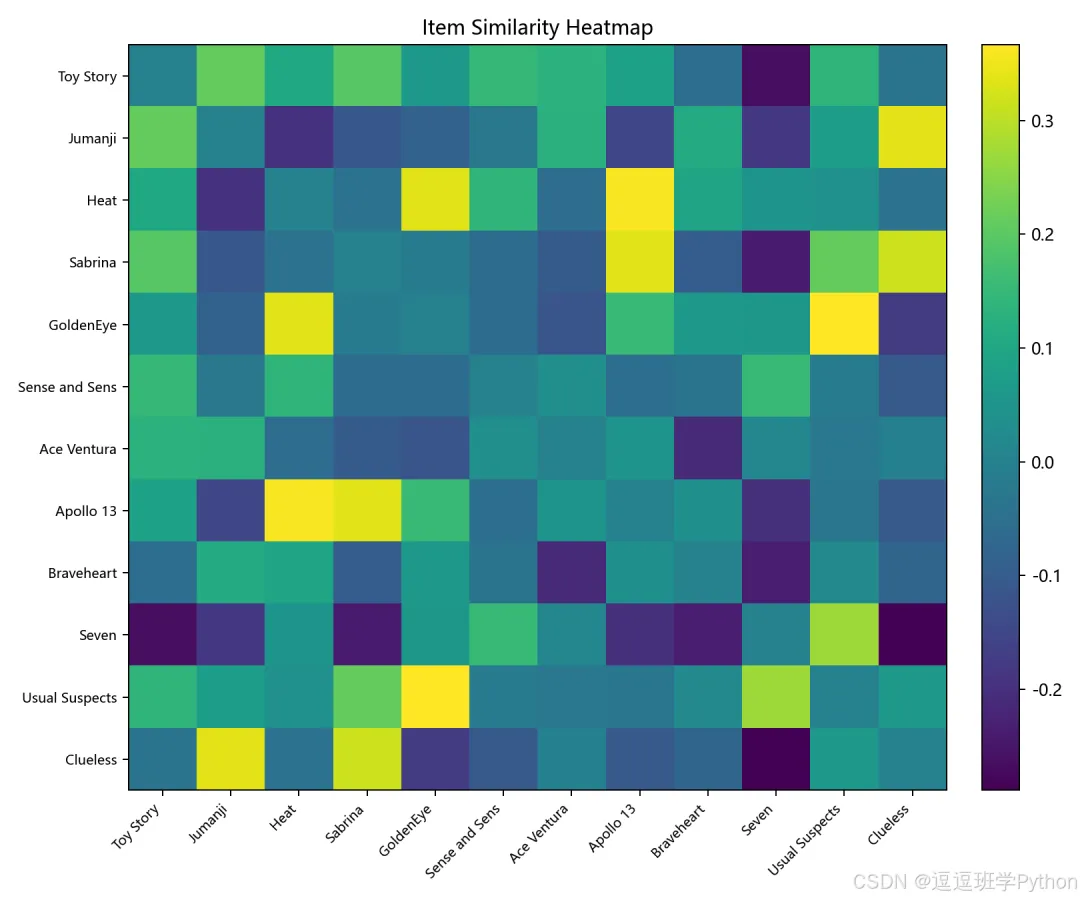
相似度热力图用于观察电影之间的 item-item 相似关系。颜色越接近,说明两部电影在用户评分行为上越相似。
三、系统功能设计
本项目不是只写一个“推荐函数”,而是做成一个可以直接运行和展示的 Flask Web 系统。核心功能包括:
1. 数据读取- 读取电影元数据 movies.csv- 读取用户画像 users.csv- 读取用户评分 ratings.csv- 合并 Web 页面新提交的 runtime_ratings.csv2. 协同过滤算法- 构建用户-电影评分矩阵- 计算用户相似度- 计算电影相似度- 用户协同过滤评分预测- 物品协同过滤评分预测- 混合推荐排序3. Web 系统- 首页- 推荐结果页- 电影详情页- 用户画像页- 数据看板页- JSON API 接口4. 结果保存- 推荐结果 CSV- 推荐结果 JSON- 评估报告 JSON- 运行验证报告 JSON- 运行截图和图表
项目结构图如下:
推荐流程图如下:
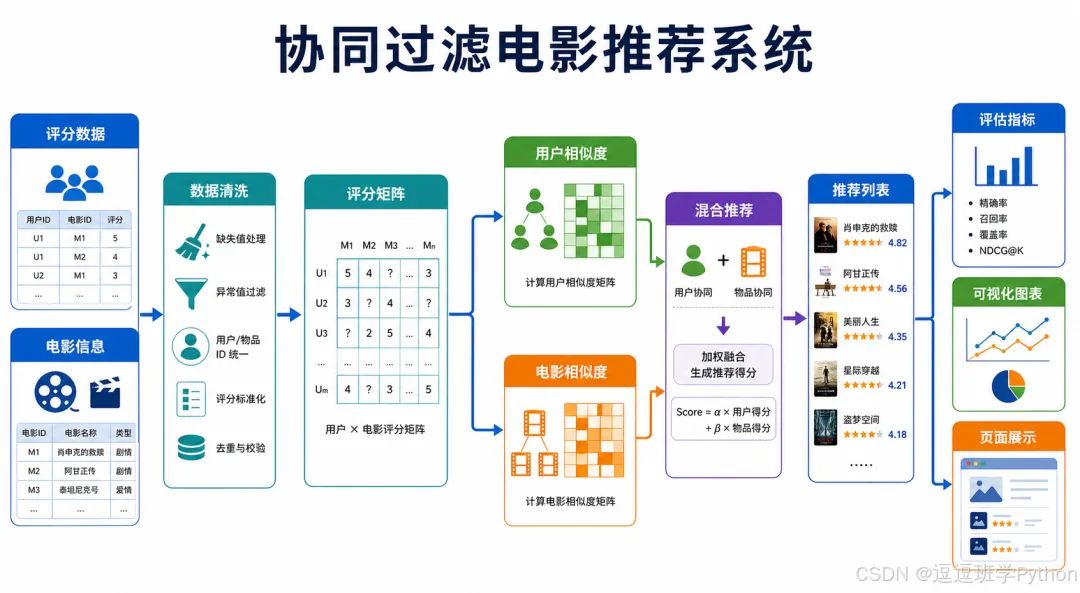
整个流程可以概括为:
电影数据 + 用户数据 + 评分数据↓构建用户-电影评分矩阵↓用户相似度 / 电影相似度↓User-CF / Item-CF 评分预测↓Hybrid 混合排序↓Flask 页面展示与 API 输出
四、项目目录结构
完整项目目录如下:
movie_cf_flask_recommender/├── app.py├── run_demo.py├── README.md├── blog.md├── requirements.txt├── requirements_full.txt├── run.bat├── run.sh├── configs/│ └── config.yaml├── demo_data/│ ├── movies.csv│ ├── ratings.csv│ ├── users.csv│ └── README_DATA.md├── src/│ ├── data_loader.py│ ├── recommender.py│ ├── evaluator.py│ ├── visualization.py│ ├── database.py│ ├── utils.py│ └── __init__.py├── templates/│ ├── base.html│ ├── index.html│ ├── recommendations.html│ ├── movie_detail.html│ ├── user_profile.html│ ├── dashboard.html│ └── error.html├── static/│ ├── css/│ │ └── style.css│ └── js/│ └── app.js├── outputs/│ ├── recommendations_user_1.csv│ ├── recommendations_user_1.json│ ├── evaluation_report.json│ ├── evaluation_summary.csv│ └── validation_report.json├── images/│ ├── figures/│ └── results/├── docs/├── tests/└── weights/└── README_WEIGHTS.md
这个结构把“算法核心”和“Web 展示”分开。src/recommender.py 只负责推荐算法,app.py 只负责 Web 路由,templates/ 负责页面展示,run_demo.py 负责离线验证和截图生成。这样设计的好处是后续扩展比较方便:要换成 FastAPI,可以复用算法模块;要加数据库,也不需要重写推荐算法;要接入 MovieLens,只需要替换数据读取和字段映射。
五、数据格式设计
项目内置三份 CSV 数据:
demo_data/movies.csvdemo_data/users.csvdemo_data/ratings.csv
movies.csv 的字段如下:
movie_id,title,year,genres,description,poster_color1,Toy Story,1995,Animation|Adventure|Comedy,玩具们在主人不在时拥有自己的世界...,#d6e4ac
users.csv 的字段如下:
user_id,name,gender,age,favorite_genres1,Alice,F,23,Action|Adventure|Sci-Fi
ratings.csv 的字段如下:
user_id,movie_id,rating,timestamp1,17,4.5,2026-01-06 05:00:00
当前演示数据统计如下:
电影数量:60用户数量:30评分数量:730平均评分:3.024最低评分:1.0最高评分:5.0电影类型数量:19
电影类型分布如下:
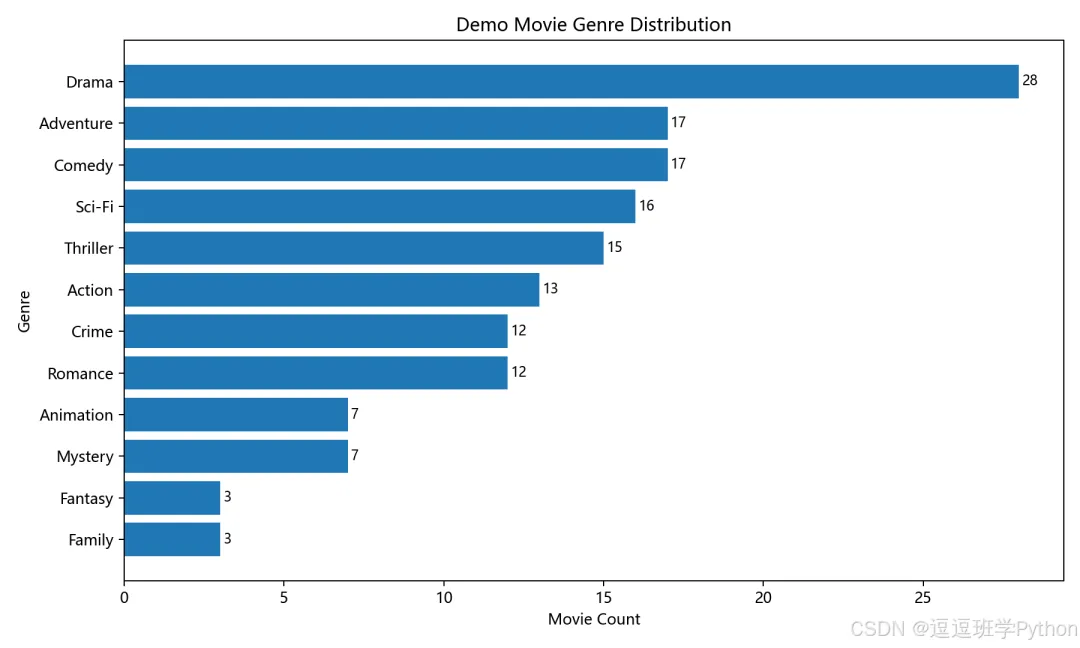
在推荐系统里,评分矩阵通常是稀疏的。一个用户不会给所有电影评分,一部电影也不会被所有用户评分。因此系统需要根据已有评分推断缺失评分。协同过滤解决的正是这个问题:从“人和人的相似”或“物品和物品的相似”出发,预测用户对未看电影的兴趣。
六、协同过滤算法原理
协同过滤的核心思想可以用一句话概括:相似用户喜欢的内容,当前用户可能也会喜欢;与用户喜欢过的电影相似的电影,也值得推荐给当前用户。
6.1 用户协同过滤 User-CF
用户协同过滤先计算用户之间的相似度。假设用户 A 和用户 B 都给很多相同电影打过分,并且评分趋势接近,那么可以认为他们偏好相似。当用户 A 没看过电影 X,而用户 B 给电影 X 打了高分,就可以把电影 X 推荐给用户 A。
在代码中,系统先构建用户-电影评分矩阵:
self.user_item = self.ratings.pivot_table(index="user_id",columns="movie_id",values="rating",aggfunc="mean",)
矩阵行表示用户,列表示电影,单元格表示评分。然后对用户评分做均值中心化,减少不同用户“打分尺度”差异的影响:
user_centered = self.user_item.sub(self.user_means, axis=0).fillna(0.0)用户相似度使用余弦相似度:
similarity = normalized @ normalized.T对目标用户预测某部电影评分时,系统会找到给这部电影打过分的相似用户,然后根据相似用户评分偏差做加权平均:
预测评分 = 当前用户平均分 + 相似用户评分偏差的加权平均这种方法直观、易解释,适合推荐系统入门项目。但它也有局限:当用户数量很大时,实时寻找相似用户成本较高;当目标用户评分很少时,也容易出现冷启动问题。
6.2 物品协同过滤 Item-CF
物品协同过滤从电影之间的相似关系出发。两部电影如果经常被相同用户以相似方式评分,就认为它们相似。例如喜欢《Star Wars》的用户也常给《The Matrix》《Interstellar》高分,那么这些电影之间可能存在较强相似关系。
Item-CF 的优势在于电影之间的相似关系相对稳定,适合预计算。项目中通过转置后的评分矩阵计算 item-item 相似度:
item_centered = self.user_item.sub(self.item_means, axis=1).fillna(0.0).Titem_sim = self._cosine_similarity(item_centered.values)
预测某个用户对目标电影的评分时,系统会查看该用户已经评分过的电影,找到其中与目标电影相似度较高的电影,再进行加权计算:
目标电影预测分 = 用户已评分电影 × 电影相似度 的加权平均Item-CF 很适合电影推荐、商品推荐、新闻推荐这类场景,因为用户可能很多,但物品数量相对可控,物品相似度可以离线计算。
6.3 混合推荐 Hybrid
单独使用 User-CF 或 Item-CF 都有自己的偏差。User-CF 更关注“人群相似”,Item-CF 更关注“内容行为相似”。本项目使用一个简单有效的混合方式:
hybrid_score = alpha * user_cf_score + (1 - alpha) * item_cf_score默认参数为:
alpha = 0.45也就是说,系统略微更依赖 Item-CF,同时保留 User-CF 的相似用户信号。这个参数可以在 configs/config.yaml 或请求参数中调整:
/recommendations?user_id=1&method=hybrid&top_n=10&alpha=0.45七、核心代码讲解
7.1 数据读取模块 data_loader.py
data_loader.py 负责读取三类数据,并处理用户在 Web 页面中新提交的评分。核心函数是:
def load_dataset(data_dir=None, include_runtime=True):movies = load_movies(data_dir)ratings = load_ratings(data_dir, include_runtime=include_runtime)users = load_users(data_dir)return movies, ratings, users
这里的 include_runtime=True 很重要。用户在电影详情页提交评分后,系统会把评分写入:
outputs/runtime_ratings.csv再次加载评分时,系统会把基础评分和运行时评分合并,并按 user_id + movie_id 去重,保留最新评分。这样项目不仅能展示推荐结果,还能体现“用户反馈影响推荐结果”的基本闭环。
7.2 推荐算法模块 recommender.py
recommender.py 是项目最核心的文件。类名为:
CollaborativeFilteringRecommender它主要包含以下方法:
fit() 构建矩阵并计算相似度predict_user_based() 用户协同过滤预测评分predict_item_based() 物品协同过滤预测评分predict_hybrid() 混合推荐评分recommend() 生成 Top-N 推荐列表similar_movies() 查询相似电影popular_movies() 首页热门电影榜evaluate() 评估 MAE、RMSE、覆盖率
系统初始化后会先调用 fit():
recommender = CollaborativeFilteringRecommender(movies, ratings, users).fit()推荐时调用:
recs = recommender.recommend(user_id=1,method="hybrid",top_n=10,k=20,alpha=0.45)
返回结果是一个 DataFrame,字段包括:
rankmovie_idtitleyeargenrespredicted_ratingconfidencemethodreasondescription
这比只返回电影 ID 更适合 Web 展示和博客截图。
7.3 评分预测中的回退机制
推荐系统项目里很容易忽略一个问题:不是所有用户和电影都有足够评分。如果没有回退机制,系统可能因为相似用户为空、相似电影为空而报错。
本项目设计了均值回退:
def _fallback_score(self, user_id, movie_id):user_mean = self.user_means.get(user_id, self.global_mean)item_mean = self.item_means.get(movie_id, self.global_mean)return 0.35 * user_mean + 0.55 * item_mean + 0.10 * self.global_mean
回退分数融合了用户平均分、电影平均分和全局平均分。这样即使遇到冷启动用户或冷启动电影,系统也能给出相对稳定的结果,而不是直接返回空。
7.4 推荐理由生成
为了让项目更像真实系统,推荐结果中加入了推荐理由。系统会寻找目标电影与用户高分电影之间的相似关系:
liked = rated[rated >= 4.0]sims = self.item_similarity.loc[movie_id, liked.index]
如果存在相似电影,就生成类似这样的解释:
与用户高分电影「Her」「Star Wars」「Raiders of the Lost Ark」相似。在项目展示中,解释字段很重要。它能让读者看到推荐不是“随机给出”,而是有相似度和历史行为依据。
八、Flask Web 页面实现
Flask 主程序是 app.py。项目包含以下路由:
/ 首页/recommendations 推荐结果页/movie/<movie_id> 电影详情页/user/<user_id> 用户画像页/dashboard 数据看板/rate 提交评分/api/recommendations 推荐结果 API/api/similar/<movie_id> 相似电影 API
首页路由读取数据、构建推荐器、统计数据,并渲染 index.html:
@app.route("/")def index():recommender, movies, ratings, users = build_recommender()stats = summarize_dataset(movies, ratings, users)popular = recommender.popular_movies(top_n=8)return render_template("index.html", stats=stats, users=users, popular=popular)
推荐结果页根据请求参数生成推荐:
@app.route("/recommendations")def recommendations():user_id = int(request.args.get("user_id", 1))method = request.args.get("method", "hybrid")top_n = int(request.args.get("top_n", 10))recommender, movies, ratings, users = build_recommender()recs = recommender.recommend(user_id=user_id, method=method, top_n=top_n)return render_template("recommendations.html", recs=recs.to_dict(orient="records"))
电影详情页除了展示元数据,还展示相似电影:
similar = recommender.similar_movies(movie_id=movie_id, top_n=8)API 接口返回 JSON,方便后续接前端框架或移动端:
GET /api/recommendations?user_id=1&method=hybrid&top_n=10GET /api/similar/18
九、运行步骤
建议使用 Python 3.10 及以上版本。进入项目目录后安装依赖:
pip install -r requirements.txt先运行离线验证:
python run_demo.py --user-id 1 --method hybrid --top-n 10如果输出如下,说明核心算法已经跑通:
MovieCF validation finished.Status: successValidation report: outputs/validation_report.json
然后启动 Flask:
python app.py浏览器访问:
浏览器访问运行日志中显示的本地地址如果使用 Windows,可以双击或命令行运行:
run.bat如果使用 Linux 或 macOS:
bash run.sh十、运行验证结果
离线验证脚本会完整执行推荐生成、评估计算和图表输出。一次实际运行结果如下:
状态:success电影数量:60用户数量:30评分数量:730平均评分:3.024
当前用户 Alice 的 Top-N 推荐结果部分如下:
详细结果会保存到:
outputs/validation_report.jsondocs/validation_report.md
十一、算法评估说明
推荐系统评估不能只看页面是否能打开,还要看预测结果是否相对稳定。项目中使用了一个简单的用户分层留出验证:对每个评分较多的用户随机抽取部分评分作为测试集,其余评分作为训练集,再预测测试集中用户对电影的评分。
主要指标包括:
MAE:平均绝对误差,越小越好RMSE:均方根误差,越小越好Catalog Coverage:目录覆盖率,越高说明推荐结果覆盖的电影越丰富
当前内置数据的评估结果为:
从结果看,Item-CF 在这份演示数据上误差更低,Hybrid 的误差接近 Item-CF,但覆盖率和稳定性更均衡。实际项目中,不同数据集上三种方法的表现可能不同,这也是推荐系统调参和实验分析的价值所在。
十二、为什么没有直接使用深度学习推荐模型
很多人一看到 AI 项目就想用深度学习,但不是所有推荐系统都必须从 DeepFM、DIN、Transformer 开始。对课程设计和项目实战而言,协同过滤有几个明显优势:
第一,运行门槛低。协同过滤不需要 GPU,不需要长时间训练,也不需要下载大模型权重。
第二,可解释性强。推荐理由可以从相似用户、相似电影、历史高分电影中直接解释。
第三,工程闭环完整。即使算法相对传统,也可以做成完整 Web 系统,包含数据、算法、页面、API、验证和截图。
第四,适合继续扩展。后续可以在协同过滤基础上加入矩阵分解、隐语义模型、内容特征、标签特征、时间衰减和深度模型。
因此本文项目选择用协同过滤作为第一版,而不是直接堆复杂模型。这样更适合读者理解,也更适合把项目交付给需要快速运行和展示的人。
十三、如何替换成 MovieLens 数据集
项目默认使用内置演示数据。如果要换成 MovieLens,只需要保持字段一致。MovieLens 常见字段如下:
movies.csv:movieId,title,genresratings.csv:userId,movieId,rating,timestamp
映射到本项目:
movieId -> movie_iduserId -> user_idgenres -> genresrating -> ratingtimestamp -> timestamp
由于 MovieLens 的 title 通常包含年份,例如:
Toy Story (1995)可以在导入时用正则表达式解析年份,生成:
title = Toy Storyyear = 1995
电影描述字段可以先用空字符串或默认描述填充:
description = 这是一部来自 MovieLens 数据集的电影。用户画像 users.csv 如果没有真实用户资料,可以根据评分表中的用户 ID 自动生成:
user_id,name,gender,age,favorite_genres1,User 1,U,0,Unknown
这样就能把 MovieLens 数据接入当前系统。
十四、项目常见问题
14.1 为什么推荐结果的预测评分看起来不是特别高
协同过滤预测的是“可能评分”,不是简单把热门电影排在最前面。项目还会排除用户已经评分过的电影,所以推荐候选集只来自未评分电影。预测分数受到相似用户、相似电影、电影平均分和用户平均分共同影响,通常不会全部接近 5 分。
14.2 为什么有的电影相似度为负
当两部电影的评分趋势相反时,余弦相似度可能为负。本项目在推荐时主要使用正相似度,避免把负相关电影作为强推荐依据。
14.3 为什么需要均值中心化
有些用户习惯给高分,有些用户习惯给低分。如果不处理这种差异,系统可能把“打分宽松”误认为“更喜欢某类电影”。均值中心化可以让相似度更关注评分趋势,而不是绝对分值。
14.4 提交评分后推荐为什么会变化
提交评分后,系统会把新评分保存到运行时评分文件和 SQLite 数据库。推荐页面重新加载时会合并新评分,并重新计算相似度和推荐分数。因此用户反馈会影响后续推荐。
14.5 项目能不能部署到服务器
可以。开发环境直接运行:
python app.py生产环境可以用:
gunicorn app:appWindows 服务器可以使用 waitress:
waitress-serve --listen=0.0.0.0:5000 app:app十五、二次开发方向
这个项目可以继续扩展成更完整的推荐系统。
15.1 增加登录注册
当前用户通过下拉框选择。后续可以增加用户注册、登录、个人中心和评分历史,把用户数据保存到数据库。
15.2 增加真实电影海报
当前项目使用颜色块作为海报占位。后续可以接入电影海报字段,或者从自有静态资源中读取海报图片。
15.3 增加内容推荐
协同过滤主要依赖评分行为。可以加入电影类型、简介关键词、演员、导演等内容特征,实现“协同过滤 + 内容推荐”的混合系统。
15.4 增加矩阵分解
可以扩展 SVD 或 ALS,把稀疏评分矩阵分解成用户隐向量和电影隐向量。这样可以提升推荐系统对稀疏数据的建模能力。
15.5 增加排序模型
如果有点击、收藏、播放时长等特征,可以进一步做 Learning to Rank,把候选召回和排序分开,实现更接近工业推荐系统的架构。
15.6 增加管理后台
可以增加电影管理、用户管理、评分管理、推荐日志查看和评估报表下载功能,使项目更适合课程设计和实践交付。
十六、适用场景
这个项目适合以下场景:
1. Python 推荐系统课程设计2. Flask Web 项目实战3. 推荐算法入门项目4. AI 项目实战博客发布5. CSDN 源码讲解文章6. 电影推荐系统项目展示7. 推荐算法实验报告8. 协同过滤算法教学案例
如果用于课程设计,可以把报告重点放在“需求分析、系统设计、协同过滤算法、数据库设计、Web 实现、运行结果、测试验证”上。如果用于 CSDN 发布,可以重点展示项目功能、运行截图、代码结构和可扩展方向。
十七、参考资料
GroupLens MovieLens Datasets: https://grouplens.org/datasets/movielens/
MovieLens 100K Dataset: https://grouplens.org/datasets/movielens/100k/
Flask 官方文档: https://flask.palletsprojects.com/
scikit-learn cosine_similarity 文档: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html
Sarwar et al., Item-Based Collaborative Filtering Recommendation Algorithms: https://files.grouplens.org/papers/www10_sarwar.pdf
十八、总结
本文完成了一个完整的 基于协同过滤的电影推荐系统 Flask Web 项目。项目不是单纯演示一个算法函数,而是围绕真实项目交付组织源码:有数据、有算法、有页面、有 API、有图表、有运行截图、有验证报告。
从技术上看,系统实现了 User-CF、Item-CF 和 Hybrid 推荐;从工程上看,系统提供了 Flask Web 页面、评分提交、JSON API 和离线验证脚本;从写作和展示角度看,项目提供了结构图、流程图、首页截图、推荐结果截图、电影详情截图、推荐得分图和评估指标图。
如果你正在准备推荐系统课程设计、Python Web 项目、AI 项目实战博客或 CSDN 源码资源,这个项目可以作为一个比较完整的基础版本。后续可以继续接入 MovieLens、增加矩阵分解、接入数据库后台、扩展用户登录和部署上线,让它从教学项目逐步升级为更完整的推荐系统应用。
