 夜雨聆风
夜雨聆风一、LLM Base抽象基类设计
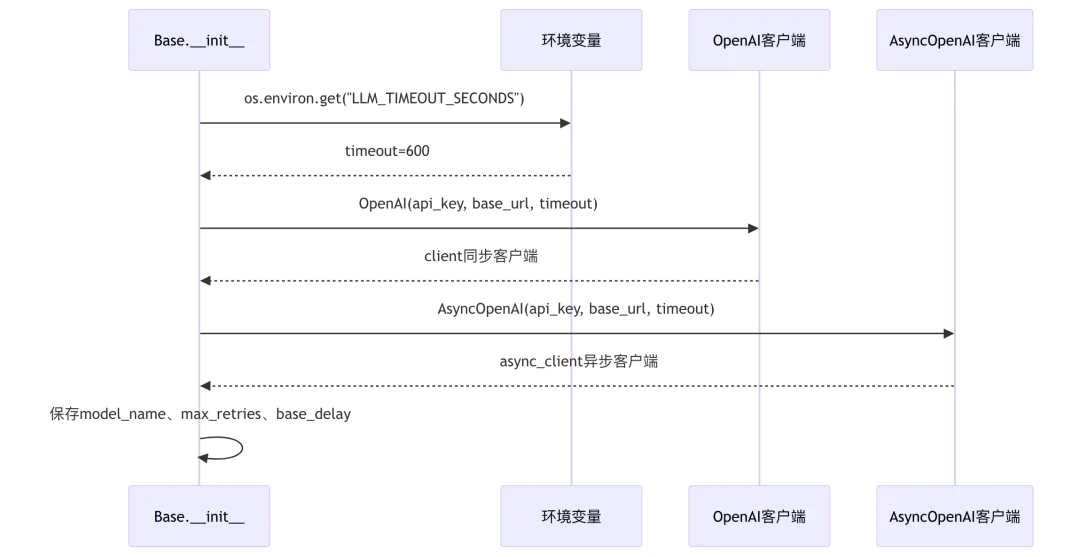
1.1 Base类初始化与配置
源码位置:rag/llm/chat_model.py:63-76
class Base(ABC):def __init__(self, key, model_name, base_url, **kwargs):# 第65行:从环境变量读取超时时间(默认600秒)timeout = int(os.environ.get("LLM_TIMEOUT_SECONDS", 600))# 第66-67行:创建同步和异步OpenAI客户端self.client = OpenAI(api_key=key, base_url=base_url, timeout=timeout)self.async_client = AsyncOpenAI(api_key=key, base_url=base_url, timeout=timeout)self.model_name = model_name# 第69-71行:配置重试参数self.max_retries = kwargs.get("max_retries", int(os.environ.get("LLM_MAX_RETRIES", 5)))self.base_delay = kwargs.get("retry_interval", float(os.environ.get("LLM_BASE_DELAY", 2.0)))self.max_rounds = kwargs.get("max_rounds", 5) # 工具调用最大轮数# 第73-75行:工具调用配置self.is_tools = Falseself.tools = []self.toolcall_sessions = {}
配置参数表:
timeout | LLM_TIMEOUT_SECONDS | ||
max_retries | LLM_MAX_RETRIES | ||
base_delay | LLM_BASE_DELAY | ||
max_rounds |
LLM客户端初始化流程图:
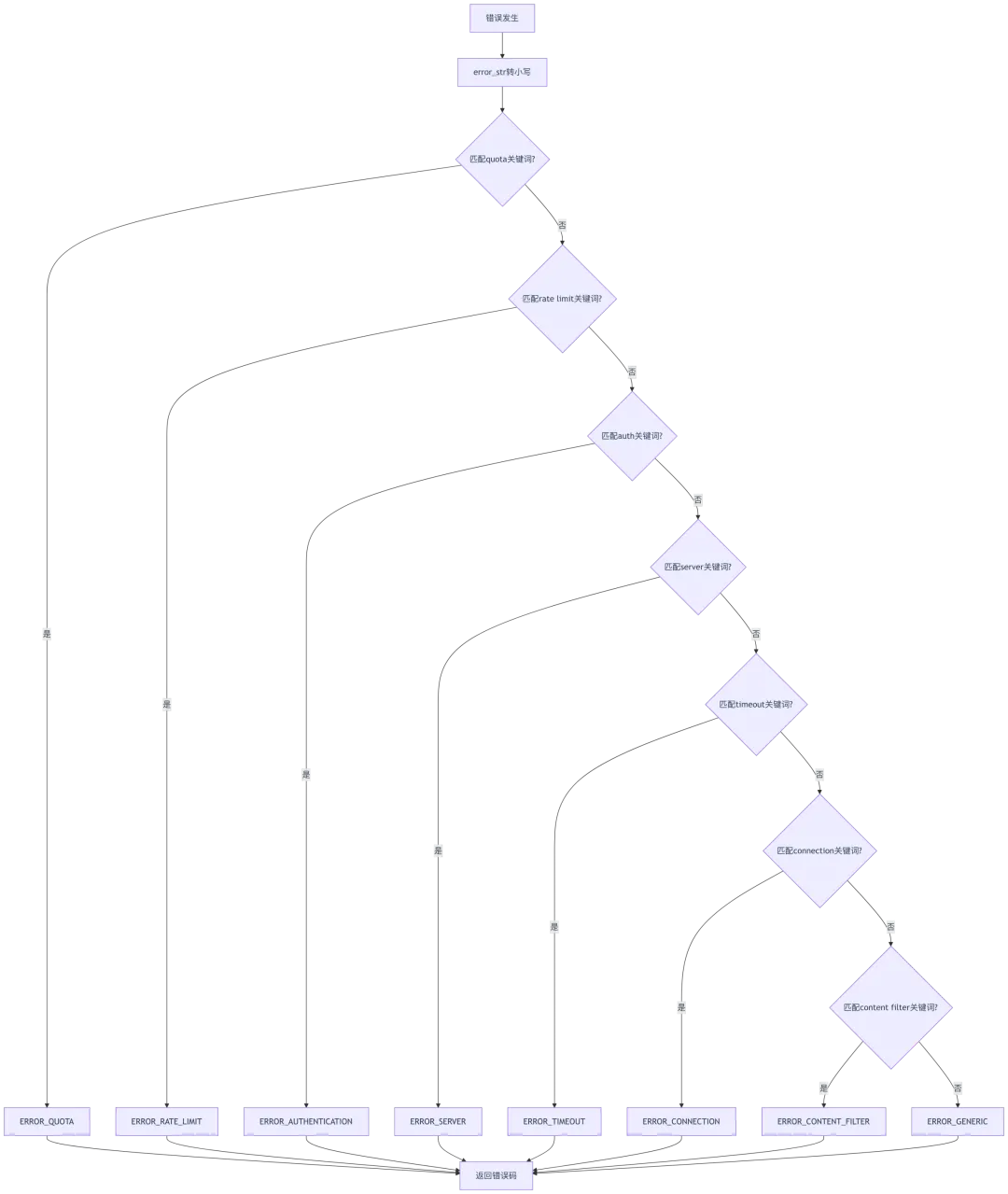
1.2 错误分类机制
源码位置:rag/llm/chat_model.py:80-99
def _classify_error(self, error):error_str = str(error).lower() # 第81行:转小写便于匹配# 第83-94行:关键词到错误码映射表keywords_mapping = [(["quota", "capacity", "credit", "billing", "balance", "欠费"], LLMErrorCode.ERROR_QUOTA),(["rate limit", "429", "tpm limit", "too many requests", "requests per minute"], LLMErrorCode.ERROR_RATE_LIMIT),(["auth", "key", "apikey", "401", "forbidden", "permission"], LLMErrorCode.ERROR_AUTHENTICATION),(["invalid", "bad request", "400", "format", "malformed", "parameter"], LLMErrorCode.ERROR_INVALID_REQUEST),(["server", "503", "502", "504", "500", "unavailable"], LLMErrorCode.ERROR_SERVER),(["timeout", "timed out"], LLMErrorCode.ERROR_TIMEOUT),(["connect", "network", "unreachable", "dns"], LLMErrorCode.ERROR_CONNECTION),(["filter", "content", "policy", "blocked", "safety", "inappropriate"], LLMErrorCode.ERROR_CONTENT_FILTER),(["model", "not found", "does not exist", "not available"], LLMErrorCode.ERROR_MODEL),(["max rounds"], LLMErrorCode.ERROR_MODEL),]# 第95-98行:遍历关键词匹配for words, code in keywords_mapping:if re.search("({})".format("|".join(words)), error_str):return codereturn LLMErrorCode.ERROR_GENERIC # 第99行:默认通用错误
错误码枚举定义:
class LLMErrorCode(StrEnum):ERROR_RATE_LIMIT = "RATE_LIMIT_EXCEEDED" # 速率限制ERROR_AUTHENTICATION = "AUTH_ERROR" # 认证错误ERROR_INVALID_REQUEST = "INVALID_REQUEST" # 无效请求ERROR_SERVER = "SERVER_ERROR" # 服务器错误ERROR_TIMEOUT = "TIMEOUT" # 超时ERROR_CONNECTION = "CONNECTION_ERROR" # 连接错误ERROR_MODEL = "MODEL_ERROR" # 模型错误ERROR_MAX_ROUNDS = "ERROR_MAX_ROUNDS" # 超过最大轮数ERROR_CONTENT_FILTER = "CONTENT_FILTERED" # 内容过滤ERROR_QUOTA = "QUOTA_EXCEEDED" # 配额超限ERROR_MAX_RETRIES = "MAX_RETRIES_EXCEEDED" # 超过最大重试ERROR_GENERIC = "GENERIC_ERROR" # 通用错误
错误分类流程图:
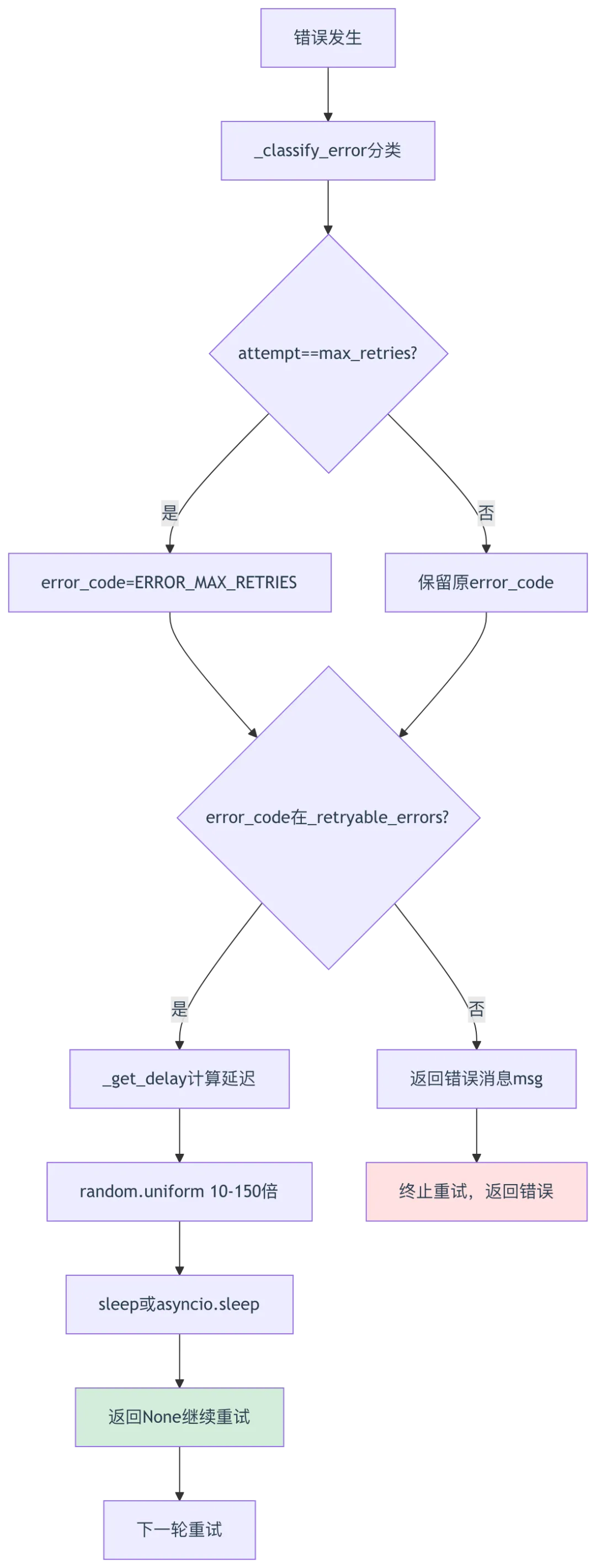
1.3 重试机制设计
源码位置:rag/llm/chat_model.py:211-242
def _exceptions(self, e, attempt) -> str | None:logging.exception("OpenAI chat_with_tools")# 第213-214行:分类错误error_code = self._classify_error(e)# 第215-216行:达到最大重试次数if attempt == self.max_retries:error_code = LLMErrorCode.ERROR_MAX_RETRIES# 第218-222行:判断是否需要重试if self._should_retry(error_code):delay = self._get_delay() # 第219行:计算延迟时间logging.warning(f"Error: {error_code}. Retrying in {delay:.2f} seconds... (Attempt {attempt + 1}/{self.max_retries})")time.sleep(delay)return None # 第222行:返回None继续重试# 第224-226行:不可重试错误,返回错误消息msg = f"{ERROR_PREFIX}: {error_code} - {str(e)}"logging.error(f"sync base giving up: {msg}")return msgasync def _exceptions_async(self, e, attempt):logging.exception("OpenAI async completion")# 第230-232行:分类错误error_code = self._classify_error(e)if attempt == self.max_retries:error_code = LLMErrorCode.ERROR_MAX_RETRIES# 第234-238行:异步重试if self._should_retry(error_code):delay = self._get_delay()logging.warning(f"Error: {error_code}. Retrying in {delay:.2f} seconds... (Attempt {attempt + 1}/{self.max_retries})")await asyncio.sleep(delay) # 第237行:异步sleepreturn None# 第240-242行:返回错误消息msg = f"{ERROR_PREFIX}: {error_code} - {str(e)}"logging.error(f"async base giving up: {msg}")return msg@propertydef _retryable_errors(self) -> set[str]:return {LLMErrorCode.ERROR_RATE_LIMIT,LLMErrorCode.ERROR_SERVER,} # 第203-206行:可重试错误集合def _should_retry(self, error_code: str) -> bool:return error_code in self._retryable_errors # 第209行:判断是否可重试def _get_delay(self):return self.base_delay * random.uniform(10, 150) # 第78行:随机延迟10-150倍基础延迟
重试决策表:
重试流程图:
关键技术点:
- 随机延迟策略
(第78行): random.uniform(10, 150)避免多请求同时重试造成二次限流 - 有限可重试集合
(第203-206行):仅RATE_LIMIT和SERVER两类错误可重试,防止无限重试 - 异步重试支持
(第237行): await asyncio.sleep(delay)支持异步场景重试 - attempt计数
(第215-216行):达到max_retries强制终止,防止无限循环
二、工具调用机制
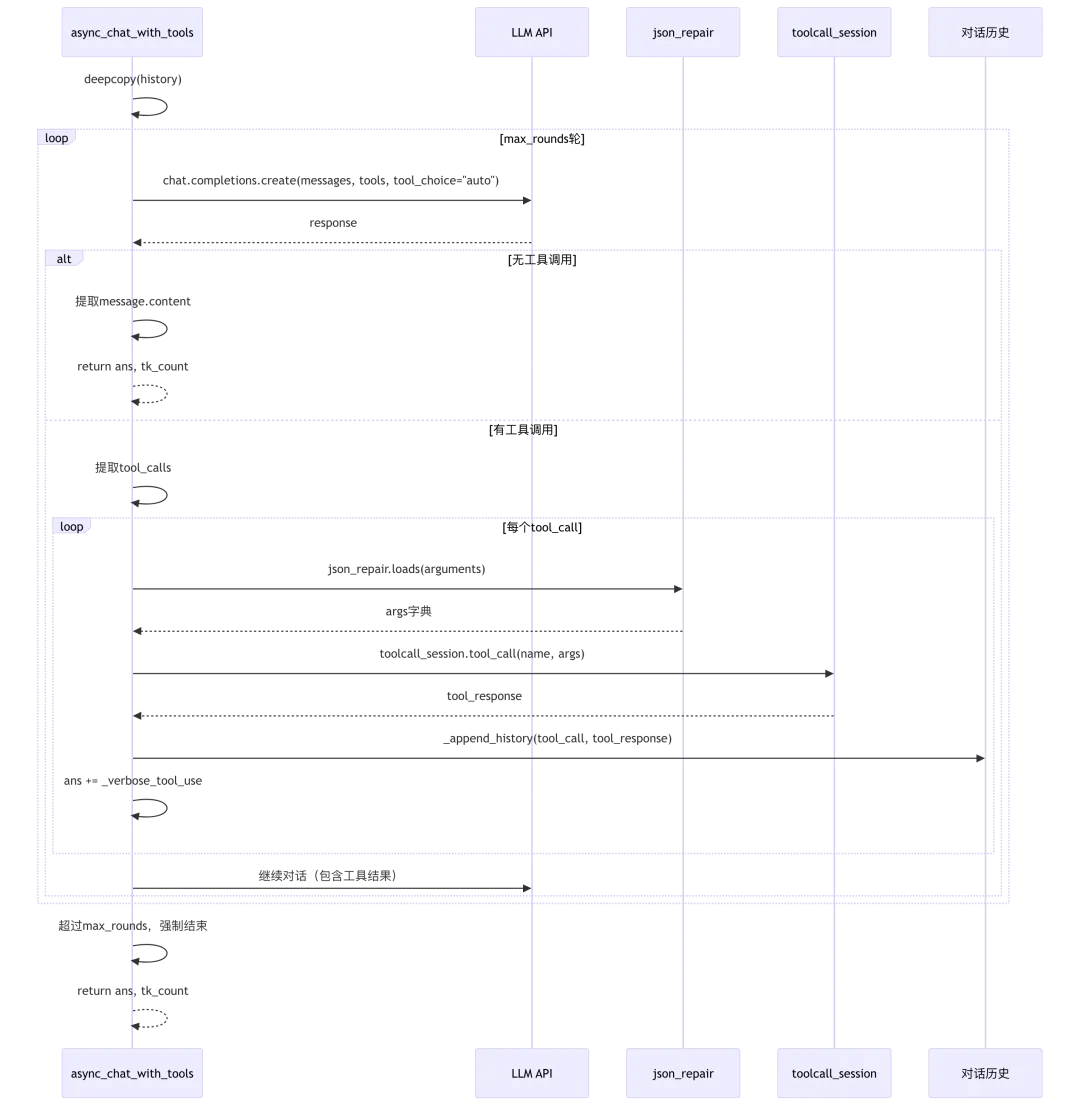
2.1 chat_with_tools工具调用流程
源码位置:rag/llm/chat_model.py:278-329
async def async_chat_with_tools(self, system: str, history: list, gen_conf: dict = {}):gen_conf = self._clean_conf(gen_conf)# 第280-281行:添加system消息if system and history and history[0].get("role") != "system":history.insert(0, {"role": "system", "content": system})ans = ""tk_count = 0hist = deepcopy(history) # 第285行:深拷贝历史# 第286-329行:重试循环for attempt in range(self.max_retries + 1):history = deepcopy(hist)try:# 第289-324行:工具调用循环for _ in range(self.max_rounds + 1):logging.info(f"{self.tools=}")# 第291行:调用LLM(包含工具定义)response = await self.async_client.chat.completions.create(model=self.model_name,messages=history,tools=self.tools,tool_choice="auto",**gen_conf)tk_count += total_token_count_from_response(response)# 第293-294行:响应结构校验if any([not response.choices, not response.choices[0].message]):raise Exception(f"500 response structure error. Response: {response}")# 第296-304行:无工具调用,返回直接答案if not hasattr(response.choices[0].message, "tool_calls") or not response.choices[0].message.tool_calls:if hasattr(response.choices[0].message, "reasoning_content"):ans += "seillee" + response.choices[0].message.reasoning_content + "aite"ans += response.choices[0].message.contentif response.choices[0].finish_reason == "length":ans = self._length_stop(ans)return ans, tk_count# 第306-317行:处理工具调用for tool_call in response.choices[0].message.tool_calls:logging.info(f"Response {tool_call=}")name = tool_call.function.nametry:# 第310-311行:解析参数并调用工具args = json_repair.loads(tool_call.function.arguments)tool_response = await thread_pool_exec(self.toolcall_session.tool_call, name, args)# 第312-313行:添加工具调用历史history = self._append_history(history, tool_call, tool_response)ans += self._verbose_tool_use(name, args, tool_response)except Exception as e:# 第315-317行:工具调用异常处理logging.exception(msg=f"Wrong JSON argument format: {tool_call}")history.append({"role": "tool", "tool_call_id": tool_call.id, "content": f"Tool call error: {str(e)}"})ans += self._verbose_tool_use(name, {}, str(e))# 第319-324行:超过最大轮数,强制结束logging.warning(f"Exceed max rounds: {self.max_rounds}")history.append({"role": "user", "content": f"Exceed max rounds: {self.max_rounds}"})response, token_count = await self._async_chat(history, gen_conf)ans += responsetk_count += token_countreturn ans, tk_countexcept Exception as e:e = await self._exceptions_async(e, attempt)if e:return e, tk_countassert False, "Shouldn't be here."
工具调用流程图:
2.2 历史记录管理
源码位置:rag/llm/chat_model.py:247-269
def _append_history(self, hist, tool_call, tool_res):# 第248-262行:添加assistant消息(包含tool_calls)hist.append({"role": "assistant","tool_calls": [{"index": tool_call.index,"id": tool_call.id,"function": {"name": tool_call.function.name,"arguments": tool_call.function.arguments,},"type": "function",},],})try:# 第264-266行:序列化工具结果if isinstance(tool_res, dict):tool_res = json.dumps(tool_res, ensure_ascii=False)finally:# 第268行:添加tool消息hist.append({"role": "tool", "tool_call_id": tool_call.id, "content": str(tool_res)})return hist
OpenAI工具调用历史格式:
[{"role": "user", "content": "搜索最新的AI新闻"},{"role": "assistant","tool_calls": [{"index": 0,"id": "call_abc123","function": {"name": "web_search","arguments": "{\"query\": \"AI news\", \"top_k\": 5}"},"type": "function"}]},{"role": "tool","tool_call_id": "call_abc123","content": "{\"results\": [...], \"count\": 5}"}]
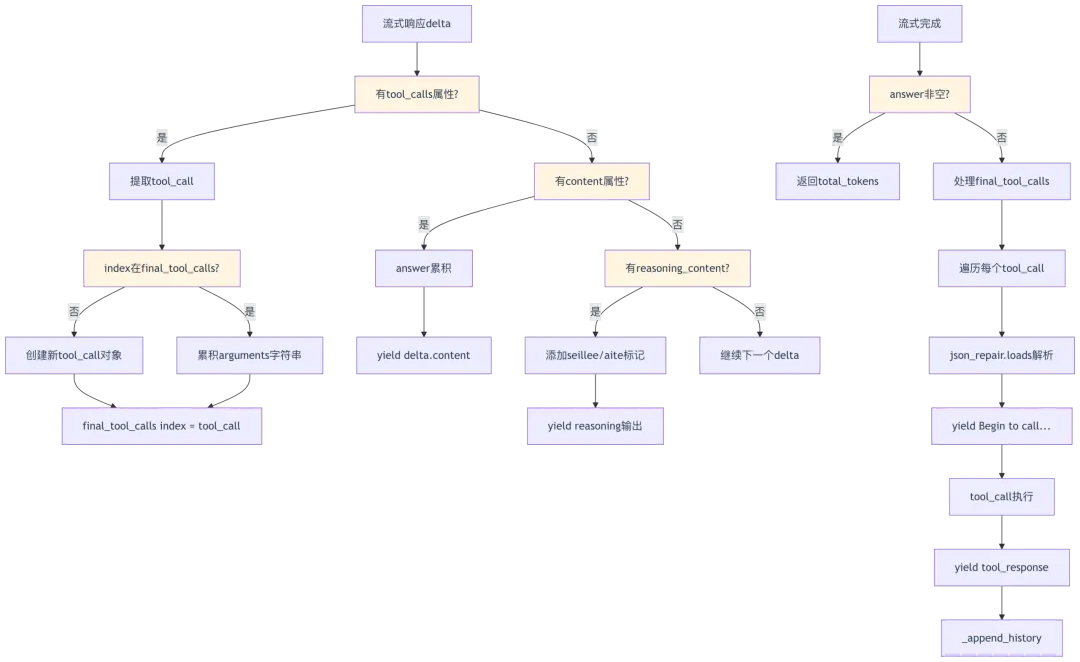
2.3 流式工具调用处理
源码位置:rag/llm/chat_model.py:332-441
async def async_chat_streamly_with_tools(self, system: str, history: list, gen_conf: dict = {}):gen_conf = self._clean_conf(gen_conf)tools = self.tools# 第335-336行:添加system消息if system and history and history[0].get("role") != "system":history.insert(0, {"role": "system", "content": system})total_tokens = 0hist = deepcopy(history)# 第341-440行:重试循环for attempt in range(self.max_retries + 1):history = deepcopy(hist)try:# 第344-411行:工具调用循环for _ in range(self.max_rounds + 1):reasoning_start = Falselogging.info(f"{tools=}")# 第348行:流式调用LLMresponse = await self.async_client.chat.completions.create(model=self.model_name,messages=history,stream=True, # 流式模式tools=tools,tool_choice="auto",**gen_conf)final_tool_calls = {} # 第350行:累积工具调用answer = "" # 第351行:累积答案# 第353-394行:处理流式响应async for resp in response:if not hasattr(resp, "choices") or not resp.choices:continuedelta = resp.choices[0].delta# 第359-368行:处理工具调用deltaif hasattr(delta, "tool_calls") and delta.tool_calls:for tool_call in delta.tool_calls:index = tool_call.indexif index not in final_tool_calls:if not tool_call.function.arguments:tool_call.function.arguments = ""final_tool_calls[index] = tool_callelse:# 第367行:累积argumentsfinal_tool_calls[index].function.arguments += tool_call.function.arguments or ""continue# 第370-394行:处理文本deltaif not hasattr(delta, "content") or delta.content is None:delta.content = ""# 第373-379行:处理reasoning_content(推理模型)if hasattr(delta, "reasoning_content") and delta.reasoning_content:ans = ""if not reasoning_start:reasoning_start = Trueans = "seillee"ans += delta.reasoning_content + "aite"yield anselse:reasoning_start = Falseanswer += delta.contentyield delta.content # 第383行:流式输出# 第385-389行:统计tokentol = total_token_count_from_response(resp)if not tol:total_tokens += num_tokens_from_string(delta.content)else:total_tokens = tol# 第391-393行:处理截断finish_reason = getattr(resp.choices[0], "finish_reason", "")if finish_reason == "length":yield self._length_stop("")# 第395-397行:有答案文本,直接返回if answer:yield total_tokensreturn# 第399-410行:处理累积的工具调用for tool_call in final_tool_calls.values():name = tool_call.function.nametry:args = json_repair.loads(tool_call.function.arguments)yield self._verbose_tool_use(name, args, "Begin to call...") # 第403行:输出开始调用tool_response = await thread_pool_exec(self.toolcall_session.tool_call, name, args)history = self._append_history(history, tool_call, tool_response)yield self._verbose_tool_use(name, args, tool_response) # 第406行:输出工具结果except Exception as e:logging.exception(msg=f"Wrong JSON argument format: {tool_call}")history.append({"role": "tool", "tool_call_id": tool_call.id, "content": f"Tool call error: {str(e)}"})yield self._verbose_tool_use(name, {}, str(e))# 第412-430行:超过最大轮数,强制流式结束logging.warning(f"Exceed max rounds: {self.max_rounds}")history.append({"role": "user", "content": f"Exceed max rounds: {self.max_rounds}"})response = await self.async_client.chat.completions.create(model=self.model_name, messages=history, stream=True, tools=tools, tool_choice="auto", **gen_conf)async for resp in response:if not hasattr(resp, "choices") or not resp.choices:continuedelta = resp.choices[0].deltaif not hasattr(delta, "content") or delta.content is None:continuetol = total_token_count_from_response(resp)if not tol:total_tokens += num_tokens_from_string(delta.content)else:total_tokens = tolyield delta.contentyield total_tokensreturnexcept Exception as e:e = await self._exceptions_async(e, attempt)if e:logging.error(f"async_chat_streamly failed: {e}")yield eyield total_tokensreturnassert False, "Shouldn't be here."
流式工具调用累积机制图:
关键技术点:
- 工具调用累积
(第367行): final_tool_calls[index].function.arguments += tool_call.function.arguments流式工具调用分多次返回,需累积arguments - 双输出模式
(第383、403、406行):同时yield文本内容和工具调用日志,用户可实时看到工具执行过程 - reasoning_content处理
(第373-379行):推理模型(如QwQ)返回推理过程,添加特殊标记便于前端区分 - json_repair修复
(第310、402行): json_repair.loads容错解析,处理LLM返回的格式错误的JSON
三、流式响应处理
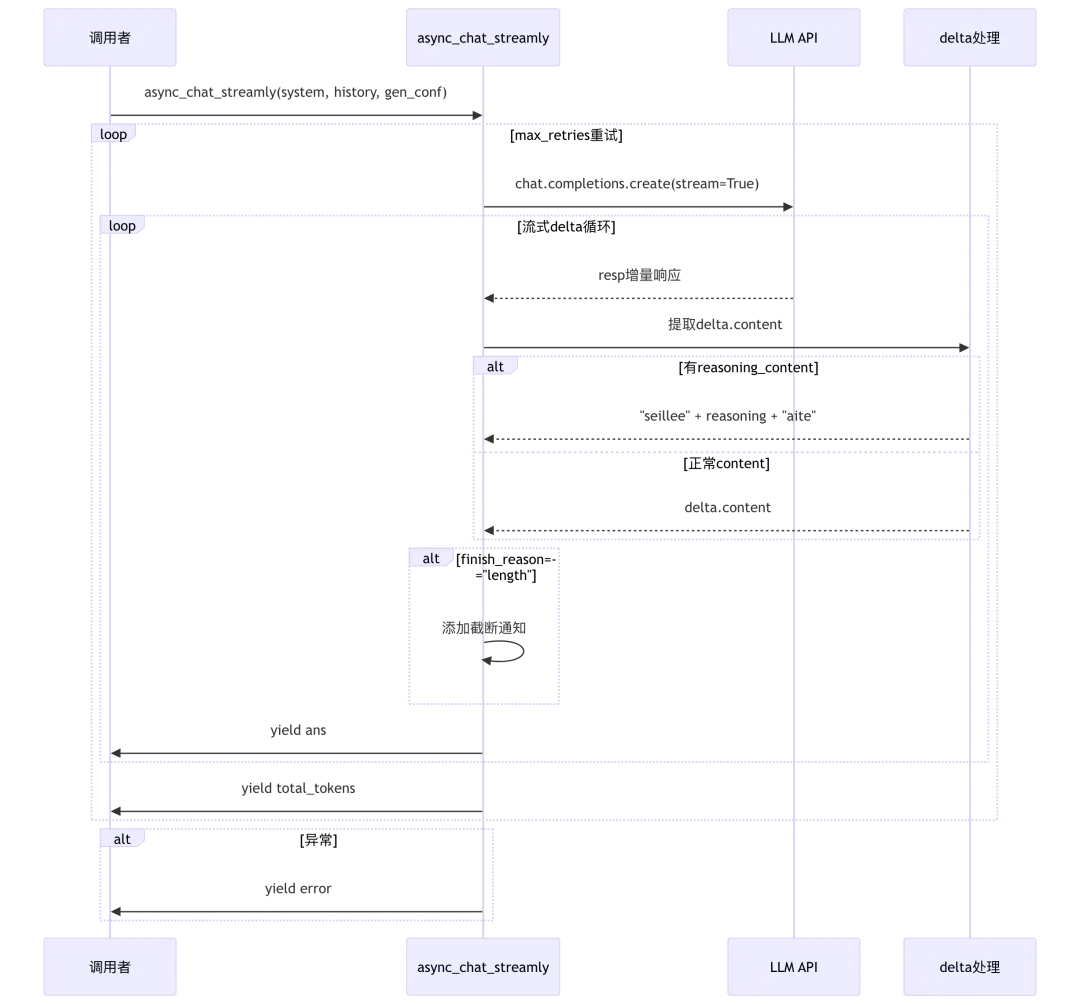
3.1 async_chat_streamly流式聊天
源码位置:rag/llm/chat_model.py:173-195
async def async_chat_streamly(self, system, history, gen_conf: dict = {}, **kwargs):# 第174-175行:添加system消息if system and history and history[0].get("role") != "system":history.insert(0, {"role": "system", "content": system})gen_conf = self._clean_conf(gen_conf)ans = ""total_tokens = 0# 第180-195行:重试循环for attempt in range(self.max_retries + 1):try:# 第182-187行:流式输出循环async for delta_ans, tol in self._async_chat_streamly(history, gen_conf, **kwargs):ans = delta_ans # 第183行:累积答案(流式模式下每次yield完整增量)total_tokens += tolyield ans # 第185行:流式输出yield total_tokens # 第187行:最后yield token数returnexcept Exception as e:e = await self._exceptions_async(e, attempt)if e:yield e # 第192行:yield错误消息yield total_tokensreturn
_async_chat_streamly核心实现:
async def _async_chat_streamly(self, history, gen_conf, **kwargs):logging.info("[HISTORY STREAMLY]" + json.dumps(history, ensure_ascii=False, indent=4))reasoning_start = False# 第141行:构造请求参数request_kwargs = {"model": self.model_name, "messages": history, "stream": True, **gen_conf}stop = kwargs.get("stop")if stop:request_kwargs["stop"] = stop# 第146行:流式调用response = await self.async_client.chat.completions.create(**request_kwargs)async for resp in response:if not resp.choices:continue# 第150-151行:处理空contentif not resp.choices[0].delta.content:resp.choices[0].delta.content = ""# 第152-161行:处理reasoning_content(推理模型)if kwargs.get("with_reasoning", True) and hasattr(resp.choices[0].delta, "reasoning_content") and resp.choices[0].delta.reasoning_content:ans = ""if not reasoning_start:reasoning_start = Trueans = "seillee"ans += resp.choices[0].delta.reasoning_content + "aite"else:reasoning_start = Falseans = resp.choices[0].delta.content# 第161-163行:统计tokentol = total_token_count_from_response(resp)if not tol:tol = num_tokens_from_string(resp.choices[0].delta.content)# 第165-171行:处理截断finish_reason = resp.choices[0].finish_reason if hasattr(resp.choices[0], "finish_reason") else ""if finish_reason == "length":if is_chinese(ans):ans += LENGTH_NOTIFICATION_CNelse:ans += LENGTH_NOTIFICATION_ENyield ans, tol # 第171行:yield增量答案和token数
流式输出流程图:
3.2 参数清理机制
源码位置:rag/llm/chat_model.py:101-135
def _clean_conf(self, gen_conf):model_name_lower = (self.model_name or "").lower()# 第103-106行:GPT-5特殊处理(清空所有自定义参数)if "gpt-5" in model_name_lower:gen_conf = {}return gen_conf# 第108-109行:删除max_tokens(使用max_completion_tokens代替)if "max_tokens" in gen_conf:del gen_conf["max_tokens"]# 第111-132行:允许的参数列表allowed_conf = {"temperature","max_completion_tokens","top_p","stream","stream_options","stop","n","presence_penalty","frequency_penalty","functions","function_call","logit_bias","user","response_format","seed","tools","tool_choice","logprobs","top_logprobs","extra_headers",}# 第134行:过滤参数gen_conf = {k: v for k, v in gen_conf.items() if k in allowed_conf}return gen_conf
参数过滤原因表:
max_tokens | ||
gpt-5 | ||
四、多提供商适配
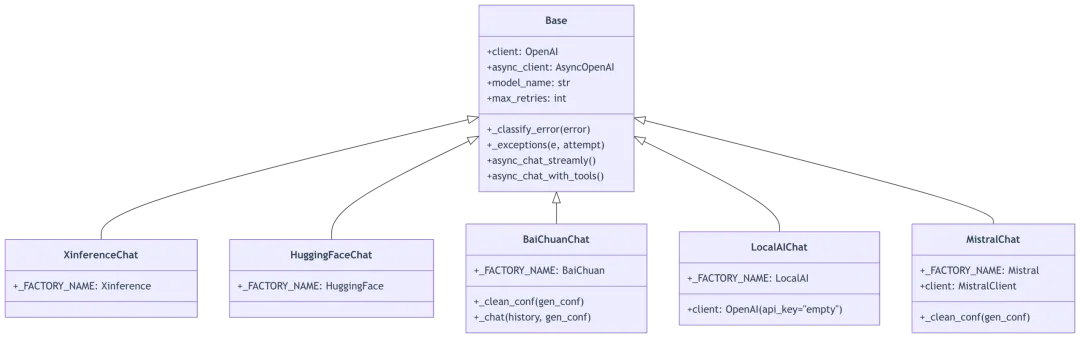
4.1 提供商继承关系
源码位置:rag/llm/chat_model.py:488-694
class XinferenceChat(Base): # 第488行:Xinference推理框架_FACTORY_NAME = "Xinference"def __init__(self, key=None, model_name="", base_url="", **kwargs):if not base_url:raise ValueError("Local llm url cannot be None")base_url = urljoin(base_url, "v1") # 第494行:拼接v1路径super().__init__(key, model_name, base_url, **kwargs)class HuggingFaceChat(Base): # 第498行:HuggingFace本地模型_FACTORY_NAME = "HuggingFace"def __init__(self, key=None, model_name="", base_url="", **kwargs):if not base_url:raise ValueError("Local llm url cannot be None")base_url = urljoin(base_url, "v1")super().__init__(key, model_name.split("___")[0], base_url, **kwargs) # 第505行:去除___后缀class BaiChuanChat(Base): # 第518行:百川AI_FACTORY_NAME = "BaiChuan"def __init__(self, key, model_name="Baichuan3-Turbo", base_url="https://api.baichuan-ai.com/v1", **kwargs):if not base_url:base_url = "https://api.baichuan-ai.com/v1"super().__init__(key, model_name, base_url, **kwargs)def _clean_conf(self, gen_conf): # 第533-537行:自定义参数清理return {"temperature": gen_conf.get("temperature", 0.3),"top_p": gen_conf.get("top_p", 0.85),}def _chat(self, history, gen_conf={}, **kwargs): # 第539-552行:特殊web_search工具response = self.client.chat.completions.create(model=self.model_name,messages=history,extra_body={"tools": [{"type": "web_search", "web_search": {"enable": True, "search_mode": "performance_first"}}]},**gen_conf,)ans = response.choices[0].message.content.strip()if response.choices[0].finish_reason == "length":if is_chinese([ans]):ans += LENGTH_NOTIFICATION_CNelse:ans += LENGTH_NOTIFICATION_ENreturn ans, total_token_count_from_response(response)class LocalAIChat(Base): # 第593行:LocalAI本地推理_FACTORY_NAME = "LocalAI"def __init__(self, key, model_name, base_url=None, **kwargs):super().__init__(key, model_name, base_url=base_url, **kwargs)if not base_url:raise ValueError("Local llm url cannot be None")base_url = urljoin(base_url, "v1")self.client = OpenAI(api_key="empty", base_url=base_url) # 第602行:空API Keyself.model_name = model_name.split("___")[0]class MistralChat(Base): # 第668行:Mistral AI_FACTORY_NAME = "Mistral"def __init__(self, key, model_name, base_url=None, **kwargs):super().__init__(key, model_name, base_url=base_url, **kwargs)from mistralai.client import MistralClientself.client = MistralClient(api_key=key) # 第676行:Mistral SDKself.model_name = model_namedef _clean_conf(self, gen_conf): # 第679-683行:仅允许3个参数for k in list(gen_conf.keys()):if k not in ["temperature", "top_p", "max_tokens"]:del gen_conf[k]return gen_conf
提供商适配策略表:
提供商继承关系图:
五、Chunking解析应用
5.1 解析器工厂映射
源码位置:rag/app/naive.py:222-228
PARSERS = {"deepdoc": by_deepdoc, # DeepDoc解析器"mineru": by_mineru, # MinerU解析器"docling": by_docling, # Docling解析器"tcadp": by_tcadp, # Tencent Cloud ADP解析器"paddleocr": by_paddleocr, # PaddleOCR解析器"plaintext": by_plaintext, # 纯文本解析器(默认)}
解析器对比表:
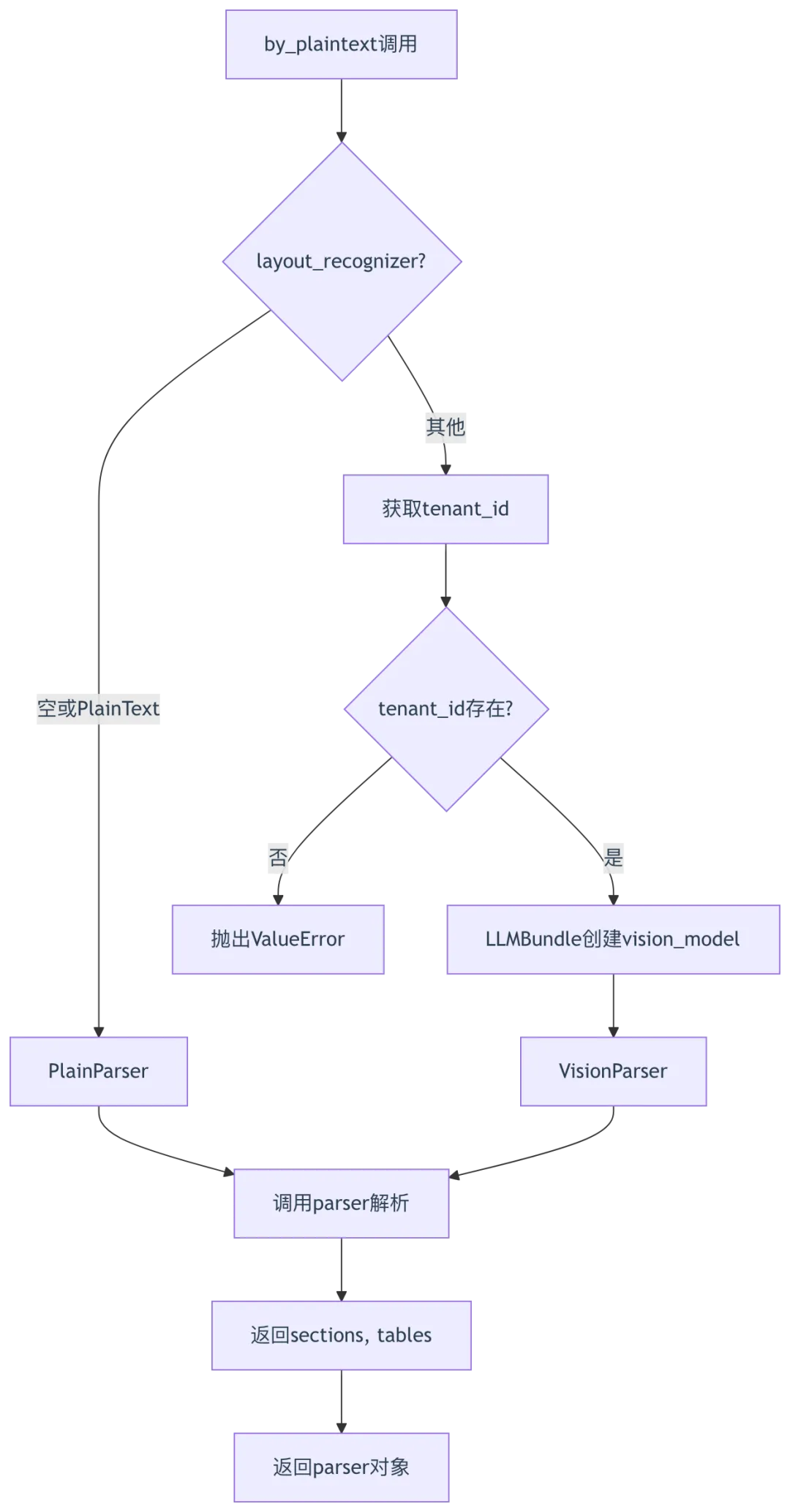
5.2 by_plaintext解析流程
源码位置:rag/app/naive.py:202-219
def by_plaintext(filename, binary=None, from_page=0, to_page=100000, callback=None, **kwargs):layout_recognizer = (kwargs.get("layout_recognizer") or "").strip()# 第204-206行:无layout_recognizer或PlainText,使用PlainParserif (not layout_recognizer) or (layout_recognizer == "Plain Text"):pdf_parser = PlainParser()else:# 第207-216行:使用Vision布局识别tenant_id = kwargs.get("tenant_id")if not tenant_id:raise ValueError("tenant_id is required when using vision layout recognizer")vision_model = LLMBundle(tenant_id,LLMType.IMAGE2TEXT,llm_name=layout_recognizer,lang=kwargs.get("lang", "Chinese"),)pdf_parser = VisionParser(vision_model=vision_model, **kwargs)# 第218行:调用解析器sections, tables = pdf_parser(filename if not binary else binary, from_page=from_page, to_page=to_page, callback=callback)return sections, tables, pdf_parser
解析流程图:
六、设计模式与技术决策总结
6.1 核心设计模式统计表
| 抽象基类 | |||
| 模板方法 | |||
| 策略模式 | |||
| 装饰器模式 | |||
| 工厂模式 | |||
| 继承复用 | |||
| 流式迭代器 |
6.2 技术决策对比表
| 客户端类型 | |||
| 错误重试 | |||
| 工具调用轮数限制 | |||
| 参数清理 | |||
| 流式工具调用 | |||
| JSON解析 |
