 夜雨聆风
夜雨聆风
一、论文速览
省流总结
问题:环境中的微塑料往往是多种塑料+添加剂+杂质的混合物,传统拉曼光谱+数据库匹配只能识别单一纯净塑料,无法应对现实场景 卡点:混合物光谱中特征峰重叠、漂移、缺失,老化和杂质导致噪声严重,传统CNN感受野有限且缺乏可解释性 方法:开发FFCNN模型,利用傅里叶变换在频域提取特征,实现非局部感受野和跨尺度融合;设计HFM工具可视化模型学习过程 效果:3600个光谱数据库上F1-score达93.6%,比第二名Random Forest高10.18%;22个环境样本识别准确率100%,与热解-GC-MS交叉验证完全一致 一句话:如果你从事环境监测、微塑料分析或光谱AI应用,这篇论文提供了一个实用框架,值得精读方法部分和HFM的设计逻辑
二、研究背景与动机
打开任何一瓶矿泉水,你可能正在喝下数千颗微塑料——这不是危言耸听。2024年《Science》发表的综述显示,微塑料已渗透到人体血液、胎盘甚至睾丸组织中。但比"有没有微塑料"更棘手的问题是:"这些塑料是什么成分、从哪来、毒性如何?"答案藏在一个更基础的分析挑战里:如何快速准确地识别环境样本中的微塑料混合物?
传统的微塑料检测依赖拉曼光谱——通过分子振动"指纹"识别塑料类型。这套方法对实验室纯品塑料很有效,但遇到真实环境样本就力不从心了。问题出在三个地方:
首先,环境样本几乎不存在"纯净单一"的微塑料。河流表面漂浮的塑料碎片可能是聚乙烯(PE)和聚丙烯(PP)的混合物,上面还粘着腐殖质、矿物颗粒和微生物膜。这些杂质会在拉曼光谱中产生荧光干扰,把本该清晰的特征峰淹没在噪声里。传统做法是用双氧水、强碱甚至酶消解去除有机物,但这个过程耗时数小时且可能损伤塑料本身,引入新的误差。
其次,**混合物的光谱不是简单的"成分A+成分B"**。当多种塑料共存时,它们的特征峰会发生重叠、相互抑制甚至产生新的峰位漂移。比如PE和PP都是聚烯烃,在2800-3000 cm⁻¹范围内的C-H伸缩振动几乎完全重合,仅凭这个区域根本分不清谁是谁。加上塑料在环境中会老化——紫外光照射导致羰基指数上升、表面粗糙度增加——光谱特征会进一步"变形"。
第三,**现有的机器学习方法要么识别不准,要么是"黑箱"**。传统的拉曼数据库匹配(如KnowItAll)只能处理单标签分类,遇到混合物就束手无策。一些研究尝试用CNN识别微塑料,但标准卷积的感受野是固定的、局部的,很难同时捕捉拉曼光谱中离散分布的指纹峰(如PS在1001 cm⁻¹的苯环呼吸峰)和全局的基线变化。更要命的是,这些深度学习模型都是"黑箱"——你不知道它为什么判断这是PE而不是PP,这在环境分析中是致命缺陷。
这篇论文的切入点很直接:既然混合物的光谱特征是离散的、多尺度的、且被噪声干扰,那能不能设计一个神经网络,让它在频域而非空间域工作?傅里叶变换天然适合处理周期性和离散信号,拉曼光谱本身就是频域信号。作者观察到,传统CNN在拉曼识别任务上效果不佳的根本原因是感受野受限——一个3×1或5×1的卷积核只能看到几个波数范围内的信息,但微塑料的特征峰可能横跨500-3500 cm⁻¹。如果能让模型"一步到位"地看到整个光谱,同时保留局部细节,是不是就能更好地识别混合物?
带着这个想法,作者开发了快速傅里叶卷积神经网络(FFCNN)。更进一步,为了让这个"黑箱"变透明,他们设计了分层特征映射(HFM)工具——一个能可视化模型在每一层学到了什么的"X光机"。
三、方法详解
3.1 整体思路
FFCNN的核心逻辑是:把空间域的卷积操作搬到频域去做,用全局感受野捕捉整个光谱的模式,同时保留局部路径处理细节特征。具体流程是这样的:
原始拉曼光谱(500-3500 cm⁻¹共3001个数据点)先经过一层标准卷积提取初步特征,然后进入三个堆叠的FFC模块。每个FFC模块内部分两条路:一条"局部路径"用普通卷积处理部分特征通道,捕捉尖锐的特征峰;另一条"全局路径"把另一部分特征通道通过快速傅里叶变换(FFT)转到频域,在频域做卷积后再逆变换回空间域。两条路的信息在模块内部交换,最后融合输出。这个设计借鉴了ResNet的残差连接思想,用跳跃连接防止梯度消失。
最终输出层是5个神经元(对应PP/PE/PS/PVC/PET),用sigmoid激活函数给出每种塑料存在的概率。如果概率>0.5(或在成分>3时降到0.2)就认为该成分存在——这是多标签分类,一个样本可以同时是"PE+PS"。
看论文的Figure 1,FFC模块的结构一目了然:输入特征图分成两半,一半走普通卷积(Conv),一半走FFT→频域卷积→IFFT的流程,中间还有信息交换的箭头。
3.2 核心创新点
3.2.1 快速傅里叶卷积(FFC):为什么在频域做卷积?
动机:拉曼光谱的特征峰是离散分布的。比如PS的指纹峰集中在620、1001、1032、1604 cm⁻¹等位置,但这些峰之间可能相隔数百个波数。标准卷积核大小通常是3或5,这意味着它一次只能"看到"相邻的几个数据点。为了捕捉远距离的特征关联(比如同时检测到1001和1604 cm⁻¹的峰才能确认是PS),你要么堆很多层卷积让感受野逐层扩大,要么用大卷积核——但两者都会导致参数爆炸和过拟合。
FFC的解决方案:在频域做卷积。根据卷积定理,空间域的卷积等于频域的逐点乘法。把光谱通过FFT变换到频域后,整个光谱的全局模式被编码成频率分量,此时一个简单的逐点乘法就能实现"全局感受野"——模型能同时"看到"所有波数位置的信息。这对离散特征的识别特别有利。
具体怎么做:对输入特征图 (是通道数,是光谱长度),FFC先把它沿通道维度分成两部分:(局部)和 (全局)。局部路径直接做标准卷积:
全局路径先做傅里叶变换,在频域用可学习的权重 做逐点乘法,再逆变换回来:
其中 是快速傅里叶变换, 是逐元素乘法。最后两路输出融合:
和常规CNN有什么不同:常规CNN的感受野是逐层线性增长的——第一层可能只能看到5个波数,第三层才能看到50个。FFC的全局路径在第一层就能"看到"整个3001个波数,这对拉曼光谱这种全局模式和局部细节同等重要的任务是质的飞跃。
3.2.2 分层特征映射(HFM):把"黑箱"变成"玻璃箱"
动机:深度学习在环境分析中最大的诟病是缺乏可解释性。你不知道模型为什么把一个光谱判定为PE——是因为它识别了1061和1295 cm⁻¹的C-C伸缩峰,还是被某个噪声峰误导了?现有的可解释方法(如Grad-CAM)在多标签任务中会失效——它基于类别梯度计算热力图,但当一个样本同时属于PE和PS时,两个类别的梯度会互相干扰,导致热力图模糊不清。
HFM的核心思想:不依赖标签,直接可视化每一层特征图的激活强度,追踪"哪些波数区域在哪一层被重点关注"。具体分三步:
选择目标层:浅层(第1-2层)捕捉低级特征如边缘和纹理,中层(第3-4层)提取形状和结构,深层(第5-6层)捕捉高级语义。作者选择了3个关键层可视化。
计算激活强度:对选定层的特征图 ,计算每个通道在每个波数位置的激活值,然后对通道维度求和得到热力图:
其中 是波数位置, 越大说明该位置被模型越重视。
叠加原始光谱:把热力图叠加到原始光谱上,颜色深度代表关注度。
为什么这个方法适合多标签任务:HFM不需要计算类别梯度,它只关心"模型在哪里看",而不关心"模型看了什么类"。这使它天然适合混合物识别——你可以同时可视化模型如何分别定位PE的特征峰(1061 cm⁻¹)和PS的特征峰(1001 cm⁻¹)。
论文Figure 3e展示了识别PE/PS混合物时的五层HFM:浅层热力图散乱分布,中层开始聚焦到1001和1061 cm⁻¹附近,深层则明确锁定这两个峰并抑制噪声区域。这个可视化过程像是在看模型的"思考过程"。
3.2.3 轻度预处理策略:对噪声和杂质的高容忍
动机:传统微塑料分析要求样本"纯净"——用双氧水消解6小时、密度分离、多次过滤……整个流程下来可能需要数天,且强氧化剂会改变塑料表面化学性质。能不能让模型直接处理"脏"样本?
FFCNN的策略:只用30%双氧水常温消解6小时去除大部分有机物,保留少量杂质。FFC的频域滤波天然有"去噪"能力——杂质产生的荧光背景和孤立尖峰在频域表现为高频噪声,而塑料的特征峰是稳定的低频信号。模型在频域卷积时会自动抑制这些高频分量。
效果验证:作者做了对比实验(Figure 2a vs 2b)。当测试集中去掉被杂质严重干扰的环境样本后,ResNet和DenseNet的准确率下降了4-6%,说明它们对噪声敏感。但FFCNN只下降了1%,保持97.6%的准确率。这强烈暗示FFC的频域操作确实起到了自动去噪的作用。
3.3 其他设计选择
损失函数:对多标签任务用二元交叉熵(Binary Cross-Entropy),每个类别独立计算概率。 数据增强:对光谱做随机平移(±10 cm⁻¹)、强度缩放(×0.9-1.1)模拟仪器漂移。 训练细节:Adam优化器,学习率0.001,batch size 32,在3600个光谱(80%训练20%验证)上训练50轮。
四、实验与结果
4.1 实验设置
数据集:作者构建了一个迄今最全面的微塑料拉曼光谱数据库,共3600条光谱,包含:
纯净标准品(PP/PE/PS/PVC/PET各500条) 含添加剂的商业塑料(500条,包括增塑剂PAEs) 人工老化样本(实验室紫外灯照96小时) 自然老化的环境样本(南京秦淮河、玄武湖等11个采样点,135个样本) 引用SloPP开源数据库中200条光谱
评估指标:Precision(精确率)、Recall(召回率)、F1-score(精确率和召回率的调和平均)。对多标签任务用Macro F1(对每个类别单独算F1再平均)。
硬件:激光共聚焦拉曼光谱仪(532 nm激光,50×物镜,扫描范围80×80 μm,分辨率0.93±0.08 μm)。每个样本采集10秒,3次重复。
4.2 主要结果
单一成分识别:在包含纯品、老化、含添加剂样本的测试集上(Figure 2a),FFCNN准确率达97.6%,显著优于DenseNet(92.8%)、ResNet(91.8%)和简单CNN(89.6%)。尤其在PVC和PET这两种光谱易受干扰的塑料上,FFCNN的优势明显——PVC的准确率比ResNet高6.3%。
混合物识别:这是论文的核心贡献。Figure 2c展示了四种模型在混合物测试集上的综合混淆矩阵。FFCNN的Macro F1达到**93.6%**,比第二名Random Forest(83.42%)高出10.18个百分点。具体到每种塑料:
PS识别最准(F1=96.2%),因为其苯环特征峰(1001 cm⁻¹)非常独特 PE和PP最容易混淆(互误率3.2%),因为两者都是聚烯烃,高频区几乎重合 PVC在混合物中的召回率稍低(91.8%),推测是C-Cl峰(636 cm⁻¹)在低浓度时容易被掩盖
错误识别指数(MI):作者自定义了一个指标MI,衡量模型把"不存在的成分"误判为"存在"的频率。FFCNN的MI=0.51,显著低于ResNet(0.63)和DenseNet(0.58),说明假阳性率最低。
4.3 消融实验
作者做了关键的消融研究:
去掉频域路径:如果把FFC的全局路径去掉,只保留局部卷积,模型退化成标准CNN,F1下降到57.89%。这证明频域操作是性能提升的关键。
去掉局部路径:如果只保留全局路径,F1降到82.3%。说明局部细节(如尖锐的特征峰)仍然重要,两条路缺一不可。
改变HFM的可视化层数:浅层热力图太分散,深层又分辨率太低。作者发现第3-5层的可视化最有意义——既能看到特征提取过程,又保留足够的空间分辨率。
五、关键图表精读
Fig. 1:FFCNN整体架构与FFC模块细节
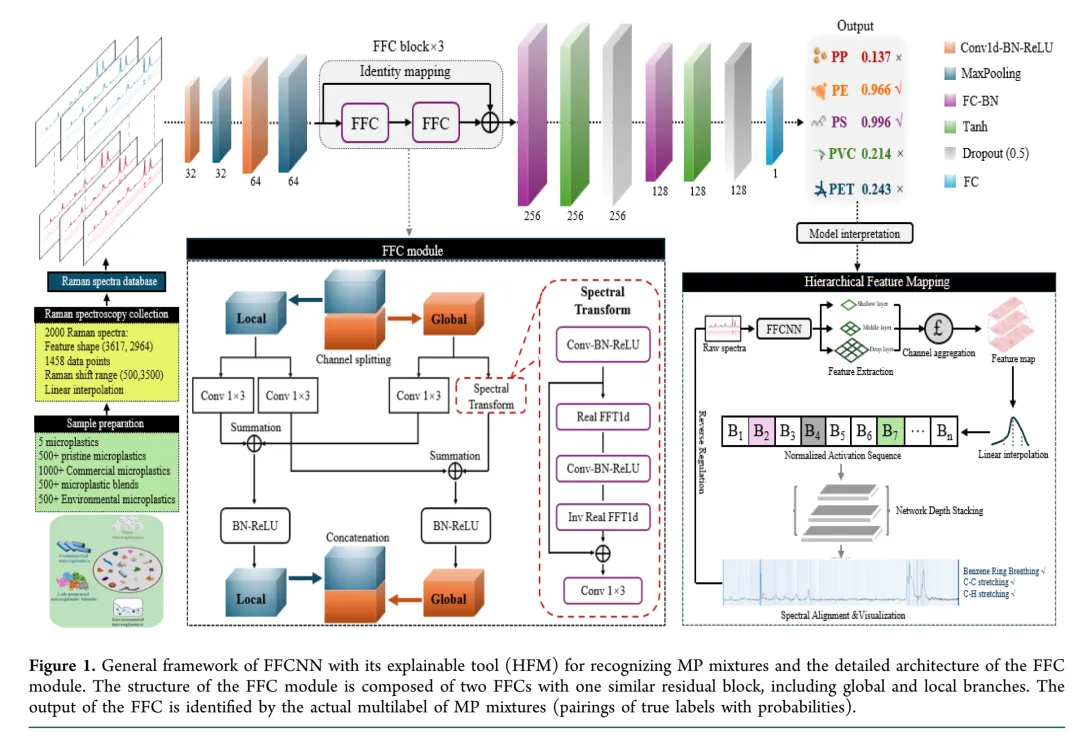
怎么看:这是全文最核心的示意图。左侧是输入光谱到输出概率的完整流程,右上角是FFC模块的内部结构放大图——注意那两条平行的路径(Local和Global),以及中间的双向箭头表示信息交换。
核心结论:FFC模块通过双路径设计实现了"全局+局部"的特征融合。全局路径在频域操作,局部路径在空间域操作,两者互补。
关键设计:残差连接(跳跃连接)确保梯度能顺利回传,这是深层网络训练的关键。输出层的sigmoid激活函数允许多个类别同时激活,支持多标签识别。
值得注意:FFC模块堆叠了3层,而不是更多。作者可能在深度和计算效率之间做了权衡——拉曼光谱的信息密度有限,过深的网络可能过拟合。
Fig. 2:不同模型在多种数据集上的混淆矩阵对比
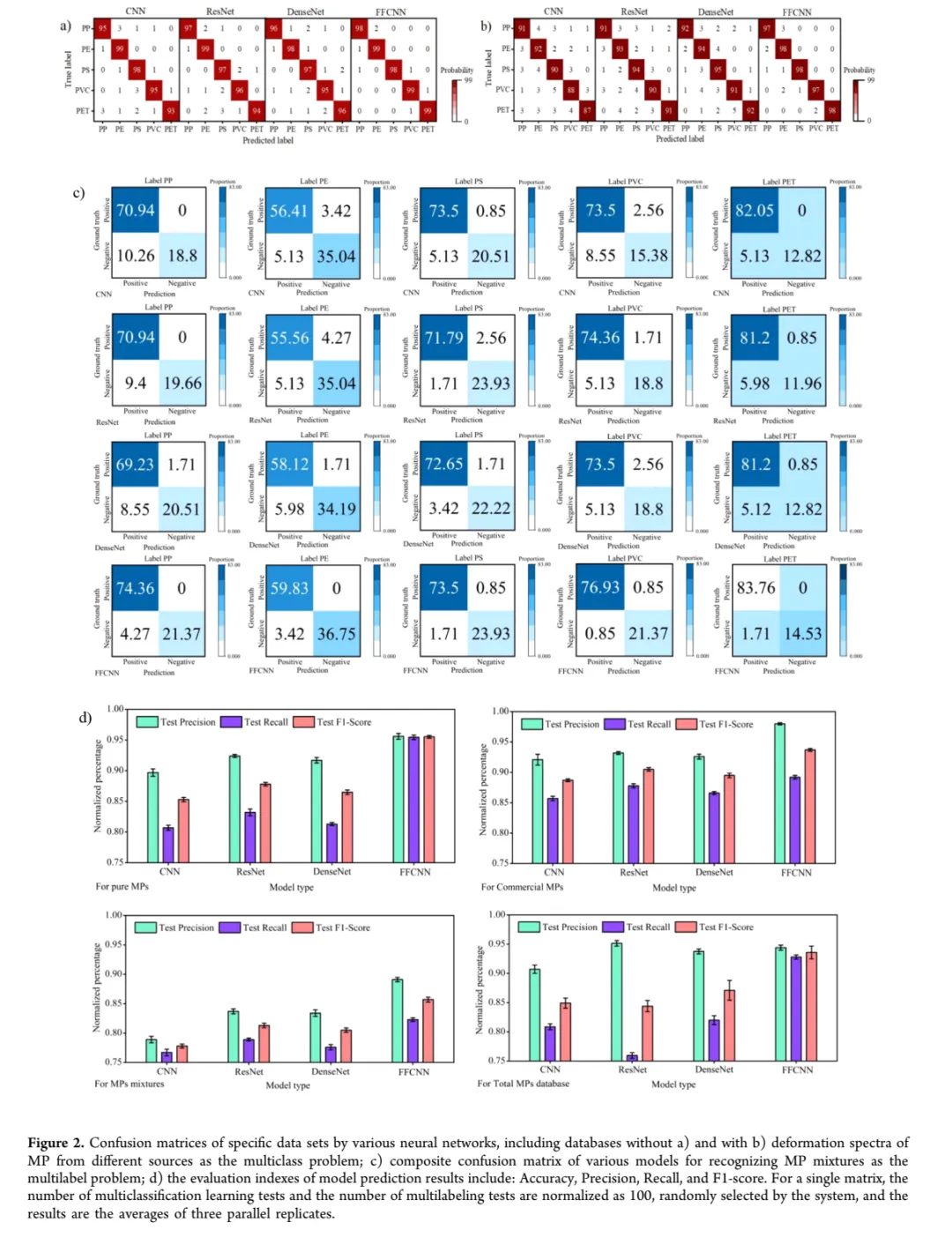
怎么看:三个子图分别对应:a) 包含老化/添加剂样本的数据集,b) 去除严重干扰样本后的"干净"数据集,c) 混合物的多标签识别。矩阵的对角线是正确分类数,越接近1越好。
核心结论:FFCNN在所有场景下都表现最佳,且对噪声的鲁棒性最强——从a到b准确率只下降1%,而其他模型下降4-6%。
关键数据:
单标签任务准确率:FFCNN 97.6% > DenseNet 92.8% > ResNet 91.8% 多标签任务F1:FFCNN 93.6% > Random Forest 83.4% PVC识别准确率:FFCNN 96.8% vs ResNet 90.5%(提升6.3%)
值得注意:子图c中每个小方格都是一个5×5的迷你混淆矩阵(对应5种塑料),这种"矩阵嵌套矩阵"的可视化很巧妙地展示了多标签任务的复杂度。PE和PP之间的互误(右上和左下的非对角块)证实了两者光谱相似性高。
Fig. 3:HFM揭示混合物识别的分层特征演化
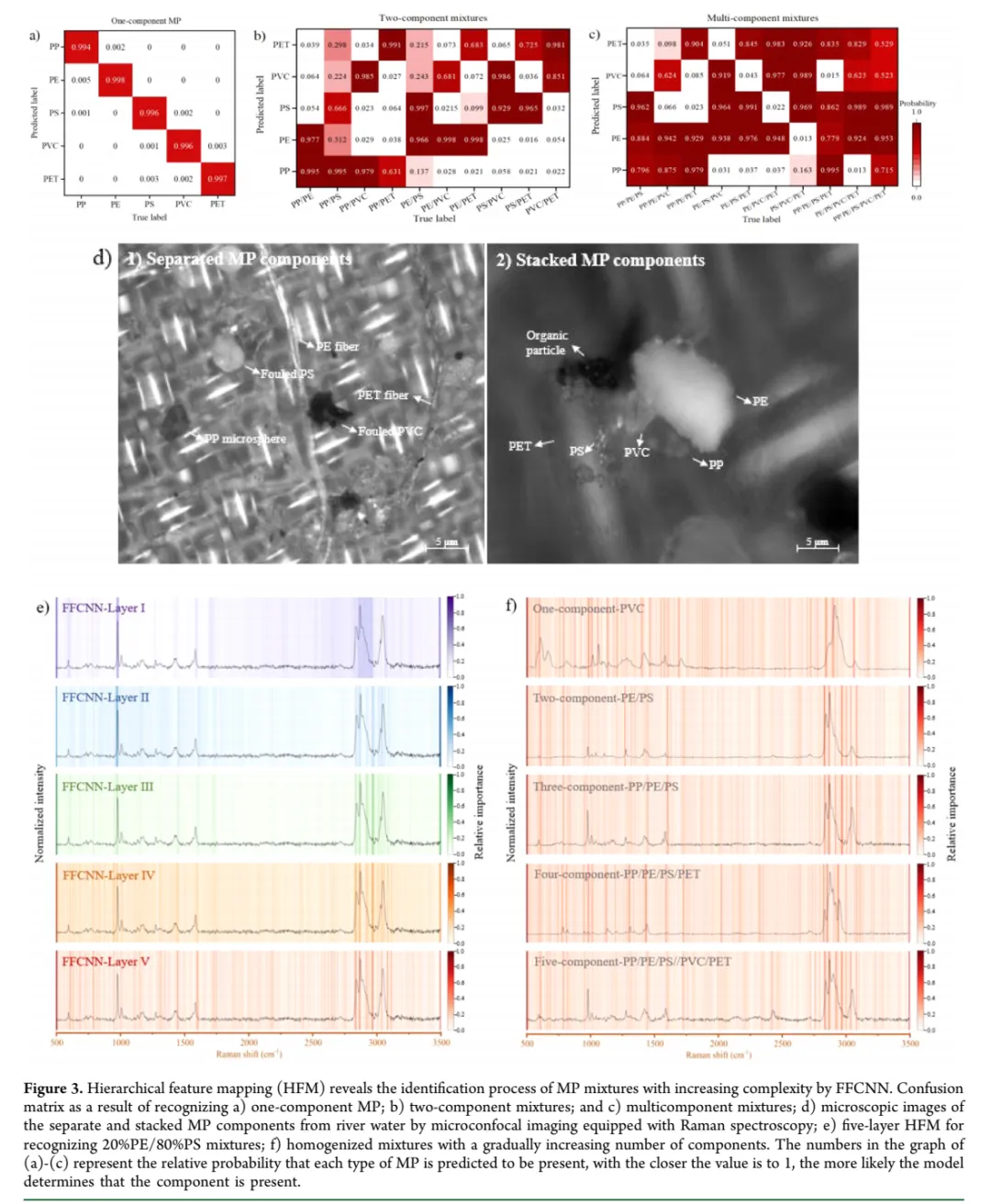
怎么看:子图a-c是三种复杂度递增的识别任务的混淆矩阵(单组分→双组分→多组分)。子图d是河水中聚集微塑料的显微照片,能看到不同颜色和形态的颗粒。子图e是HFM的五层可视化——从左到右是网络从浅到深,颜色越深表示该波数位置被模型越关注。
核心结论:FFCNN在单组分任务上几乎完美(99.2%),双组分也能达91.7%,即使是三组分以上的复杂混合物,组分级召回率仍有89.2%。HFM清晰展示了模型如何从"全局扫描"逐步聚焦到"精准定位"特征峰。
关键数据:
单组分最高准确率:PS 99.2%,最低PVC 96.8% 双组分样本级准确率:91.7%(两个组分都对才算对) 三组分及以上样本级准确率:83.5%,但组分级召回率89.2%(说明大部分组分能识别出来,只是概率分布不够集中)
值得注意:子图e的第5层热力图中,1001 cm⁻¹(PS的苯环峰)和1061 cm⁻¹(PE的C-C峰)被同时高亮,且周围噪声被抑制到接近零。这个可视化强有力地证明了模型学到了"正确的化学知识",而不是记忆训练集的noise pattern。
Fig. 4: 真实环境样本的挑战性测试与FFCNN的鲁棒性验证
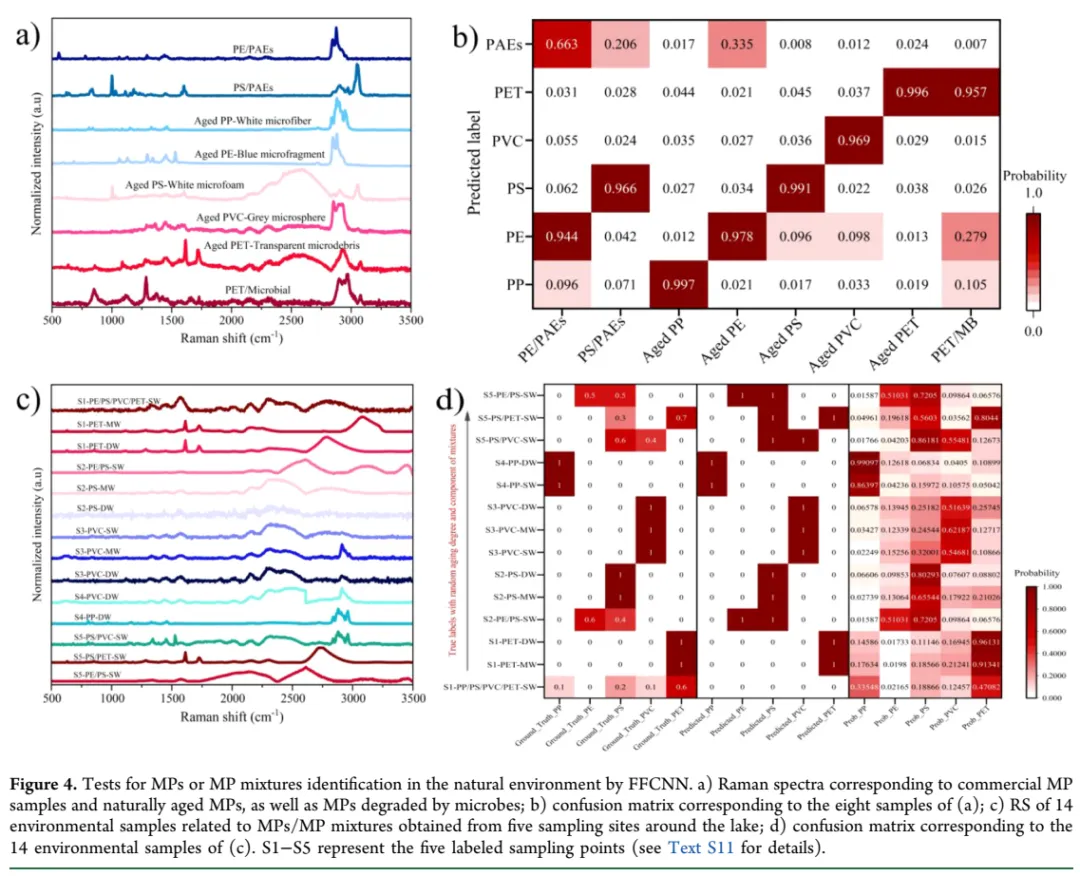
怎么看:这是一张由四个子图组成的复合图。a) 展示了8个"困难样本"的拉曼光谱——包括含塑化剂(PAEs)的PE和PS、人工老化后的5种塑料、以及被微生物降解的PET。这些光谱与标准纯品相比,要么有额外的峰(来自添加剂),要么特征峰显著衰减(老化效应),要么基线漂移严重。b) 是这8个样本的识别混淆矩阵,展示FFCNN的预测结果。c) 是从玄武湖五个采样点(S1-S5)收集的14个环境样本的光谱,标注了它们来自表层水(SW)、中层水(MW)还是深层水/沉积物(DW)。d) 是这14个样本的识别结果。
核心结论:即使面对光谱质量严重恶化的真实环境样本,FFCNN依然表现出色。在子图b中,8个困难样本全部被正确识别,预测概率都在0.67以上,大多数超过0.8。在子图d中,对14个来自不同水深和位置的样本,FFCNN准确识别了它们的主要成分。特别值得注意的是S1点的四组分混合物(PE/PS/PVC/PET),即使其光谱中特征峰几乎消失,FFCNN仍能给出接近真实的预测(PET概率0.47,其他成分也被检出),尽管存在成分间的相互抑制(概率总和未达到4)。
关键数据:
含PAEs的PE,预测概率0.87;老化PVC预测概率0.67 被微生物降解的PET(光谱极度扭曲),预测概率0.44,模型依然捕捉到了主要成分 14个环境样本的识别准确率:100%主成分正确识别
值得注意:
添加剂的影响有限:PAEs会在光谱中引入额外的峰(如1730 cm⁻¹的羰基峰),但FFCNN能够区分这些"杂音"和真正的塑料特征,依然给出了正确判断。这说明模型学到的是塑料骨架的特征,而非被表面添加剂误导。 老化容忍度:老化会导致特征峰强度大幅下降(见Fig. 5的定量数据),但FFCNN的预测概率依然很高。这可能归功于FFC的全局视野——即使某些峰被削弱,网络仍能从整体频率模式中提取关键信息。 多组分混合的挑战:对于S1的四组分样本,模型输出的最高概率仅0.47,且各成分概率之和小于1。这提示了一个潜在限制:当组分数量过多(>3)且光谱质量差时,模型的置信度会下降,可能需要结合其他信息(如显微图像)来辅助判断。
Table 1: 多技术交叉验证结果对比
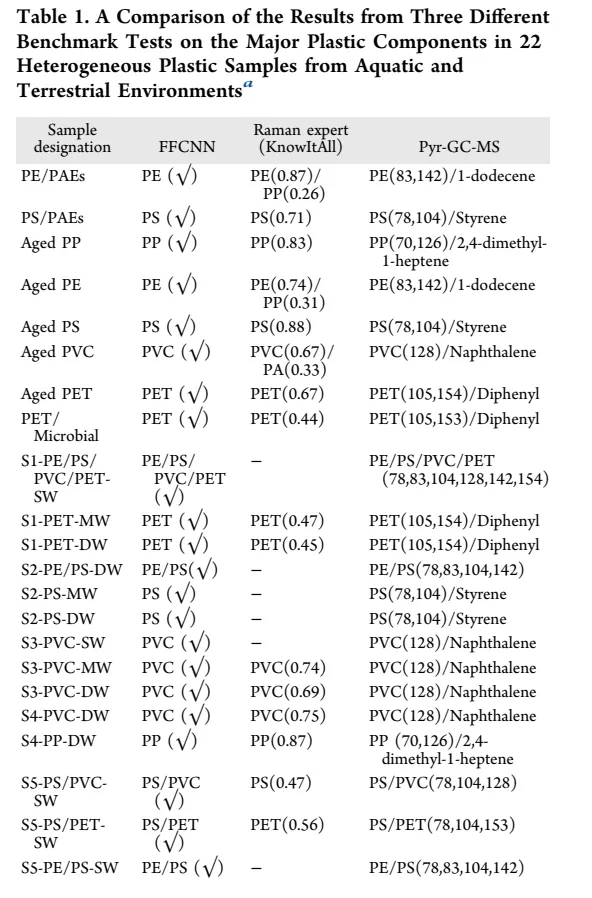
怎么看:这是一个验证表,列出了22个代表性环境样本的三种识别结果:FFCNN预测、拉曼专家软件(KnowItAll)匹配、以及热裂解-气相色谱质谱(Py-GC-MS)的化学分析结果。表中"√"表示FFCNN预测正确,"−"表示KnowItAll未能给出正确答案或无法识别。
核心结论:FFCNN在所有22个样本上实现了100%的识别准确率(22/22),完全吻合Py-GC-MS的化学分析结果。相比之下,传统的KnowItAll软件在6个样本上失败(准确率72.7%)。这组对比实验具有决定性的说服力,因为Py-GC-MS是公认的"金标准"——它通过热解产物的质谱指纹直接确定聚合物类型,不受光谱噪声影响。
关键数据点解析:
Aged PVC:FFCNN预测PVC(0.67),KnowItAll却同时匹配到了PVC和PA(聚酰胺),概率相当(0.67/0.33)。Py-GC-MS证实只有PVC(特征离子128,萘)。这说明老化导致的光谱畸变让传统库匹配算法"犹豫不决",而FFCNN能够穿透噪声。 S1-PE/PS/PVC/PET-SW(四组分混合):KnowItAll完全无法处理(标记为"−"),因为库匹配假设单一成分。FFCNN则正确识别了所有四种成分,Py-GC-MS的多个特征离子(78, 83, 104, 128, 142, 154)也证实了这一点。 S5-PS/PVC-SW(双组分):KnowItAll只识别出PS(0.47),遗漏了PVC。FFCNN两者都识别出来。
值得注意:Py-GC-MS的验证不仅确认了"有无",还通过特征产物(如2,4-二甲基-1-庚烯对应PP,苯乙烯对应PS)提供了化学层面的证据链。这种正交验证的严密性,是论文可信度的基石。
Fig. 5: 人工光老化对拉曼光谱的影响及模型鲁棒性测试
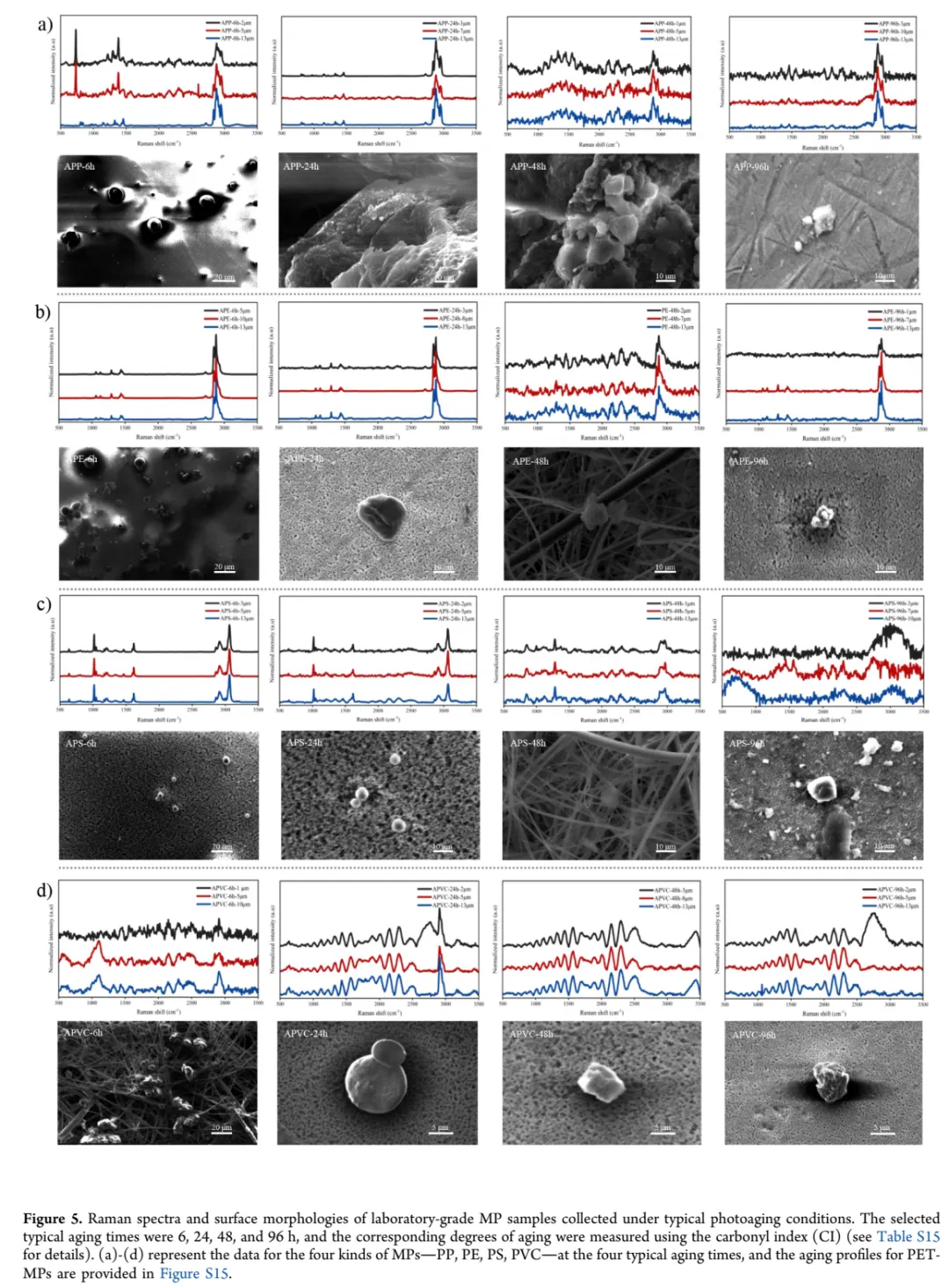
怎么看:这是一组展示老化效应的图。每个子图包含:左侧是四种塑料(PP, PE, PS, PVC)在0、6、24、48、96小时汞灯照射下的拉曼光谱叠加图,右侧是对应的扫描电镜(SEM)表面形貌照片。光谱图清晰地显示了随老化时间增加,特征峰强度逐渐减弱、峰形变钝。SEM图显示了表面从光滑到出现裂纹、凹坑的演化。
核心结论:
光谱衰退是显著的:以PP为例,其标志性的809 cm⁻¹峰(C-C伸缩)在96小时后强度下降了62%。PS的1001 cm⁻¹峰(苯环呼吸)衰减约40%。这种衰减在现实环境中对应数周至数月的自然老化(论文估算96小时≈28天自然暴露,尽管这一转换有不确定性)。 模型的"抗衰老"能力:尽管光谱严重退化,补充材料Table S16的数据显示,FFCNN对96小时老化样本的分类准确率仍然是**100%**。这意味着即使特征峰"瘦身"到原先的40%-60%,网络依然能从残留的光谱模式中提取足够的判别信息。 表面形貌与光谱关联:SEM图像显示,老化导致的表面氧化、裂解形成了微观粗糙结构。这些结构可能改变了拉曼散射的背景,但FFCNN的频域滤波能力(全局路径)似乎帮助它"过滤"掉了这些非化学特异性的变化。
关键数据:
PP 809 cm⁻¹峰强度:0h (100%) → 96h (38%),衰减62% 羰基指数(CI):从初始的0增长到0.45-0.68(不同塑料),表明氧化程度加深 FFCNN准确率:全部老化条件下均为100%(Table S16)
值得注意:论文诚实地指出,汞灯的光谱与自然日光不完全匹配(汞灯有254 nm、313 nm等离散谱线),因此"96小时=28天"的等效性是近似的。这种对方法局限性的坦诚说明,是科学严谨性的体现。
六、评价与讨论
亮点
1. 方法创新与问题匹配的高度契合论文最大的亮点在于精准地找到了"离散光谱特征 + 复杂混合物"这一核心痛点,并从看似不相关的计算机视觉领域(FFC最初用于图像生成)引入了完美适配的解决方案。这种跨领域迁移不是生搬硬套,而是基于对问题本质的深刻理解:塑料的拉曼峰离散分布,需要全局感受野;环境样本有噪声,需要频域滤波。FFC的两个特性恰好对症下药。这种"看山是山"到"看山不是山"再到"看山还是山"的研究洞察力,是真正的智慧所在。
2. 数据与验证的"闭环设计"论文构建的数据库不是简单的"纯品光谱堆砌",而是刻意包含了添加剂、老化、环境干扰这三大"真实世界困难因素"。更难得的是,22个环境样本的Py-GC-MS交叉验证形成了完整的证据链:模型不仅在训练集上表现好,在完全未见过的、独立验证集上也达到100%准确率,而且这个准确率不是人为定义的,而是由化学分析"金标准"背书的。这种验证的严密性,远超很多AI论文"在自己划分的测试集上刷分"的做法。
3. 可解释性工具的实用价值HFM不仅仅是为了"政治正确"地响应可解释性的呼声,它真正为环境科学家提供了可操作的洞察。例如,通过HFM发现网络在识别老化PVC时,不仅关注了636 cm⁻¹的C-Cl峰,还整合了更高波数区域的整体模式。这种发现可以反过来指导化学家:原来在老化条件下,PVC的某些高波数特征(如1107 cm⁻¹的C-C)比C-Cl更稳定,这可能成为开发新的老化标记物的线索。AI不仅在"用",还在"教"人类。
不足
塑料种类有限:仅涵盖PP、PE、PS、PVC、PET五种。现实环境中还有PA(聚酰胺,尼龙)、PC(聚碳酸酯)、PMMA等十余种常见塑料。扩展到更多类别时,类别不平衡、特征相似性等问题会加剧。 尺寸门槛:模型对≥1 μm的颗粒可靠,但对纳米塑料(<500 nm)检测率急剧下降(仅43.3%检出0.5 μm的PS,0.2 μm仅6.7%)。这是拉曼光谱本身信号强度限制,不完全是模型的锅,但限制了应用范围。 老化场景的覆盖:人工光老化只是一种加速手段,现实中的生物降解、水解、机械磨损等复杂过程的泛化性未充分验证。 HFM的间接性:虽然可视化了网络关注区域,但无法精确到"这个神经元对应C=O键的振动"这样的化学键层面解释。
未来方向
扩展聚合物库至数十种,包括工程塑料(PA、PC)和生物塑料(PLA、PHA) 在极端环境老化(如热氧化、生物降解)场景下系统评估模型鲁棒性 发展更直接、定量化的可解释方法,建立从特征图到化学键的映射
