 夜雨聆风
夜雨聆风你一定遇到过这种场景吧?打开AI工具问问题,它噼里啪啦输出一大段,逻辑通顺、用词精准,你抄起结果就用,结果转头发现全错。
前阵子看到一位网友吐槽,自己手机天天接到陌生电话,一开口就问他卖不卖猪。他以为是恶作剧,追根溯源才发现,居然是AI把他的手机号错误标注成了一家养殖场的联系方式。好好一个上班族,平白无故成了“生猪养殖户”,哭笑不得。
我自己写东西的时候也踩过坑,让AI帮忙整理文献参考,结果生成的27篇文献里,只有3篇真实存在,剩下的全是AI编出来的,连期刊名称都编得有模有样。
为什么好好的AI,会干出这种一本正经胡说八道的事?今天我们就把这件事说透,从底层逻辑帮你拆解清楚,最后还会告诉你普通人怎么避开这个坑。

先搞懂:什么是AI幻觉
你听到最多的说法,就是把这种胡说八道叫做AI幻觉。
据奇安信人工智能领域专家介绍,AI幻觉主要指大模型的幻觉,就是大模型在生成回答的过程中,看似生成了合理流畅、语义语法都没有问题的回答,但是在事实性、真实性上面存在问题。它可能非常自信,一本正经地输出内容,但实际上根本不对。
简单来说,AI说的话听起来全对,仔细一查全错。
这种问题不是偶发的小bug,在各个领域都能碰到:有律师用ChatGPT生成法律文书,结果里面引用的所有司法案例全是AI虚构的,最后律师被法院罚款;证券分析师用AI写行业报告,AI直接编造出不存在的企业扩产数据,连政府红头文件编号都能编出来;医疗场景里,AI甚至会给错误诊断病症,差点耽误患者治疗。
你会发现,哪怕错得离谱,AI的语气永远笃定,逻辑永远顺滑,普通人根本很难第一时间分辨出来。这意味着什么?
这意味着,你如果把AI说的话全盘接受,很可能就会掉进它挖好的坑里。尤其是涉及到专业领域的关键信息,一个小小的幻觉就能带来不小的麻烦。
数据层面:先天不足的种子
那AI为什么会产生幻觉?我们从根源一层层说,第一关就是训练数据的问题。
AI不是凭空长出知识的,它所有的认知都来自训练它的数据集。如果训练数据本身就有问题,AI学不到正确的知识,出错自然是早晚的事。
第一个问题是数据质量参差不齐。现在大模型的训练数据大多来自开放互联网,网上本来就混杂着大量谣言、错误信息和过时内容。比如你问AI某个景区能不能去,AI可能把三年前旧闻当成最新信息,告诉你可以进入,但实际上这个地方早就封山保护了。据中华网报道,国内已经有多起因AI传播过时错误信息,导致游客白跑一趟的案例发生。
这意味着什么?训练数据里本来就掺了沙子,AI吃进去沙子,排出来的自然不可能是干净的面粉。
第二个问题是数据时效性不足。社会在发展,信息在更新,很多新事物、新规则是训练数据截止之后才出现的,AI没有接触过这些新信息,自然只能靠旧知识瞎猜。你问它今年新发布的政策,它只能把过去类似政策拼起来给你,内容不对太正常了。
第三个问题是知识盲区。如果你的问题非常冷门,或者属于非常细分的专业领域,训练数据里根本没有足够的相关内容,AI就只能强行“编”出一个答案。它不会说“我不知道”,只会硬着头皮给你拼出一段看似通顺的话,结果当然就是错的。
更麻烦的是,AI错误生成的内容,一旦被放到网上再次成为训练数据,就会形成“滚雪球”效应,错误会越传越多,进一步污染整个数据集。

核心根源:模型天生就是这样
说了数据问题,其实这都不是最关键的。AI会胡说八道,最核心的原因,来自它本身的底层机制。
你得先搞懂,现在的大语言模型本质是什么?它本质上是一个概率预测工具。
它的工作逻辑非常简单:你给它一段文字,它根据前面所有的文字,预测下一个哪个词出现的概率最高,然后把这个词放出来。一个词接一个词,拼出一整段回答。
它的核心目标是什么?不是告诉你正确的事实,而是生成一句接一句通顺流畅的话。
举个非常形象的比喻,大模型就像一个参加开卷考试的学生,他不需要知道答案对不对,只要把句子写通顺就能拿到步骤分。所以他会优先保证每一句话都顺理成章,哪怕内容不对,也比卡在那里说不出话强。
它不理解你问的问题到底是什么意思,也不知道自己说的内容是不是真的,它只是按照统计规律,把词一个接一个拼出来而已。遇到训练数据里没见过的问题,它就闭着眼睛猜,反正只要拼出来的话通顺,它就觉得自己完成任务了。
这就是为什么它总能一本正经地胡说八道——从它的逻辑来看,它只是在完成“生成通顺文本”的任务,根本不知道自己在“胡说”。
这意味着什么?幻觉不是AI变坏了,也不是它故意骗你,它天生就是这么工作的。只要还是这种概率预测的底层机制,幻觉就不可能完全消失。
还有一个容易被忽略的原因,就是当前的评估机制在变相鼓励幻觉。研究显示,现在主流的模型评估方式,都是“答对得分,不答不得分”,这种规则下,模型选择“瞎猜一个答案”,比直接说“我不知道”收益更高。时间长了,模型自然就养成了“不懂也硬编”的习惯。
那些被你忽略的诱因
除了数据和机制本身,还有一些常见情况,会更容易诱发AI产生幻觉。
最常见的就是上下文过长。你给AI发了几千字的材料,让它从中总结信息,很多模型处理不了这么长的上下文,前面的信息读到后面就忘了,只能自己拼内容补全,错误率自然就上去了。
还有一种情况,就是你的输入本身前后矛盾。比如你前面说“我要找2024年发布的政策”,后面又说“请结合2025年的新规修改”,AI搞不清楚你到底要哪个,就只能各拼一点,出来的结果自然不对。
你可能会问,现在不是很多模型都支持十万字以上的上下文了吗?这个问题是不是解决了?其实没有。支持长上下文不代表能记住所有细节,越是长文本,越容易出现细节错误,这是目前行业内共同的难题。据新浪财经报道,即使是当前顶尖的大模型,处理超过十万字的长文本时,事实错误率也会比短文本高出近一倍。
这意味着什么?你给AI的内容越长,越要小心它偷偷给你“编”细节。
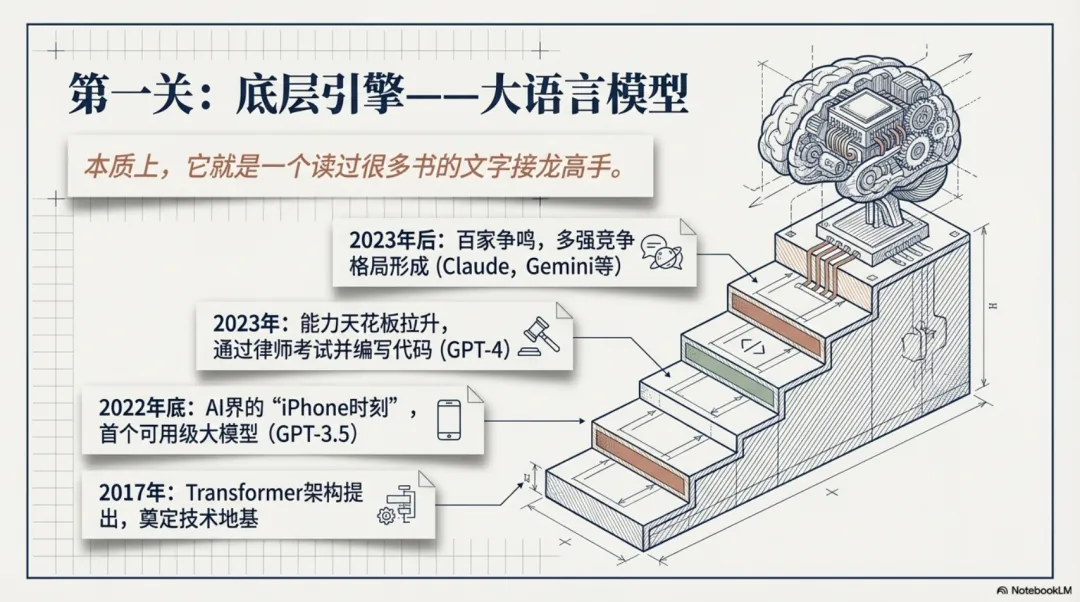
现在能做到:缓解但无法根除
很多人肯定会问,既然知道原因了,能不能把幻觉彻底消除?
行业里的结论很明确:现有技术条件下,AI幻觉不能完全避免,但可以缓解。
“AI会产生幻觉”这件事本身,业界早有预见,但是具体什么时候、针对哪个问题会出幻觉,谁也提前说不准。不过我们可以通过一系列综合手段,把幻觉发生的概率降下来。
具体怎么做?从技术层面,主要有这几个方向:
第一个方向是优化训练数据。把质量差、过时的错误数据清理出去,多加入高质量、时效性强的权威数据,从源头减少AI学到错误知识的可能。
第二个方向是优化训练方法。现在主流的做法,是用基于人类反馈的强化学习,让人类专家给AI的输出打分,告诉它什么是对的,什么是错的,引导它尽量输出准确内容。针对医疗、法律这些专业领域,还会用领域内的优质数据做专门微调,让AI更懂专业规则。
第三个方向是在应用阶段加工程化手段。这是目前最成熟也最有效的方案,常见操作包括这几种:
- 用检索增强生成技术,让AI回答问题之前,先去权威数据库里检索一遍相关内容,把“闭卷答题”改成“开卷答题”,从已有权威内容里组织答案,减少自己瞎编的概率。
- 多模型交叉验证,让不同的大模型针对同一个问题分别回答,让它们互相校验,不一致的内容就重点核查,把明显错误提前筛出去。
- 设置输出安全护栏,如果输出内容属于容易出幻觉的领域,自动触发交叉验证,要求AI标注信息来源,不确定的内容直接提示风险,不会直接放出来。
奇安信专家也提到,把这些手段组合起来,就能把AI幻觉的发生概率降到比较低的水平。
普通人能做的三个防护步骤
说了这么多技术层面的东西,对你来说,最重要的还是:我日常用AI的时候,怎么避开幻觉的坑?
我整理了三个非常实用的步骤,你只要照着做,就能挡住绝大部分AI幻觉带来的麻烦。
第一步,优化你的提问方式,从源头减少AI发挥空间。
很多人用AI提问太模糊,上来就一句“帮我写一份行业报告”,没有任何约束,AI当然只能自由发挥。你要反过来,给AI加上明确的限制:
- 要求它明确信息来源,比如加上一句“仅引用2025年公开的官方数据回答”;
- 明确告诉它规则,比如加上一句“不知道的内容直接说不知道,不要编造”;
- 把复杂大任务拆成小步骤,不要一次扔给AI几万字的内容,一步一步来,每一步核对清楚,比一次性出结果出错概率低得多。
这意味着什么?你给AI划好边界,它出错的空间就小了很多。
第二步,关键信息一定要做验证,不要偷懒。
如果AI输出的内容涉及法律、医疗、财务、学术这些关键领域,不管AI说得多笃定,你一定要自己去权威渠道核对一遍。这是最后一道防线,也是最管用的一道防线。
你还可以用一个小技巧:找两个不同的大模型,问同一个问题,如果两个模型给出的答案差别很大,那这个内容十有八九有问题,一定要重点核查。
第三步,永远保持清晰的认知边界。
你要记住,AI就是一个辅助工具,它不会主动分辨事实真伪,它只是帮你整理信息、提高效率。最终做判断、负责任的永远是你自己,不能把思考的权力完全交给AI。
说到底,AI会产生幻觉,不是技术的缺陷,而是当前技术路径的必然结果。我们不需要因为AI会胡说八道就拒绝它,也不能因为它好用就盲目信任它。
工具永远只是工具,拿捏好使用的度,守住自己的判断,才能真正用好AI这个帮手。
保持独立思考,才是对抗AI幻觉最好的解药。
我做这个公众号
不是为了炫耀什么,而是想记录,一个普通人的,如何在AI时代重新成长。
---
如果你也想知道
普通人怎么利用AI:做内容,做副业,提高效率,做短视频,做个人IP,做实体店宣传。
欢迎一起交流学习。
---
作者:梁誉锋|AI觉醒
一个普通人, 在AI时代重新成长。

微信:znn1491
