 夜雨聆风
夜雨聆风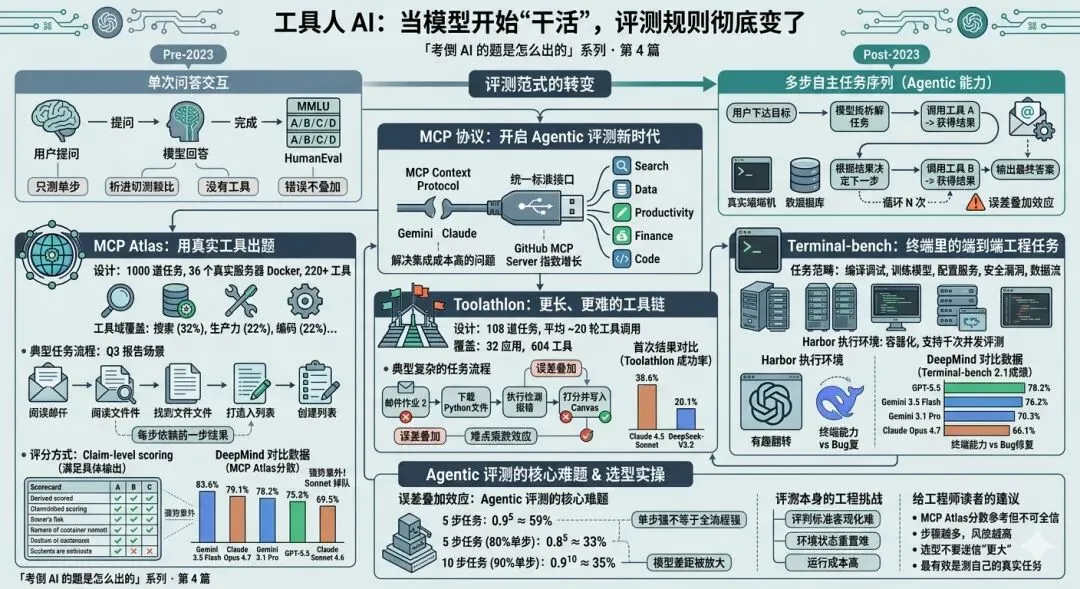
工具人 AI:当模型开始"干活",评测规则彻底变了
「考倒 AI 的题是怎么出的」系列 · 第 4 篇
两种不同的"聪明"
先做一个思想实验。
你雇了一个新员工,能力测评很优秀:记忆力强,逻辑清晰,专业知识扎实。
第一天,你让他回答一道选择题——他完美作答。
第二天,你让他独立完成一个任务:"帮我把上周的客户反馈邮件整理成报告,同时在日历上给相关负责人约好下周的对齐会议,然后把报告草稿上传到共享文档。"
这时候,你才真正知道他能不能干活。
大模型也是一样。过去几年,几乎所有主流评测测的都是第一种能力:给一个问题,模型给一个答案。MMLU 是,HumanEval 是,SWE-bench 也在某种程度上是。
但从 2023 年开始,一件新的事情发生了。
模型开始被要求完成第二种任务——不是回答一个问题,而是自主地执行一连串操作,调用外部工具,处理中间结果,直到完成一个真实的目标。
这就是"Agentic"能力。它需要一套全新的评测体系。
一个范式的转变
2023 年之前,语言模型的使用模式基本上是:用户提问 → 模型回答 → 完成。
这是一次性的问答交互。
2023 年之后,随着 GPT-4 的工具调用能力(Function Calling)成熟、各种 Agent 框架涌现、Anthropic 推出 MCP 协议,模型开始被用在一种完全不同的范式里:
用户下达目标
↓
模型拆解任务
↓
调用工具 A → 获得结果
↓
根据结果决定下一步
↓
调用工具 B → 获得结果
↓
... 循环 N 次 ...
↓
输出最终答案这个范式有一个根本性的不同:中间有环境反馈,有错误,有分支决策。
模型不再是坐在那里"想出"答案,而是在一个真实的(或模拟的)环境里"行动"——搜索、读文件、调 API、写代码并执行、处理报错、根据结果调整策略。
这就是为什么旧的评测全部失效了。你没办法用一道选择题来测"能不能在连续 20 步操作中保持目标不偏移"。
旧评测的三个根本缺陷
Agentic 场景下,传统 benchmark 暴露出三个无法修补的缺陷:
一、只测单步,不测序列。
MMLU 测的是"这道题答对了吗"。Agentic 任务测的是"这 20 步操作最终完成目标了吗"。前者只有一个评分节点,后者有一个完整的行动序列。两者的复杂度不在同一个维度。
二、没有工具,没有环境。
传统评测里,模型只需要产生文字。Agentic 任务里,模型需要调用真实的(或沙盒的)工具——搜索引擎、数据库、文件系统、日历、邮件……这些工具会返回真实的结果,有时候还会返回错误。模型必须能理解错误,并作出合理的应对。
三、错误不会叠加,但现实中会。
如果一个任务有 10 个步骤,每步成功率 90%,那么全流程成功率是 0.9¹⁰ ≈ 35%。这意味着即使每一步都"不算太差",完整任务的成功率也可能只有三分之一。这个"误差叠加效应"是 Agentic 任务特有的挑战,传统单步评测根本捕捉不到。
MCP 的出现:一个新的标准接口
要理解 Agentic 评测为什么在 2024-2025 年快速成熟,需要先理解 MCP。
MCP(Model Context Protocol)是 Anthropic 在 2024 年提出的一个开放标准协议,定义了"AI 模型应该如何调用外部工具"的统一接口格式。
在 MCP 出现之前,每个工具都有自己的调用方式:有的用 REST API,有的用 Function Calling,有的用自定义格式。模型厂商、工具厂商、Agent 框架各自为战,集成成本极高。
MCP 的价值类似于 USB 接口的统一——不管是什么工具、什么模型,只要都实现了 MCP 协议,就能"即插即用"。这个协议迅速被整个行业采纳,GitHub 上的 MCP Server 数量在 2024 年底到 2025 年初呈指数增长。
MCP 的普及带来了一个副产品:Agentic 评测有了统一的基础设施。既然所有工具都能通过 MCP 接口调用,那就可以用真实的 MCP Server 来出评测题——不再需要模拟或 Mock,直接上真实工具。
这就是 MCP Atlas 的诞生背景。
MCP Atlas:用真实工具出题
2025 年,Scale AI 发布了 MCP Atlas(正式名称 MCP-Atlas),这是第一个大规模使用真实 MCP 服务器进行评测的 benchmark。
MCP Atlas 的核心设计:
• 1000 道任务,全部由人工专家编写和验证 • 覆盖 36 个真实 MCP 服务器,共 220+ 个工具 • 5 大类工具域:搜索(32%)、数据分析(12%)、生产力工具(22%)、金融(12%)、编码(22%) • 真实服务器,锁定版本:所有服务器部署在 Docker 环境里,版本固定,保证可复现性
"真实服务器"这四个字是关键。之前很多工具调用评测用的是"模拟工具"——一个假装是搜索引擎的函数,一个假装是数据库的字典。模拟工具的问题在于,它们的数据格式太干净,错误太少,不能代表真实工具的行为复杂性。
MCP Atlas 强制使用真实的开源 MCP 实现。模型调用的是真实的文件系统、真实的代码执行环境、真实的数据库查询接口。真实工具意味着真实的不确定性:有时候查询返回空结果,有时候格式与预期不符,有时候需要多步操作才能获取想要的信息。
评分方式同样值得关注:MCP Atlas 使用"声明级别的评分"(claim-level scoring)——评判不是"任务完成了吗"这样粗粒度的对错,而是细到每一个预期的输出声明是否被满足。这让分数更能反映"完成了多少",而不只是"有没有完成"。
一道 MCP Atlas 任务是什么样的
来看一道典型任务,感受一下它和 HumanEval 的差距:
任务描述:
"从我的工作邮件里找到所有包含'Q3 报告'关键词的邮件,提取发件人列表,然后检查这些人中谁还没有在共享文档系统里提交 Q3 报告,把缺报告的人名整理成一个清单。"
完成这个任务需要:
1. 调用邮件搜索工具,按关键词过滤邮件 2. 解析搜索结果,提取所有发件人 3. 调用文档系统工具,查询 Q3 报告的提交记录 4. 对比两个列表,找出差集 5. 格式化输出结果
每一步都依赖上一步的结果。如果第 2 步解析出错,第 4 步的比对就会产生错误答案。如果第 3 步的查询参数不对,可能返回空结果,模型需要识别这个问题并重试。
这就是 Agentic 任务的复杂性:信息是分散的,步骤是有依赖的,错误是会传播的。
第一次测试:各模型的成绩
在图表(本系列第 0 篇里那张 DeepMind 的评测对比图)出现的 MCP Atlas 数据里,各模型分数如下:
| 83.6% | |
有几个值得注意的地方:
Gemini 3.5 Flash 的强势令人意外。在很多其他评测里,Flash 系列是"性价比版本",旗舰版 Gemini 3.1 Pro 应该更强才对。但在 MCP Atlas 上,Flash 版反而高出 Pro 版整整 5 个百分点。这说明工具调用能力不是简单地随着模型整体能力线性提升的——针对 Agentic 工作流的专项优化,可能比纯粹的参数规模更重要。
Claude Sonnet 4.6 的掉队值得关注。Sonnet 和 Opus 之间差了近 10 个百分点。考虑到 Sonnet 在很多其他评测上和 Opus 差距不大,这个 gap 说明 Agentic 工作流对模型的"规划和追踪能力"有特殊要求,而这个能力在更大的模型上有显著优势。
Toolathlon:更长、更难的工具链
如果说 MCP Atlas 测的是"能不能正确调用工具完成任务",Toolathlon 要求的是更长时间维度上的持续执行能力。
Toolathlon("Tool Decathlon",工具十项全能)由香港科技大学、CMU、Duke 大学等机构联合发布,2025 年 10 月公开。
它的设计理念很清晰:真实工作流里,一个任务不是 3-5 步,而是 20 步甚至更多。
Toolathlon 的规模:
• 108 道任务,全部人工编写或筛选 • 覆盖 32 个软件应用,604 种工具 • 工具域从 Google Calendar、Notion 这类日常应用,到 WooCommerce、Kubernetes、BigQuery 这类专业生产工具 • 平均每个任务需要约 20 轮工具调用才能完成
来看 Toolathlon 里的一道真实任务:
"检查你的邮件,找出所有作业 2 的提交。把 Python 文件从邮件附件下载到本地工作区,在终端里执行每个 Python 文件检查是否有错误。如果文件正确运行,在 Canvas 系统里给该学生打 10 分;否则打 0 分。学生如果提交了多次,使用最新的提交版本。学生 ID 信息在
student_canvas_ids.csv文件里。"
分解这个任务需要:
• 读邮件(按条件筛选) • 下载附件(多个文件) • 执行代码(并处理可能的报错) • 读 CSV 文件(比对学生 ID) • 写入 Canvas 系统(逐一打分)
而且顺序不能错,任何一个文件执行失败都需要正确处理,不能因为一个错误就中断整个流程。
Toolathlon 的首次评测结果:
最强模型 Claude 4.5 Sonnet 的成功率:38.6%
开源最强 DeepSeek-V3.2:20.1%
这两个数字都比 MCP Atlas 的成绩低得多,原因就是任务长度的乘数效应:20 步操作,即使每步成功率有 95%,全流程成功率也只有 0.95²⁰ ≈ 36%。
Terminal-bench:终端环境里的真实考验
MCP Atlas 和 Toolathlon 测的是"跨应用的多工具协调",Terminal-bench 测的是一个更具体的场景:在命令行终端环境里,端到端地完成工程任务。
Terminal-bench 由斯坦福大学和 Laude Institute 联合开发,2025 年 4 月发布,迅速成为前沿实验室的标准测试之一。
它的任务范围包括:
• 编译并调试复杂的代码项目 • 训练机器学习模型(包括处理环境依赖和配置) • 配置服务器和系统服务 • 处理安全漏洞 • 进行数据处理和分析流程
每个任务在 Docker 容器里执行,模型通过终端命令与环境交互,Oracle 解答用于最终验证。
Terminal-bench 2.0 在 2025 年 11 月升级,包含 89 个精选任务,同时发布了 Harbor 框架——一个专门为 Agent 评测设计的容器化执行环境,支持同时运行数千次评测。
来看 Terminal-bench 2.1 里记录的模型成绩(这正是本系列第 0 篇里图表中的数据):
| 78.2% | |
这里出现了另一个有趣的翻转:在 Terminal-bench 上,GPT-5.5 的优势比较明显,而 Claude Opus 4.7 反而不是最强的选手——虽然它在 SWE-bench Pro 上是顶尖水平。
这说明"终端操作能力"和"代码库级别的 Bug 修复能力"是两种不同的子能力,擅长一个不代表另一个也强。
误差叠加:Agentic 评测的核心难题
所有 Agentic 评测都面临一个共同的挑战,值得单独拿出来说:误差叠加。
设想一个 5 步任务,每步的成功率都是 90%:
• 5 步全对的概率:0.9⁵ ≈ 59% • 如果每步降到 80%:0.8⁵ ≈ 33% • 如果有 10 步,每步 90%:0.9¹⁰ ≈ 35%
这意味着:
1. 即使模型单步能力很强,长任务的成功率也会系统性地更低 2. 任务步骤越多,模型之间的成功率差距会被放大——一个单步 90% 和 80% 的两个模型,在 10 步任务上的差距会从 10% 放大到 20%+
这就是为什么 Toolathlon 的整体成功率比 MCP Atlas 低这么多——不是任务单步难度高出多少,而是步骤数量让误差自然叠加了。
从评测设计的角度,这带来一个两难困境:
• 任务太短:捕捉不到 Agentic 能力的真实挑战,容易被"单步能力强"的模型刷高分 • 任务太长:所有模型的成功率都很低,很难区分"哪里出了问题"
Toolathlon 用了 20 步平均长度,MCP Atlas 大约 5-10 步,这个差异直接导致了两者的分数分布不同。
评测本身的挑战:Agentic 评测比传统评测难得多
除了误差叠加,Agentic 评测还有几个传统评测没有的困难:
评判标准难以客观化。MMLU 的答案是 A、B、C、D,对就是对。Agentic 任务的结果可能是"在 Canvas 系统里给 20 个学生打了分"——怎么验证?用脚本对比数据库状态,可以做,但实现难度远高于字符串匹配。
环境状态难以重置。如果你在评测里真的操作了邮件系统和日历,评测结束后你需要清理这些副作用——不然下一次评测的环境就不是干净的初始状态了。这要求每个任务都有一套对应的环境初始化和清理脚本,工程量巨大。
成本不可忽视。一个 20 步的 Agentic 任务,可能消耗几十甚至上百次 API 调用。在 108 个任务上测试一个模型,总成本可能达到数百美元——更不用说 Toolathlon 的论文里提到他们总共跑了 3 万多次试验。
这些困难解释了为什么 Agentic 评测直到 2024-2025 年才开始成熟:它需要大量的工程基础设施,不是一个研究小组能轻松搭建的。
这对你意味着什么
如果你在用 AI 工具做自动化工程——无论是 Claude Code、Cursor Agent,还是自己搭的 MCP 工作流——理解 Agentic 评测能帮你更清楚地认识你所依赖的工具的真实局限。
几个实用的参考点:
看 MCP Atlas 分数,但别完全信它。MCP Atlas 的任务设计相对整洁,真实的生产工作流通常更混乱。83.6% 的 MCP Atlas 分数不等于在你的工作流里有同等的可靠性。
步骤越多,风险越高。如果你的 Agent 工作流超过 10 步,即使每步成功率很高,整体成功率也可能大幅下降。设计工作流时,尽量加入检查点和失败回滚机制。
工具调用能力因模型而异。Gemini 3.5 Flash 在 MCP Atlas 上超过了更大的 Gemini 3.1 Pro,这提示工具调用能力需要专门优化。在选型时,不要假设"更大的模型在 Agentic 场景下一定更好"。
你的工作流需要自己测。和 SWE-bench 的结论一样:最有效的评测是用你自己的真实任务。选 5-10 个最典型的 Agent 工作流,跑完整的端到端测试,看最终成功率——这比任何标准 benchmark 分数都更有参考价值。
下一篇预告
前四篇讲的都是"在有限范围内完成任务"的能力:一道知识题、一道数学题、一个代码文件、一组工具调用。
但现实中,AI 越来越多地被用来处理超长的文档——法律合同、技术报告、完整的代码库。这时候,模型还能保持注意力吗?
2023 年底,一个工程师做了一个简单实验,把一句话藏进了一百多万字的文本里,然后问模型"那句话在哪里"。结果令人不安——几乎所有模型都"忘记"了那句话。
下一篇:《大海捞针:把一句话藏进 100 万字里,AI 能找到吗》
如果你在搭建 AI 工作流或 Agent 系统,这篇文章对你有帮助的话,欢迎转发。
评论区话题:你在实际工作中跑过多步骤 Agent 任务吗?整体成功率大概在什么水平?
「考倒 AI 的题是怎么出的」持续更新,关注不迷路。
