 夜雨聆风
夜雨聆风随着智能体工具和框架生态系统的迅速扩张,开发者在构建 AI 系统时往往面临着选择困难症,如何在众多工具与模型中选择最适合自己应用的那一个?企业团队如何在成本、灵活性和风险间找到平衡?近日,来自 UIUC、斯坦福、哈佛等多所顶尖机构的研究者联合发布了一篇论文,提出统一的适应性分类框架,将Agentic AI的适配策略系统性地归纳为四种核心范式,并深入剖析了各类适配策略的优劣、应用场景及未来机遇。(文末附下载)

一、 两种适配维度:智能体 vs. 工具
Agentic AI系统虽然强大,但仍面临工具使用不可靠,比如AI生成的代码总是出错;长期规划能力有限,无法完成需要多步骤的任务;领域特定推理有缺口,在医疗、金融等专业领域表现不佳;在真实环境中鲁棒性差,遇到新情况就卡壳;对未接触过的环境泛化能力弱等诸多挑战。
这些挑战表明,即使是最强大的基础模型,也需要“适配”才能在特定场景中发挥最佳性能。该框架将整个智能体适配领域分为两大核心维度,核心区别在于优化的对象是智能体本身,还是它周围的环境与工具。
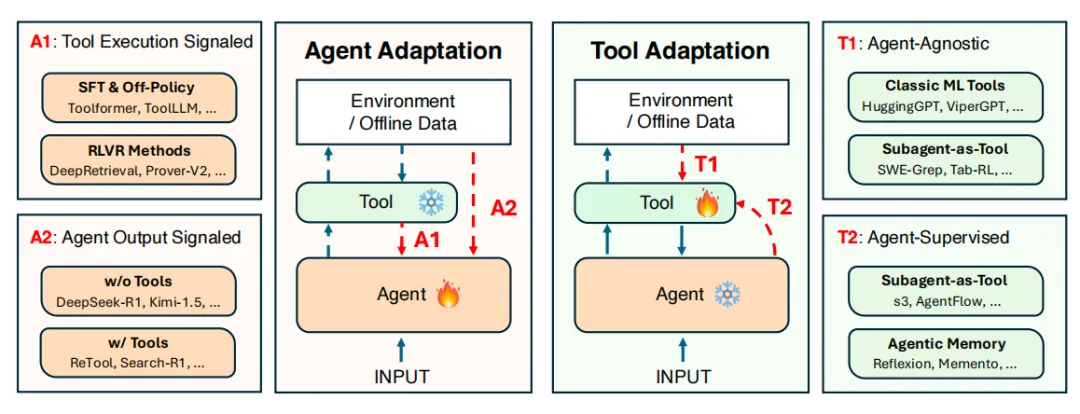
1. 智能体适配(Agent Adaptation)
该方法直接修改智能体的大脑,即其底层基础模型。通过微调、强化学习等方式更新模型的内部参数或行为策略,使其行为更好地与特定任务对齐。简单说,就是直接重塑智能体的认知和决策方式。
优点:灵活性最高,能从根本上改变智能体的能力。
缺点:计算成本极高,需训练数十亿参数的大模型,且可能导致“灾难性遗忘”,即学习新任务时忘记旧技能。
2. 工具适配(Tool Adaptation)
该方法将优化目标从昂贵的智能体转移到其外部工具生态系统上。智能体本身被“冻结”(不做任何改动),转而优化外部工具,比如搜索检索器、记忆模块、子智能体等。这种方式不用承担重训大模型的巨额成本,就能让系统持续进化。
优点:计算成本低,模块化程度高,易于系统演进。
缺点:工具的能力受限于固定智能体的理解与调用能力。
二、 四种核心适配策略
论文提出了 “二维四策略” 框架, 以适配对象(智能体/ 工具)和信号来源(工具执行 / 智能体输出 / 智能体无关 / 智能体监督)为区分元素,将适配策略划分为 A1、A2、T1、T2 四类,每类策略都有明确的适用场景和代表性方法。
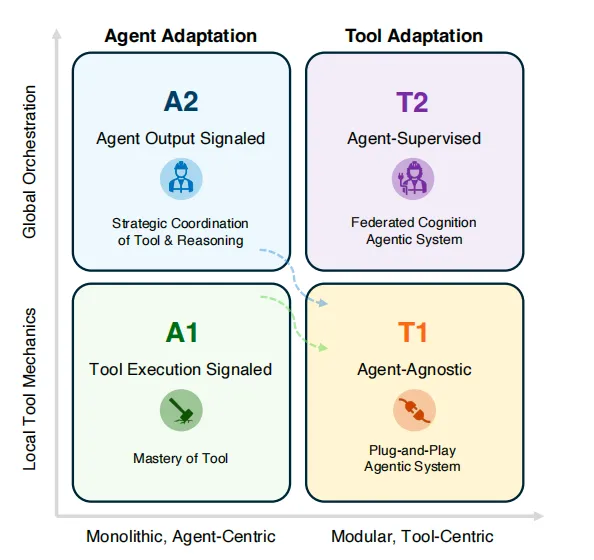
A1:基于工具执行信号的智能体适配
智能体在实践中学习,通过工具执行结果的直接反馈来学习。比如代码编译器是否运行成功、数据库检索结果是否准确,这种信号是客观、可验证的。这些客观反馈会指导智能体掌握工具的使用技巧。
典型案例:DeepSeek-R1 通过带可验证奖励的强化学习训练,生成的代码能在沙箱中成功执行。反馈信号很简单直接,代码要么运行正常,要么崩溃,这种方式能让智能体在编码、SQL 等稳定可验证的领域形成扎实的基础能力。
适用场景:需要精准掌握工具操作细节的任务,比如 API 调用、代码编写、数据查询等。
A2:基于智能体输出信号的智能体适配
不关注智能体中间用了多少工具、走了多少步骤,只根据最终输出结果的质量来优化。这种方式会倒逼智能体学会统筹规划,合理协调各类工具达成目标。评估信号可以是最终答案的正确性,也可以是人类的偏好评分。
典型案例:Search-R1 是一款多步骤检索问答智能体,只有最终答案正确时才会获得奖励。这让它在学习过程中不断优化搜索和推理策略,学会如何高效利用工具获取关键信息。
适用场景:复杂的多步骤工作流,比如深度调研、复杂问题拆解、多工具协同任务等。
T1:与智能体无关的工具适配
工具先在广泛数据上独立训练,之后像 “插件” 一样直接接入冻结的智能体。工具的设计不针对特定智能体,通用性强,即插即用。
典型案例:RAG 系统中常用的经典稠密检索器,先在通用搜索数据上训练完成,之后无论接入 GPT、Claude 还是其他大模型,都能正常提供信息检索服务,无需为特定模型单独调整。
适用场景:快速原型开发、通用场景应用,比如需要基础检索、格式转换等功能的普通任务。
T2:智能体监督下的工具适配
工具是量身定制的,以冻结智能体的输出为监督信号,专门优化工具来满足该智能体的需求,这样可以使工具高度专业化地服务于某个固定的主智能体,形成 “智能体主导、工具适配” 的共生关系。
典型案例:s3 框架训练了一个小型 “搜索器” 模型,它的奖励来自于冻结的大型 LLM(推理核心)能否用它检索到的文档正确回答问题。这让搜索器精准适配推理核心的知识缺口,提供最有用的信息。
适用场景:企业专有数据应用、高并发低成本需求场景,比如需要处理内部文档的智能客服、定制化数据分析工具等。
值得注意的是,复杂 AI 系统往往会混合使用多种策略。比如一个深度调研系统,可能会用 T1 的通用检索工具、T2 的自适应搜索代理,再搭配 A1 的专业推理代理,形成协同高效的架构。
三、 关键权衡:成本、泛化与模块化
对于企业决策者而言,选择哪种策略取决于对以下几个关键维度的权衡,这直接影响项目的投入产出比:
1. 成本与灵活性
A1/A2(智能体适配):灵活性拉满,能彻底改变智能体的行为模式,能实现深度定制,但成本极高。比如 A2 策略的 Search-R1 需要 17 万个训练样本,耗费大量计算资源和数据标注成本;不过推理时效率较高,模型体积比通用模型小。
T1/T2(工具适配):性价比突出,无需重训大模型,数据效率极高。比如 T2 的 s3 只用 2400 个训练样本(仅为 Search-R1 的 1/70)就达到了相近性能;但推理时需要协调核心模型和工具,存在一定的额外开销。
2. 泛化能力
A1/A2:存在过拟合风险。智能体可能在特定任务上表现极佳,但失去通用能力。比如 Search-R1 在训练任务中表现出色,却在专业医疗问答中仅达到 71.8% 的准确率。
T1/T2:泛化性更强,T1工具本身就在广泛数据上训练;T2工具则依赖冻结智能体已有的广泛世界知识。比如 s3 在同样的医疗问答任务中达到 76.6% 的准确率,既发挥了核心模型的通用优势,又通过工具弥补了专业领域缺口。但要注意,如果核心模型本身无法处理某类任务,工具再优化也难以奏效。
3. 模块化与系统演进
T1/T2:支持热插拔。可以独立升级检索器、记忆模块或规划器,而无需触动核心智能体。比如 Memento 系统优化记忆模块后,直接替换就能提升性能,不影响整体架构,维护成本低。
A1/A2:通常是单体式的。为学习新技能而微调智能体,可能导致灾难性遗忘,损害已有能力。系统的任何更新都需要重新训练整个大模型,演进成本高。比如训练智能体编写代码后,它可能在之前擅长的数学推理任务上表现下滑,因为内部参数被覆盖,可维护性较差。
四、 企业应用路线图:从简单到复杂
结合实际应用场景,开发者和企业可遵循 “循序渐进” 的策略选择阶梯,平衡风险与效果:
第一步:从 T1 开始(低风险快速落地)
先用冻结的强大模型(如 Gemini、Claude)搭配现成的工具,比如 RAG 检索器、MCP 连接器等。无需任何训练,就能快速搭建起可用的系统,适合原型验证和通用场景,是投入少、见效快的方式。
第二步:升级到 T2(精准适配核心需求)
如果通用工具无法满足需求,比如检索结果不贴合核心模型的推理习惯,不要急于重新训练大模型,可以训练一个轻量的专用子智能体(如定制化搜索器、记忆管理器)。这种方式数据效率高,适合处理企业企业私有数据和高频、成本敏感的应用,是高性价比的优化方向。
第三步:用 A1 做专业化补强(解决技术痛点)
如果智能体在技术类任务上存在根本性缺陷,比如写不出能运行的代码、调用 API 频繁出错,就需要用 A1 策略优化它对工具的理解。适合打造特定领域专家,比如专注于 SQL 查询、Python 编程或企业内部工具操作的专用智能体。训练出的专家模型随后可作为T1工具供其他系统使用。
第四步:A2 作为终极选项(谨慎使用)
仅当应用场景极度复杂,需要智能体深度内化一套复杂的跨工具策略和自校正能力时,才考虑投入资源进行端到端的A2训练。这种方式资源消耗巨大,对于绝大多数企业应用来说并非必需,通常只在需要构建高度自主的复杂系统时才会采用。
五、小结
随着 AI 技术的成熟,行业焦点正从打造单一完美模型转向构建智能工具生态,以稳定的核心模型为基础,搭配各类灵活适配的专用工具,形成协同高效的智能体系统。
对于大多数企业和开发者而言,通往实用型智能体的最优路径,不是追求更大的 “大脑”,而是给大脑配备更称手的 “工具”。通过合理组合 T1、T2、A1、A2 四大策略,既能控制成本和风险,又能实现精准适配,让智能体真正服务于实际业务需求。
究模智后台对话框回复1230智能体即可下载!
