 夜雨聆风
夜雨聆风本文导读
Part 1 讲 Runtime 内核——回答一个最基础的问题:Claude Code 到底是什么形态的系统? Part 2 讲 Tool 协议——为什么 Claude Code 把工具设计成「协议对象」而非「函数映射」? Part 3 讲输入侧与状态连续性——Prompt、Context、Memory、Session 这一串是怎么撑住长任务的? Part 4 讲安全与拓展——Permission、Sandbox、MCP、Skills 怎么协同工作? Part 5 讲多 Agent 架构——Sub-Agent、Coordinator、Swarm 三层如何分工? Part 6 做工程收束——从源码中能抽出哪些可迁移的设计原则?
引言:Claude Code 是什么?
Claude Code 是一个本地的 Agent Runtime(Agent 运行时)。这句话拆开来看:
Agent(智能体):能自主感知环境、做决策、执行动作的 AI 程序——不只是聊天,而是会主动调用工具、读写文件、执行命令。 Runtime(运行时):负责承载 Agent 决策-执行循环的那一整套工程底座,包括上下文管理、工具调度、安全边界、状态恢复等。
表面上它以 CLI(命令行界面)作为入口,但 CLI 只是「门面」。真正干活的是背后一整套完整的 Agent 执行链——CLI 负责收发对话,Runtime 负责治理 Agent 的每一次行动。
业界定位上,Claude Code 属于 Harness Engineering(脚手架工程)的范畴。这是一个从 Prompt Engineering → Context Engineering 逐步演化而来的新范式:
Prompt Engineering 关心「怎么写一个好提示词」;
Context Engineering 关心「怎么组织和管理上下文」;
Harness Engineering 更进一步——它不再只优化输入,而是构建一整套运行时体系,去承接、治理、恢复模型的自主行动。
Claude Code 的 Harness 工程要解决两个核心命题:安全可靠地执行,以及在有限上下文窗口的约束下最优地完成复杂长任务。
下面用六章来展开这套架构的每个关键组件。
Part 1:Runtime 内核 —— 它到底是什么形态的系统?
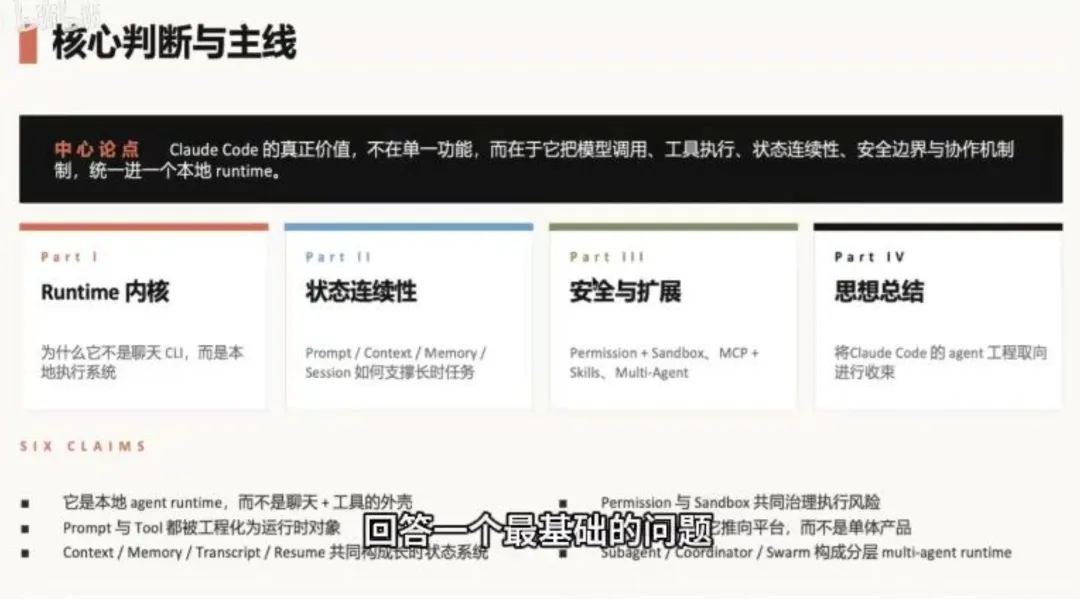
1.1 程序入口链:在用户看到界面之前发生了什么
Claude Code 的启动并非「打开聊天框就开始对话」。在你看到任何 UI 之前,程序已经跑完了一长串初始化流程:
1 2 3 4 5
CLI (cli.tsx)→ main.tsx (主流程调度)→ init + setup (安全初始化:确认目录可信、加载用户配置)→ launch REPL (基于 Ink + React 拉起终端 UI)→ query 函数 (核心执行循环)
什么是 REPL?它是 Read-Eval-Print Loop 的缩写——「读取输入 → 执行 → 打印结果 → 回到读取」这个循环。Claude Code 的 REPL 是用 Ink(一个用 React 写终端界面的框架)渲染的,但核心不在渲染,在 query 函数里。
在 main.tsx 中,程序根据启动参数分叉出不同运行形态:
--print | ||
--headless | ||
--acp | ||
--remote | ||
关键结论:不管哪种运行形态(REPL、headless、SDK、bridge、remote、subagent),底层都共用同一条 query 执行内核,不存在两套实现。后面讲到多 Agent 时你会看到,主 Agent 派出的子 Agent 跑的就是这个同一内核——只是上下文做了隔离。
💡 一句话:Claude Code 是一套「多种入口形态 + 单一时执行内核」的架构。
1.2 Query 循环:所有 Agent 的共同基因
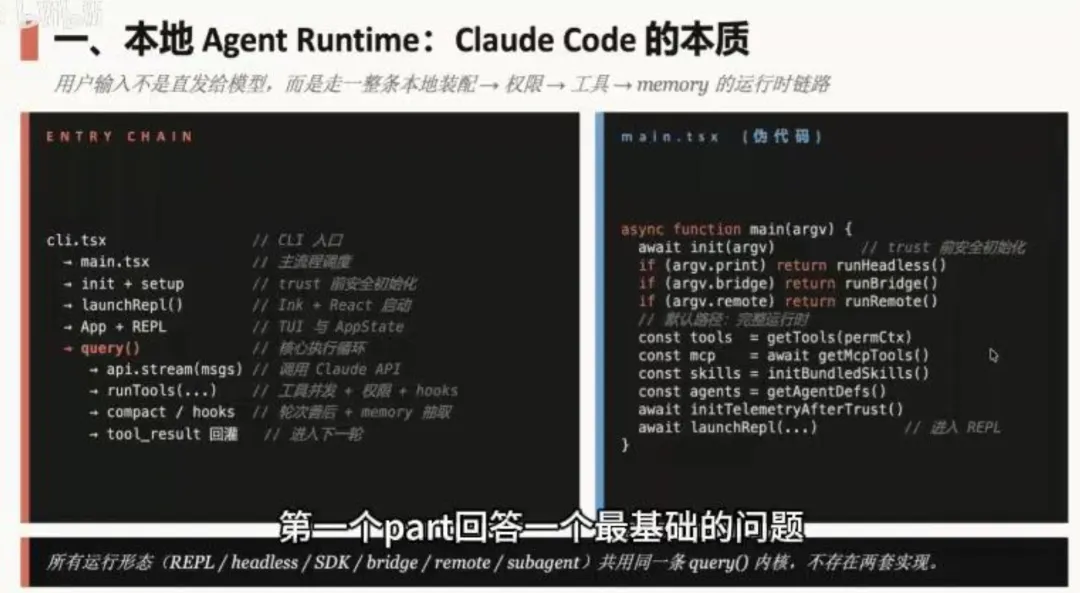
所有 AI Agent 的底层形态都可以归结为一个 while 循环——反复调用大模型,模型每轮决定「继续用工具干活」还是「停下来交结果」:
1 2 3
start → API Call → 判断 stop_reason├─tool_use→执行工具→把结果追加回对话→回到API Call└─end_turn→ 退出循环
可以把它想象成一条流水线:模型是「决策工位」,每次产出两种可能——要么说「我要用这个工具」然后等待结果,要么说「我做完了」。Claude Code 把这条流水线拆成了六个标准化工位:
Pre-API Phase(上下文装配):把 attachment、skill、memory 等上下文拼装好,喂给模型 API Request Phase(API 请求):流式调用 API,处理网络重试 Process Response(响应解析):把模型的输出翻译成 transition状态字Execute Tools(工具执行):按并发性分批执行工具,串入权限检查和 hooks Stop Hooks(轮次收尾):每一轮结束后做钩子检查 Should Exit(退出判定):判断是否收工;否则 turn_count + 1,回到第 1 步
什么是流式调度?整条循环的底层做成了流式——模型还在逐字输出时,界面就已经开始显示,下游也同步消化内容并准备执行工具,不用等整段输出结束。这就是为什么 Claude Code 跑起来感觉「丝滑」——流式调度在每一层都给模型抢时间。
Transition 状态字:第 3 步将模型输出解析为一个状态机语义字,决定下一轮走哪条路径:
continue | |
tool_use | |
end_turn | |
stop_sequence | |
max_tokens | |
error_recovery | |
budget_exceeded | |
abort |
💡 一句话:Agent = while 循环 + 六阶段流水线 + 状态机驱动。这是整个 Runtime 的心跳。
1.3 七级错误恢复级联:长任务不死的「急救梯」
Agent 跑长任务时会遇到各种「猝死」风险:网络断了、上下文塞满了、输出截断了、token 预算烧完了。Claude Code 把这些失败按严重程度从轻到重排成七级,每一级都有对症的恢复策略——类似医院的分级诊疗:
| L1 | |||
| L2 | |||
| L3 | |||
| L4 | |||
| L5 | |||
| L6 | |||
| L7 |
这套梯子的核心价值:它把长任务可能「死」的所有方式都铺成了可恢复的路径。这是 Claude Code 能跑半小时、一小时甚至更长复杂长任务的基础设施。
💡 一句话:不是不出错,而是出错后知道怎么爬起来。

Part 2:Tool 协议 —— 工具不是函数,是受治理的资源
在大多数 Agent 框架中,Tool(工具)就是一个函数,再加一段 description(描述)——模型说「调用它」,框架就调。但 Claude Code 把 Tool 从「可调用的能力」升级成了协议对象(Protocol Object)。
这并非术语上的咬文嚼字,而是架构立场的根本分歧:
前者把 Tool 视为「可调用的能力」→ 只关心能不能跑;
后者把 Tool 视为「需治理的资源」→ 同时关心能不能跑、安不安全、能不能并发、谁监管。

2.1 Tool 的「双面性」:功能面 + 安全面
每个 Tool 需要声明两类属性,缺一不可:
功能面(决定「能做什么」):
name | |
description | |
input_schema | |
call |
安全面(决定「能不能放心让它做」):
is_read_only | |
is_concurrent_safe | |
permission_check |
这四个功能属性 + 三个安全属性 = 一个 Tool 的完整定义。关键在于:每个工具作者在定义新工具时,被强制要求把这些安全属性表达清楚。这些属性直接决定:
这个工具能不能和其他工具同时跑(并发性) 能不能修改文件(读写性) 需不需要弹窗确认(权限等级) 在 UI 上如何渲染(呈现方式)
💡 一句话:安全不是一个「后续再考虑」的附加项,而是定义 Tool 时必须回答的第一性问题。
2.2 Fail-Closed 哲学:「默认不优化,先保证可控」
Claude Code 的默认配置体现了一个清晰的设计立场:
is_concurrent_safe | false | |
is_read_only | false | |
表面上看,「权限默认放行」似乎和「安全优先」矛盾。但结合并发性看,逻辑就完整了:
未声明并发安全 → 进入串行执行通道(一次只跑一个) 未声明只读 → 进入权限检查通道(每次都要用户确认)
新工具默认走的是「串行执行 + 权限检查」的保守路径,绕不开治理。
这是典型的 Fail-Closed(故障关闭)立场,类比电路设计中的保险丝:默认断电,只有显式确认安全才接通。只有当你主动声明「我是只读的」「我可以并发跑」,系统才给你升级到快路径——让你并发执行、免弹窗。
💡 一句话:默认状态下最安全、最慢、最可控;性能是「挣来的」,不是「给来的」。
2.3 执行管线:每一步都可以喊停
从模型输出「我要用工具」到工具真正执行完毕,经过的完整链路不是一步直通,而是一条层层设卡的管线:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
模型输出 assistant message(含一个或多个 tool_use block)↓query.ts 收集 tool_use↓Tool Orchestration(按并发性分批)↓Tool Execution(逐个执行)├── Schema 校验 ← 参数格式先过一遍├── ValidateInput ← 输入合法性再查一遍---- pre-tool hooks ← 执行前钩子:可以在这里拦截├──ToolHooks← 工具钩子:改写、补充上下文└── Permission ← 权限确认:用户可以拒绝↓Tool Core(实际调用,真正干活)↓规范化为 tool_result message↓进入下一轮 API 调用
这条链的关键不在于它有多少层,而在于每一层都有显式的治理点——可以在工具执行前拒绝、改写、补充上下文:
Hooks:可以在工具执行前直接拦截。「你别调这个,我给你个缓存结果」 Permission:可以让用户确认,也可以直接拒绝。「这个操作你要确认吗?」
模型不是想调就调。每一步都可以喊停。这就是「治理写进管线」的含义。
2.4 并发调度策略:能一起跑的就别排队
模型一轮可能同时输出多个 tool_use block(比如同时想读 5 个文件)。Claude Code 的调度逻辑是:
标记了 is_concurrent_safe: true的工具 → 并发执行(同一批一起跑)未标记或标记为 false的工具 → 退化为串行,独占执行(等它跑完再跑下一个)
一个具体例子——假设模型一次输出了 7 个 tool_use:
| 独占串行 | |||
| 单独串行 |
安全的 P1 起跑,不安全的退化成单条。这就是 is_concurrent_safe 分批的逻辑——性能和安全不是二选一,是用声明式属性让系统自动决策。
2.5 Streaming Tool Executor:一边收指令一边跑
更细一层是 Streaming Tool Executor(流式工具执行器)。它用四个状态追踪每个 Tool 的生命周期:
queued | |
executing | |
completed | |
yielded |
关键点:它边接收 tool_use 边启动执行,不需要等模型把整个输出吐完。模型刚输出「读 A 文件」的指令,执行器已经在读 A 文件了——与此同时模型还在继续生成后面的思考。这就是 Claude Code 跑起来快的原因:流式调度在给模型抢时间。

2.6 Tool 设计小结
Claude Code 的 Tool 设计可以归纳为三条原则:
Tool 是协议对象,不是函数映射。同一份定义同时服务于模型调用、权限判断、并发调度、UI 呈现与结果回流。 治理写进协议,而非外包给管理层。安全与并发是工具作者的设计责任,不是事后打补丁。 Fail-Closed 默认,显式声明才升级。默认串行、默认需权限、默认可控——只有主动声明安全属性,才获得性能与体验上的升级。
Part 3:输入侧与状态连续性 —— 长任务的记忆系统
3.1 System Prompt 的三层架构
在聊具体机制之前,先理解一个基础概念:LLM 的每一次 API 调用都是「无状态」的——模型本身不记得上一轮说了什么。所谓的「对话记忆」全靠每次请求时把历史消息重新塞进去。所以上下文窗口(Context Window)就是模型一次能看到的最大信息量——它是一个有限资源,必须精心管理。
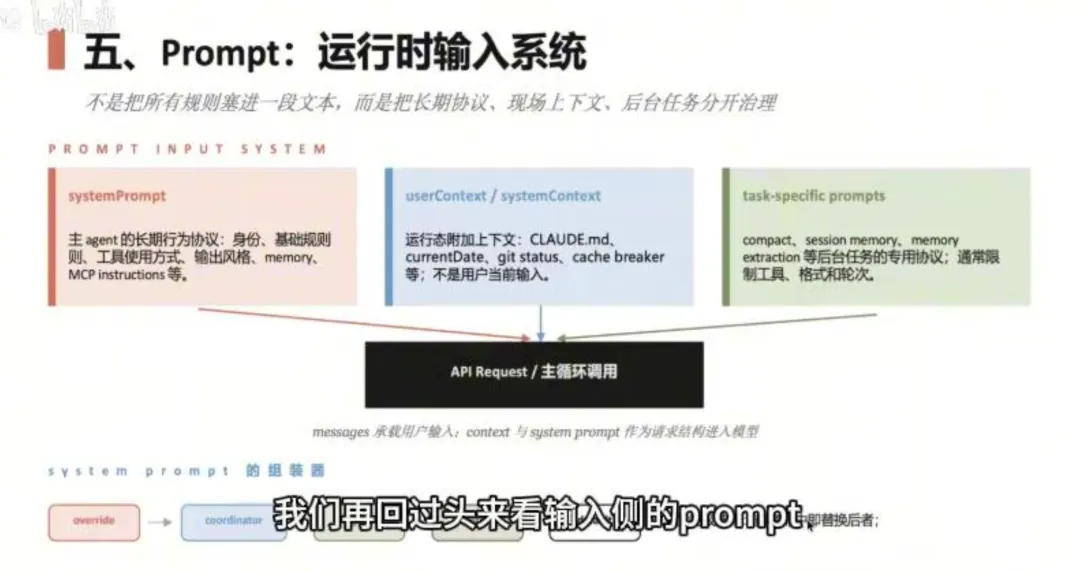
Claude Code 把给模型的输入分成三类来源:
System Prompts(长期行为协议):身份定义、基础规则、工具使用方式、输出风格、记忆——几乎不变,相当于模型的「职业守则」 User/System Context(运行态上下文):CLAUDE.md 配置、当前日期、git 状态等——Runtime 自己塞入的现场信息,相当于「当班交底」 Task-Specific Prompts(后台任务专用协议):compact(压缩)、session memory 等场景——各有自己的工具白名单、格式约束和轮次限制
优先级链(五档,从左到右逐级回退):
1
override > coordinator > agent > custom > defaultoverride | ||
coordinator | ||
agent | ||
custom | ||
default |
这条链解释了为什么 coordinator 模式或 sub-agent 能「换一个身份运行」——替换的是 system prompt 这个槽位,不是模型变了,是模型看到的「自己是谁」变了。
💡 一句话:System Prompt 不是写死的一篇文档,而是一个有优先级、可插拔的身份系统。

3.2 Prompt Cache:稳定在前,动态在后
prompt 拼接完成后,Claude Code 把它切成上下两段:
上半段(静态主干):身份规则、任务规则、工具使用方式、语气——几乎不变,放最前面 下半段(动态边界):长期记忆、环境信息、语言偏好、输出风格——每次会变,放后面
这样排是因为 API 服务端的 Prompt Cache 是按前缀匹配的。前缀(上半段)越稳定越长,重复请求时 Cache 命中率越高,token 计费越便宜。
两层一起治理,才能把长期运营成本压下来。
💡 一句话:排 prompt 的顺序不是随便排的——把不变的内容放前面,就是在省钱。
3.3 上下文压缩:五级梯子策略
长任务中,每一轮工具执行的输出都会被追加回对话历史,token 窗口很快就会塞满。Claude Code 的应对是五级压缩策略,且在每轮 API 请求开始前都会做一次上下文治理,按梯子顺序依次尝试:
| Snip | |||
| Micro Compact | |||
| Context Cliff Summary | |||
| Auto Compact | |||
| Session Memory Compact |

两条关键原则:
轻量优先:如果前面的策略已经把占用降到阈值以下,就不进入更重的 auto compact(就像先拿扫帚扫一扫,别上来就请保洁公司) 压缩不是截断:完整 compact 不是删历史,而是用 summary + post-compact attachment 重建工作台——工具声明、文件上下文、计划状态都得塞回去,否则模型会忘了自己干到哪一步
💡 一句话:不是「内存满了就删」,而是「能轻量处理就不大动干戈,大动时保证不丢状态」。
3.4 Memory 系统:按需召回,而非全量注入
长期记忆有一个核心矛盾:记太多,塞进 prompt 会撑爆上下文窗口;记太少,模型没有足够的背景信息做决策。Claude Code 的解法是「按需召回」(Relevant Recall)——存的时候全部存,但注入 prompt 时只挑最相关的。
Claude Code 把长期状态拆成三种类型:
| Auto Memory | |||
| Session Memory | |||
| Memory Agent |
补充层还有 Team Memory 做团队间同步。
Relevant Recall 的四步流程:
扫描每个记忆文件的头部元数据 生成记忆清单 让轻量模型从中选出最多 5 条最相关的 只把这 5 条的正文代入本轮请求
Claude Code 自己维护的 memory.md 不是正文仓库,而是入口索引——每条记忆只记一个链接加一行描述,整个文件限制在 200 行、25KB 以内。
💡 一句话:记忆不是洪水猛灌,而是一个图书馆——平时安静归档,用时精准取阅。

3.5 Transcript & Resume:关掉再打开,能从断点继续跑
你把 Claude Code 关掉,第二天重新打开还能从中断位置继续跑——这靠的是 Transcript + Resume 这套机制。
Transcript(会话转录)不是一个聊天记录数组,而是一个 append-only 事件流日志(只追加,不修改):
每个事件有一个唯一 UUID,并指向它的上一条 parent_UUID所有事件靠这两个字段串成一条链 只有四类事件能进入 transcript:用户输入、模型输出、附加内容、系统消息(工具执行的中间进度不进主链) 写盘策略:append-only + 批量 flush——先进内存队列,后台批量刷盘,不拖慢主循环 尾部元数据:标题、标签、模式、worktree 等周期性重挂到文件末尾(因为 resume 列表页只扫文件尾部一小段窗口)
Resume(恢复)的四步重建管线:
加载日志:读取 JSONL 文件,按事件类型分类 重建主链:以最新消息为叶子节点,沿 parent_UUID 向前回溯 修复断点:处理链断开的情况——早期版本残留的桥接信息、snip 后的空洞重新挂载到活着的祖先节点 恢复运行态:计划状态、文件读取历史、context cliff 状态、Agent 模式全部挂回内存,最终交还控制权给 REPL
💡 一句话:Transcript 是「存档」,Resume 是「读档」——但比游戏存档更复杂之处在于,它连 AI 的上下文、计划状态、工具历史全都要无损恢复。

Part 4:安全与拓展 —— Sandbox、Permission、MCP、Skills
4.1 Sandbox 管线:四步执行链
每一条 bash 命令落到宿主机执行之前,要经过四道关卡:
1
逐条路由 → 配置翻译 → 隔离运行 → 收尾清理Sandbox 与 Permission 的关系是互补,不是替代:
Permission 回答「这条命令能不能执行」(能不能的问题) Sandbox 回答「已允许的命令能走多远」(范围的问题)
此外,Sandbox 还保护控制平面——各类 settings 文件、.claude 目录、skill 目录全部列入禁止写入范围,防止被恶意命令拿去修改 Agent 自己的配置。
💡 一句话:Permission 是门禁,Sandbox 是活动半径——两个加起来才是完整的安全边界。
4.2 Bash Tool 前置检查
在进入 Sandbox 之前,bash tool 自己还有一层前置检查:
命令语法和危险模式识别(比如 rm -rf /这种直接拦截)基于规则的 permission 判断 只读命令的识别和分流(只读命令可以绕过部分限制)

4.3 MCP:外部工具入池,走同一治理链路
MCP(Model Context Protocol,模型上下文协议)是 Anthropic 推出的一个开放协议标准——它定义了外部工具服务器如何被 AI 模型发现和调用。可以把它理解成「工具和模型之间的 USB 接口标准」:只要实现了 MCP,任何外部工具都可以被 Claude Code 识别和使用。
Claude Code 对 MCP 的处理方式是:
MCP Server 上的工具被标准化为内置 tool 对象 然后进入工具池和执行链,不走旁路 一样要经过 Schema 校验、Permission 检查、call → result 回流这一整套流程
Tool Search 延迟加载:当装了太多 MCP 工具时,不会把所有工具描述一次性灌进 prompt,而是先暴露一个轻量的发现入口,模型按需要展开具体工具的边界说明。这降低了 prompt 体积,提高了 Cache 命中率。
💡 一句话:MCP 解决的是「怎么接入外部工具」,但接入之后受的治理和内置工具一模一样——没有特权通道。
4.4 Skills:任务协议注入,按需激活
Skill 不是 tool,它是一个可复用的 prompt package(提示词包)——本质上是 Markdown + 元数据 + 可选的执行脚本:
Frontmatter(文件头元数据)声明:名称、描述、可用工具、触发条件等 Body(正文):任务方法、上下文、约束规则 调用时把这些拼成一个任务上下文,注入给模型
三条激活入口(全部按需,不常驻):
path 字段 | .py 文件 → 自动激活 Python skill) |
目标一致:避免一堆备用技能把上下文窗口撑爆。

💡 一句话:MCP 接入外部工具能力,Skills 注入任务方法知识——两个都是入口,但执行时都走同一条治理链路。
Part 5:多 Agent 架构 —— 上下文隔离下的任务分工
Claude Code 的多 Agent 体系分三层,但目的只有一个:在有限上下文约束下实现有效的任务分工。
为什么需要多 Agent?因为单个 Agent 的上下文窗口有限——如果让一个 Agent 同时做搜索、分析、编码、测试,历史消息会很快把窗口撑爆。多 Agent = 把大任务拆成小任务,每个 Agent 在干净的上下文里各干一个。
5.1 Sub-Agent:上下文隔离
子 Agent 拿到的不是父 Agent 的全部历史,而是一份全新的 message 数组,里面只包含 task prompt(任务描述)。它在自己的上下文里独立完成工具调用和结果回收,干完后返回的不是自己的完整上下文,而是一条摘要。子上下文随即被丢弃。
这就是 Sub-Agent 的工程价值:用一份干净的子上下文做隔离,防止主链被工具产物撑爆。好比主厨派了帮厨去隔壁厨房单独做一道菜——帮厨在隔壁折腾得满锅满灶,但主厨的工作台保持整洁。
5.2 Coordinator:任务编排
Coordinator 不是「把 Sub-Agent 多开几个」,而是把主 Agent 的 system prompt 换成 Coordinator 身份,让它负责派工、综合、续写多个 worker 的结果。典型流程包括 research 并行、implementation 分派等。
这一层解决的是任务编排问题——「谁干什么、顺序是什么、结果怎么汇总」。
5.3 Swarm:Mailbox + Task Board
Swarm 模式通过 team create 显式创建团队、声明角色。每个 teammate 脚下挂着一个独立的 JSONL 文件作为 inbox(信箱):
通信:Leader 给 Coder 派任务时不直接调用,而是把消息写进对方的 inbox 文件。每个 teammate 在 LLM 调用前先 poll(轮询)自己的 inbox,把新消息作为上下文注入。 自主认领:Teammate 在 idle(空闲)超时后,自己去 task board 上扫未认领的任务,先 claim(把名字写入 owner 字段),再进入 work 状态,干完回到 idle。
权限回流:当 teammate 想用敏感工具时,权限请求统一发到 Leader 那里确认——安全决策权不下放。
Agent 委派的统一入口:Agent tool 是暴露给模型发起 Agent 委派的工具——同一个 tool,通过不同参数决定走普通的 Sub-Agent、Coordinator 派出的 worker,或 Swarm 里的 teammate。入口分了层,但底层执行仍然回到同一个 Runtime、同一条 query 执行链。

💡 一句话:多 Agent 不是一套新系统,而是在同一套 Runtime 上叠了三层协作模式——隔离(Sub-Agent)、编排(Coordinator)、自治(Swarm)。
Part 6:设计原则总结 —— 从源码中能带走什么
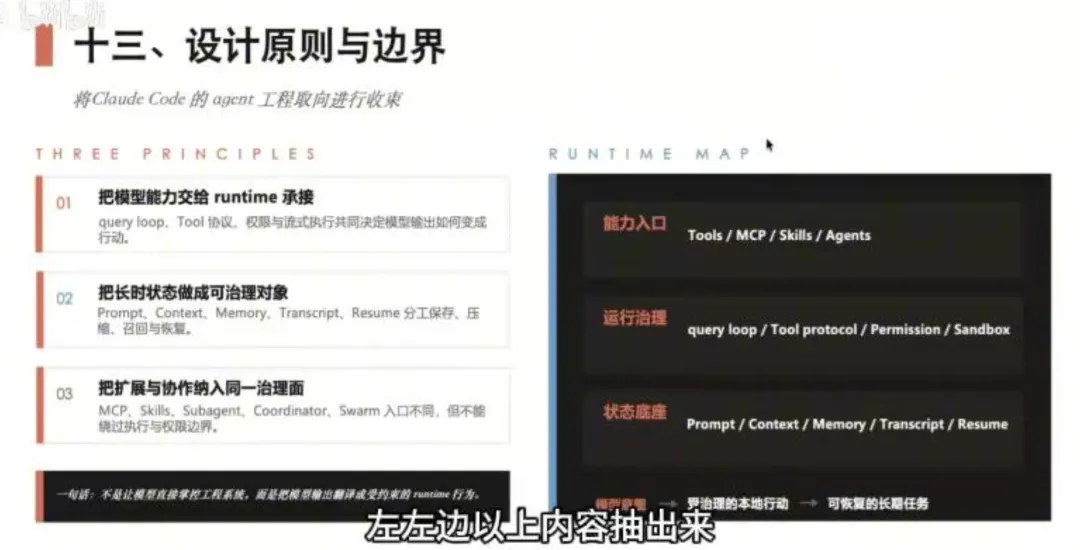
从整套架构中可以抽出三条可迁移的设计原则:
原则一:把模型能力交给 Runtime 承接
模型输出本身只是一段文字。这段文字怎么变成真实的工程行动,是 Runtime 层的 query loop、tool 协议、permission、流式执行共同决定的。
模型不是总指挥,Runtime 才是。 模型负责「意图」,Runtime 负责「执行、监管、恢复」。
原则二:把长期状态做成可治理的对象
Prompt、Context、Memory、Transcript、Resume——每一个维度都有明确的「怎么保存、怎么压缩、怎么召回、怎么恢复」的分工。不是事后补丁,而是原生设计。
一个系统能跑多久,不取决于模型多聪明,而取决于它的状态管理多扎实。
原则三:把拓展与协作纳入同一治理体系
MCP、Skills、Sub-Agent、Coordinator、Swarm——入口形态各不相同,但进来之后都不能绕过权限边界、执行治理和上下文预算。
多元入口,一套约束。 开放扩展,但不开放特权。
Runtime Map(自底向上三层)
1 2 3
能力入口层 Tools / MCP / Skills / Agent运行治理层 Query Loop → Tool Protocol → Permission → Sandbox → 流式调度状态底座层 Prompt / Context / Memory / Transcript / Resume
一句话概括整套架构:
模型意图 → 变成受治理的本地行动 → 再变成可恢复的长期任务。
结语:围绕有限上下文的 Harness Engineering
Claude Code 不只是一个 AI 模型或一个聊天工具。它是包在语言模型 API 上的一整套 Harness 工程,解决的核心命题是:
在有限上下文窗口的硬约束下,如何让模型安全、可靠、可恢复地完成复杂长任务。
每一层设计——从 query 循环到 tool 协议,从五级压缩到三级记忆,从 Sandbox 到多 Agent——都是在为这个命题交答卷。如果你也在做 Agent 相关的工程,这三条原则值得带走:Runtime 承接、状态可治、治理统一。
