 夜雨聆风
夜雨聆风今天看了一个开源项目,叫 OpenDataLoader PDF。
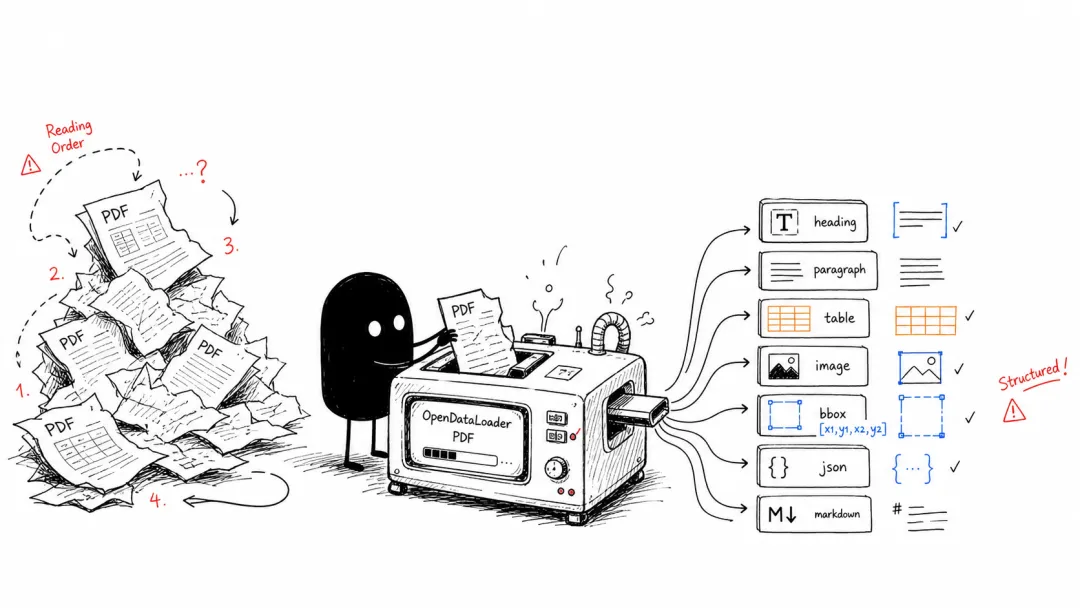
它做的事情很直接:
把 PDF 解析成 AI 更容易处理的结构化数据。
听起来像普通的 PDF 转 Markdown。
但我看完之后发现,它真正解决的是三个更麻烦的问题。
第一,PDF 的阅读顺序经常是乱的。
人看页面知道先读标题、正文、表格。
一旦顺序错了,丢给 AI 做总结、问答、RAG 检索,结果就会很奇怪。
OpenDataLoader PDF 会做版面分析,识别标题、段落、表格、图片,还会给每个元素保留坐标。
它输出的不只是文字,还有结构。
第二,表格、扫描件、公式、图表这些内容很难解析。
很多 PDF 工具遇到复杂表格就散架。
这个项目提供两种模式:
普通 PDF 可以走本地快速模式。
复杂页面可以走 hybrid 模式,用 AI 后端处理 OCR、复杂表格、公式和图表描述。
简单页面追求速度,复杂页面追求准确。
第三,它还在做 PDF 无障碍。
这个点很少有人关注。
很多 PDF 对屏幕阅读器并不友好,因为没有正确的标签结构。
OpenDataLoader PDF 可以把未标记 PDF 自动生成 Tagged PDF。
这对政府、教育、企业文档很重要。PDF 不只是给人眼看的,也应该能被辅助工具读取。
从工程上看,这个项目也不是玩具。
它有 Java 核心,外面包了 Python、Node.js、Java SDK,还提供 CLI 和 MCP。
输出格式包括 Markdown、JSON、HTML、Tagged PDF。
JSON 里会保留元素类型、页码、坐标、字体、内容。
这对做知识库很有用。你不仅知道 AI 引用了哪段话,还能定位它来自 PDF 的哪个位置。
我觉得这个项目最值得关注的地方是:
它没有把 PDF 当成“一坨文字”。
它把 PDF 当成一个有版面、有顺序、有语义的文档。
这才是 AI 时代真正需要的解析方式。
如果你在做 RAG、企业知识库、论文解析、合同分析,这类工具会越来越重要。
因为 AI 的能力再强,前提也是:
你得先把资料喂对。
PDF 解析不好,后面的智能都是虚的。
